python库Tsmoothie模块数据平滑化异常点抓取
目录
- 前言
- 1.准备
- 2.Tsmoothie 基本使用
- 3.基于Tsmoothie的极端异常值检测
前言
在处理数据的时候,我们经常会遇到一些非连续的散点时间序列数据:
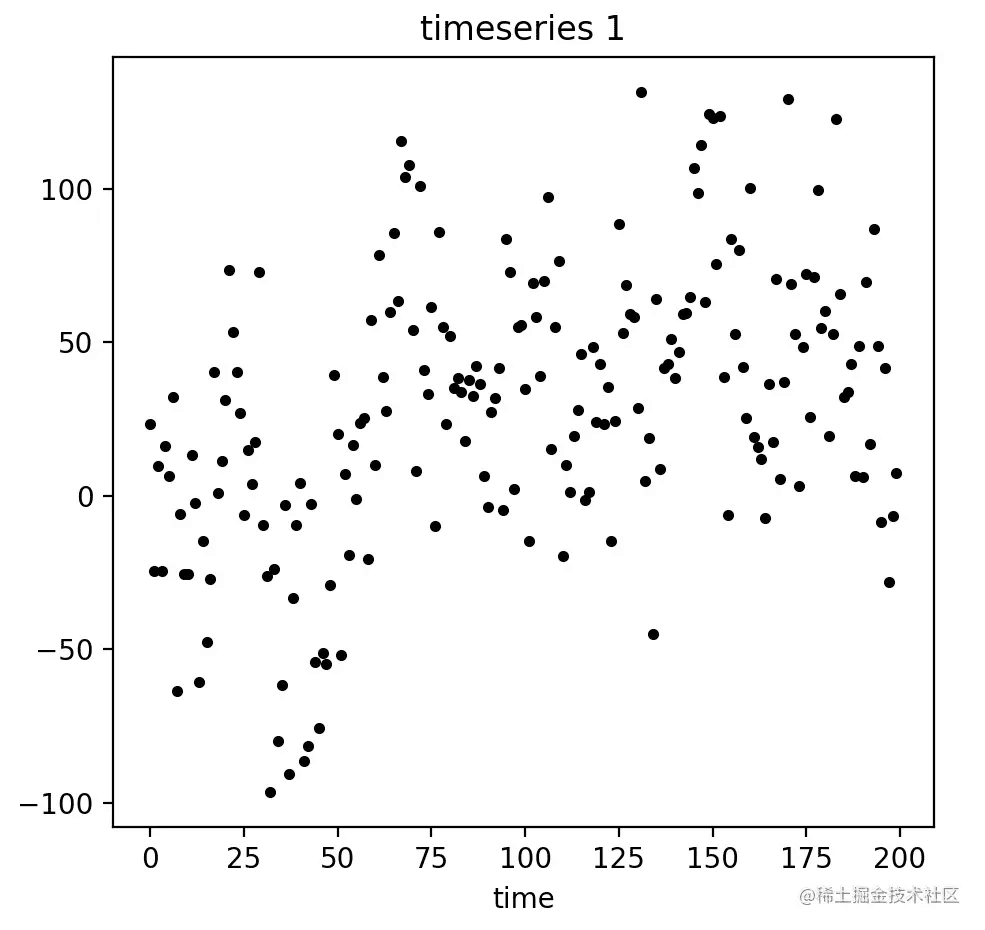
有些时候,这样的散点数据是不利于我们进行数据的聚类和预测的。因此我们需要把它们平滑化,如下图所示:
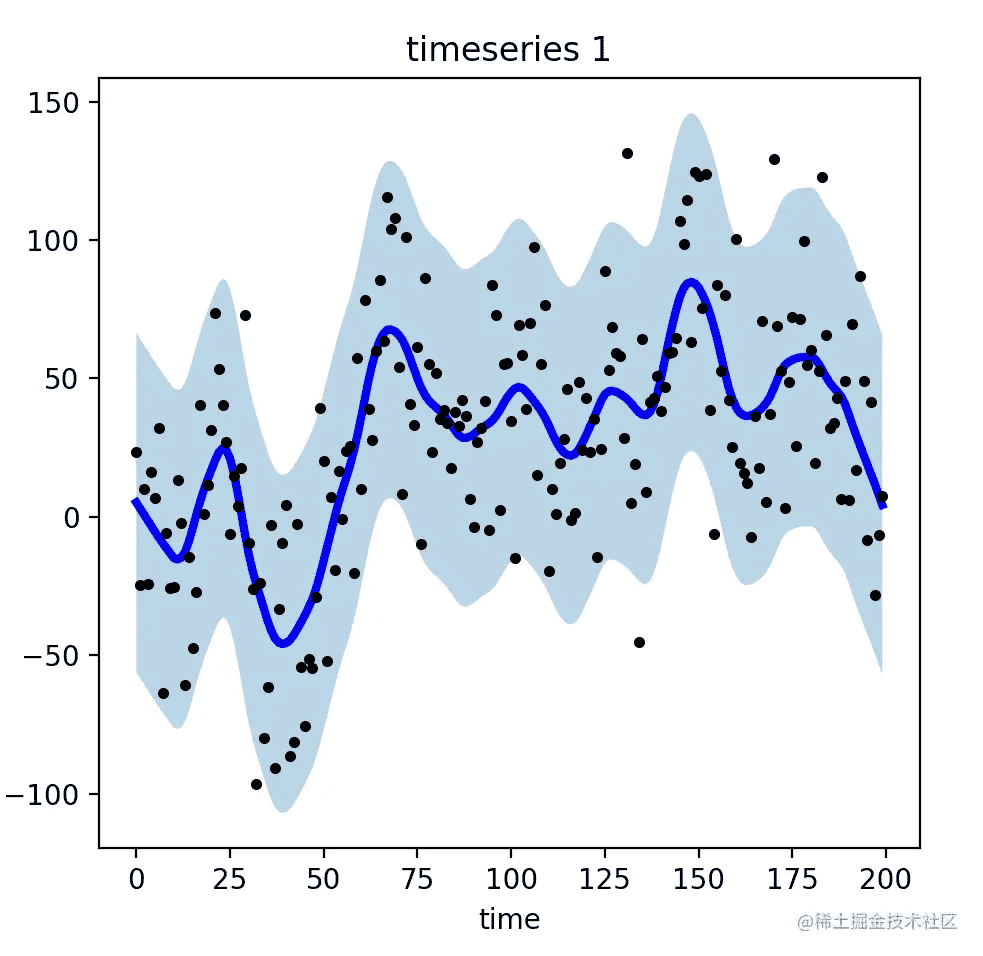
如果我们将散点及其范围区间都去除,平滑后的效果如下:
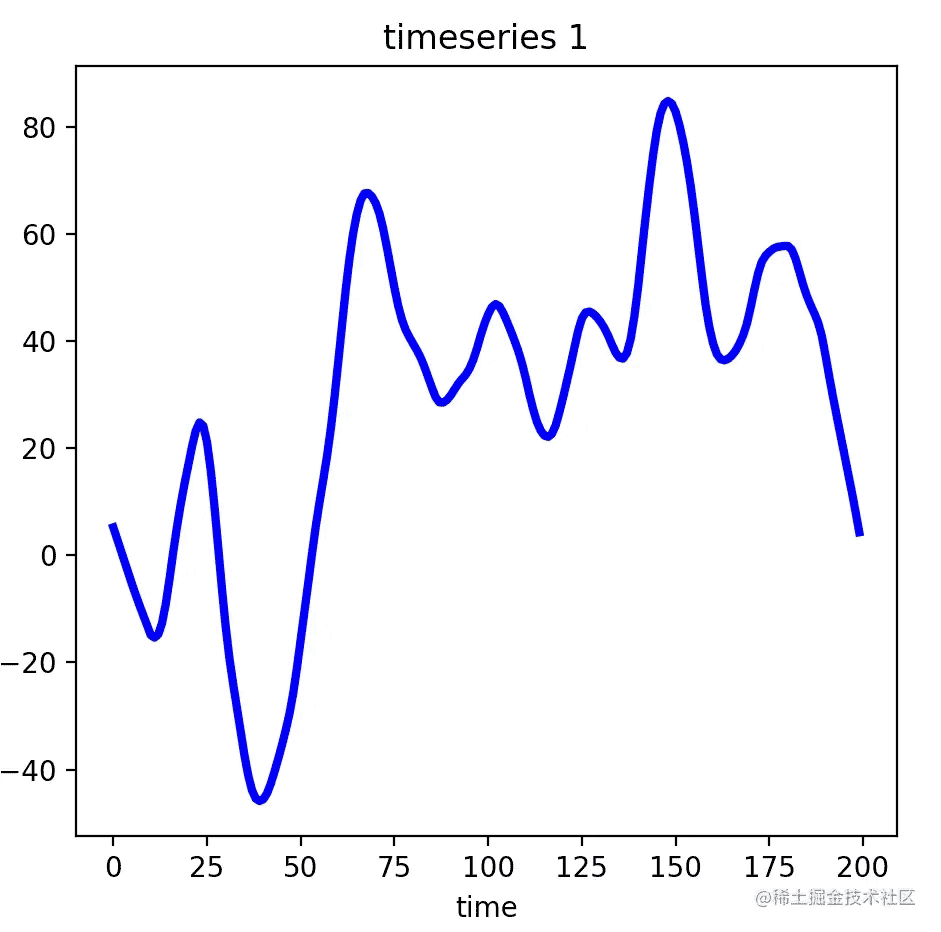
这样的时序数据是不是看起来舒服多了?此外,使用平滑后的时序数据去做聚类或预测或许有令人惊艳的效果,因为它去除了一些偏差值并细化了数据的分布范围。
如果我们自己开发一个这样的平滑工具,会耗费不少的时间。因为平滑的技术有很多种,你需要一个个地去研究,找到最合适的技术并编写代码,这是一个非常耗时的过程。平滑技术包括但不限于:
- 指数平滑
- 具有各种窗口类型(常数、汉宁、汉明、巴特利特、布莱克曼)的卷积平滑
- 傅立叶变换的频谱平滑
- 多项式平滑
- 各种样条平滑(线性、三次、自然三次)
- 高斯平滑
- 二进制平滑
所幸,有大佬已经为我们实现好了时间序列的这些平滑技术,并在GitHub上开源了这份模块的代码——它就是 Tsmoothie 模块。
1.准备
开始之前,你要确保Python和pip已经成功安装在电脑上。
(可选1) 如果你用Python的目的是数据分析,可以直接安装Anaconda,它内置了Python和pip.
(可选2) 此外,推荐大家用VSCode编辑器,它有许多的优点。
请选择以下任一种方式输入命令安装依赖:
- Windows 环境 打开 Cmd (开始-运行-CMD)。
- MacOS 环境 打开 Terminal (command+空格输入Terminal)。
- 如果你用的是 VSCode编辑器 或 Pycharm,可以直接使用界面下方的Terminal.
pip install tsmoothie
(PS) Tsmoothie 仅支持Python 3.6 及以上的版本。
2.Tsmoothie 基本使用
为了尝试Tsmoothie的效果,我们需要生成随机数据:
import numpy as np
import matplotlib.pyplot as plt
from tsmoothie.utils_func import sim_randomwalk
from tsmoothie.smoother import LowessSmoother
# 生成 3 个长度为200的随机数据组
np.random.seed(123)
data = sim_randomwalk(n_series=3, timesteps=200,
process_noise=10, measure_noise=30)
然后使用Tsmoothie执行平滑化:
# 平滑 smoother = LowessSmoother(smooth_fraction=0.1, iterations=1) smoother.smooth(data)
通过 smoother.smooth_data 你就可以获取平滑后的数据:
print(smoother.smooth_data) # [[ 5.21462928 3.07898076 0.93933646 -1.19847767 -3.32294934 # -5.40678762 -7.42425709 -9.36150892 -11.23591897 -13.05271523 # ....... ....... ....... ....... ....... ]]
绘制效果图:
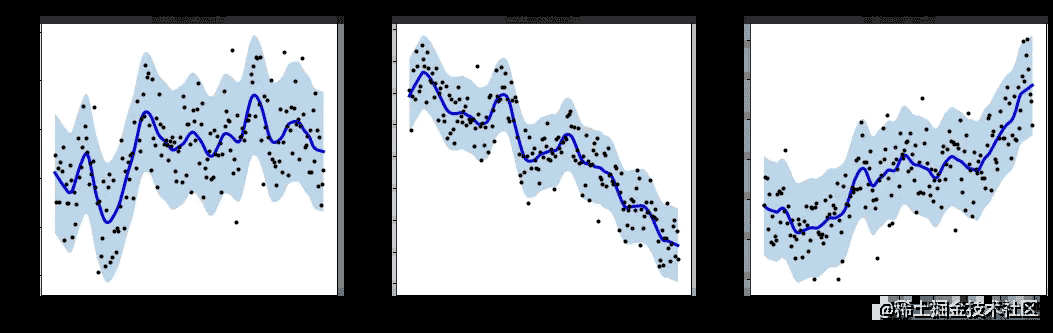
3.基于Tsmoothie的极端异常值检测
事实上,基于smoother生成的范围区域,我们可以进行异常值的检测:
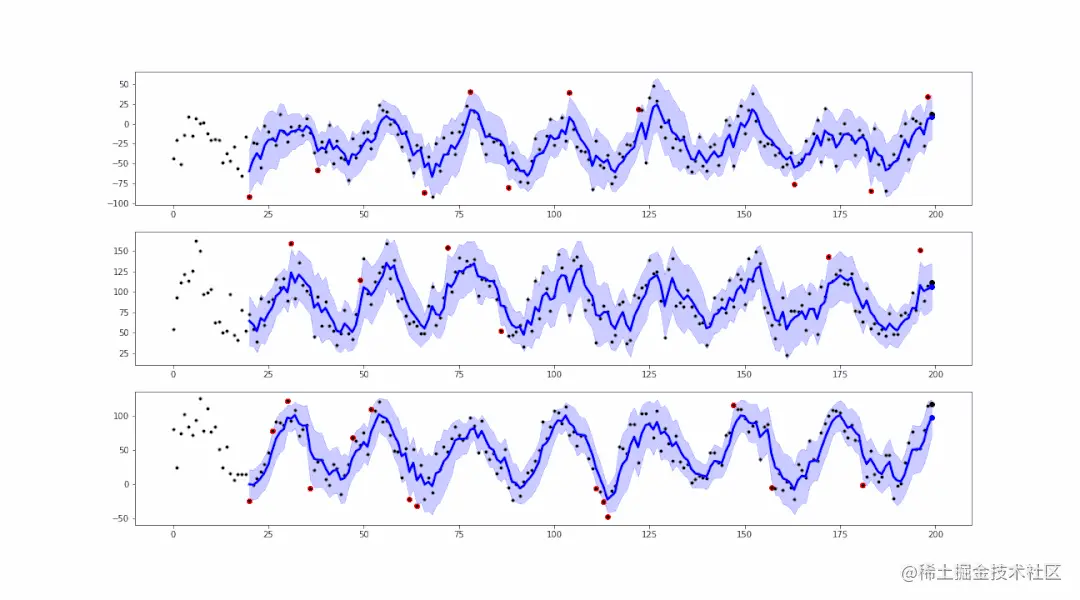
可以看到,在蓝色范围以外的点,都属于异常值。我们可以轻易地将这些异常值标红或记录,以便后续的处理。
_low, _up = smoother.get_intervals('sigma_interval', n_sigma=2)
series['low'] = np.hstack([series['low'], _low[:,[-1]]])
series['up'] = np.hstack([series['up'], _up[:,[-1]]])
is_anomaly = np.logical_or(
series['original'][:,-1] > series['up'][:,-1],
series['original'][:,-1] < series['low'][:,-1]
).reshape(-1,1)
假设蓝色范围interval的最大值为up、最小值为low,如果存在 data > up 或 data < low 则表明此数据是异常点。
使用以下代码通过滚动数据点进行平滑化和异常检测,就能保存得到上方的GIF动图。
上滑查看更多代码
# Origin: https://github.com/cerlymarco/MEDIUM_NoteBook/blob/master/Anomaly_Detection_RealTime/Anomaly_Detection_RealTime.ipynb
import numpy as np
import matplotlib.pyplot as plt
from celluloid import Camera
from collections import defaultdict
from functools import partial
from tqdm import tqdm
from tsmoothie.utils_func import sim_randomwalk, sim_seasonal_data
from tsmoothie.smoother import *
def plot_history(ax, i, is_anomaly, window_len, color='blue', **pltargs):
posrange = np.arange(0,i)
ax.fill_between(posrange[window_len:],
pltargs['low'][1:], pltargs['up'][1:],
color=color, alpha=0.2)
if is_anomaly:
ax.scatter(i-1, pltargs['original'][-1], c='red')
else:
ax.scatter(i-1, pltargs['original'][-1], c='black')
ax.scatter(i-1, pltargs['smooth'][-1], c=color)
ax.plot(posrange, pltargs['original'][1:], '.k')
ax.plot(posrange[window_len:],
pltargs['smooth'][1:], color=color, linewidth=3)
if 'ano_id' in pltargs.keys():
if pltargs['ano_id'].sum()>0:
not_zeros = pltargs['ano_id'][pltargs['ano_id']!=0] -1
ax.scatter(not_zeros, pltargs['original'][1:][not_zeros],
c='red', alpha=1.)
np.random.seed(42)
n_series, timesteps = 3, 200
data = sim_randomwalk(n_series=n_series, timesteps=timesteps,
process_noise=10, measure_noise=30)
window_len = 20
fig = plt.figure(figsize=(18,10))
camera = Camera(fig)
axes = [plt.subplot(n_series,1,ax+1) for ax in range(n_series)]
series = defaultdict(partial(np.ndarray, shape=(n_series,1), dtype='float32'))
for i in tqdm(range(timesteps+1), total=(timesteps+1)):
if i>window_len:
smoother = ConvolutionSmoother(window_len=window_len, window_type='ones')
smoother.smooth(series['original'][:,-window_len:])
series['smooth'] = np.hstack([series['smooth'], smoother.smooth_data[:,[-1]]])
_low, _up = smoother.get_intervals('sigma_interval', n_sigma=2)
series['low'] = np.hstack([series['low'], _low[:,[-1]]])
series['up'] = np.hstack([series['up'], _up[:,[-1]]])
is_anomaly = np.logical_or(
series['original'][:,-1] > series['up'][:,-1],
series['original'][:,-1] < series['low'][:,-1]
).reshape(-1,1)
if is_anomaly.any():
series['ano_id'] = np.hstack([series['ano_id'], is_anomaly*i]).astype(int)
for s in range(n_series):
pltargs = {k:v[s,:] for k,v in series.items()}
plot_history(axes[s], i, is_anomaly[s], window_len,
**pltargs)
camera.snap()
if i>=timesteps:
continue
series['original'] = np.hstack([series['original'], data[:,[i]]])
print('CREATING GIF...') # it may take a few seconds
camera._photos = [camera._photos[-1]] + camera._photos
animation = camera.animate()
animation.save('animation1.gif', codec="gif", writer='imagemagick')
plt.close(fig)
print('DONE')
注意,异常点并非都是负面作用,在不同的应用场景下,它们可能代表了不同的意义。
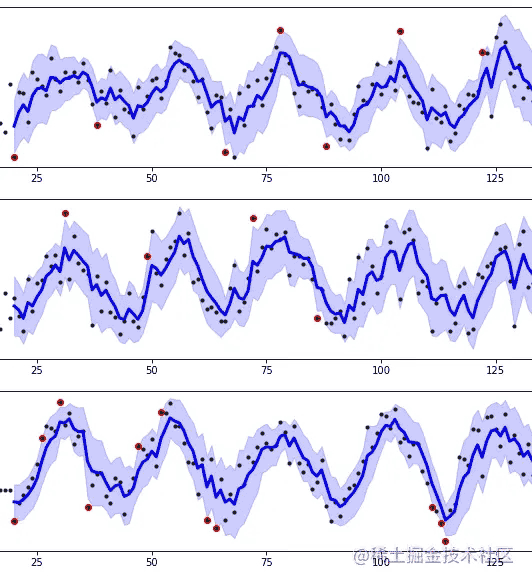
比如在股票中,它或许可以代表着震荡行情中某种趋势反转的信号。
或者在家庭用电量分析中,它可能代表着某个时刻的用电峰值,根据这个峰值我们可以此时此刻开启了什么样的电器。
所以异常点的作用需要根据不同应用场景进行不同的分析,才能找到它真正的价值。
总而言之,Tsmoothie 不仅可以使用多种平滑技术平滑化我们的时序数据,让我们的模型训练更加有效,还可以根据平滑结果找出数据中的离群点,是我们做数据分析和研究的一个好帮手,非常有价值。
以上就是python库Tsmoothie模块数据平滑化异常点抓取的详细内容,更多关于python Tsmoothie异常点抓取的资料请关注我们其它相关文章!
相关推荐
-
python基于三阶贝塞尔曲线的数据平滑算法
前言 很多文章在谈及曲线平滑的时候,习惯使用拟合的概念,我认为这是不恰当的.平滑后的曲线,一定经过原始的数据点,而拟合曲线,则不一定要经过原始数据点. 一般而言,需要平滑的数据分为两种:时间序列的单值数据.时间序列的二维数据.对于前者,并非一定要用贝塞尔算法,仅用样条插值就可以轻松实现平滑:而对于后者,不管是 numpy 还是 scipy 提供的那些插值算法,就都不适用了. 本文基于三阶贝塞尔曲线,实现了时间序列的单值数据和时间序列的二维数据的平滑算法,可满足大多数的平滑需求. 贝塞尔曲线 关于
-

详解python的异常捕获
目录 ①捕捉一个异常 ②捕捉多个异常 ③Exception捕捉所有异常 ④raise主动触发异常 ⑤try…except…else…finally逻辑 总结 ①捕捉一个异常 捕捉一个异常 以用0作为除数会得到ZeroDivisionError异常为例, print(1/0) 为例程序的持续执行,不因该异常而中止, 遂对该异常进行处理,使异常时输出该异常内容: try: print(1/0) except ZeroDivisionError as e: print(e) ②捕捉多个异常 捕捉指定的
-
python构建指数平滑预测模型示例
指数平滑法 其实我想说自己百度的- 只有懂的人才会找到这篇文章- 不懂的人-看了我的文章-还是不懂哈哈哈 指数平滑法相比于移动平均法,它是一种特殊的加权平均方法.简单移动平均法用的是算术平均数,近期数据对预测值的影响比远期数据要大一些,而且越近的数据影响越大.指数平滑法正是考虑了这一点,并将其权值按指数递减的规律进行分配,越接近当前的数据,权重越大:反之,远离当前的数据,其权重越小.指数平滑法按照平滑的次数,一般可分为一次指数平滑法.二次指数平滑法和三次指数平滑法等.然而一次指数平滑法适用于无趋
-
python数据分析实战指南之异常值处理
目录 异常值 1.异常值定义 2.异常值处理方式 2.1 均方差 2.2 箱形图 3.实战 3.1 加载数据 3.2 检测异常值数据 3.3 显示异常值的索引位置 总结 异常值 异常值是指样本中的个别值,其数值明显偏离其余的观测值.异常值也称离群点,异常值的分析也称为离群点的分析. 常用的异常值分析方法为3σ原则.箱型图分析.机器学习算法检测,一般情况下对异常值的处理都是删除和修正填补,即默认为异常值对整个项目的作用不大,只有当我们的目的是要求准确找出离群点,并对离群点进行分析时有必要用到机器学
-
python库Tsmoothie模块数据平滑化异常点抓取
目录 前言 1.准备 2.Tsmoothie 基本使用 3.基于Tsmoothie的极端异常值检测 前言 在处理数据的时候,我们经常会遇到一些非连续的散点时间序列数据: 有些时候,这样的散点数据是不利于我们进行数据的聚类和预测的.因此我们需要把它们平滑化,如下图所示: 如果我们将散点及其范围区间都去除,平滑后的效果如下: 这样的时序数据是不是看起来舒服多了?此外,使用平滑后的时序数据去做聚类或预测或许有令人惊艳的效果,因为它去除了一些偏差值并细化了数据的分布范围. 如果我们自己开发一个这样的平滑
-
利用Python的tkinter模块实现界面化的批量修改文件名
用Python编写过批量修改文件名的脚本程序,代码很简单,运行也比较快,唯一美中不足之处是每次批量修改文件名时都需要执行以下步骤: 1)复制文件夹路径: 2)打开脚本程序 3)替换脚本中的文件夹路径 4)保存脚本程序 5)执行脚本程序 为了便于操作,最好还是弄成GUI界面,手动选择文件夹,这样程序也更通用.Python中的GUI库很多,绝大部分都支持跨平台,其中安装python时自带的GUI库是tkinter,本文就学习并创建基于tkinte的批量修改文件名程序. 本文涉及的知识点包括以下几个:
-
Python利用matplotlib模块数据可视化绘制3D图
目录 前言 1 matplotlib绘制3D图形 2 绘制3D画面图 2.1 源码 2.2 效果图 3 绘制散点图 3.1 源码 3.2 效果图 4 绘制多边形 4.1 源码 4.2 效果图 5 三个方向有等高线的3D图 5.1 源码 5.2 效果图 6 三维柱状图 6.1 源码 6.2 效果图 7 补充图 7.1 源码 7.2 效果图 总结 前言 matplotlib实际上是一套面向对象的绘图库,它所绘制的图表中的每个绘图元素,例如线条Line2D.文字Text.刻度等在内存中都有一个对象与之
-
python3 BeautifulSoup模块使用字典的方法抓取a标签内的数据示例
本文实例讲述了python3 BeautifulSoup模块使用字典的方法抓取a标签内的数据.分享给大家供大家参考,具体如下: # -*- coding:utf-8 -*- #python 2.7 #XiaoDeng #http://tieba.baidu.com/p/2460150866 #标签操作 from bs4 import BeautifulSoup import urllib.request import re #如果是网址,可以用这个办法来读取网页 #html_doc = "htt
-
python微信聊天机器人改进版(定时或触发抓取天气预报、励志语录等,向好友推送)
最近想着做一个微信机器人,主要想要实现能够每天定时推送天气预报或励志语录,励志语录要每天有自动更新,定时或当有好友回复时,能够随机推送不同的内容.于是开始了分析思路.博主是采用了多线程群发,因为微信对频繁发送消息过快还会出现发送失败的问题,因此还要加入time.sleep(1),当然时间根据自身情况自己定咯.本想把接入写诗机器人,想想自己的渣电脑于是便放弃了,感兴趣的可以尝试一下.做完会有不少收获希望对你有帮助. (1)我们要找个每天定时更新天气预报的网站,和一个更新励志语录的网站.当然如果你想
-
Python使用Srapy框架爬虫模拟登陆并抓取知乎内容
一.Cookie原理 HTTP是无状态的面向连接的协议, 为了保持连接状态, 引入了Cookie机制 Cookie是http消息头中的一种属性,包括: Cookie名字(Name)Cookie的值(Value) Cookie的过期时间(Expires/Max-Age) Cookie作用路径(Path) Cookie所在域名(Domain),使用Cookie进行安全连接(Secure) 前两个参数是Cookie应用的必要条件,另外,还包括Cookie大小(Size,不同浏览器对Cookie个数及大
-
在Python中使用cookielib和urllib2配合PyQuery抓取网页信息
刚才好无聊,突然想起来之前做一个课表的点子,于是百度了起来. 刚开始,我是这样想的:在写微信墙的时候,用到了urllib2[两行代码抓网页],那么就只剩下解析html了.于是百度:python解析html.发现一篇好文章,其中介绍到了pyQuery. pyQuery 是 jQuery 在 Python 中的实现,能够以 jQuery 的语法來操作解析 HTML 文档.使用前需要安装,Mac安装方法如下: sudo easy_install pyquery OK!安装好了! 我们来试一试吧: fr
-
python使用beautifulsoup从爱奇艺网抓取视频播放
复制代码 代码如下: import sysimport urllibfrom urllib import requestimport osfrom bs4 import BeautifulSoup class DramaItem: def __init__(self, num, title, url): self.num = num self.title = title self.url = url def __str__(self):
-
Python抓取今日头条街拍图片数据
目录 (1)抓取今日头条街拍图片 (2)分析今日头条街拍图片结构 (3)按功能不同编写不同方法组织代码 (4)抓取20page今日头条街拍图片数据 (1)抓取今日头条街拍图片 (2)分析今日头条街拍图片结构 keyword: 街拍 pd: atlas dvpf: pc aid: 4916 page_num: 1 search_json: {"from_search_id":"20220104115420010212192151532E8188","orig
-
python实现多线程抓取知乎用户
需要用到的包: beautifulsoup4 html5lib image requests redis PyMySQL pip安装所有依赖包: pip install \ Image \ requests \ beautifulsoup4 \ html5lib \ redis \ PyMySQL 运行环境需要支持中文 测试运行环境python3.5,不保证其他运行环境能完美运行 需要安装mysql和redis 配置 config.ini 文件,设置好mysql和redis,并且填写你的知乎帐号