Python多线程Threading、子线程与守护线程实例详解
本文实例讲述了Python多线程Threading、子线程与守护线程。分享给大家供大家参考,具体如下:
线程与进程:
- 线程对于进程来说,就好似工厂里的工人,分配资源是分配到工厂,工人再去处理。
- 线程是被系统独立调度和分派的基本单位,线程自己不拥有系统资源,只拥有一点儿在运行中必不可少的资源,但它可与同属一个进程的其它线程共享进程所拥有的全部资源。
- 在单个程序中同时运行多个线程完成不同的工作,称为多线程
- 对于IO密集型的程序来说,多线程可以利用读IO的时间去做其他事【IO并不占用CPU,这就好像A买个一份外卖,他只需要等着送过来然后敲A家的门就行了】;
- 而对于CPU密集型的程序来说,多线程的效率就不是很高了【CPU由于要计算,切换之间要恢复之前的现场消耗相对较大,比如我同时做几份作业,一份作业做十分钟,假如十分钟做不完一份作业,那么我后面再回头做的时候,我就要好好想想刚才做到哪,刚才想到哪】
补充:IO需要CPU吗?知乎:https://www.zhihu.com/question/27734728
-
线程Threading:
python中多线程需要使用threading模块
线程的创建与运行:
1.直接调用threading的Thread类:
线程的创建:线程对象=thread.Thread(target=函数名,args=(参数))【补充,由于args是一个元组,单个参数时要加“,”】
线程的启动:线程对象.start(),调用start(),那么线程对象会自动去调用thread.Thread中的run()
让主线程等待其余线程结束:线程对象.join(),加了join之后,相当于阻塞了主线程,主线程只有当join的线程结束后才会向下执行
import threading,time def run(n): time.sleep(1) print("task ",n) t1=threading.Thread(target=run,args=("t1",)) t2 = threading.Thread(target=run,args=("t2",)) start_time=time.time()#开始时间 t1.start() t2.start() ##因为是独立线程,如果想要主线程等待其他线程运行完毕,需要使用join t1.join() t2.join() spend_time=time.time()-start_time print(spend_time)##1.0多,说明是并行的结果附加说明--join是阻塞等待:
import threading,time class MyTread(threading.Thread): def __init__(self,name): super(MyTread,self).__init__()#调用父类的__init__() self.name=name def run(self):#重写方法,按自己的要求去写 time.sleep(1) print("run in task",self.name,threading.current_thread(),threading.active_count()) t1=MyTread("t1") t2=MyTread("t2") start_time=time.time() t1.start() t2.start() t1.join() t2.join() time.sleep(1)###主线程等待其余线程结束 print(time.time()-start_time) #结果是2.0多,证明是join是相当于阻塞了主线程的执行,只有当线程结束后才会向下执行2.继承threading的Thread类:
继承threading的Thread类的类要主要做两件事:
1.如果不做自定义变量的初始化,那么可以直接使用继承的父类的__init__(),如果需要做自定义变量的初始化,则需要先调用父类的__init__()【否则需要自己填写线程初始化相关的参数】
2.重写run,虽然继承了父类的run,但实际上如果不重写,那么我们继承threading的Thread类又有什么意义呢?为什么不直接调用threading的Thread类
-
import threading,time class MyTread(threading.Thread): def __init__(self,name): super(MyTread,self).__init__()#调用父类的__init__() self.name=name def run(self):#重写方法,按自己的要求去写 time.sleep(1) print("run in task",self.name,threading.current_thread(),threading.active_count()) t1=MyTread("t1") t2=MyTread("t2") start_time=time.time() t1.start() t2.start() ###主线程等待其余线程结束 t1.join() t2.join() print(time.time()-start_time)#结果是1.0多,证明是并行的
子线程:
- 由一个线程启动的线程可以成为它的子线程,A启动B,B是A的子线程,A是B的父线程
线程的几个常用函数:
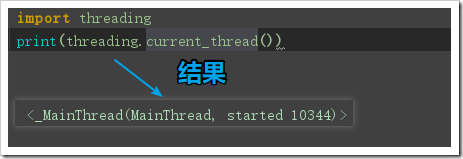
- threading.current_thread():
返回当前正在运行的线程对象
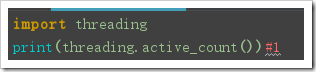
- threading.active_count():
返回当前进程中的存活的线程对象数
- 线程对象.isAlive()方法判断线程是否存活
- getName(): 返回线程名。
- setName(): 设置线程名。

- get_ident():获取当前线程ID。
守护线程:
- 守护线程是起到辅助功能的,就好像魔法师放禁咒总要骑士保护一样【魔法师只需要关系自己的任务,保护他的任务交给守护者】
- 而守护线程与主线程的关系呢,就好像备胎跟女神,去买东西的话,备胎要一直在外面等女神【守护线程运行结束就狗带,但不影响主进程结束,由主线程决定运行时间】,女神不需要等待备胎【主线程结束,守护线程也要结束,不管自身任务是否完成】
- 与join的区别:join是阻塞等待,守护线程是并行的等待
- 设置守护线程:线程对象.setDaemon(True)【注意!!!!!设置守护线程必须要在start()前面,不然会报错】
下面的代码显示了主线程并不会等待其守护线程结束:
import threading,time class MyTread(threading.Thread): def __init__(self,name): super(MyTread,self).__init__() self.name=name def run(self): print("守护线程已经启动",self.name) time.sleep(1) print("run in task",self.name,threading.current_thread(),threading.active_count()) t1=MyTread("t1") t1.setDaemon(True) t2=MyTread("t2") t2.setDaemon(True) start_time=time.time()#开始时间 t1.start() t2.start() spend_time=time.time()-start_time print(spend_time)##0.0多,而且三个线程都执行完毕了,说明这个是并行的等待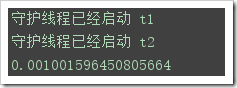
让主线程sleep一下,显示一下如果主线程要等待守护线程,那么是并行的等待:
import threading,time class MyTread(threading.Thread): def __init__(self,name): super(MyTread,self).__init__() self.name=name def run(self): print("守护线程已经启动",self.name) time.sleep(1) print("run in task",self.name,threading.current_thread(),threading.active_count()) t1=MyTread("t1") t1.setDaemon(True) t2=MyTread("t2") t2.setDaemon(True) start_time=time.time()#开始时间 t1.start() t2.start() time.sleep(2) spend_time=time.time()-start_time print(spend_time)##2.0多,而且三个线程都执行完毕了,说明这个是并行的等待
更多关于Python相关内容感兴趣的读者可查看本站专题:《Python进程与线程操作技巧总结》、《Python数据结构与算法教程》、《Python函数使用技巧总结》、《Python字符串操作技巧汇总》、《Python入门与进阶经典教程》、《Python+MySQL数据库程序设计入门教程》及《Python常见数据库操作技巧汇总》
希望本文所述对大家Python程序设计有所帮助。
相关推荐
-
python主线程与子线程的结束顺序实例解析
这篇文章主要介绍了python主线程与子线程的结束顺序实例解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 引用自 主线程退出对子线程的影响 的一段话: 对于程序来说,如果主进程在子进程还未结束时就已经退出,那么Linux内核会将子进程的父进程ID改为1(也就是init进程),当子进程结束后会由init进程来回收该子进程. 主线程退出后子线程的状态依赖于它所在的进程,如果进程没有退出的话子线程依然正常运转.如果进程退出了,那么它所有的线程都会
-
python实现守护进程、守护线程、守护非守护并行
守护进程 1.守护子进程 主进程创建守护进程 其一:守护进程会在主进程代码执行结束后就终止 其二:守护进程内无法再开启子进程,否则抛出异常:AssertionError: daemonic processes are not allowed to havechildren 注意:进程之间是互相独立的,主进程代码运行结束,守护进程随即终止 我们来看一个例子 from multiprocessing import Process import os,time,random def task(): p
-
python子线程退出及线程退出控制的代码
下面通过代码给大家介绍python子线程退出问题,具体内容如下所示: def thread_func(): while True: #do something #do something #do something t=threading.Thread(target = thread_func) t.start() # main thread do something # main thread do something # main thread do something 跑起来是没有问题的,
-
python 多线程中子线程和主线程相互通信方法
需求:主线程开启了多个线程去干活,每个线程需要完成的时间不同,但是在干完活以后都要通知给主线程 下面上代码: #!/usr/bin/python # coding:utf8 ''' 多线程和queue配合使用,实现子线程和主线程相互通信的例子 ''' import threading __author__ = "Kenny.Li" import Queue import time import random q = Queue.Queue() class MyThread(thread
-
python主线程捕获子线程的方法
最近,在做一个项目时遇到的了一个问题,主线程无法捕获子线程中抛出的异常. 先看一个线程类的定义 ''''' Created on Oct 27, 2015 @author: wujz ''' import threading class runScriptThread(threading.Thread): def __init__(self, funcName, *args): threading.Thread.__init__(self) self.args = args self.funcN
-

Python 多线程Threading初学教程
1.1 什么是多线程 Threading 多线程可简单理解为同时执行多个任务. 多进程和多线程都可以执行多个任务,线程是进程的一部分.线程的特点是线程之间可以共享内存和变量,资源消耗少(不过在Unix环境中,多进程和多线程资源调度消耗差距不明显,Unix调度较快),缺点是线程之间的同步和加锁比较麻烦. 1.2 添加线程 Thread 导入模块 import threading 获取已激活的线程数 threading.active_count() 查看所有线程信息 threading.enumer
-
Python多线程threading模块用法实例分析
本文实例讲述了Python多线程threading模块用法.分享给大家供大家参考,具体如下: 多线程 - threading python的thread模块是比较底层的模块,python的threading模块对thread做了一些包装,可以更加方便的被使用. 1. 使用threading模块 单线程执行 #coding=utf-8 import time def saySorry(): print('跑一圈') time.sleep(1) if __name__ == "__main__&qu
-
Python多线程threading和multiprocessing模块实例解析
本文研究的主要是Python多线程threading和multiprocessing模块的相关内容,具体介绍如下. 线程是一个进程的实体,是由表示程序运行状态的寄存器(如程序计数器.栈指针)以及堆栈组成,它是比进程更小的单位. 线程是程序中的一个执行流.一个执行流是由CPU运行程序代码并操作程序的数据所形成的.因此,线程被认为是以CPU为主体的行为. 线程不包含进程地址空间中的代码和数据,线程是计算过程在某一时刻的状态.所以,系统在产生一个线程或各个线程之间切换时,负担要比进程小得多. 线程是一
-
Python多线程threading join和守护线程setDeamon原理详解
同一进程下的多个线程共享内存数据,多个线程之间没有主次关系,相互之间可以操作:cpu执行的都是线程,默认程序会开一个主线程:进程是程序以及和程序相关资源的集合:某些场景下我们可以使用多线程来达到提高程序执行效率的目的,下面就多线程的一些基础知识做简要说明 简单的多线程 import threading, time def test1(x): time.sleep(5) print(x**x) #下面定义两个线程调用test1这个函数,创建多线程使用如下语法,target后面跟函数名,args传递
-
Python 多线程,threading模块,创建子线程的两种方式示例
本文实例讲述了Python 多线程,threading模块,创建子线程的两种方式.分享给大家供大家参考,具体如下: GIL(全局解释器锁)是C语言版本的Python解释器中专有的,GIL的存在让多线程的效率变低(哪个线程抢到锁,就执行哪个线程).在IO密集型程序中,多线程依然比单线程效率高(GIL通过IO阻塞自动切换多线程). 解决GIL(全局解释器锁)的问题的三种方法: 1.不要用C语言版本的Python解释器. 2.让子线程运行其他语言代码(例如:主线程运行Python代码,子线程运行C语言
-
python从子线程中获得返回值的方法
如下所示: # coding:utf-8 import time from threading import Thread def foo(number): time.sleep(20) return number class MyThread(Thread): def __init__(self, number): Thread.__init__(self) self.number = number def run(self): self.result = foo(self.number) d
-
python多线程threading.Lock锁用法实例
本文实例讲述了python多线程threading.Lock锁的用法实例,分享给大家供大家参考.具体分析如下: python的锁可以独立提取出来 复制代码 代码如下: mutex = threading.Lock() #锁的使用 #创建锁 mutex = threading.Lock() #锁定 mutex.acquire([timeout]) #释放 mutex.release() 锁定方法acquire可以有一个超时时间的可选参数timeout.如果设定了timeout,则在超时后通过返回值