服务器中TIME_WAIT状态过多时的排查分析
目录
- 一、概述
- (一)现象
- (二)相关知识
- 二、问题推测
- (一)网络
- (二)应用
- 三、排查
- (一)TCP连接上的IP
- 1.下图是容器的IP
- 2.下图是连接中本地的IP
- 3.下图是连接本地API项目的主动IP
- 4.下图是连接中外地的IP
- 5.下图是展示到底是对请求了API的web前端nginx
- (二)宿主机上的容器
- 1.应用和网络的关系
一、概述
(一)现象
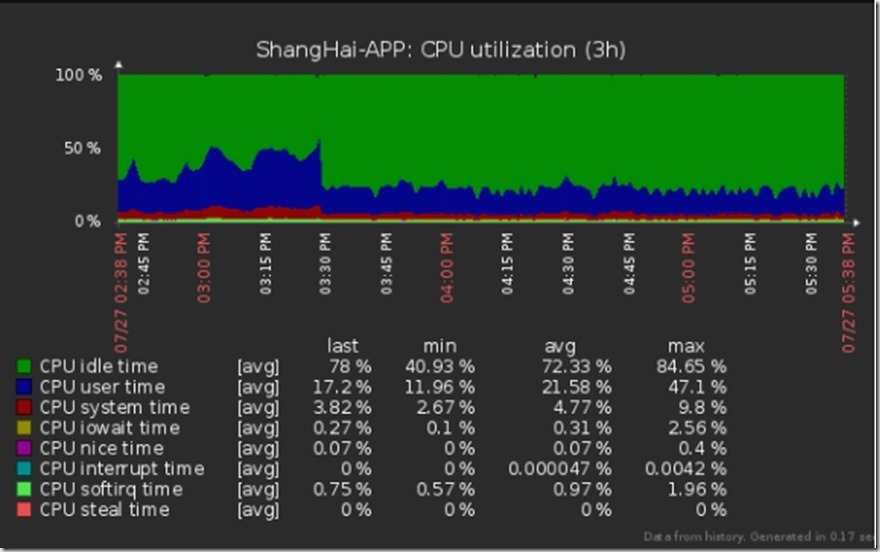
服务器有两个现象,第一是tcp连接数不多,不超过10个,但是time_wait状态的2000。第二个按照以往的性质,在很少用户访问的情况下,服务器的资源几乎没有使用,比如CPU,不超过5%。现在没有什么用户的的情况下,CPU损耗坚持在40%左右,夜间也不停歇。里面运行着好几个web项目,都用docker启动的容器分开。


(二)相关知识
tcp连接有3次握手,断开有四次挥手。
三次握手中第一次,是主动端发出SYN信号给正在listen的被动端,然后自己变成了SYN-SENT状态;第二次是被动端发送ACK确认收到信号和SYN信号;第三次是主动端发出ACK信号确认已经收到了被动端的SYN。然后双双进入了enblished状态,便是已经连接成功。
四次挥手中的第一次就是主动端断开,发送FIN信号,变成FIN-WAIT-1状态;第二次是被动方收到FIN信号,就变成CLOSE-WAIT状态,然后赶紧发送ACK信号给主动方确认,这是时候主动方变为FIN-WAIT-2状态;第三次还是被动方等自己的应用断开连接的时候,发送FIN信号给主动方,被动方的状态变成LAST-ACK;第四次是主动方收到被动方的FIN信号,然后发送的ACK信号,瞬间自己变成TIME-WAIT状态,然后等待回收。
就是说,谁有TIME-WAIT,谁就是主动方。这点可以排除用户频繁关闭网页的可能。意思就是说这都是服务器主动请求断开连接的,而TIME-WAIT状态的链接也没有回收。
二、问题推测
(一)网络
网络上面的就是网络不好,或者被攻击。
(二)应用
中间件的参数不对,导致有中间件断开的连接,或者应用程序错误造成的主动断开连接。或者也是应用方面导致消耗资源太多。
三、排查
这个服务器有三个项目,每个项目的架构都是lanmp。问题复杂在于服务器里面好几个项目,每个项目用都一个反向代理。好的一点是后端是docker容器,分开的。
(一)TCP连接上的IP
1.下图是容器的IP
命令:
for i in $(docker ps|awk 'NR!=1 {print $NF}');do echo -e $i "\c";docker inspect --format '{{ .NetworkSettings.IPAddress }}' $i;done

2.下图是连接中本地的IP
命令:
netstat -tn|grep TIME_WAIT|awk '{print $4}'|sort|uniq -c|sort -nr|head
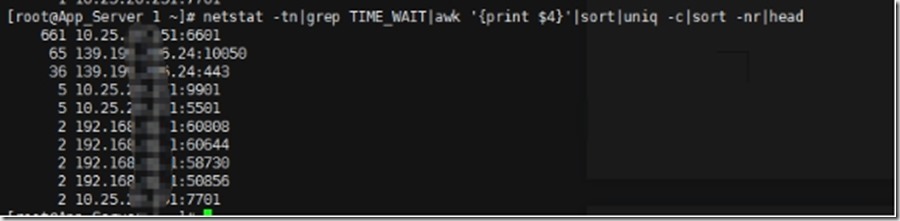
排名第一这个是我们本地IP,6601是api项目的监听端口,从这里可以看出在所欲的TIME_WAIT状态的TCP里面,API项目的后端是被请求最多的那个。估计反向代理服务器也被请求了很多。
3.下图是连接本地API项目的主动IP
命令:
netstat -ant|grep 10.25.20.251:6601
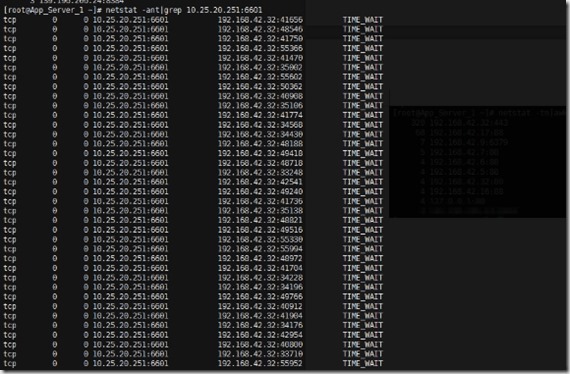
途中可以看出,请求连接API后端的全部都是nginx的IP,这也很容易理解,nginx反向代理是入口嘛。下面就看看到底是谁对nginx发出请求。
4.下图是连接中外地的IP
命令:netstat -tn|awk '{print $5}'|sort|uniq -c|sort -nr|head

对API的请求是600,对nginx的请求是300,说明所有的TIME-WAIT,一部分是请求nginx的,一部分是nginx请求API的。
5.下图是展示到底是对请求了API的web前端nginx
命令:netstat -ant|grep 192.168.42.32:443
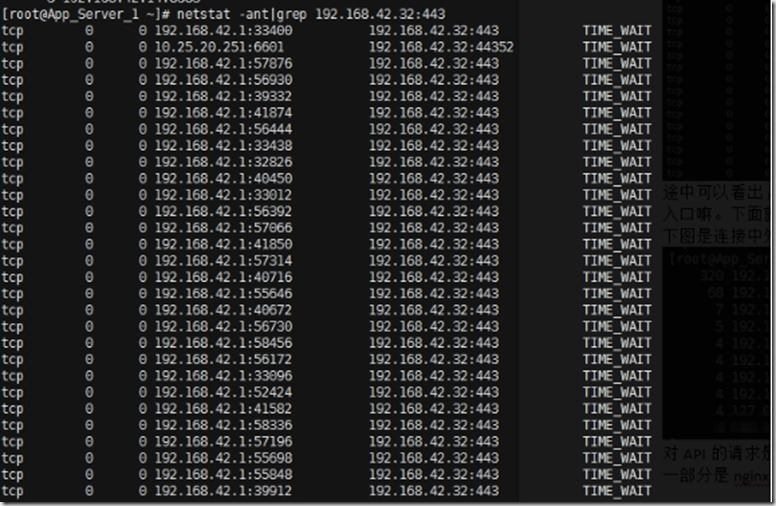
原来是192.168.42.1这个IP的请求。其实192.168.42.1这个IP是docker的虚拟网卡的IP,作为全部容器的网关,也就是说反正这就是这些容器发出的请求,但是不能确定是哪一个。
综上所述,可以排除网络问题,中间件apache的参数没有改,但是对web前端nginx的请求那么多,可以说明问题不是出现在apache的请求上面。那就往代码错误方面考虑。
(二)宿主机上的容器
1.应用和网络的关系

可能TIME-WAIT的问题就是后端程序乱发请求,apache是主项目的后端容器,apache-api就是api的后端程序。webserver占用的CPU上升,刚好就说明容器使用的系统资源就是由这种请求引起的。下面用tail看看api的access日志。

实时监测,发现API一秒钟被请求12次左右,根据业务性质和docker的状态显示,可以断定是主项目的循环请求造成的系统资源内耗。而每次请求API项目就返回了access_token,API返回数据之后就发出断开信号,逻辑和现象很符合,也可以断定TIME_WAIT的状态也是这请求引起。而TIME_WAIT不是不回收,而是回收了,但不断的生成。
以上就是服务器中TIME_WAIT状态过多时的排查分析的详细内容,更多关于服务器TIME_WAIT状态过多排查的资料请关注我们其它相关文章!
相关推荐
-
解决linux下大量TIME WAIT的方法详解
问题描述:在Linux系统中高并发的Squid服务器,TCP TIME_WAIT套接字数量经常达到两.三万,服务器很容易被拖死.解决方法:通过修改Linux内核参数,可以减少linux服务器的IME_WAIT套接字数量.vi /etc/sysctl.conf增加以下几行: 复制代码 代码如下: net.ipv4.tcp_fin_timeout = 30net.ipv4.tcp_keepalive_time = 1200net.ipv4.tcp_syncookies = 1net.ipv4.tcp
-
apache time_wait连接数太多问题解决方法
最近发现apache与负载均衡器的的连接数过多,而且大部分都是time_wait,调整apache2.conf后也没效果. 通过调整内核参数解决: 复制代码 代码如下: vi /etc/sysctl.conf 编辑文件,加入以下内容: 复制代码 代码如下: net.ipv4.tcp_syncookies = 1 net.ipv4.tcp_tw_reuse = 1 net.ipv4.tcp_tw_recycle = 1 net.ipv4.tcp_fin_timeout = 30 然后,执行 /sb
-
解决time_wait强制关闭socket
解决time_wait 今天我在测试代码的时候,边开边看电影,服务端的CPU消耗和内存使用让我挺满意的 可是过了一会,在统计达到了一定连接后,后来连接很多无法登陆.象上公交车,拥 挤不堪无法上车,用netstat -an查看了下连接状态,time_wait状态的端口非常多 原因就在此了,消耗完系统的端口数,服务端将就无法接收新连接,找到问题就来说明 time_wait,这个东西默认存活时间为2分钟,够长的,这点很要命,更多的大家百度下 对付这个问题,我写了一个函数,强制关闭socket,代码环境
-
探讨如何减少Linux服务器TIME_WAIT过多的问题
TIME_WAIT状态的意义: 客户端与服务器端建立TCP/IP连接后关闭SOCKET后,服务器端连接的端口状态为TIME_WAIT是不是所有执行主动关闭的socket都会进入TIME_WAIT状态呢?有没有什么情况使主动关闭的socket直接进入CLOSED状态呢?主动关闭的一方在发送最后一个 ack 后就会进入 TIME_WAIT 状态 停留2MSL(max segment lifetime)时间,这个是TCP/IP必不可少的,也就是"解决"不了的.也就是TCP/IP设计者本来是这
-

分析从Linux源码看TIME_WAIT的持续时间
目录 一.前言 二.首先介绍下Linux环境 三.TIME_WAIT状态转移图 四.持续时间真如TCP_TIMEWAIT_LEN所定义么? 五.TIME_WAIT定时器源码 5.1.inet_twsk_schedule 5.2.具体的清理函数 5.3.先作出一个假设 5.4.如果一个slot中的TIME_WAIT<=100 5.5.如果一个slot中的TIME_WAIT>100 5.6.PAWS(Protection Against Wrapped Sequences)使得TIME_WAIT延
-
服务器中TIME_WAIT状态过多时的排查分析
目录 一.概述 (一)现象 (二)相关知识 二.问题推测 (一)网络 (二)应用 三.排查 (一)TCP连接上的IP 1.下图是容器的IP 2.下图是连接中本地的IP 3.下图是连接本地API项目的主动IP 4.下图是连接中外地的IP 5.下图是展示到底是对请求了API的web前端nginx (二)宿主机上的容器 1.应用和网络的关系 一.概述 (一)现象 服务器有两个现象,第一是tcp连接数不多,不超过10个,但是time_wait状态的2000.第二个按照以往的性质,在很少用户访问的情况下,
-
游戏服务器中的Netty应用以及源码剖析
目录 一.Reactor模式和Netty线程模型 1. BIO模型 2. NIO模型 3. Reacor模型 ①. 单Reacor单线程模型 ②. 单Reactor多线程模型 ③. 主从Reactor多线程模型 ④. 部分源码分析 二.select/poll和epoll 1.概念 2.jdk提供selector 3.Netty提供的Epoll封装 4.Netty相关类图 5.配置Netty为EpollEventLoop 三.Netty相关参数 1.SO_KEEPALIVE 2.SO_REUSEA
-
CentOS7服务器中apache、php7以及mysql5.7的安装配置代码
CentOS7服务器中apache.php7以及mysql5.7的配置代码如下所示: yum upgrade yum install net-tools 安装apache 关闭SELinux 编辑器打开 etc/selinux/config 文件,找到 SELINUX=enforcing 字段,将其改成 SELINUX=disabled ,并重启设备. yum -y install httpd mod_ssl 配置防火墙 firewall-cmd --permanent --add-port=8
-
ASP.NET中Cookie状态的说明与用法
Cookie 最早出现是在Netscape Navigator 2.0 中.后来 ASP 也引入了这个技术,它的作用是与 Session 对象相结合来识别用户.每当用户开始连接站点时,系统将自动在内存块中创建一个用户有关的会话状态,同时创建一个用户的 ID 存放在浏览器端,与当前的用户惟一地联系起来.这样,服务器保存了 Session,浏览器保存了 Cookie(用户的 ID).当下一次用户发出请求时,请求的用户将被要求提交用户的 ID,两者对照以正确地还原原来的会话状态.这就是在无状态协议的
-
如何在 Netware 服务器中安装多块网卡
如果网络在扩大时服务器只装一块网卡.所有工作站采用总线结构上网,那么访问速度会很慢.另外,如果上网时某台工作站出了故障,所有的工作站都受其影响,不能工作. 我们可以在服务器中安装多块网卡来解决问题.这样,服务器不但工作稳定,工作站上网速度会大幅度提高,而且若有工作站出现故障,只会影响与该工作站共用一块网卡的那些工作站,使用其它网卡的工作站却不受影响.本文以在NetWare服务器安装3块网卡为例. 安装与设置 准备好要安装的网卡(型号最好相同,不同亦可,但必须与NE2000兼容),先把一块网卡插入
-
Nginx服务器中强制使用缓存的配置及缓存优先级的讲解
nginx代理做好了,缓存也配置好了,但是发现css.js.jpg这些静态文件统统都cached成功.但是偏偏页面文件依旧到源服务器取. 1. nginx不缓存原因 默认情况下,nginx是否缓存是由nginx缓存服务器与源服务器共同决定的, 缓存服务器需要严格遵守源服务器响应的header来决定是否缓存以及缓存的时常.header主要有如下: Cache-control:no-cache.no-store 如果出现这两值,nginx缓存服务器是绝对不会缓存的 Expires:1980-01-0
-
详解nginx服务器中的安全配置
本篇文章详细的讲诉了nginx服务器中的安全配置,具体如下: 一.关闭SELinux 安全增强型Linux(SELinux)的是一个Linux内核的功能,它提供支持访问控制的安全政策保护机制. 但是,SELinux带来的附加安全性和使用复杂性上不成比例,性价比不高 sed -i /SELINUX=enforcing/SELINUX=disabled/ /etc/selinux/config /usr/sbin/sestatus -v #查看状态 二.通过分区挂载允许最少特权 服务器上 nginx
-
详解Nginx 被动检查服务器的存活状态
介绍 通过发送定期健康检查来监控上游组中 HTTP 服务器的健康状况.Nginx 可以持续测试您的上游服务器,避免出现故障的服务器,并将恢复的服务器优雅地添加到负载均衡组中. 被动健康检查 对于被动健康检查,Nginx 会在事务发生时对其进行监控,并尝试恢复失败的连接.如果事务仍然无法恢复,Nginx 将服务器标记为不可用并暂时停止向其发送请求,直到它再次标记为活动状态. 上游服务器标记为不可用的条件是通过上游块中服务器指令的参数为每个上游服务器定义的: fail_timeout :设置要将服务
-
解决ASP中http状态跳转返回错误页的问题
IIS默认的错误页是很不友好的,很多人看到默认的错误页时都会说:网站打不开了!白白损失了这部分流量.而如果错误页直接跳转到首页又对搜索引擎很不友好,搞不好首页还会被封掉.所以根据情况,有两个方法解决这个问题: 如果是博客等内容型的网站,可以返回一个带有404错误的搜索框让访客搜索,若是电子商务型网站,则可以返回一个带有404错误的进度条进行跳转.这两种方法即照顾了访客又顾及到了SEO. 可以在Google webmaster tools中查看自己网站错误页有多少. 修改默认错误页的方法很简单:在
-
在Linux服务器中配置mongodb环境的步骤
1.到mongodb官网下载一个合适的linux环境安装包 如下图,放到本地的某个角落,要记得位置哦~ 2.然后你需要有一个服务器,并进入 ssh root@你的IP //回车输入密码 3.把下载好的安装包传到服务中 另开ssh窗口(command+n),如果是windows就打开新的cmd窗口,因为我们要操作本地文件,之前的窗口我们已经登了服务器了. 传的方法很多,我只演示其中一种啦. cd "安装包所在文件夹" // 去你刚才安装包放的位置 scp "本地文件"