Python-opencv实现红绿两色识别操作
1.颜色空间转换(RGB转HSV)
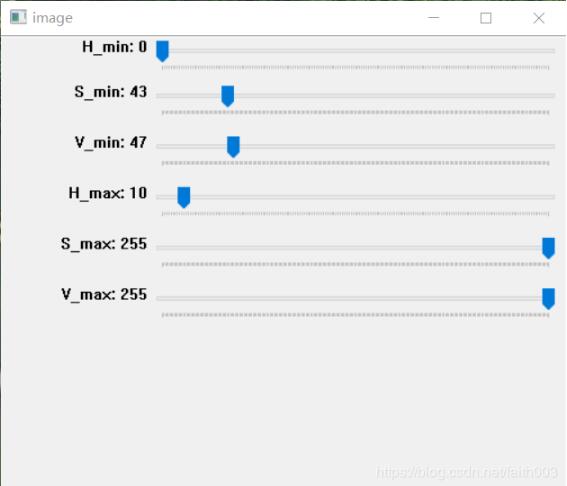
为了较准确的调红色和绿色的HSV,我使用cv2.createTrackbar()函数创建了六个滚动条
#创建HSV最低滚动条
cv2.createTrackbar('H_min','image',35,180,nothing)
cv2.createTrackbar('S_min','image',43,255,nothing)
cv2.createTrackbar('V_min','image',46,255,nothing)
#创建HSV最高滚动条
cv2.createTrackbar('H_max','image',0,180,nothing)
cv2.createTrackbar('S_max','image',255,255,nothing)
cv2.createTrackbar('V_max','image',255,255,nothing)
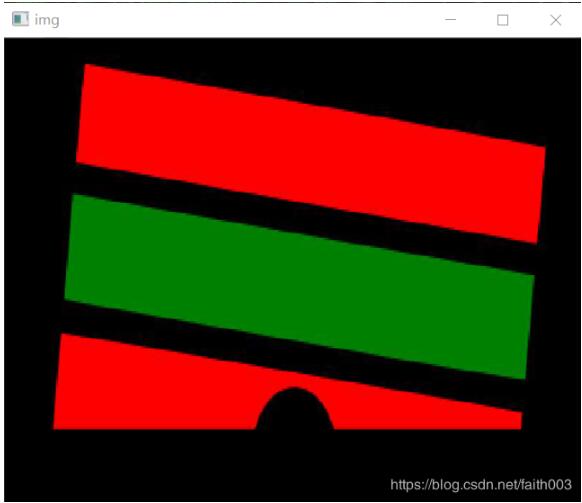
实际效果如图
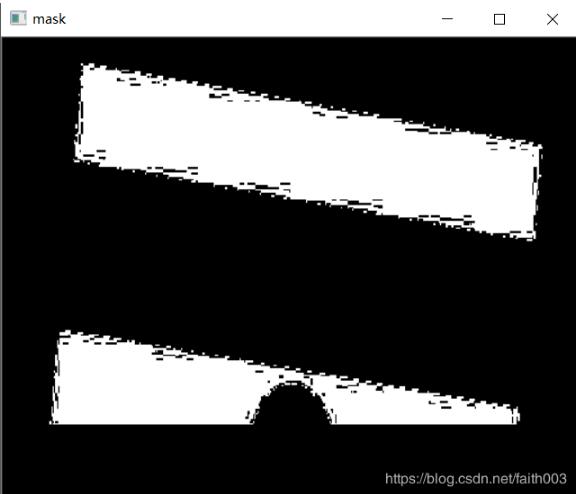
2.识别颜色并画矩形框
颜色阈值已经确定了,这就可以进行颜色识别了。
为了让识别更稳定,在代码中加入自适应阈值。
th_img = cv2.adaptiveThreshold(mask,255,cv2.ADAPTIVE_THRESH_MEAN_C,cv2.THRESH_BINARY_INV,5,2)
3.画矩形框
使用函数cv2.findContours()来检测物体轮框
再使用函数cv2.boundingRect()查找最小矩形框
使用函数cv2.rectangle()画出
contours_green,hierarchy = cv2.findContours(th_green,cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_SIMPLE) contours_red,hierarchy = cv2.findContours(th_red,cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_SIMPLE) for red in contours_red: x_red,y_red,w_red,h_red = cv2.boundingRect(red) if w_red>width|h_red>height: cv2.rectangle(img,(x_red,y_red),((x_red+h_red),(y_red+w_red)),(0,255,0),1) for red in contours_red: x_red,y_red,w_red,h_red = cv2.boundingRect(red) if w_red>width|h_red>height: cv2.rectangle(img,(x_red,y_red),((x_red+h_red),(y_red+w_red)),(0,255,0),1)
为了凸显出颜色的差距,我使用绿色的矩形框,画红色的物体,用红色的矩形框画绿色物体
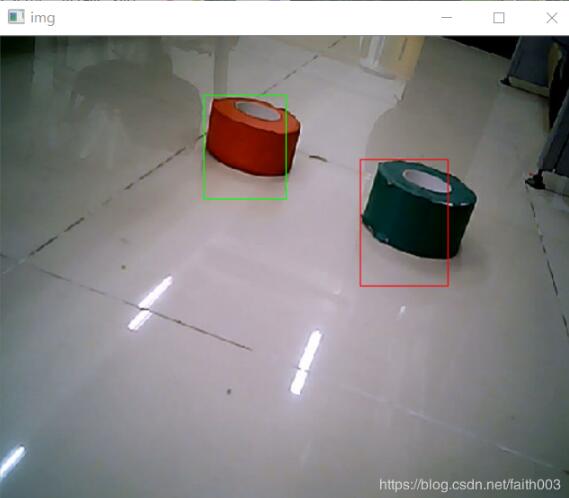
以上这篇Python-opencv实现红绿两色识别操作就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

Python Opencv实现图像轮廓识别功能
本文实例为大家分享了python opencv识别图像轮廓的具体代码,供大家参考,具体内容如下 要求:用矩形或者圆形框住图片中的云朵(不要求全部框出) 轮廓检测 Opencv-Python接口中使用cv2.findContours()函数来查找检测物体的轮廓. import cv2 img = cv2.imread('cloud.jpg') # 灰度图像 gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 二值化 ret, binary = cv2.th
-
python+opencv实现动态物体识别
注意:这种方法十分受光线变化影响 自己在家拿着手机瞎晃的成果图: 源代码: # -*- coding: utf-8 -*- """ Created on Wed Sep 27 15:47:54 2017 @author: tina """ import cv2 import numpy as np camera = cv2.VideoCapture(0) # 参数0表示第一个摄像头 # 判断视频是否打开 if (camera.isOpened()
-
Python+Opencv识别两张相似图片
在网上看到python做图像识别的相关文章后,真心感觉python的功能实在太强大,因此将这些文章总结一下,建立一下自己的知识体系. 当然了,图像识别这个话题作为计算机科学的一个分支,不可能就在本文简单几句就说清,所以本文只作基本算法的科普向. 看到一篇博客是介绍这个,但他用的是PIL中的Image实现的,感觉比较麻烦,于是利用Opencv库进行了更简洁化的实现. 相关背景 要识别两张相似图像,我们从感性上来谈是怎么样的一个过程?首先我们会区分这两张相片的类型,例如是风景照,还是人物照.风景照中
-
python+OpenCV实现车牌号码识别
基于python+OpenCV的车牌号码识别,供大家参考,具体内容如下 车牌识别行业已具备一定的市场规模,在电子警察.公路卡口.停车场.商业管理.汽修服务等领域已取得了部分应用.一个典型的车辆牌照识别系统一般包括以下4个部分:车辆图像获取.车牌定位.车牌字符分割和车牌字符识别 1.车牌定位的主要工作是从获取的车辆图像中找到汽车牌照所在位置,并把车牌从该区域中准确地分割出来 这里所采用的是利用车牌的颜色(黄色.蓝色.绿色) 来进行定位 #定位车牌 def color_position(img,ou
-
Python-opencv实现红绿两色识别操作
1.颜色空间转换(RGB转HSV) 为了较准确的调红色和绿色的HSV,我使用cv2.createTrackbar()函数创建了六个滚动条 #创建HSV最低滚动条 cv2.createTrackbar('H_min','image',35,180,nothing) cv2.createTrackbar('S_min','image',43,255,nothing) cv2.createTrackbar('V_min','image',46,255,nothing) #创建HSV最高滚动条 cv2.
-
Python+Opencv身份证号码区域提取及识别实现
前端时间智能信息处理实训,我选择的课题为身份证号码识别,对中华人民共和国公民身份证进行识别,提取并识别其中的身份证号码,将身份证号码识别为字符串的形式输出.现在实训结束了将代码发布出来供大家参考,识别的方式并不复杂,并加了一些注释,如果有什么问题可共同讨论.最后重要的事情说三遍:请勿直接抄袭,请勿直接抄袭,请勿直接抄袭!尤其是我的学弟学妹们,还是要自己做的,小心直接拿我的用被老师发现了挨批^_^. 实训环境:CentOS-7.5.1804 + Python-3.6.6 + Opencv-3.4.
-
Python OpenCV超详细讲解调整大小与图像操作的实现
目录 准备工作 重新调整图像大小 图像裁剪 准备工作 右击新建的项目,选择Python File,新建一个Python文件,然后在开头import cv2导入cv2库. 我们还要知道在OpenCV中,坐标轴的方向是x轴向右,y轴向下,坐标原点在左上角,比如下面这张长为640像素,宽为480像素的图片.OK,下面开始本节的学习吧. 查看图像大小 调用imread()方法获取我们资源文件夹中的图片lambo.png 输出图像的shape属性 img=cv2.imread("Resources/lam
-
python+opencv像素的加减和加权操作的实现
本文介绍了python+opencv像素的加减和加权操作的实现,分享给大家. # 目标: # 1.在图像上进行算术操作,如加减以及按位操作 # 2.将会学会使用cv2.add(),cv2.addWeights() # 参考网站:https://docs.opencv.org/3.0-beta/doc/py_tutorials/py_core/py_image_arithmetics/py_image_arithmetics.html#image-arithmetics import numpy
-
Python OpenCV中的numpy与图像类型转换操作
Python OpenCV存储图像使用的是Numpy存储,所以可以将Numpy当做图像类型操作,操作之前还需进行类型转换,转换到int8类型 import cv2 import numpy as np # 使用numpy方式创建一个二维数组 img = np.ones((100,100)) # 转换成int8类型 img = np.int8(img) # 颜色空间转换,单通道转换成多通道, 可选可不选 img = cv2.cvtColor(img, cv2.COLOR_GRAY2BGR) cv2
-
Python+OpenCV实现车牌字符分割和识别
最近做一个车牌识别项目,入门级别的,十分简单. 车牌识别总体分成两个大的步骤: 一.车牌定位:从照片中圈出车牌 二.车牌字符识别 这里只说第二个步骤,字符识别包括两个步骤: 1.图像处理 原本的图像每个像素点都是RGB定义的,或者称为有R/G/B三个通道.在这种情况下,很难区分谁是背景,谁是字符,所以需要对图像进行一些处理,把每个RGB定义的像素点都转化成一个bit位(即0-1代码),具体方法如下: ①将图片灰度化 名字拗口,但是意思很好理解,就是把每个像素的RGB都变成灰色的RGB值,而灰色的
-
python+opencv识别图片中的圆形
本文实例为大家分享了python+opencv识别图片中足球的方法,供大家参考,具体内容如下 先补充下霍夫圆变换的几个参数知识: dp,用来检测圆心的累加器图像的分辨率于输入图像之比的倒数,且此参数允许创建一个比输入图像分辨率低的累加器.上述文字不好理解的话,来看例子吧.例如,如果dp= 1时,累加器和输入图像具有相同的分辨率.如果dp=2,累加器便有输入图像一半那么大的宽度和高度. minDist,为霍夫变换检测到的圆的圆心之间的最小距离,即让我们的算法能明显区分的两个不同圆之间的最小距离.这
-
python opencv将表格图片按照表格框线分割和识别
如下小程序为使用python+opencv将表格图片,按照表格进行分割,并识别分割后的子图片中的文字,希望对需要的小伙伴有一些些帮助.具体的实现见如下代码. # -*- coding: utf-8 -*- """ Created on Tue May 28 19:23:19 2019 将图片按照表格框线交叉点分割成子图片(传入图片路径) @author: hx """ import cv2 import numpy as np import py