pandas 像SQL一样使用WHERE IN查询条件说明
in
newDropList = [9,10,11,12,22,50,51,60,61]
newDB = newDB[newDB['groupId'].isin(newDropList)]
直接查询表中groupId列,值为newDropList的记录
not in
newDropList = [9,10,11,12,22,50,51,60,61]
newDB = newDB[-newDB['groupId'].isin(newDropList)]
直接加一个" - " 号即可
补充知识:pandas条件组合筛选和按范围筛选
1、从记录中选出所有fault_code列的值在fault_list= [487, 479, 500, 505]这个范围内的记录
record2=record[record['FAULT_CODE'].isin(fault_list)]
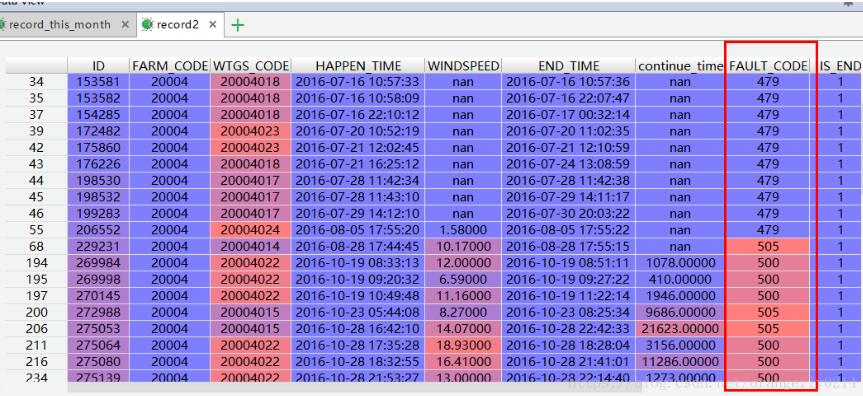
要用.isin 而不能用in,用 in以后选出来的值都是True 和False,然后报错:
ValueError: The truth value of a Series is ambiguous. Use a.empty, a.bool(), a.item(), a.any()
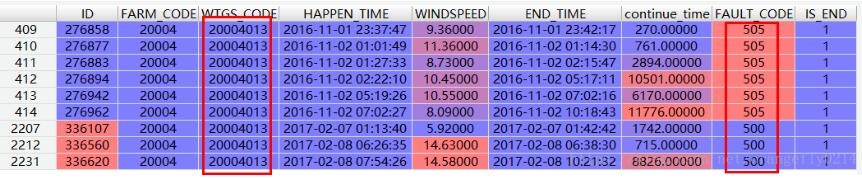
2、选出所有WTGS_CODE=20004013的记录
set=20004013
record= record[record['WTGS_CODE'] == set]

3、其次,从记录中选出所有满足set条件且fault_code列的值在fault_list= [487, 479, 500, 505]这个范围内的记录
record_this_month=record[(record['WTGS_CODE']==set)&(record['FAULT_CODE'].isin(fault_list))]
(1)多个条件筛选的时候每个条件都必须加括号。
(2)判断值是否在某一个范围内进行筛选的时候需要使用DataFrame.isin()的isin()函数,而不能使用in。
以上这篇pandas 像SQL一样使用WHERE IN查询条件说明就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
pandas数据处理基础之筛选指定行或者指定列的数据
pandas主要的两个数据结构是:series(相当于一行或一列数据机构)和DataFrame(相当于多行多列的一个表格数据机构). 本文为了方便理解会与excel或者sql操作行或列来进行联想类比 1.重新索引:reindex和ix 上一篇中介绍过数据读取后默认的行索引是0,1,2,3...这样的顺序号.列索引相当于字段名(即第一行数据),这里重新索引意思就是可以将默认的索引重新修改成自己想要的样子. 1.1 Series 比方说:data=Series([4,5,6],index=['a',
-
pandas按若干个列的组合条件筛选数据的方法
还是用图说话 A文件: 比如,我想筛选出"设计井别"."投产井别"."目前井别"三列数据都为11的数据,结果如下: 当然,这里的筛选条件可以根据用户需要自由调整,代码如下: # -*- coding: utf-8 -*- """ Created on Wed Nov 29 10:46:31 2017 @author: wq """ import pandas as pd #input.c
-
python中数据库like模糊查询方式
在Python中%是一个格式化字符,所以如果需要使用%则需要写成%%. 将在Python中执行的sql语句改为: sql = "SELECT * FROM table_test WHERE value LIKE '%%%%%s%%%%'" % test_value 执行成功,print出SQL语句之后为: SELECT * FROM table_test WHERE value LIKE '%%public%%' Python在执行sql语句的时候,同样也会有%格式化的问题,仍然需要使
-
pandas.DataFrame 根据条件新建列并赋值的方法
实例如下所示: import numpy as np import pandas as pd data = {'city': ['Beijing', 'Shanghai', 'Guangzhou', 'Shenzhen', 'Hangzhou', 'Chongqing'], 'year': [2016,2016,2015,2017,2016, 2016], 'population': [2100, 2300, 1000, 700, 500, 500]} frame = pd.DataFrame(
-
pandas 像SQL一样使用WHERE IN查询条件说明
in newDropList = [9,10,11,12,22,50,51,60,61] newDB = newDB[newDB['groupId'].isin(newDropList)] 直接查询表中groupId列,值为newDropList的记录 not in newDropList = [9,10,11,12,22,50,51,60,61] newDB = newDB[-newDB['groupId'].isin(newDropList)] 直接加一个" - " 号即可 补充知
-

浅述SQL Server的聚焦强制索引查询条件和Columnstore Index
前言 本节我们再来穿插讲讲索引知识,后续再讲数据类型中的日期类型,简短的内容,深入的理解. 强制索引查询条件 前面我们也讲了一点强制索引查询的知识,本节我们再来完整的讲述下 (1)SQL Server使用默认索引 USE TSQL2012 GO SELECT * FROM Sales.Orders 上述就不用我再啰嗦了,使用默认主键创建的聚集索引来执行查询执行计划. (2)SQL Server使用强制索引 USE TSQL2012 GO SELECT custid FROM Sales.Orde
-
pandas中read_sql使用参数进行数据查询的实现
目录 一.之前的处理方法 二.使用 read_sql 中的 params 传入参数 1.文档说明 2.具体的使用 三.总结对比 四.字符串的格式化 pandas.read_sql 可以在数据库中执行指定的SQL语句查询或对指定的整张表进行查询,以DataFrame 的类型返回查询结果,这是在跟数据库进行交互操作时很重要的一步——既读取数据,还返回DataFrame方便处理. 要解决的问题: 编写过的SQL语句需要重复使用,这就涉及到参数,使用参数来替换条件,然后根据需要替换参数. 一.之前的处理
-
用非动态SQL Server SQL语句来对动态查询进行执行
此文章主要向大家讲述的是非动态SQL ServerSQL语句执行动态查询,在实际操作中我尝试在一个存储过程中,来进行传递一系列以逗号划定界限的值,来对结果集进行限制.但是无论什么时候,我在IN子句中使用变量,都会得到错误信息. 是否存在一种不执行动态SQL语句也能完成查询的方式呢? 我尝试在一个存储过程中传递一系列以逗号划定界限的值,以限制结果集.但是无论什么时候,我在IN子句中使用变量,都会得到错误信息.是否存在一种不执行动态SQL ServerSQL语句也能完成查询的方式呢? 专家解答: 这
-
SQL 复合查询条件(AND,OR,NOT)对NULL值的处理方法
NULL值影响查询条件的结果,并且结果很微妙. 以下是SQL中AND,OR,NOT的真值表. 表1 AND的真值表 TRUE FALSE NULL TRUE TRUE FALSE NULL FALSE FALSE FALSE FALSE NULL NULL FALSE NULL 表2 OR的真值表 TRUE FALSE NULL TRUE TRUE TRUE TRUE FALSE TRUE F
-
使用SQL Server数据库嵌套子查询的方法
很多SQL Server程序员对子查询(subqueries)的使用感到困惑,尤其对于嵌套子查询(即子查询中包含一个子查询).现在,就让我们追本溯源地探究这个问题. 有两种子查询类型:标准和相关.标准子查询执行一次,结果反馈给父查询.相关子查询每行执行一次,由父查询找回.在本文中,我将重点讨论嵌套子查询(nested subqueries)(我将在以后介绍相关子查询). 试想这个问题:你想生成一个卖平垫圈的销售人员列表.你需要的数据分散在四个表格中:人员.联系方式(Person.Contac
-
浅谈SQL Server中统计对于查询的影响分析
而每次查询分析器寻找路径时,并不会每一次都去统计索引中包含的行数,值的范围等,而是根据一定条件创建和更新这些信息后保存到数据库中,这也就是所谓的统计信息. 如何查看统计信息 查看SQL Server的统计信息非常简单,使用如下指令: DBCC SHOW_STATISTICS('表名','索引名') 所得到的结果如图1所示. 图1.统计信息 统计信息如何影响查询 下面我们通过一个简单的例子来看统计信息是如何影响查询分析器.我建立一个测试表,有两个INT值的列,其中id为自增,ref上建立非聚集索引
-
SQL Server数据库按百分比查询出表中的记录数
SQL Server数据库查询时,能否按百分比查询出记录的条数呢?答案是肯定的.本文我们就介绍这一实现方法. 实现该功能的代码如下: create procedure pro_topPercent ( @ipercent [int] =0 --默认不返回 ) as begin select top (@ipercent ) percent * from books end 或 create procedure pro_topPercent ( @ipercent [int] =0 ) as be
-
SQL Server 2008数据库分布式查询知识
在接触公司一个系统时,公司使用的是SQL Server 2008数据库,里面涉及到了多个数据库之间的查询,而且数据库是分布式的,数据库分布在多台服务器之间,并且各个数据库各尽其责,负责存放不同模块功能的数据.这里面就要涉及到了数据库的分布式查询. 补充一下分布式查询的知识: 分布式查询从多异类数据源中访问数据.这些数据源可以存储在同一台计算机或不同的计算机上.Microsoft SQL Server 通过使用 OLE DB 来支持分布式查询. SQL Server 用户可以使用分布式查询访问以下
-
Orancle的SQL语句之多表查询和组函数
一.SQL的多表查询: 1.左连接和右连接(不重要一方加(+)) SELECT e.empno,e.ename,d.deptno,d.dname,d.loc FROM emp e,dept d WHERE e.deptno(+)=d.deptno ; (+)在等号左边是右连接,反之左连接. 2.交叉连接 (CROSS JOIN产生笛卡尔积) SELECT * FROM emp CROSS JOIN dept ; 3.自然连接 (NATURAL JOIN)自动关联字段匹配 SELECT * FRO