PyTorch中view()与 reshape()的区别详析
目录
- 前言
- 一、PyTorch中tensor的存储方式
- 1、PyTorch张量存储的底层原理
- 2、PyTorch张量的步长(stride)属性
- 二、对“视图(view)”字眼的理解
- 三、view() 和reshape() 的比较
- 1、对 torch.Tensor.view() 的理解
- 2、对 torch.reshape() 的理解
- 四、总结
前言
总之,两者都是用来重塑tensor的shape的。view只适合对满足连续性条件(contiguous)的tensor进行操作,而reshape同时还可以对不满足连续性条件的tensor进行操作,具有更好的鲁棒性。view能干的reshape都能干,如果view不能干就可以用reshape来处理。别看目录挺多,但内容很细呀~其实原理并不难啦~我们开始吧~
一、PyTorch中tensor的存储方式
想要深入理解view与reshape的区别,首先要理解一些有关PyTorch张量存储的底层原理,比如tensor的头信息区(Tensor)和存储区 (Storage)以及tensor的步长Stride。不用慌,这部分的原理其实很简单的(^-^)!
1、PyTorch张量存储的底层原理
tensor数据采用头信息区(Tensor)和存储区 (Storage)分开存储的形式,如图1所示。变量名以及其存储的数据是分为两个区域分别存储的。比如,我们定义并初始化一个tensor,tensor名为A,A的形状size、步长stride、数据的索引等信息都存储在头信息区,而A所存储的真实数据则存储在存储区。另外,如果我们对A进行截取、转置或修改等操作后赋值给B,则B的数据共享A的存储区,存储区的数据数量没变,变化的只是B的头信息区对数据的索引方式。如果听说过浅拷贝和深拷贝的话,很容易明白这种方式其实就是浅拷贝。
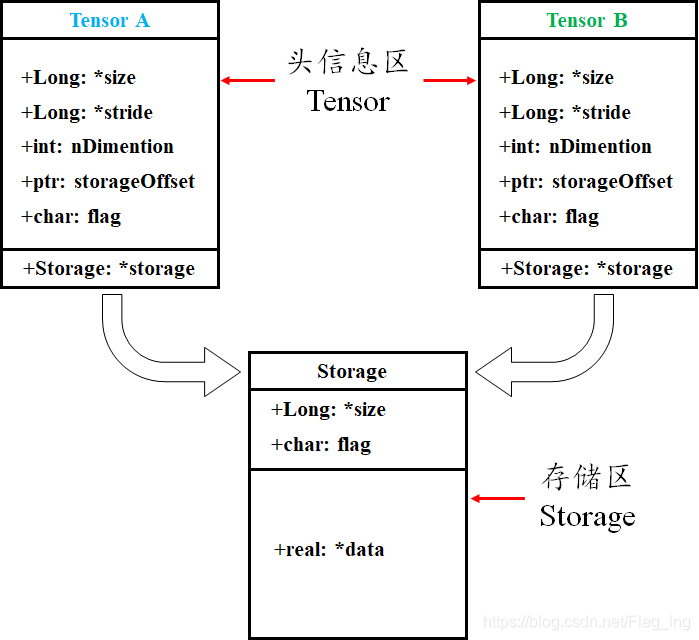
图1 Torch中Tensor的存储结构
举个例子:
import torch
a = torch.arange(5) # 初始化张量 a 为 [0, 1, 2, 3, 4]
b = a[2:] # 截取张量a的部分值并赋值给b,b其实只是改变了a对数据的索引方式
print('a:', a)
print('b:', b)
print('ptr of storage of a:', a.storage().data_ptr()) # 打印a的存储区地址
print('ptr of storage of b:', b.storage().data_ptr()) # 打印b的存储区地址,可以发现两者是共用存储区
print('==================================================================')
b[1] = 0 # 修改b中索引为1,即a中索引为3的数据为0
print('a:', a)
print('b:', b)
print('ptr of storage of a:', a.storage().data_ptr()) # 打印a的存储区地址,可以发现a的相应位置的值也跟着改变,说明两者是共用存储区
print('ptr of storage of b:', b.storage().data_ptr()) # 打印b的存储区地址
''' 运行结果 '''
a: tensor([0, 1, 2, 3, 4])
b: tensor([2, 3, 4])
ptr of storage of a: 2862826251264
ptr of storage of b: 2862826251264
==================================================================
a: tensor([0, 1, 2, 0, 4])
b: tensor([2, 0, 4])
ptr of storage of a: 2862826251264
ptr of storage of b: 2862826251264
2、PyTorch张量的步长(stride)属性
torch的tensor也是有步长属性的,说起stride属性是不是很耳熟?是的,卷积神经网络中卷积核对特征图的卷积操作也是有stride属性的,但这两个stride可完全不是一个意思哦。tensor的步长可以理解为从索引中的一个维度跨到下一个维度中间的跨度。为方便理解,就直接用图1说明了,您细细品(^-^):
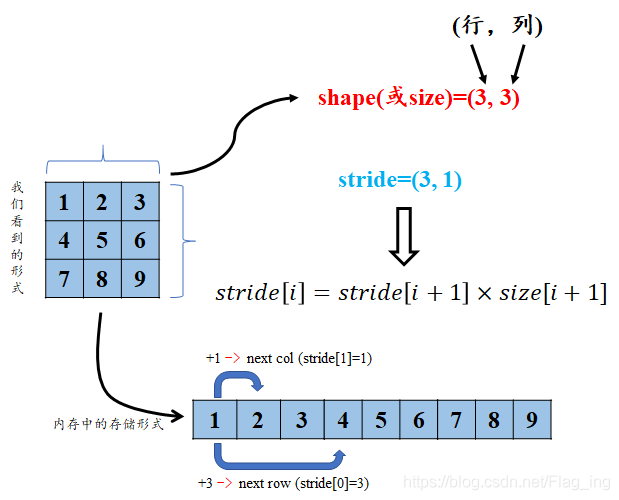
图2 对张量的stride属性的理解
举个例子:
import torch
a = torch.arange(6).reshape(2, 3) # 初始化张量 a
b = torch.arange(6).view(3, 2) # 初始化张量 b
print('a:', a)
print('stride of a:', a.stride()) # 打印a的stride
print('b:', b)
print('stride of b:', b.stride()) # 打印b的stride
''' 运行结果 '''
a: tensor([[0, 1, 2],
[3, 4, 5]])
stride of a: (3, 1)
b: tensor([[0, 1],
[2, 3],
[4, 5]])
stride of b: (2, 1)
二、对“视图(view)”字眼的理解
视图是数据的一个别称或引用,通过该别称或引用亦便可访问、操作原有数据,但原有数据不会产生拷贝。如果我们对视图进行修改,它会影响到原始数据,物理内存在同一位置,这样避免了重新创建张量的高内存开销。由上面介绍的PyTorch的张量存储方式可以理解为:对张量的大部分操作就是视图操作!
与之对应的概念就是副本。副本是一个数据的完整的拷贝,如果我们对副本进行修改,它不会影响到原始数据,物理内存不在同一位置。
有关视图与副本,在NumPy中也有着重要的应用。可参考这里。
三、view() 和reshape() 的比较
1、对 torch.Tensor.view() 的理解
定义:
view(*shape) → Tensor
作用:类似于reshape,将tensor转换为指定的shape,原始的data不改变。返回的tensor与原始的tensor共享存储区。返回的tensor的size和stride必须与原始的tensor兼容。每个新的tensor的维度必须是原始维度的子空间,或满足以下连续条件:
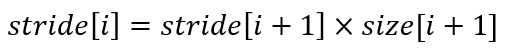
式1 张量连续性条件
否则需要先使用contiguous()方法将原始tensor转换为满足连续条件的tensor,然后就可以使用view方法进行shape变换了。或者直接使用reshape方法进行维度变换,但这种方法变换后的tensor就不是与原始tensor共享内存了,而是被重新开辟了一个空间。
如何理解tensor是否满足连续条件呐?下面通过一系列例子来慢慢理解下:
首先,我们初始化一个张量 a ,并查看其stride、storage等属性:
import torch
a = torch.arange(9).reshape(3, 3) # 初始化张量a
print('struct of a:\n', a)
print('size of a:', a.size()) # 查看a的shape
print('stride of a:', a.stride()) # 查看a的stride
''' 运行结果 '''
struct of a:
tensor([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]])
size of a: torch.Size([3, 3])
stride of a: (3, 1) # 注:满足连续性条件
把上面的结果带入式1,可以发现满足tensor连续性条件。
我们再看进一步处理——对a进行转置后的结果:
import torch
a = torch.arange(9).reshape(3, 3) # 初始化张量a
b = a.permute(1, 0) # 对a进行转置
print('struct of b:\n', b)
print('size of b:', b.size()) # 查看b的shape
print('stride of b:', b.stride()) # 查看b的stride
''' 运行结果 '''
struct of b:
tensor([[0, 3, 6],
[1, 4, 7],
[2, 5, 8]])
size of b: torch.Size([3, 3])
stride of b: (1, 3) # 注:此时不满足连续性条件
将a转置后再看最后的输出结果,带入到式1中,是不是发现等式不成立了?所以此时就不满足tensor连续的条件了。这是为什么那?我们接着往下看:
首先,输出a和b的存储区来看一下有没有什么不同:
import torch
a = torch.arange(9).reshape(3, 3) # 初始化张量a
print('ptr of storage of a: ', a.storage().data_ptr()) # 查看a的storage区的地址
print('storage of a: \n', a.storage()) # 查看a的storage区的数据存放形式
b = a.permute(1, 0) # 转置
print('ptr of storage of b: ', b.storage().data_ptr()) # 查看b的storage区的地址
print('storage of b: \n', b.storage()) # 查看b的storage区的数据存放形式
''' 运行结果 '''
ptr of storage of a: 2767173747136
storage of a:
0
1
2
3
4
5
6
7
8
[torch.LongStorage of size 9]
ptr of storage of b: 2767173747136
storage of b:
0
1
2
3
4
5
6
7
8
[torch.LongStorage of size 9]
由结果可以看出,张量a、b仍然共用存储区,并且存储区数据存放的顺序没有变化,这也充分说明了b与a共用存储区,b只是改变了数据的索引方式。那么为什么b就不符合连续性条件了呐(T-T)?其实原因很简单,我们结合图3来解释下:
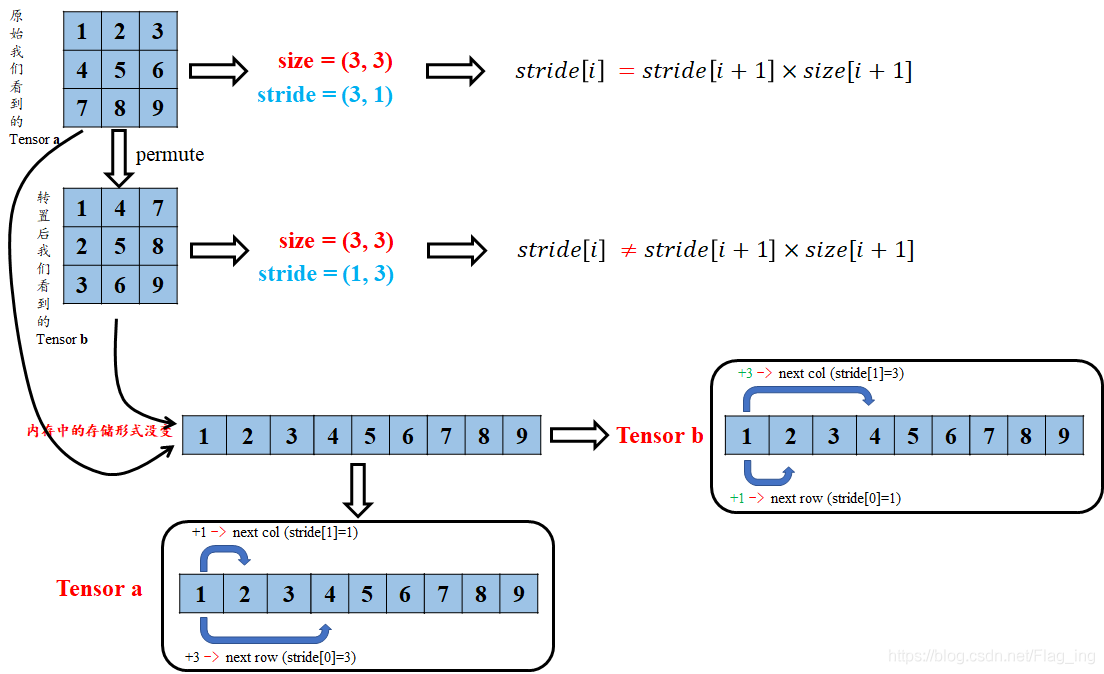
图3 对张量连续性条件的理解
转置后的tensor只是对storage区数据索引方式的重映射,但原始的存放方式并没有变化.因此,这时再看tensor b的stride,从b第一行的元素1到第二行的元素2,显然在索引方式上已经不是原来+1了,而是变成了新的+3了,你在仔细琢磨琢磨是不是这样的(^-^)。所以这时候就不能用view来对b进行shape的改变了,不然就报错咯,不信你看下面;
import torch
a = torch.arange(9).reshape(3, 3) # 初始化张量a
print(a.view(9))
print('============================================')
b = a.permute(1, 0) # 转置
print(b.view(9))
''' 运行结果 '''
tensor([0, 1, 2, 3, 4, 5, 6, 7, 8])
============================================
Traceback (most recent call last):
File "此处打码", line 23, in <module>
print(b.view(9))
RuntimeError: view size is not compatible with input tensor's size and stride (at least one dimension spans across two contiguous subspaces). Use .reshape(...) instead.
但是嘛,上有政策下有对策,这种情况下,直接用view不行,那我就先用contiguous()方法将原始tensor转换为满足连续条件的tensor,在使用view进行shape变换,值得注意的是,这样的原理是contiguous()方法开辟了一个新的存储区给b,并改变了b原始存储区数据的存放顺序!同样的例子:
import torch
a = torch.arange(9).reshape(3, 3) # 初始化张量a
print('storage of a:\n', a.storage()) # 查看a的stride
print('+++++++++++++++++++++++++++++++++++++++++++++++++')
b = a.permute(1, 0).contiguous() # 转置,并转换为符合连续性条件的tensor
print('size of b:', b.size()) # 查看b的shape
print('stride of b:', b.stride()) # 查看b的stride
print('viewd b:\n', b.view(9)) # 对b进行view操作,并打印结果
print('+++++++++++++++++++++++++++++++++++++++++++++++++')
print('storage of a:\n', a.storage()) # 查看a的存储空间
print('storage of b:\n', b.storage()) # 查看b的存储空间
print('+++++++++++++++++++++++++++++++++++++++++++++++++')
print('ptr of a:\n', a.storage().data_ptr()) # 查看a的存储空间地址
print('ptr of b:\n', b.storage().data_ptr()) # 查看b的存储空间地址
''' 运行结果 '''
storage of a:
0
1
2
3
4
5
6
7
8
[torch.LongStorage of size 9]
+++++++++++++++++++++++++++++++++++++++++++++++++
size of b: torch.Size([3, 3])
stride of b: (3, 1)
viewd b:
tensor([0, 3, 6, 1, 4, 7, 2, 5, 8])
+++++++++++++++++++++++++++++++++++++++++++++++++
storage of a:
0
1
2
3
4
5
6
7
8
[torch.LongStorage of size 9]
storage of b:
0
3
6
1
4
7
2
5
8
[torch.LongStorage of size 9]
+++++++++++++++++++++++++++++++++++++++++++++++++
ptr of a:
1842671472000
ptr of b:
1842671472128
由上述结果可以看出,张量a与b已经是两个存在于不同存储区的张量了。也印证了contiguous()方法开辟了一个新的存储区给b,并改变了b原始存储区数据的存放顺序。对应文章开头提到的浅拷贝,这种开辟一个新的内存区的方式其实就是深拷贝。
2、对 torch.reshape() 的理解
定义:
torch.reshape(input, shape) → Tensor
作用:与view方法类似,将输入tensor转换为新的shape格式。
但是reshape方法更强大,可以认为a.reshape = a.view() + a.contiguous().view()。
即:在满足tensor连续性条件时,a.reshape返回的结果与a.view()相同,否则返回的结果与a.contiguous().view()相同。
不信你就看人家官方的解释嘛,您在细细品:
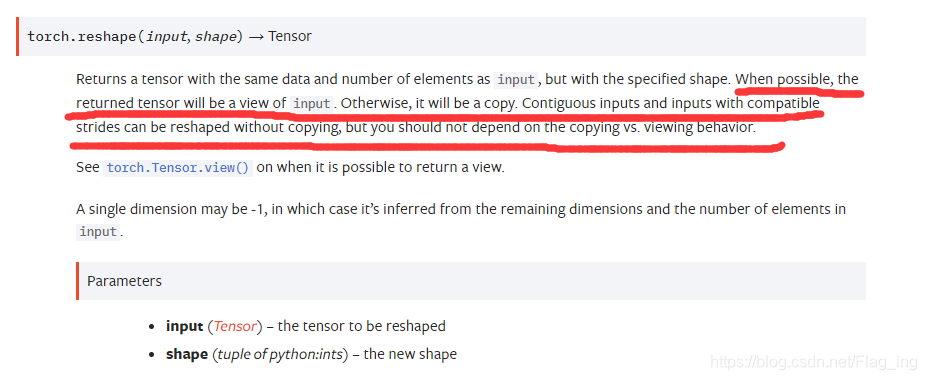
关于两者区别,还可以参考这个链接:
What's the difference between reshape and view in pytorch? - Stack Overflow
2021.03.30更新:最近又发现了pytorch官网对view及reshape原理的阐述,说的很清晰明了,大家可以参考下:
Tensor Views — PyTorch 1.9.0 documentation
放一张该网站上的截图:

四、总结
torch的view()与reshape()方法都可以用来重塑tensor的shape,区别就是使用的条件不一样。view()方法只适用于满足连续性条件的tensor,并且该操作不会开辟新的内存空间,只是产生了对原存储空间的一个新别称和引用,返回值是视图。而reshape()方法的返回值既可以是视图,也可以是副本,当满足连续性条件时返回view,否则返回副本[ 此时等价于先调用contiguous()方法在使用view() ]。因此当不确能否使用view时,可以使用reshape。如果只是想简单地重塑一个tensor的shape,那么就是用reshape,但是如果需要考虑内存的开销而且要确保重塑后的tensor与之前的tensor共享存储空间,那就使用view()。
2020.10.23
以上是我个人看了官网的的解释并实验得到的结论,所以有没有dalao知道为啥没把view废除那?是不是还有我不知道的地方
2020.11.14
为什么没把view废除那?最近偶然看到了些资料,又想起了这个问题,觉得有以下原因:
1、在PyTorch不同版本的更新过程中,view先于reshape方法出现,后来出现了鲁棒性更好的reshape方法,但view方法并没因此废除。其实不止PyTorch,其他一些框架或语言比如OpenCV也有类似的操作。
2、view的存在可以显示地表示对这个tensor的操作只能是视图操作而非拷贝操作。这对于代码的可读性以及后续可能的bug的查找比较友好。
总之,我们没必要纠结为啥a能干的b也能干,b还能做a不能干的,a存在还有啥意义的问题。就相当于马云能日赚1个亿而我不能,那我存在的意义是啥。。。存在不就是意义吗?存在即合理,最重要的是我们使用不同的方法可以不同程度上提升效率,何乐而不为?
到此这篇关于PyTorch中view() 与 reshape()区别的文章就介绍到这了,更多相关PyTorch view() 与 reshape() 区别内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
基于PyTorch的permute和reshape/view的区别介绍
二维的情况 先用二维tensor作为例子,方便理解. permute作用为调换Tensor的维度,参数为调换的维度.例如对于一个二维Tensor来说,调用tensor.permute(1,0)意为将1轴(列轴)与0轴(行轴)调换,相当于进行转置. In [20]: a Out[20]: tensor([[0, 1, 2], [3, 4, 5]]) In [21]: a.permute(1,0) Out[21]: tensor([[0, 3], [1, 4], [2, 5]]) 如果使用view(
-
pytorch 在sequential中使用view来reshape的例子
pytorch中view是tensor方法,然而在sequential中包装的是nn.module的子类,因此需要自己定义一个方法: import torch.nn as nn class Reshape(nn.Module): def __init__(self, *args): super(Reshape, self).__init__() self.shape = args def forward(self, x): # 如果数据集最后一个batch样本数量小于定义的batch_batch
-

PyTorch中view()与 reshape()的区别详析
目录 前言 一.PyTorch中tensor的存储方式 1.PyTorch张量存储的底层原理 2.PyTorch张量的步长(stride)属性 二.对“视图(view)”字眼的理解 三.view() 和reshape() 的比较 1.对 torch.Tensor.view() 的理解 2.对 torch.reshape() 的理解 四.总结 前言 总之,两者都是用来重塑tensor的shape的.view只适合对满足连续性条件(contiguous)的tensor进行操作,而reshape同时还
-
在Pytorch中计算卷积方法的区别详解(conv2d的区别)
在二维矩阵间的运算: class torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True) 对由多个特征平面组成的输入信号进行2D的卷积操作.详解 torch.nn.functional.conv2d(input, weight, bias=None, stride=1, padding=0, dilation=1, groups=1)
-
Nginx中break与last的区别详析
先说区别 last,重写后的规则,会继续用重写后的值去匹配下面的location. break,重写后的规则,不会去匹配下面的location.使用新的规则,直接发起一次http请求了. Nginx 配置文件 server { listen 88; server_name _; location /break { # location 1 rewrite ^/break/(.*)$ /bak/$1 break; } location /last { # location 2 rewrite ^/
-
Spring中@Autowired与@Resource的区别详析
目录 一.定义 二.区别 总结 一.定义 @Autowired 对类成员变量.方法及构造函数进行标注,完成自动装配的工作. @Resource 在语义上被定义为通过其唯一的名称来标识特定的目标组件,其中声明的类型与匹配过程无关. 如果没有明确指定名称,则默认名称是从字段名称或设置方法(get.set方法)派生的. 如果用在字段上,则采用字段名称; 如果用在在setter方法,它采用其属性名称(例如setProperty()方法,取property做为属性名称). 二.区别 在Spring框架中,
-
Java中Boolean和boolean的区别详析
目录 前言 类加载机制: 对象实例化过程: 补充:Boolean与boolean性能探究 总结 前言 上次一个同学问,Boolean 类型的值不是只有 true 和 false 两种吗?为什么他定义的属性出现了 null 值? 我们应该先明确一点,boolean 是 Java 的基本数据类型,Boolean 是 Java 的一个类.boolean 类型会在“赋零值”阶段给属性赋 false.而 Boolean 是一个类,会在“赋零值”阶段给对象赋 null. 如果是静态属性,会在类加载时被赋值
-
对Pytorch中nn.ModuleList 和 nn.Sequential详解
简而言之就是,nn.Sequential类似于Keras中的贯序模型,它是Module的子类,在构建数个网络层之后会自动调用forward()方法,从而有网络模型生成.而nn.ModuleList仅仅类似于pytho中的list类型,只是将一系列层装入列表,并没有实现forward()方法,因此也不会有网络模型产生的副作用. 需要注意的是,nn.ModuleList接受的必须是subModule类型,例如: nn.ModuleList( [nn.ModuleList([Conv(inp_dim
-
基于python中staticmethod和classmethod的区别(详解)
例子 class A(object): def foo(self,x): print "executing foo(%s,%s)"%(self,x) @classmethod def class_foo(cls,x): print "executing class_foo(%s,%s)"%(cls,x) @staticmethod def static_foo(x): print "executing static_foo(%s)"%x a=A(
-
node.js中grunt和gulp的区别详解
node.js中grunt和gulp的区别详解 自nodeJS登上前端舞台,自动化构建变得越来越流行.目前最流行的当属grunt和gulp,这两个光看名字挺像,功能也差不多,不过gulp能在grunt这位大哥如日中天的境况下开辟出自己的一片天地,有着她独到的优点. 易用 Gulp相比Grunt更简洁,而且遵循代码优于配置策略,维护Gulp更像是写代码. 高效 Gulp相比Grunt更有设计感,核心设计基于Unix流的概念,通过管道连接,不需要写中间文件. 高质量 Gulp的每个插件只完成一个功能
-
基于js中this和event 的区别(详解)
今天在看javascript入门经典-事件一章中看到了 this 和 event 两种传参形式.因为作为一个初级的前端开发人员平时只用过 this传参,so很想弄清楚,this和event的区别是什么,什么情况下用什么比较合适. onclick = changeImg(this) vs onclick = changeImg(event) <img src='usa.gif' onclick="changeImg(event)" /> <scrip
-
iOS中setValue和setObject的区别详解
网上关于setValue和setObject的区别的文章很多,说的并不准确,首先我们得知道: setObject:ForKey: 是NSMutableDictionary特有的:setValue:ForKey:是KVC的主要方法 话不多说,上代码: - (void)viewDidLoad { [super viewDidLoad]; //setObject和setvalue的区别 NSMutableDictionary *dic = [NSMutableDictionary dictionary