python中的json模块常用方法汇总
目录
- 一、概述
- 二、方法详解
- 1.dump()
- 2.dumps
- 3.load
- 4.loads
- 三、代码实战
- 1.dumps()
- 2.dump()
- 4.loads()
一、概述
推荐使用参考网站:json
在python中,json模块可以实现json数据的序列化和反序列化
- 序列化:将可存放在内存中的python 对象转换成可物理存储和传递的形式
- 实现方法:load() loads()
- 反序列化:将可物理存储和传递的json数据形式转换为在内存中表示的python对象
- 实现方法:dump() dumps()
二、方法详解
1.dump()
def dump(obj, fp, *, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, default=None, sort_keys=False, **kw):
- 1.把python对象obj转换成物理表现形式fp流。其中fp的.write()可以支持写入类文件中
- 2.如果skipkeys是true,那么在处理json对象的时候,仅支持 (str, int, float, bool, None) 这些基本类型的key,如果有非基本类型,就会抛出TypeError异常;如果值为false,那么对于非基本类型,则会抛出TypeError;默认值为false
- 3.如果ensure_ascii是true,那么obj中字符在写入fp的时候,非ascii字符会被进行转义;如果值为false,那么对于这些非ascii字符不会进行转义,会原样写入;默认值为true
- 4.如果check_circular是false,那么遇到container类型(list,dict,自定义编码类型)的时候,不会循环引用检查,一旦是循环引用,结果就是OverflowError;如果值为true,那么会对container类型进行循环引用检查,检查失败会 raise ValueError(“Circular reference detected”);默认值是true
- 5.如果allow_nan是false,严格遵守json的规范,对于序列化一些超出float范围的值(nan, inf, -inf)的时候,会抛出ValueError;如果值为true,那么超过float范围的值将会使用在JavaScript中的等效值(NaN, Infinity, -Infinity);默认值为true
- 6.如果indent是一个non-negative (正)整数,那么json中的数组元素和对象元素都将会使用indent单位缩进格式来进行输出;值为0的时候,就只会插入一个换行符;值为None的时候,会输出最紧凑的格式
- 7.separators的指定是以元组(item_separator, key_separator)的方式;如果indent=‘None’ 那么该选项的默认值为(', ', ': '),否则该选项的默认值为(',', ': ');如果想要紧凑的json表达,那么应该使用(',', ': ')来去除空格
- 8.default(obj)是一个函数,主要是针对于那些无法被直接序列化的对象。该参数可以提供一个默认的序列化版本,否则就会抛出一个TypeError。默认是抛出TypeError
- 9.如果sort_keys是true,那么输出的时候会根据key进行排序,默认值是false可以指定一个JSONEncoder的子类,来序列化其他的类型,可以通过cls或者是JSONEncoder参数来指定
2.dumps
def dumps(obj, *, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, default=None, sort_keys=False, **kw):
4.把obj序列化成一个json格式的字符串,并返回该字符串支持的python内置可进行json序列化的类型有(str, int, float, bool, None,list,tuple,dict)如果无法序列化的类型,会抛出TypeError
2.其他参数同上解释
3.load
def load(fp, *, cls=None, object_hook=None, parse_float=None, parse_int=None, parse_constant=None, object_pairs_hook=None, **kw):
- 1.把物理表现形式fp流(fp.read()的返回需要是一个json格式)反序列化成一个python对象
- 2.object_hook是一个可选的函数,主要用来对直接反序列化之后的结果进行二次加工;object_hook的参数只有一个,是dict,该dict也是反序列化的直接结果;object_hook的返回值为load方法的返回值 ;这个功能一般是用来自定义解码器,例如JSON-RPC
- 3.object_pairs_hook是一个可选的函数,主要用来对直接反序列化之后的结果进行二次加工;object_pairs_hook的参数只有一个,是list(tuple),该list(tuple)也是反序列化的直接结果;object_pairs_hook的返回值为load方法的返回值 ;这个功能一般是用来自定义解码器,例如JSON-RPC;在同时指定了object_hook和object_pairs_hook的时候,object_pairs_hook的优先级高于object_hook
- 4.cls的关键字参数,支持使用自定义的JSONDecoder的子类;如果不指定,默认使用JSONDecoder
4.loads
def loads(s, *, cls=None, object_hook=None, parse_float=None, parse_int=None, parse_constant=None, object_pairs_hook=None, **kw):
- 1.反序列化一个s(包含json文本的str,bytes,bytearray的实例对象)到一个python对象
- 2.object_hook 同上
- 3.object_pairs_hook同上
- 4.parse_float 如果定义了,那么会在对json字符串中的每一个float进行解码的时候调用;默认情况下等价于 float(num_str);也可以使用其他的数据类型,如(e.g. decimal.Decimal)

- 5.parse_int 如果定义了,那么会在对json字符串中的每一个float进行解码的时候调用;默认情况下,等价于 int(num_str);也可使用其他针对于json中的integer的datatype或者是parser

6.parse_constant 如果定义了,那么在碰到-Infinity, Infinity, NaN.这些的时候会被调用;如果遇到无效的json符号,会抛出异常

三、代码实战
1.dumps()
import json
if __name__ == '__main__':
# 测试格式化非json格式数据
print('-------------测试格式化非json格式数据----------------')
a = json.dumps(2.0)
print(a, type(a))
a = json.dumps(tuple())
print(a, type(a))
a = json.dumps([])
print(a, type(a))
# 测试格式化json格式数据
print('-------------测试格式化json格式数据----------------')
j = {'a': 1, 'b': 6}
a = json.dumps(j)
print(a, type(a))
# 测试skipkeys参数
print('-------------测试skipkeys参数----------------')
j = {'a': 1, tuple(): 6}
a = json.dumps(j, skipkeys=True)
print(a, type(a))
# 测试indent参数
print('-------------测试indent默认参数----------------')
j = {'a': 1, 'b': 234}
a = json.dumps(j)
print(a, type(a))
print('-------------测试indent=0参数----------------')
a = json.dumps(j, indent=0)
print(a, type(a))
print('-------------测试indent=2参数----------------')
a = json.dumps(j, indent=2)
print(a, type(a))
print('-------------测试separators参数----------------')
a = json.dumps(j, separators=('[', ']'))
print(a, type(a))

2.dump()
import json
if __name__ == '__main__':
# 测试格式化非json格式数据
fp = open('./json_dump_data', mode='w')
print('-------------测试格式化非json格式数据----------------')
a = json.dump(2.0, fp)
fp.write('\n')
a = json.dump(tuple(), fp)
a = json.dump([], fp)
fp.write('\n')
# 测试格式化json格式数据
j = {'a': 1, 'b': 6}
a = json.dump(j, fp)
cat json_dump_data:
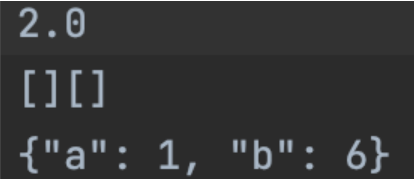
1和2中很多参数都是相同的,这里就不再详述3.load()
import json
if __name__ == '__main__':
j = open('./json_data', mode='r')
# 测试默认参数
a = json.load(j)
print('-------------测试默认参数----------------')
print(a)
# 测试object_hook参数
j = open('./json_data', mode='r')
a = json.load(j, object_hook=lambda x: x.get('b'))
print('-------------测试object_hook参数----------------')
print(a)
# 测试object_pairs_hook参数
j = open('./json_data', mode='r')
loads = json.load(j, object_pairs_hook=lambda x: print(type(x), type(x[2])))
print('-------------测试object_pairs_hook参数----------------')
print(loads)
# 测试parse_constant参数
j = open('./json_data', mode='r')
loads = json.load(j, parse_constant=lambda x: 'not notification')
print('-------------测试parse_constant参数----------------')
print(loads)
# 测试parse_int参数
j = open('./json_data', mode='r')
loads = json.load(j, parse_int=lambda x: 'cutomer int')
print('-------------测试parse_int参数----------------')
print(loads)
# 测试parse_float参数
j = open('./json_data', mode='r')
loads = json.load(j, parse_float=lambda x: 'cutomer float')
print('-------------测试parse_float参数----------------')
print(loads)

注:
因为load方法的底层是调用了fp.read(),所以每一次重新调用load的时候都需要重新打开文件句柄。不然就会导致在第二次调用load方法的时候,就会因为fp.read()返回的是none就导致异常
4.loads()
import json
if __name__ == '__main__':
j = '{"a":1,"b":2.0,"c":Infinity}'
# 测试默认参数
a = json.loads(j)
print('-------------测试默认参数----------------')
print(a)
# 测试object_hook参数
a = json.loads(j, object_hook=lambda x: x.get('b'))
print('-------------测试object_hook参数----------------')
print(a)
# 测试object_pairs_hook参数
loads = json.loads(j, object_pairs_hook=lambda x: print(type(x), type(x[2])))
print('-------------测试object_pairs_hook参数----------------')
print(loads)
# 测试parse_constant参数
loads = json.loads(j, parse_constant=lambda x: 'not notification')
print('-------------测试parse_constant参数----------------')
print(loads)
# 测试parse_int参数
loads = json.loads(j, parse_int=lambda x: 'cutomer int')
print('-------------测试parse_int参数----------------')
print(loads)
# 测试parse_float参数
loads = json.loads(j, parse_float=lambda x: 'cutomer float')
print('-------------测试parse_float参数----------------')
print(loads)

到此这篇关于python中的json模块常用方法汇总的文章就介绍到这了,更多相关python json模块 内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python实现学生管理系统的代码(JSON模块)
构思 学生管理系统 应该包含老师注册登录 管理学生信息(增删改查)还有数据持久化 因为数据存入JSON文件 增删改查都需要读取和修改文件 所以需要一个读写文件的方法文件 file_manager 密码加密可以用到哈希模块文件 tools 老师和学生的类文件 model 程序入口(主页)文件index 核心增删改查文件 student_manager file_manager.py """ Project: ClassStudent Creator: 猫猫 Create tim
-
详解python 3.6 安装json 模块(simplejson)
JSON 相关概念: 序列化(Serialization):将对象的状态信息转换为可以存储或可以通过网络传输的过程,传输的格式可以是JSON,XML等.反序列化就是从存储区域(JSON,XML)读取反序列化对象的状态,重新创建该对象. JSON(Java Script Object Notation):一种轻量级数据交互格式,相对于XML而言更简单,也易于阅读和编写,机器也方便解析和生成,Json是JavaScript中的一个子集. python2.6版本开始加入了JSON模块,python的j
-
python的json中方法及jsonpath模块用法分析
本文实例讲述了python的json中方法及jsonpath模块用法.分享给大家供大家参考,具体如下: 什么是json JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,它使得人们很容易的进行阅读和编写.同时也方便了机器进行解析和生成.适用于进行数据交互的场景,比如网站前台与后台之间的数据交互. json模块中方法的学习 其中类文件对象的理解: 具有read()或者write()方法的对象就是类文件对象,比如f = open("a.txt",
-
Python json模块与jsonpath模块区别详解
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,它使得人们很容易的进行阅读和编写.同时也方便了机器进行解析和生成.适用于进行数据交互的场景,比如网站前台与后台之间的数据交互. JSON和XML相比较可谓不相上下. Python 3.X中自带了JSON模块,直接import json就可以使用了. 官方文档:http://docs.python.org/library/json.html Json在线解析网站:http://www.json.cn/ JS
-
Python3内置json模块编码解码方法详解
目录 JSON简介 dumps编码 编码字典 编码列表 编码字符串 格式化输出JSON 转换关系对照表 loads解码 总结 JSON简介 JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,它基于ECMAScript的一个子集. JSON采用完全独立于语言的文本格式,这些特性使JSON成为理想的数据交换格式,易于人阅读和编写,同时也易于机器解析和生成,在接口数据开发和传输中非常常用. Python3中我们利用内置模块json解码和编码JSON对象.jso
-
Python 的Json 模块编码详解
可以用函数 json.dumps()将 Python 对象编码转换为字符串形式. 例如: import json python_obj = [[1,2,3],3.14,'abc',{'key1':(1,2,3),'key2':[4,5,6]},True,False,None] json_str=json.dumps(python_obj) print(json_str) 输出: [[1, 2, 3], 3.14, "abc", {"key1": [1, 2, 3],
-
Python利用jmespath模块进行json数据处理
jmespath是python的第三方模块,是需要额外安装的.它在python原有的json数据处理上 做出了很大的贡献,至于效果接下来试试就知道了有多方便. 话不多说,我们直接进入正题… 既然是第三方的库,那肯定是要安装的.通过pip的方式先将jmespath库安装好… pip install jmespath 将安装好的模块导入到代码块中… import jmespath as jp jmespath中有一个很重要.很方便的函数那就是search,不管你的json数据有多么变态,它都能给你找
-
python中的json模块常用方法汇总
目录 一.概述 二.方法详解 1.dump() 2.dumps 3.load 4.loads 三.代码实战 1.dumps() 2.dump() 4.loads() 一.概述 推荐使用参考网站:json 在python中,json模块可以实现json数据的序列化和反序列化 序列化:将可存放在内存中的python 对象转换成可物理存储和传递的形式 实现方法:load() loads() 反序列化:将可物理存储和传递的json数据形式转换为在内存中表示的python对象 实现方法:dump() du
-
python中的Json模块dumps、dump、loads、load函数用法详解
目录 json的作用 python中的Json模块dumps.dump.loads.load函数用法详解 1.json.dumps()和loads() 2.json.dump()和json.load() 3.如何读取写入多行数据呢? json的作用 JSON (JavaScript Object Notation) 是一种轻量级的数据交换格式 json.dumps(): 对数据进行编码,把python对象转换为字符串数据json.loads(): 对数据进行解码,把json的字符串转换为pyth
-
简单介绍Python中的JSON模块
(一)什么是json: JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式.易于人阅读和编写.同时也易于机器解析和生成.它基于JavaScript Programming Language, Standard ECMA-262 3rd Edition - December 1999的一个子集.JSON采用完全独立于语言的文本格式,但是也使用了类似于C语言家族的习惯(包括C, C++, C#, Java, JavaScript, Perl, Python等
-
详解python中的json的基本使用方法
在Python中使用json的时候,主要也就是使用json模块,json是以一种良好的格式来进行数据的交互,从而在很多时候,可以使用json数据格式作为程序之间的接口. #!/usr/bin/env python #-*- coding:utf-8 -*- import json print json.load(open('kel.txt')) #deserialize string or unicode to python object j = json.loads(open('kel.txt
-
使用Python中的tkinter模块作图的方法
python简述: Python是一种解释型.面向对象.动态数据类型的高级程序设计语言.自从20世纪90年代初Python语言诞生至今,它逐渐被广泛应用于处理系统管理任务和Web编程.Python[1]已经成为最受欢迎的程序设计语言之一.2011年1月,它被TIOBE编程语言排行榜评为2010年度语言.自从2004年以后,python的使用率是呈线性增长. tkinter模块介绍 tkinter模块("Tk 接口")是Python的标准Tk GUI工具包的接口.Tk和Tkinter可以
-
简单谈谈Python中的json与pickle
这是用于序列化的两个模块: • json: 用于字符串和python数据类型间进行转换 • pickle: 用于python特有的类型和python的数据类型间进行转换 Json 模块提供了四个功能:dumps.dump.loads.load pickle 模块提供了四个功能:dumps.dump.loads.load import pickle data = {'k1':123, 'k2':888} #dumps可以将数据类型转换成只有python才认识的字符串 p_str = pickle.
-
python中解析json格式文件的方法示例
前言 JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式.它基于JavaScript(Standard ECMA-262 3rd Edition - December 1999)的一个子集. JSON采用完全独立于语言的文本格式,但是也使用了类似于C语言家族的习惯(包括C, C++, C#, Java, JavaScript, Perl, Python等).这些特性使JSON成为理想的数据交换语言.易于人阅读和编写,同时也易于机器解析和生成. 本文主要介
-
Python3中的json模块使用详解
1. 概述 JSON (JavaScript Object Notation)是一种使用广泛的轻量数据格式. Python标准库中的json模块提供了JSON数据的处理功能. Python中一种非常常用的基本数据结构就是字典(Dictionary). 它的典型结构如下: d = { 'a': 123, 'b': { 'x': ['A', 'B', 'C'] } } 而JSON的结构如下: { "a": 123, "b": { "x": [&quo
-
Python中logger日志模块详解
1 logging模块简介 logging模块是Python内置的标准模块,主要用于输出运行日志,可以设置输出日志的等级.日志保存路径.日志文件回滚等:相比print,具备如下优点: 可以通过设置不同的日志等级,在release版本中只输出重要信息,而不必显示大量的调试信息: print将所有信息都输出到标准输出中,严重影响开发者从标准输出中查看其它数据:logging则可以由开发者决定将信息输出到什么地方,以及怎么输出: Logger从来不直接实例化,经常通过logging模块级方法(Modu
-
Python中安装库的常用方法介绍
目录 方法一:需要在网络条件下安装 方法二:离线安装 方法三:换源安装 总结 方法一:需要在网络条件下安装 win+R进入运行框输入命令cmd 点击确定进入 普通下载:pip install 模块名字 例如:输入 pip install pygame pip install numpy pip install xlwt xlwt代表需要安装所需包和库等 列出安装版本:pip list 和pip freeze 卸载模块: pip uninstall xlwt Y--确定卸载,n--否 指定版本下载