C语言进阶几分钟带你理解大小端存储模式
目录
- 正片开始
- 共用体原理
- 引申一下
- 字节顺序
- 大小端存储
- 共用体判断大小端
正片开始
C语言中数据类型的存储是较为严谨的,一块空间只能存储一种数据类型,要知道内存这个东西,在早期可是非常珍贵的。
尤其对于那些性能不好计算机更是如此,比如 Office1997,操作系统为Windows95 ,奔腾1的cpu,内存只有128M。就这么绿豆点大的存储空间,要想达到节约,利用最大化就必须在同一块空间中存入不同类型数据。
所以共用体的概念就随之产生,将几种不同类型的内容覆盖到同一内存单元,之前在我的一篇共用体专题写过,但感觉自己总结的还不够到位,这里再讲讲。
共用体原理
共用体和结构体非常相似,共用体定义很简单,只需要 union + 共用体名即可,举个栗子:
union student:
{
char name;
short age;
int weight;
char sex;
};
某种意义上,共用体与结构体是差不多的数据结构,他们都可以同时包含多种数据类型。
但是!毕竟不叫同一个名儿就不是同一个玩意儿,那他们==本质上的区别是啥?==这里我先从内存方面下手,对于结构体,在内存中,他们有各自的存储空间,不管这个这个成员我有没有去使用他,C语言程序都会给他分配空间, 所以有结构体类型长度大于或等于各成员长度之和一说。
而在共用体中,各成员在一坨空间里面,空间相当于是共享的的公共空间,一个共用体类型长度等于所有成员变量中最宽数据的长度,比如我刚刚的student 这个共用体中 ,有 char,short和 int 类型,此时该共用体类型长度就是4个字节,也就是 int 类型长度。强调一下,这里的共享并不是把多个变量同时放入一个共用体内,是指该共用体可被赋予任何一种变量的值,但每次赋值只能赋一种,多种还是会遵循共用体最长数据覆盖原则,也就是说共用体在同一时间只能存放一个变量。
引申一下
为了去确定当前计算机的存储模式,我们可以用共用体去试触,判断它是大端存储还是小端存储,这样简单又高效。
我们都知道计算机内存是以字节为单位的划分的,每个地址单元对应一个字节,一个字节占 8 个 bit 位,一个 bit 对应存储一个二进制数据,比如 00000000;
另外还有 int ,long ,long long,在16位和32位处理器中,可同时处理16 bit 和32 bit 的数据,寄存器宽度都大于一个字节,就此我们的大小端存储模式应运而生。
字节顺序
在搞清楚大小端模式之前必须搞清楚字节的顺序,在两个设备之间进行数据的传输时,我要把一个东西从A传到B,但这时发现在A设备中,内容是正序的,但是B设备中的内容是反序放着的,我们就无法在传输后得到正确的格式,所以就要要求统一的模式。
大小端存储
大端存储是指数据的低位字节顺序会存储在内存的高地址中,小端存储模式则恰恰相反,比如我将一个十六进制数 0x1234ffff,对应字节序由低到高从 f 到 1 ,从右向左依次读取较低位字节放在地址较大的内存单元中,如下:
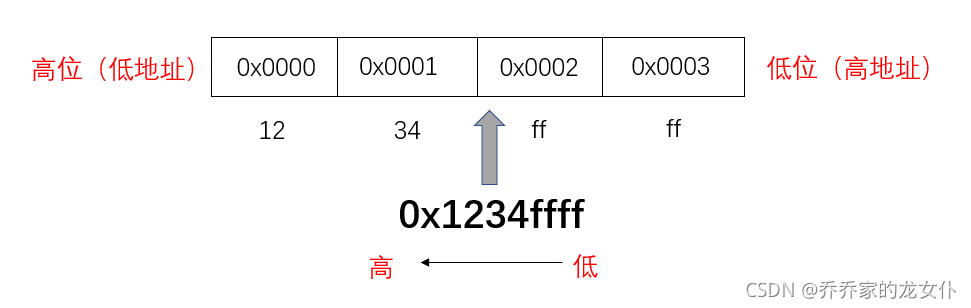
小端存储则会从右向左依次读取较低位的字节存入地址较小的内存单元中。


我们常用的X86结构,ARM就是小端模式,什么 C51则为大端模式(没学我也不知道是个啥,但还是摆出来)。
共用体判断大小端
union num
{
int a;
char b[2];
};
比如我定义一个num共用体类型,再创建一个共用体变量 union num i,这时内存中会划分出四个字节的大小用于存放 num1;假设i的char类型 i.b = 0x1234,虽然这时我num1中的char类型没有被赋值,但已经被我的 int 类型所覆盖, 我们int 类型四个字节对应四个空间,char类型只需一个空间,我们只需要观察int的值是否在char空间中高位存放了低位字节,是则为大端存储,反之则为小端存储,可用代码打印如下:
printf("i.a = %x\n",i.a);
printf("i.b[0] = %x\n",i.b[0]);
printf("i.b[1] = %x\n",i.b[1]);
效果如图:

可以看出我的电脑就是小端存储滴。
今天就到这里吧,摸了家人们,更多关于C语言进阶大小端模式的资料请关注我们其它相关文章!
相关推荐
-

关于C语言中数据在内存中的存储详解
前言 1. 数据类型详细介绍 2. 整形在内存中的存储:原码.反码.补码 3. 大小端字节序介绍及判断 4. 浮点型在内存中的存储解析 一.数据类型介绍 1.类型的基本归类 1.整形家族 char unsigned char signed char short unsigned short [int] signed short [int] int unsigned int signed int long unsigned long [int] signed long [int] 2.浮点型家族
-
一篇文章带你了解C语言--数据的储存
目录 前言 数据类型介绍 类型的基本归类 整形在内存中的存储 原码.反码.补码 大小端介绍 浮点型在内存中的存储 前言 前面我们学习了C语言的一些基本知识和基础的语法,想必大家对C语言都有了自己的认识. 当然只是学习这些知识还是不够的,我们需要进行更加深入的学习. 从本章开始,我们将进行C语言进阶阶段的学习,所以难度会有所增加. 数据类型介绍 前面我们已经学习了基本的内置类型: char //字符数据类型 short //短整型 int //整形 long //长整型 long long //更
-
关于大小端、位域的一些概念详解
大小端: 对于像C++中的char这样的数据类型,它本身就是占用一个字节的大小,不会产生什么问题.但是当数制类型为int,在32bit的系统中,它需要占用4个字节(32bit),这个时候就会产生这4个字节在寄存器中的存放顺序的问题.比如int maxHeight = 0x12345678,&maxHeight = 0x0042ffc4.具体的该怎么存放呢?这个时候就需要理解计算机的大小端的原理了. 大端:(Big-Endian)就是把数值的高位字节放在内存的低位地址上,把数值的地位字节放在内存的
-
C语言编程大小端问题示例详解教程
目录 如何理解大小端 大小端的基本概念 大小端是如何影响数据的存取的 今天想给大家分享的,是数据存储中的大小端问题,今天的分享主要分为三个部分,分别是如何理解大小端,大小端的基本概念以及大小端是如何影响数据存取的. 如何理解大小端 首先先带大家了解一个权值的概念. 对于多位数,处在某一位上的"i"所表示的数值的大小,称为该位的位权,可以简单理解为权值. 权值大的即为高权值位,权值小的即为低权值位,例如 0x010001,从左边起第一个1表示的是1*2^7,第二个1表示的是1*2^0,事
-
C语言进阶几分钟带你理解大小端存储模式
目录 正片开始 共用体原理 引申一下 字节顺序 大小端存储 共用体判断大小端 正片开始 C语言中数据类型的存储是较为严谨的,一块空间只能存储一种数据类型,要知道内存这个东西,在早期可是非常珍贵的. 尤其对于那些性能不好计算机更是如此,比如 Office1997,操作系统为Windows95 ,奔腾1的cpu,内存只有128M.就这么绿豆点大的存储空间,要想达到节约,利用最大化就必须在同一块空间中存入不同类型数据. 所以共用体的概念就随之产生,将几种不同类型的内容覆盖到同一内存单元,之前在我的一篇
-
10分钟带你理解Java中的反射
一.简介 Java 反射是可以让我们在运行时获取类的方法.属性.父类.接口等类的内部信息的机制.也就是说,反射本质上是一个"反着来"的过程.我们通过new创建一个类的实例时,实际上是由Java虚拟机根据这个类的Class对象在运行时构建出来的,而反射是通过一个类的Class对象来获取它的定义信息,从而我们可以访问到它的属性.方法,知道这个类的父类.实现了哪些接口等信息. 二.Class类 我们知道使用javac能够将.java文件编译为.class文件,这个.class文件包含了我们对
-
10分钟带你理解Java中的弱引用
前言 本文尝试从What.Why.How这三个角度来探索Java中的弱引用,帮助大家理解Java中弱引用的定义.基本使用场景和使用方法. 一. What--什么是弱引用? Java中的弱引用具体指的是java.lang.ref.WeakReference<T>类,我们首先来看一下官方文档对它做的说明: 弱引用对象的存在不会阻止它所指向的对象被垃圾回收器回收.弱引用最常见的用途是实现规范映射(canonicalizing mappings,比如哈希表). 假设垃圾收集器在某个时间点决定一个对象是
-
C语言进阶数据的存储机制完整版
目录 数据类型 内存窗口 1.地址栏 2.内容 3.文本 整型的存储 原码,反码,补码 补码的意义 大小端模式 不同数据类型存储 浮点数存储机制 数据类型 1.基本内置类型:byte,int ,char, float, double 2.构造数据类型: 数组类型:结构体类型:struct共用体(联合类型):union枚举类型:enum 3.指针类型 :int* p,char* p,float* p,void* p 4.空类型 : void(无类型),通常用于函数的返回类型,函数参数与指针类型.
-
用C语言程序判断大小端模式
1.大端模式,是指数据的低位保存在内存的高地址中,而数据的高位,保存在内存的低地址中:小端模式相反 2.为什么有大小端之分??? 因为在计算机系统中,存储是以字节为单位的,每个地址单元都对应着一个字节,一个字节=8bit.在C语言中除了8bit的char之外,还有16bit的short型,32bit的long型(要看具体的编译器).对于位数大于8位的处理器,例如16位或者32位的处理器,由于寄存器宽度大于一个字节,如何安排多个字节的存储,这就有了大端存储模式和小端存储模式 3.各自的优势: 小端
-
带你理解C语言中的汉诺塔公式
目录 汉诺塔公式 汉诺塔问题在数学层面的公式: C语言递归公式 两层汉诺塔 三层汉诺塔 总结 汉诺塔公式 汉诺塔问题在数学层面的公式: 不用说,你看到这个公式一定一脸懵逼,我现在来讲解这个公式的作用. 先来回想一下大象放冰箱要几步,三步吧,打开冰箱,放进去,关上门就行了,我们先不要去思考一些细碎的步骤,将一个复杂的问题先简单化,再慢慢去分析. 那汉诺塔问题也是同样的简单三步:(假设有n个盘子) 一.把最大的盘子留在A柱,然后将其他的盘子全放在B柱. 二.把最大的盘子放到C柱. 三.然后将B柱上的
-
你真的理解C语言qsort函数吗 带你深度剖析qsort函数
目录 一.前言 二.简单冒泡排序法 三.qsort函数的使用 1.qsort函数的介绍 2.qsort函数的运用 2.1.qsort函数排序整型数组 2.2.qsort函数排序结构体 四.利用冒泡排序模拟实现qsort函数 五.总结 一.前言 我们初识C语言时,会做过让一个整型数组按照从小到大来排序的问题,我们使用的是冒泡排序法,但是如果我们想要比较其他类型怎么办呢,显然我们当时的代码只适用于简单的整形排序,对于结构体等没办法排序,本篇将引入一个库函数来实现我们希望的顺序. 二.简单冒泡排序法
-
Python进阶学习之带你探寻Python类的鼻祖-元类
Python是一门面向对象的语言,所以Python中数字.字符串.列表.集合.字典.函数.类等都是对象. 利用 type() 来查看Python中的各对象类型 In [11]: # 数字 In [12]: type(10) Out[12]: int In [13]: type(3.1415926) Out[13]: float In [14]: # 字符串 In [15]: type('a') Out[15]: str In [16]: type("abc") Out[16]: str
-
30分钟带你了解Docker(推荐)
最近一直在忙项目,不知不觉2个多月没有更新博客了.正好自学了几天docker就干脆总结一下,也顺带增加一篇<30分钟入门系列>.网上能够查到的对于docker的定义我就不再重复了,说说我自己对它的理解:Docker一个方便多次部署的虚拟化Linux容器,与当下流行的SpringBoot和微服务框架搭配更加相得益彰,从而真正的做到从开发到部署的全流程灵敏.请注意这里的三个关键词:Linux容器,SpringBoot,灵敏.首先,Docker不能别用来部署本地应用(如果你有开发过基于Qt的桌面应用