PyTorch-GPU加速实例
硬件:NVIDIA-GTX1080
软件:Windows7、python3.6.5、pytorch-gpu-0.4.1
一、基础知识
将数据和网络都推到GPU,接上.cuda()
二、代码展示
import torch
import torch.nn as nn
import torch.utils.data as Data
import torchvision
# torch.manual_seed(1)
EPOCH = 1
BATCH_SIZE = 50
LR = 0.001
DOWNLOAD_MNIST = False
train_data = torchvision.datasets.MNIST(root='./mnist/', train=True, transform=torchvision.transforms.ToTensor(), download=DOWNLOAD_MNIST,)
train_loader = Data.DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
test_data = torchvision.datasets.MNIST(root='./mnist/', train=False)
# !!!!!!!! Change in here !!!!!!!!! #
test_x = torch.unsqueeze(test_data.test_data, dim=1).type(torch.FloatTensor)[:2000].cuda()/255. # Tensor on GPU
test_y = test_data.test_labels[:2000].cuda()
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Sequential(nn.Conv2d(in_channels=1, out_channels=16, kernel_size=5, stride=1, padding=2,),
nn.ReLU(), nn.MaxPool2d(kernel_size=2),)
self.conv2 = nn.Sequential(nn.Conv2d(16, 32, 5, 1, 2), nn.ReLU(), nn.MaxPool2d(2),)
self.out = nn.Linear(32 * 7 * 7, 10)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = x.view(x.size(0), -1)
output = self.out(x)
return output
cnn = CNN()
# !!!!!!!! Change in here !!!!!!!!! #
cnn.cuda() # Moves all model parameters and buffers to the GPU.
optimizer = torch.optim.Adam(cnn.parameters(), lr=LR)
loss_func = nn.CrossEntropyLoss()
for epoch in range(EPOCH):
for step, (x, y) in enumerate(train_loader):
# !!!!!!!! Change in here !!!!!!!!! #
b_x = x.cuda() # Tensor on GPU
b_y = y.cuda() # Tensor on GPU
output = cnn(b_x)
loss = loss_func(output, b_y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if step % 50 == 0:
test_output = cnn(test_x)
# !!!!!!!! Change in here !!!!!!!!! #
pred_y = torch.max(test_output, 1)[1].cuda().data # move the computation in GPU
accuracy = torch.sum(pred_y == test_y).type(torch.FloatTensor) / test_y.size(0)
print('Epoch: ', epoch, '| train loss: %.4f' % loss, '| test accuracy: %.2f' % accuracy)
test_output = cnn(test_x[:10])
# !!!!!!!! Change in here !!!!!!!!! #
pred_y = torch.max(test_output, 1)[1].cuda().data # move the computation in GPU
print(pred_y, 'prediction number')
print(test_y[:10], 'real number')
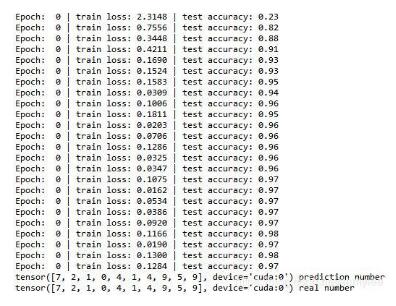
三、结果展示
补充知识:pytorch使用gpu对网络计算进行加速
1.基本要求
你的电脑里面有合适的GPU显卡(NVIDA),并且需要支持CUDA模块
你必须安装GPU版的Torch,(详细安装方法请移步pytorch官网)
2.使用GPU训练CNN
利用pytorch使用GPU进行加速方法主要就是将数据的形式变成GPU能读的形式,然后将CNN也变成GPU能读的形式,具体办法就是在后面加上.cuda()。
例如:
#如何检查自己电脑是否支持cuda print torch.cuda.is_available() # 返回True代表支持,False代表不支持 ''' 注意在进行某种运算的时候使用.cuda() ''' test_data=test_data.test_labels[:2000].cuda() ''' 对于CNN与损失函数利用cuda加速 ''' class CNN(nn.Module): ... cnn=CNN() cnn.cuda() loss_f = t.nn.CrossEntropyLoss() loss_f = loss_f.cuda()
而在train时,对于train_data训练过程进行GPU加速。也同样+.cuda()。
for epoch ..: for step, ...: 1 ''' 若你的train_data在训练时需要进行操作 若没有其他操作仅仅只利用cnn()则无需另加.cuda() ''' #eg train_data = torch.max(teain_data, 1)[1].cuda()
补充:取出数据需要从GPU切换到CPU上进行操作
eg:
loss = loss.cpu()
acc = acc.cpu()
理解并不全,如有纰漏或者错误还望各位大佬指点迷津
以上这篇PyTorch-GPU加速实例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
将Pytorch模型从CPU转换成GPU的实现方法
最近将Pytorch程序迁移到GPU上去的一些工作和思考 环境:Ubuntu 16.04.3 Python版本:3.5.2 Pytorch版本:0.4.0 0. 序言 大家知道,在深度学习中使用GPU来对模型进行训练是可以通过并行化其计算来提高运行效率,这里就不多谈了. 最近申请到了实验室的服务器来跑程序,成功将我简陋的程序改成了"高大上"GPU版本. 看到网上总体来说少了很多介绍,这里决定将我的一些思考和工作记录下来. 1. 如何进行迁移 由于我使用的是Pytorch写的模型,网上给
-
pytorch多GPU并行运算的实现
Pytorch多GPU运行 设置可用GPU环境变量.例如,使用0号和1号GPU' os.environ["CUDA_VISIBLE_DEVICES"] = '0,1' 设置模型参数放置到多个GPU上.在pytorch1.0之后的版本中,多GPU运行变得十分方便,先将模型的参数设置并行 if torch.cuda.device_count() > 1: print("Let's use", torch.cuda.device_count(), "GPU
-
关于pytorch多GPU训练实例与性能对比分析
以下实验是我在百度公司实习的时候做的,记录下来留个小经验. 多GPU训练 cifar10_97.23 使用 run.sh 文件开始训练 cifar10_97.50 使用 run.4GPU.sh 开始训练 在集群中改变GPU调用个数修改 run.sh 文件 nohup srun --job-name=cf23 $pt --gres=gpu:2 -n1 bash cluster_run.sh $cmd 2>&1 1>>log.cf50_2GPU & 修改 –gres=gpu:
-
pytorch使用指定GPU训练的实例
本文适合多GPU的机器,并且每个用户需要单独使用GPU训练. 虽然pytorch提供了指定gpu的几种方式,但是使用不当的话会遇到out of memory的问题,主要是因为pytorch会在第0块gpu上初始化,并且会占用一定空间的显存.这种情况下,经常会出现指定的gpu明明是空闲的,但是因为第0块gpu被占满而无法运行,一直报out of memory错误. 解决方案如下: 指定环境变量,屏蔽第0块gpu CUDA_VISIBLE_DEVICES = 1 main.py 这句话表示只有第1块
-
pytorch多进程加速及代码优化方法
目标:优化代码,利用多进程,进行近实时预处理.网络预测及后处理: 本人尝试了pytorch的multiprocessing,进行多进程同步处理以上任务. from torch.multiprocessing import Pool,Manager 为了进行各进程间的通信,使用Queue,作为数据传输载体. manager = Manager() input_queue = manager.Queue() output_queue = manager.Queue() show_queue = ma
-

Python3实现打格点算法的GPU加速实例详解
目录 技术背景 打格点算法实现 打格点算法加速 总结概要 技术背景 在数学和物理学领域,总是充满了各种连续的函数模型.而当我们用现代计算机的技术去处理这些问题的时候,事实上是无法直接处理连续模型的,绝大多数的情况下都要转化成一个离散的模型再进行数值的计算.比如计算数值的积分,计算数值的二阶导数(海森矩阵)等等.这里我们所介绍的打格点的算法,正是一种典型的离散化方法.这个对空间做离散化的方法,可以在很大程度上简化运算量.比如在分子动力学模拟中,计算近邻表的时候,如果不采用打格点的方法,那么就要针对
-
PyTorch-GPU加速实例
硬件:NVIDIA-GTX1080 软件:Windows7.python3.6.5.pytorch-gpu-0.4.1 一.基础知识 将数据和网络都推到GPU,接上.cuda() 二.代码展示 import torch import torch.nn as nn import torch.utils.data as Data import torchvision # torch.manual_seed(1) EPOCH = 1 BATCH_SIZE = 50 LR = 0.001 DOWNLOA
-
Python基于pyCUDA实现GPU加速并行计算功能入门教程
本文实例讲述了Python基于pyCUDA实现GPU加速并行计算功能.分享给大家供大家参考,具体如下: Nvidia的CUDA 架构为我们提供了一种便捷的方式来直接操纵GPU 并进行编程,但是基于 C语言的CUDA实现较为复杂,开发周期较长.而python 作为一门广泛使用的语言,具有 简单易学.语法简单.开发迅速等优点.作为第四种CUDA支持语言,相信python一定会 在高性能计算上有杰出的贡献–pyCUDA. pyCUDA特点 CUDA完全的python实现 编码更为灵活.迅速.自适应调节
-
关于Python的GPU编程实例近邻表计算的讲解
目录 技术背景 加速场景 基于Numba的GPU加速 总结概要 技术背景 GPU加速是现代工业各种场景中非常常用的一种技术,这得益于GPU计算的高度并行化.在Python中存在有多种GPU并行优化的解决方案,包括之前的博客中提到的cupy.pycuda和numba.cuda,都是GPU加速的标志性Python库.这里我们重点推numba.cuda这一解决方案,因为cupy的优势在于实现好了的众多的函数,在算法实现的灵活性上还比较欠缺:而pycuda虽然提供了很好的灵活性和相当高的性能,但是这要求
-
解决pytorch GPU 计算过程中出现内存耗尽的问题
Pytorch GPU运算过程中会出现:"cuda runtime error(2): out of memory"这样的错误.通常,这种错误是由于在循环中使用全局变量当做累加器,且累加梯度信息的缘故,用官方的说法就是:"accumulate history across your training loop".在默认情况下,开启梯度计算的Tensor变量是会在GPU保持他的历史数据的,所以在编程或者调试过程中应该尽力避免在循环中累加梯度信息. 下面举个栗子: 上代
-
Pytorch: 自定义网络层实例
自定义Autograd函数 对于浅层的网络,我们可以手动的书写前向传播和反向传播过程.但是当网络变得很大时,特别是在做深度学习时,网络结构变得复杂.前向传播和反向传播也随之变得复杂,手动书写这两个过程就会存在很大的困难.幸运地是在pytorch中存在了自动微分的包,可以用来解决该问题.在使用自动求导的时候,网络的前向传播会定义一个计算图(computational graph),图中的节点是张量(tensor),两个节点之间的边对应了两个张量之间变换关系的函数.有了计算图的存在,张量的梯度计算也
-
Pytorch GPU显存充足却显示out of memory的解决方式
今天在测试一个pytorch代码的时候显示显存不足,但是这个网络框架明明很简单,用CPU跑起来都没有问题,GPU却一直提示out of memory. 在网上找了很多方法都行不通,最后我想也许是pytorch版本的问题,原来我的pytorch版本是0.4.1,于是我就把这个版本卸载,然后安装了pytorch1.1.0,程序就可以神奇的运行了,不会再有OOM的提示了.虽然具体原因还不知道为何,这里还是先mark一下,具体过程如下: 卸载旧版本pytorch: conda uninstall pyt
-
已安装tensorflow-gpu,但keras无法使用GPU加速的解决
问题 我们使用anoconda创建envs环境下的Tensorflow-gpu版的,但是当我们在Pycharm设置里的工程中安装Keras后,发现调用keras无法使用gpu进行加速,且使用的是cpu在运算,这就违背了我们安装Tensorflow-gpu版初衷了. 原因 因为我们同时安装了tensorflow和tensorflow-gpu(在-Anaconda3\envs\fyy_tf\Lib\site-packages中可以找到他们的文件夹),使用keras时会默认调用tensorflow,从