Apache Hudi灵活的Payload机制硬核解析
1.摘要
Apache Hudi 的Payload是一种可扩展的数据处理机制,通过不同的Payload我们可以实现复杂场景的定制化数据写入方式,大大增加了数据处理的灵活性。Hudi Payload在写入和读取Hudi表时对数据进行去重、过滤、合并等操作的工具类,通过使用参数 "hoodie.datasource.write.payload.class"指定我们需要使用的Payload class。本文我们会深入探讨Hudi Payload的机制和不同Payload的区别及使用场景。
2. 为何需要Payload
在数据写入的时候,现有整行插入、整行覆盖的方式无法满足所有场景要求,写入的数据也会有一些定制化处理需求,因此需要有更加灵活的写入方式以及对写入数据进行一定的处理,Hudi提供的playload方式可以很好的解决该问题,例如可以解决写入时数据去重问题,针对部分字段进行更新等等。
3. Payload的作用机制
写入Hudi表时需要指定一个参数hoodie.datasource.write.precombine.field,这个字段也称为Precombine Key,Hudi Payload就是根据这个指定的字段来处理数据,它将每条数据都构建成一个Payload,因此数据间的比较就变成了Payload之间的比较。只需要根据业务需求实现Payload的比较方法,即可实现对数据的处理。
Hudi所有Payload都实现HoodieRecordPayload接口,下面列出了所有实现该接口的预置Payload类。

下图列举了HoodieRecordPayload接口需要实现的方法,这里有两个重要的方法preCombine和combineAndGetUpdateValue,下面我们对这两个方法进行分析。
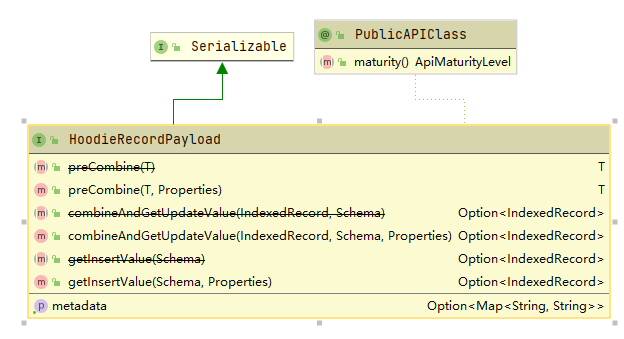
3.1 preCombine分析
从下图可以看出,该方法比较当前数据和oldValue,然后返回一条记录。
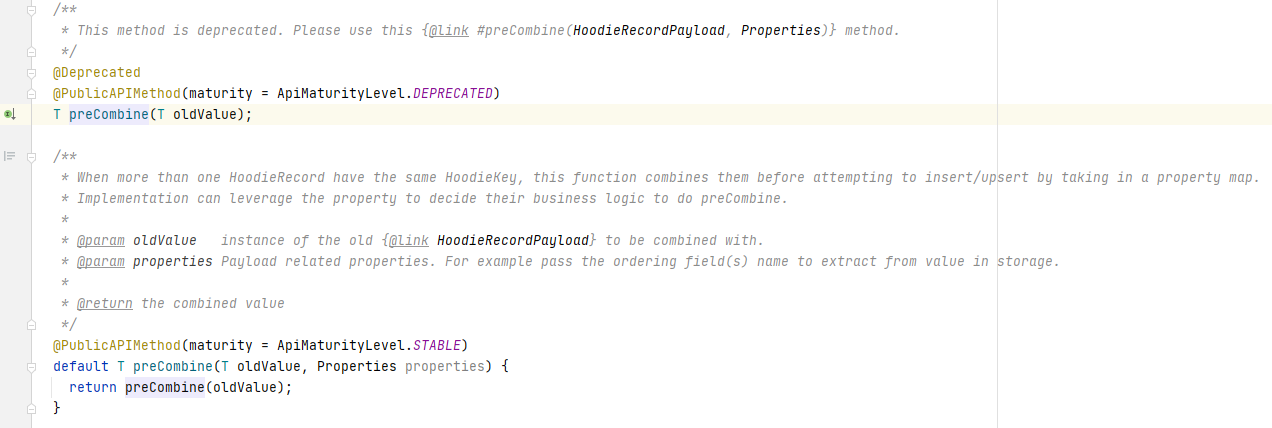
从preCombine方法的注释描述也可以知道首先它在多条相同主键的数据同时写入Hudi时,用来进行数据去重。
调用位置
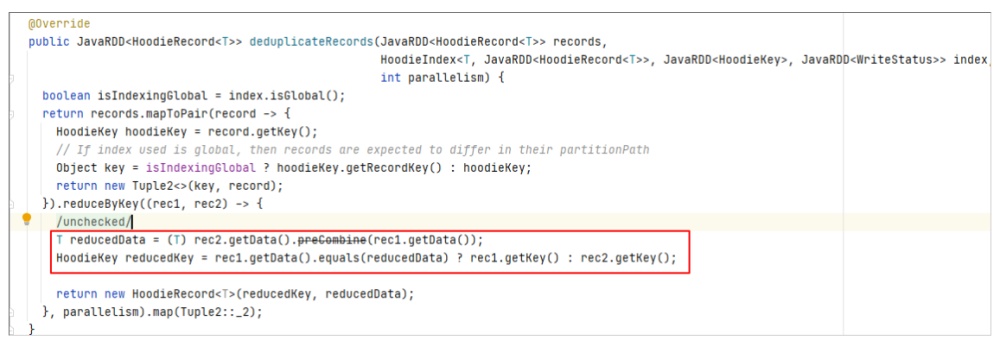
其实该方法还有另一个调用的地方,即在MOR表读取时会对Log file中的相同主键的数据进行处理。
如果同一条数据多次修改并写入了MOR表的Log文件,在读取时也会进行preCombine。
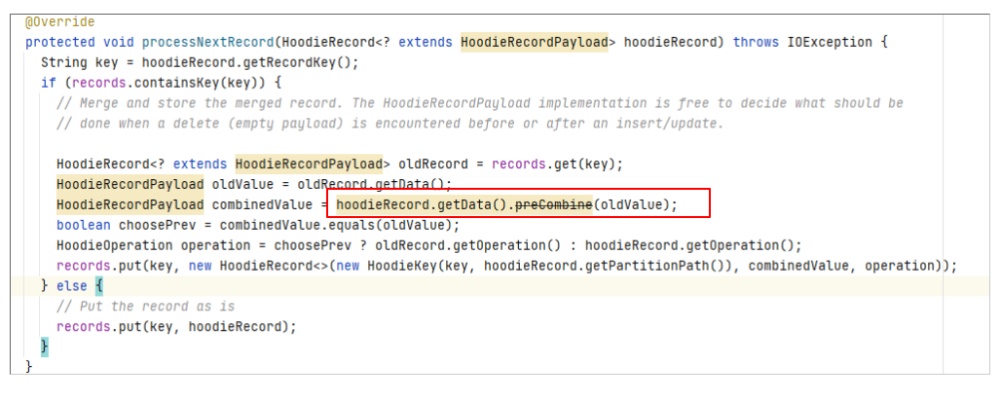
3.2 combineAndGetUpdateValue分析
该方法将currentValue(即现有parquet文件中的数据)与新数据进行对比,判断是否需要持久化新数据。
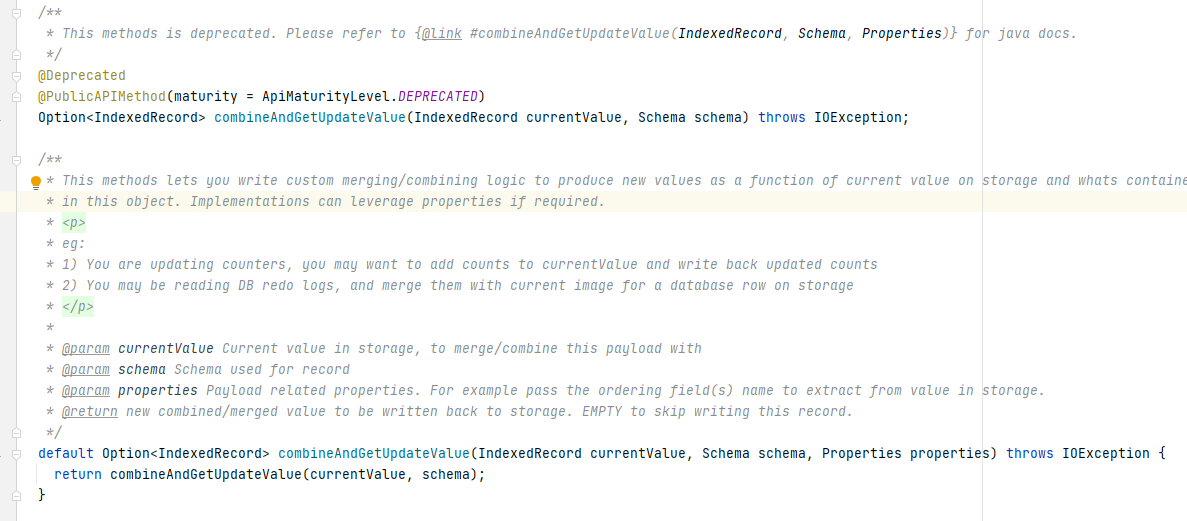
由于COW表和MOR表的读写原理差异,因此combineAndGetUpdateValue的调用在COW和MOR中也有所不同:
在COW写入时会将新写入的数据与Hudi表中存的currentValue进行比较,返回需要持久化的数据
在MOR读取时会将经过preCombine处理的Log中的数据与Parquet文件中的数据进行比较,返回需要持久化的数据
4.常用Payload处理逻辑的对比
了解了Payload的内核原理,下面我们对比分析下集中常用的Payload实现的方式。
4.1 OverwriteWithLatestAvroPayload
OverwriteWithLatestAvroPayload 的相关方法实现如下

可以看出使用OverwriteWithLatestAvroPayload 会根据orderingVal进行选择(这里的orderingVal即precombine key的值),而combineAndGetUpdateValue永远返回新数据。
4.2 OverwriteNonDefaultsWithLatestAvroPayload
OverwriteNonDefaultsWithLatestAvroPayload继承OverwriteWithLatestAvroPayload,preCombine方法相同,重写了combineAndGetUpdateValue方法,新数据会按字段跟schema中的default value进行比较,如果default value非null且与新数据中的值不同时,则在新数据中更新该字段。由于通常schema定义的default value都是null,在此场景下可以实现更新非null字段的功能,即如果一条数据有五个字段,使用此Payload更新三个字段时不会影响另外两个字段原来的值。

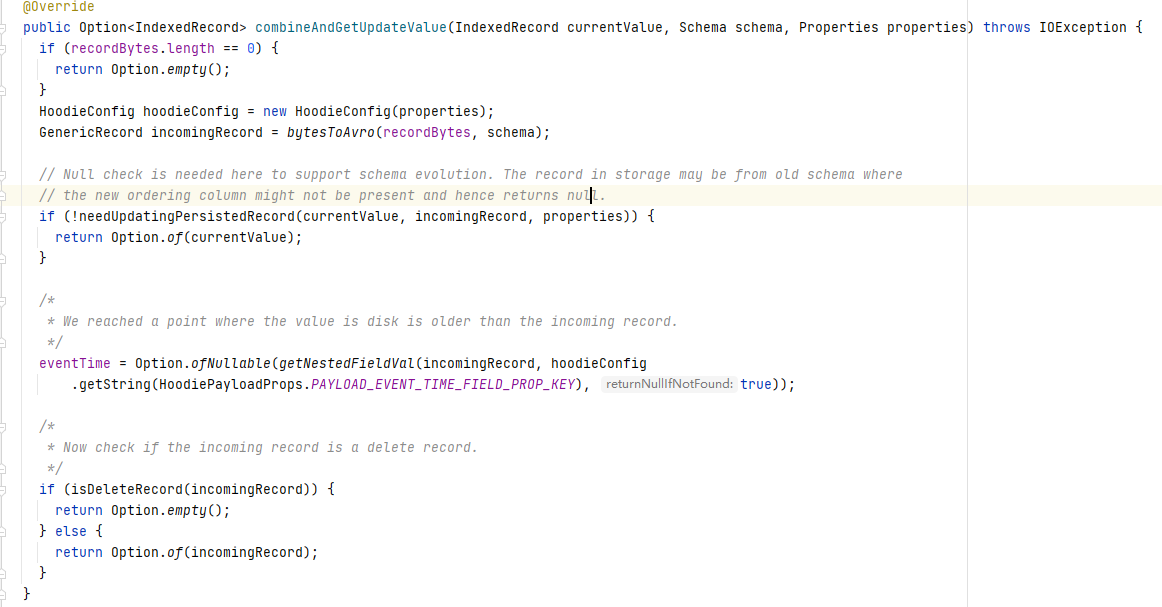
4.3 DefaultHoodieRecordPayload
DefaultHoodieRecordPayload同样继承OverwriteWithLatestAvroPayload重写了combineAndGetUpdateValue方法,通过下面代码可以看出该Payload使用precombine key对现有数据和新数据进行比较,判断是否要更新该条数据。
下面我们以COW表为例展示不同Payload读写结果测试
5. 测试
我们使用如下几条源数据,以key为主键,col3为preCombine key写Hudi表。

首先我们一次写入col0是'aa'、'bb'的两条数据,由于他们的主键相同,所以在precombine时会根据col3比较去重,最终写入Hudi表的只有一条数据。(注意如果写入方式是insert或bulk_insert则不会去重)
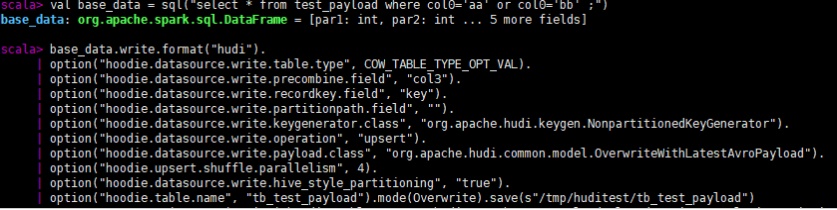
查询结果

下面我们使用col0是'cc'的数据进行更新,这是由于三种Payload的处理逻辑不同,最终写入的数据结果也不同。
OverwriteWithLatestAvroPayload完全用新数据覆盖了旧数据。

OverwriteNonDefaultsWithLatestAvroPayload由于更新数据中col1 col2为null,因此该字段未被更新。

DefaultHoodieRecordPayload由于cc的col3小于bb的,因此该数据未被更新。

6. 总结
通过上面分析我们清楚了Hudi常用的几种Payload机制,总结对比如下
| Payload | 更新逻辑与适用场景 |
|---|---|
| OverwriteWithLatestAvroPayload | 永远用新数据更新老数据全部字段,适合每次更新数据都是完整的 |
| OverwriteNonDefaultsWithLatestAvroPayload | 将新数据中的非空字段更新到老数据中,适合每次更新数据只有部分字段 |
| DefaultHoodieRecordPayload | 根据precombine key比较是否要更新数据,适合实时入湖且入湖顺序乱序 |
虽然Hudi提供了多个预置Payload,但是仍不能满足一些特殊场景的数据处理工作:例如用户在使用Kafka-Hudi实时入湖,但是用户的一条数据的修改不在一条Kafka消息中,而是多条相同主键的数据消息到,第一条里面有col0,col1的数据,第二条有col2,col3的数据,第三条有col4的数据,这时使用Hudi自带的Payload就无法完成将这三条数据合并之后写入Hudi表的工作,要实现这个逻辑就要通过自定义Payload,重写Payload中的preCombine和combineAndGetUpdateValue方法来实现相应的业务逻辑,并在写入时通过hoodie.datasource.write.payload.class指定我们自定义的Payload实现
以上就是Apache Hudi灵活的Payload机制硬核解析的详细内容,更多关于Apache Hudi Payload机制解析的资料请关注我们其它相关文章!
相关推荐
-

Apache Calcite进行SQL解析(java代码实例)
背景 当一个项目分了很多模块,很多个服务的时候,一些公共的配置就需要统一管理了,于是就有了元数据驱动! 简介 什么是Calcite?是一款开源SQL解析工具, 可以将各种SQL语句解析成抽象语法树AST(Abstract Syntax Tree), 之后通过操作AST就可以把SQL中所要表达的算法与关系体现在具体代码之中.Calcite能做啥? SQL 解析 SQL 校验 查询优化 SQL 生成器 数据连接 实例 今天主要是贴出一个java代码实例,实现了:解析SQL语句中的表名上代码:SQL语
-
Apache Calcite 实现方言转换的代码
定义 Calcite能够通过解析Sql为SqlNode,再将SqlNode转化为特定数据库的方言的形式实现Sql的统一. 实现 在Calcite中实现方言转换的主要类是SqlDialect基类,其具体的变量含义如下: public class SqlDialect { BUILT_IN_OPERATORS_LIST: 支持的内置定义函数或者运算符(例如:abs and..) // 列 表的标识符 String identifierQuoteString: 标识符的开始符号 String iden
-
阿里云服务器搭建Php+Apache运行环境的详细过程
1.apache 1.1 安装apache 使用yum命令安装 : yum -y install httpd 执行结果如下: 1.2 开启apache 开启apache: systemctl start httpd 开启启动apache: systemctl enable httpd 执行结果如下: 1.3 验证安装是否成功 在浏览器输入http://(服务器公网ip),如果出现以下页面说明安装成功: 1.4 验证是否能够正常访问 使用vim在/var/www/html下面编辑一个html文件:
-
Apache log4j2-RCE 漏洞复现及修复建议(CVE-2021-44228)
目录 Apache log4j2-RCE 漏洞复现 0x01 漏洞简介 0x02 环境准备 0x03 漏洞验证(DNSLOG篇) 0x04 漏洞验证(远程代码执行弹计算器&记事本篇) 0x05 漏洞深度利用(反弹shell) 0x06 影响范围及排查方法 0x07 修复建议 0x08 涉及资源 Apache log4j2-RCE 漏洞复现 0x01 漏洞简介 Apache Log4j2是一个基于Java的日志记录工具.由于Apache Log4j2某些功能存在递归解析功能,攻击者可直接构造恶意请
-
Apache Log4j2 报核弹级漏洞快速修复方法
Apache Log4j2 报核弹级漏洞,栈长的朋友圈都炸锅了,很多程序猿都熬到半夜紧急上线,昨晚你睡了吗?? Apache Log4j2 是一个基于Java的日志记录工具,是 Log4j 的升级,在其前身Log4j 1.x基础上提供了 Logback 中可用的很多优化,同时修复了Logback架构中的一些问题,是目前最优秀的 Java日志框架之一. 此次 Apache Log4j2 漏洞触发条件为只要外部用户输入的数据会被日志记录,即可造成远程代码执行. 影响版本 2.0 <= Apache
-
Apache Pulsar集群搭建部署详细过程
目录 一.集群组成说明 二.安装前置条件 三.ZooKeeper集群搭建 四.BookKeeper集群搭建 五.Broker集群搭建 六.docker安装pulsar-dashboard 一.集群组成说明 1.搭建Pulsar集群至少需要3个组件:ZooKeeper集群.BookKeeper集群和Broker集群(Broker是Pulsar的自身实例).这三个集群组件如下:ZooKeeper集群(3个ZooKeeper节点组成)Bookie集群(也称为BookKeeper集群,3个BookKee
-
Vertica集成Apache Hudi重磅使用指南
目录 1. 摘要 2. Apache Hudi介绍 3. 环境准备 4. Vertica和Apache Hudi集成 4.1 在 Apache Spark 上配置 Apache Hudi 和 AWS S3 4.2 配置 Vertica 和 Apache HUDI 集成 4.3 如何让 Vertica 查看更改的数据 4.3.1 写入数据 4.3.2 更新数据 4.3.3 创建和查看数据的历史快照 1. 摘要 本文演示了使用外部表集成 Vertica 和 Apache Hudi. 在演示中我们使用
-
Apache Hudi灵活的Payload机制硬核解析
1.摘要 Apache Hudi 的Payload是一种可扩展的数据处理机制,通过不同的Payload我们可以实现复杂场景的定制化数据写入方式,大大增加了数据处理的灵活性.Hudi Payload在写入和读取Hudi表时对数据进行去重.过滤.合并等操作的工具类,通过使用参数 "hoodie.datasource.write.payload.class"指定我们需要使用的Payload class.本文我们会深入探讨Hudi Payload的机制和不同Payload的区别及使用场景. 2
-
深入解析Apache Hudi内核文件标记机制
目录 1. 摘要 2. 为何引入Markers机制 3. 现有的直接标记机制及其局限性 4. 基于时间线服务器的标记机制提高写入性能 5. 标记相关的写入选项 6. 性能 7. 总结 1. 摘要 Hudi 支持在写入时自动清理未成功提交的数据.Apache Hudi 在写入时引入标记机制来有效跟踪写入存储的数据文件. 在本博客中,我们将深入探讨现有直接标记文件机制的设计,并解释了其在云存储(如 AWS S3.Aliyun OSS)上针对非常大批量写入的性能问题. 并且演示如何通过引入基于时间轴服
-
Java CountDownLatch的源码硬核解析
目录 前言 介绍和使用 例子 概述 实现思路 源码解析 类结构图 await() 实现原理 countDown()实现原理 前言 对于并发执行,Java中的CountDownLatch是一个重要的类,简单理解, CountDownLatch中count down是倒数的意思,latch则是“门闩”的含义.在数量倒数到0的时候,打开“门闩”, 一起走,否则都等待在“门闩”的地方. 为了更好的理解CountDownLatch这个类,本文通过例子和源码带领大家深入解析这个类的原理. 介绍和使用 例子
-
解析Apache Dubbo的SPI实现机制
一.SPI 在Java中,SPI体现了面向接口编程的思想,满足开闭设计原则. 1.1.JDK自带SPI实现 从JDK1.6开始引入SPI机制后,可以看到很多使用SPI的案例,比如最常见的数据库驱动实现,在JDK中只定义了java.sql.Driver的接口,具体实现由各数据库厂商来提供.下面一个简单的例子来快速了解下Java SPI的使用方式: 1)定义一个接口 package com.vivo.study public interface Car { void getPrice(); } 2)
-
Apache Hudi基于华米科技应用湖仓一体化改造
目录 1. 应用背景及痛点介绍 2. 技术方案选型 3. 问题与解决方案 3.1.增量数据字段对齐问题 3.2 全球存储兼容性问题 3.3 云主机时区统一问题 3.4 升级新版本问题 3.5 多分区Upsert性能问题 3.6 数据特性适应问题 4. 上线收益 4.1 成本方面 4.2 效率方面 4.3 稳定性层面 4.4 查询性能层面 5. 总结与展望 1. 应用背景及痛点介绍 华米科技是一家基于云的健康服务提供商,拥有全球领先的智能可穿戴技术.在华米科技,数据建设主要围绕两类数据:设备数据和
-
Apache Hudi的多版本清理服务彻底讲解
目录 1. 回收空间以控制存储成本 2. 问题描述 3. 深入了解 Hudi清理服务 4. 清理服务 5. 例子 6. 配置 7. 运行命令 8. 未来计划 Apache Hudi提供了MVCC并发模型,保证写入端和读取端之间快照级别隔离.在本篇博客中我们将介绍如何配置来管理多个文件版本,此外还将讨论用户可使用的清理机制,以了解如何维护所需数量的旧文件版本,以使长时间运行的读取端不会失败. 1. 回收空间以控制存储成本 Hudi 提供不同的表管理服务来管理数据湖上表的数据,其中一项服务称为Cle
-
Apache Hudi基于华米科技应用湖仓一体化改造
目录 1. 应用背景及痛点介绍 2. 技术方案选型 3. 问题与解决方案 3.1.增量数据字段对齐问题 3.2 全球存储兼容性问题 3.3 云主机时区统一问题 3.4 升级新版本问题 3.5 多分区Upsert性能问题 3.6 数据特性适应问题 4. 上线收益 4.1 成本方面 4.2 效率方面 4.3 稳定性层面 4.4 查询性能层面 5. 总结与展望 1. 应用背景及痛点介绍 华米科技是一家基于云的健康服务提供商,拥有全球领先的智能可穿戴技术.在华米科技,数据建设主要围绕两类数据:设备数据和
-
NopCommerce架构分析之(四)基于路由实现灵活的插件机制
NopCommerce支持灵活的插件机制,所谓Web系统插件,其实也就是可以像原系统的一部分一样使用. Web系统的使用方式就是客户端发送一个请求,服务端进行解析.在asp.net MVC中对客户请求的解析是通过路由的方式实现的. 所谓路由就是在客户端发生请求时,对请求路径的解析过程. 在Global.asax.cs中注册所有路由类: //register custom routes (plugins, etc) var routePublisher = EngineContext.Curren
-
硬核!15张图解Redis为什么这么快(推荐)
作为一名服务端工程师,工作中你肯定和 Redis 打过交道.Redis为什么快,这点想必你也知道,至少为了面试也做过准备.很多人知道Redis快仅仅因为它是基于内存实现的,对于其它原因倒是模棱两可. 那么今天就和小莱一起看看: 图注:- 思维导图 - 基于内存实现 这点在一开始就提到过了,这里再简单说说. Redis 是基于内存的数据库,那不可避免的就要与磁盘数据库做对比.对于磁盘数据库来说,是需要将数据读取到内存里的,这个过程会受到磁盘 I/O 的限制. 而对于内存数据库来说,本身数据就存在于