Spring Batch远程分区的本地Jar包模式的代码详解
1 前言
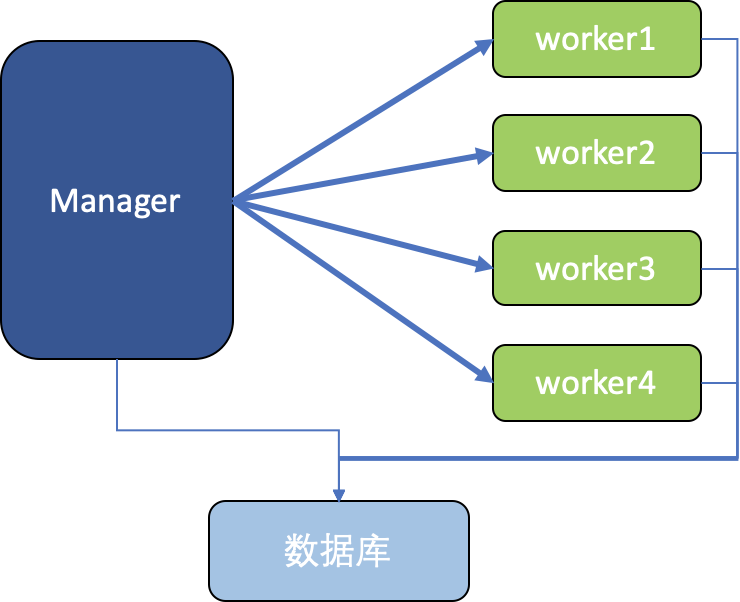
Spring Batch远程分区对于大量数据的处理非常擅长,它的实现有多种方式,如本地Jar包模式、MQ模式、Kubernetes模式。这三种模式的如下:
(1)本地Jar包模式:分区处理的worker为一个Java进程,从jar包启动,通过jvm参数和数据库传递参数;官方提供示例代码。
(2)MQ模式:worker是一个常驻进程,Manager和Worker通过消息队列来传递参数;网上有不少相关示例代码。
(3)Kubernetes模式:worker为K8s中的Pod,Manager直接启动Pod来处理;网上并没有找到任何示例代码。
本文将通过代码来讲解第一种模式(本地Jar包模式),其它后续再介绍。
建议先看下面文章了解一下:
Spring Batch入门:Spring Batch入门教程篇
Spring Batch并行处理介绍:详解SpringBoot和SpringBatch 使用
2 代码讲解
本文代码中,Manager和Worker是放在一起的,在同一个项目里,也只会打一个jar包而已;我们通过profile来区别是manager还是worker,也就是通过Spring Profile实现一份代码,两份逻辑。实际上也可以拆成两份代码,但放一起更方便测试,而且代码量不大,就没有必要了。
2.1 项目准备
2.1.1 数据库
首先我们需要准备一个数据库,因为Manager和Worker都需要同步状态到DB上,不能直接使用嵌入式的内存数据库了,需要一个外部可共同访问的数据库。这里我使用的是H2 Database,安装可参考:把H2数据库从jar包部署到Kubernetes,并解决Ingress不支持TCP的问题。
2.1.2 引入依赖
maven引入依赖如下所示:
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-batch</artifactId> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-task</artifactId> </dependency> <dependency> <groupId>com.h2database</groupId> <artifactId>h2</artifactId> <scope>runtime</scope> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-deployer-local</artifactId> <version>2.4.1</version> </dependency> <dependency> <groupId>org.springframework.batch</groupId> <artifactId>spring-batch-integration</artifactId> </dependency>
spring-cloud-deployer-local用于部署和启动worker,非常关键;其它就是Spring Batch和Task相关的依赖;以及数据库连接。
2.1.3 主类入口
Springboot的主类入口如下:
@EnableTask
@SpringBootApplication
@EnableBatchProcessing
public class PkslowRemotePartitionJar {
public static void main(String[] args) {
SpringApplication.run(PkslowRemotePartitionJar.class, args);
}
}
在Springboot的基础上,添加了Spring Batch和Spring Cloud Task的支持。
2.2 关键代码编写
前面的数据库搭建和其它代码没有太多可讲的,接下来就开始关键代码的编写。
2.2.1 分区管理Partitioner
Partitioner是远程分区中的核心bean,它定义了分成多少个区、怎么分区,要把什么变量传递给worker。它会返回一组<分区名,执行上下文>的键值对,即返回Map<String, ExecutionContext>。把要传递给worker的变量放在ExecutionContext中去,支持多种类型的变量,如String、int、long等。实际上,我们不建议通过ExecutionContext来传递太多数据;可以传递一些标识或主键,然后worker自己去拿数据即可。
具体代码如下:
private static final int GRID_SIZE = 4;
@Bean
public Partitioner partitioner() {
return new Partitioner() {
@Override
public Map<String, ExecutionContext> partition(int gridSize) {
Map<String, ExecutionContext> partitions = new HashMap<>(gridSize);
for (int i = 0; i < GRID_SIZE; i++) {
ExecutionContext executionContext = new ExecutionContext();
executionContext.put("partitionNumber", i);
partitions.put("partition" + i, executionContext);
}
return partitions;
}
};
}
上面分成4个区,程序会启动4个worker来处理;给worker传递的参数是partitionNumber。
2.2.2 分区处理器PartitionHandler
PartitionHandler也是核心的bean,它决定了怎么去启动worker,给它们传递什么jvm参数(跟之前的ExecutionContext传递不一样)。
@Bean
public PartitionHandler partitionHandler(TaskLauncher taskLauncher, JobExplorer jobExplorer, TaskRepository taskRepository) throws Exception {
Resource resource = this.resourceLoader.getResource(workerResource);
DeployerPartitionHandler partitionHandler =
new DeployerPartitionHandler(taskLauncher, jobExplorer, resource, "workerStep", taskRepository);
List<String> commandLineArgs = new ArrayList<>(3);
commandLineArgs.add("--spring.profiles.active=worker");
commandLineArgs.add("--spring.cloud.task.initialize-enabled=false");
commandLineArgs.add("--spring.batch.initializer.enabled=false");
partitionHandler
.setCommandLineArgsProvider(new PassThroughCommandLineArgsProvider(commandLineArgs));
partitionHandler
.setEnvironmentVariablesProvider(new SimpleEnvironmentVariablesProvider(this.environment));
partitionHandler.setMaxWorkers(2);
partitionHandler.setApplicationName("PkslowWorkerJob");
return partitionHandler;
}
上面代码中:
resource是worker的jar包地址,表示将启动该程序;
workerStep是worker将要执行的step;
commandLineArgs定义了启动worker的jvm参数,如--spring.profiles.active=worker;
environment是manager的系统环境变量,可以传递给worker,当然也可以选择不传递;
MaxWorkers是最多能同时启动多少个worker,类似于线程池大小;设置为2,表示最多同时有2个worker来处理4个分区。
2.2.3 Manager和Worker的Batch定义
完成了分区相关的代码,剩下的就只是如何定义Manager和Worker的业务代码了。
Manager作为管理者,不用太多业务逻辑,代码如下:
@Bean
@Profile("!worker")
public Job partitionedJob(PartitionHandler partitionHandler) throws Exception {
Random random = new Random();
return this.jobBuilderFactory.get("partitionedJob" + random.nextInt())
.start(step1(partitionHandler))
.build();
}
@Bean
public Step step1(PartitionHandler partitionHandler) throws Exception {
return this.stepBuilderFactory.get("step1")
.partitioner(workerStep().getName(), partitioner())
.step(workerStep())
.partitionHandler(partitionHandler)
.build();
}
Worker主要作用是处理数据,是我们的业务代码,这里就演示一下如何获取Manager传递过来的partitionNumber:
@Bean
public Step workerStep() {
return this.stepBuilderFactory.get("workerStep")
.tasklet(workerTasklet(null, null))
.build();
}
@Bean
@StepScope
public Tasklet workerTasklet(final @Value("#{stepExecutionContext['partitionNumber']}") Integer partitionNumber) {
return new Tasklet() {
@Override
public RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {
Thread.sleep(6000); //增加延时,查看效果,通过jps:在jar情况下会新起java进程
System.out.println("This tasklet ran partition: " + partitionNumber);
return RepeatStatus.FINISHED;
}
};
}
通过表达式@Value("#{stepExecutionContext['partitionNumber']}") 获取Manager传递过来的变量;注意要加注解@StepScope。
3 程序运行
因为我们分为Manager和Worker,但都是同一份代码,所以我们先打包一个jar出来,不然manager无法启动。配置数据库和Worker的jar包地址如下:
spring.datasource.url=jdbc:h2:tcp://localhost:9092/test spring.datasource.username=pkslow spring.datasource.password=pkslow spring.datasource.driver-class-name=org.h2.Driver pkslow.worker.resource=file://pkslow/target/remote-partitioning-jar-1.0-SNAPSHOT.jar
执行程序如下:
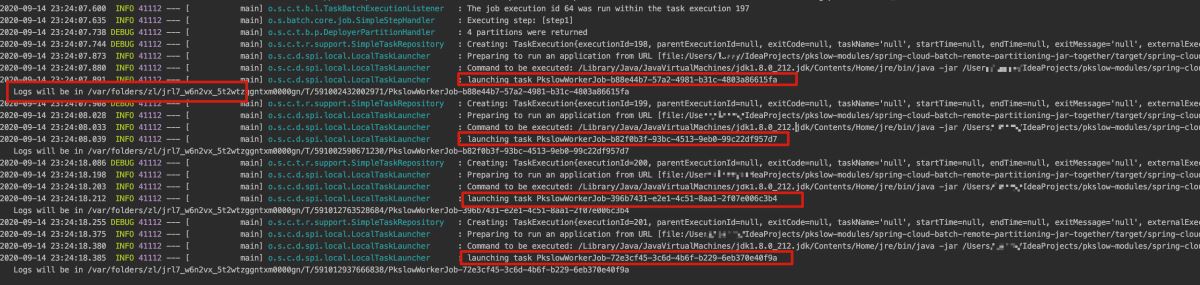
可以看到启动了4次Java程序,还给出日志路径。
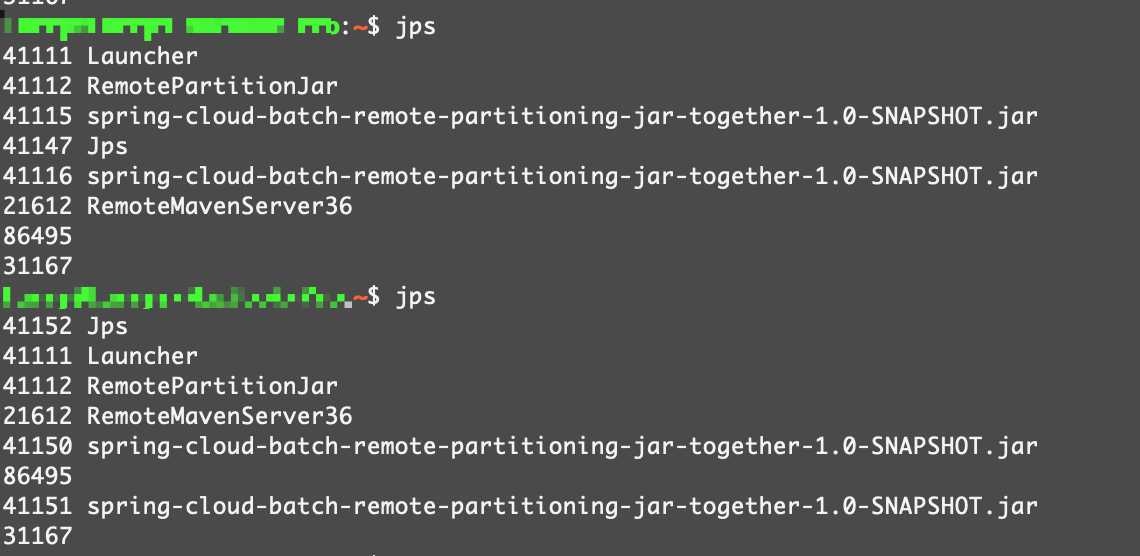
通过jps命令查看,能看到一个Manager进程,还有两个worker进程:
4 复杂变量传递
前面讲了Manager可以通过ExecutionContext传递变量,如简单的String、long等。但其实它也是可以传递复杂的Java对象的,但对应的类需要可序列化,如:
import java.io.Serializable;
public class Person implements Serializable {
private Integer age;
private String name;
private String webSite;
//getter and setter
}
Manager传递:
executionContext.put("person", new Person(0, "pkslow", "www.pkslow.com"));
Worker接收:
@Value("#{stepExecutionContext['person']}") Person person
5 总结
本文介绍了Spring Batch远程分区的本地Jar包模式,只能在一台机器上运行,所以也是无法真正发挥出远程分区的作用。但它对我们后续理解更复杂的模式是有很大帮助的;同时,我们也可以使用本地模式进行开发测试,毕竟它只需要一个数据库就行了,依赖很少。
相关推荐
-

Spring Batch入门教程篇
SpringBatch介绍: SpringBatch 是一个大数据量的并行处理框架.通常用于数据的离线迁移,和数据处理,⽀持事务.并发.流程.监控.纵向和横向扩展,提供统⼀的接⼝管理和任务管理;SpringBatch是SpringSource和埃森哲为了统一业界并行处理标准为广大开发者提供方便开发的一套框架. 官方地址:github.com/spring-projects/spring-batch SpringBatch 本身提供了重试,异常处理,跳过,重启.任务处理统计,资源管理等特性,这些特
-
Spring Batch读取txt文件并写入数据库的方法教程
项目需求 近日需要实现用户推荐相关的功能,也就是说向用户推荐他可能喜欢的东西. 我们的数据分析工程师会将用户以及用户可能喜欢的东西整理成文档给我,我只需要将数据从文档中读取出来,然后对数据进行进一步的清洗(例如去掉特殊符号,长度如果太长则截取).然后将处理后的数据存入数据库(Mysql). 所以分为三步: 读取文档获得数据 对获得的数据进行处理 更新数据库(新增或更新) 考虑到这个数据量以后会越来越大,这里没有使用 poi 来读取数据,而直接使用了 SpringBatch. 实现步骤 本文假设读
-
基于Spring Batch向Elasticsearch批量导入数据示例
1.介绍 当系统有大量数据需要从数据库导入Elasticsearch时,使用Spring Batch可以提高导入的效率.Spring Batch使用ItemReader分页读取数据,ItemWriter批量写数据.由于Spring Batch没有提供Elastisearch的ItemWriter和ItemReader,本示例中自定义一个ElasticsearchItemWriter(ElasticsearchItemReader),用于批量导入. 2.示例 2.1 pom.xml 本文使用spr
-
spring batch 读取多个文件数据导入数据库示例
项目的目录结构 需要读取文件的的数据格式 applicatonContext.xml的配置 <?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:p=
-
Spring batch批处理框架
spring batch框架的简介 批处理任务是大多数IT项目的一个重要组成部分,批处理在业务系统中负责处理海量的数据,无须人工干预就能够自动高效的进行复杂的数据分析和处理.批处理会定期读入批量数据,经过相应的业务处理进行归档的业务操作,批处理的特征是自动执行,处理的数据量大,定时执行.将整个批处理的流程按逻辑划分可以分为读数据,处理数据和写数据. spring batch对批处理本身的特性进行了抽象,将批处理作业抽象为job和job step,将批处理的处理过程分解为数据读,数据处理和数据写.
-
Spring Batch远程分区的本地Jar包模式的代码详解
1 前言 Spring Batch远程分区对于大量数据的处理非常擅长,它的实现有多种方式,如本地Jar包模式.MQ模式.Kubernetes模式.这三种模式的如下: (1)本地Jar包模式:分区处理的worker为一个Java进程,从jar包启动,通过jvm参数和数据库传递参数:官方提供示例代码. (2)MQ模式:worker是一个常驻进程,Manager和Worker通过消息队列来传递参数:网上有不少相关示例代码. (3)Kubernetes模式:worker为K8s中的Pod,Manager
-
mysql-connector-java.jar包的下载过程详解
mysql-connector-java.jar包的下载教程: 1.首先我们打开mysql的官网:https://www.mysql.com/ 2.点击选择DOWNLOADS选项: 3.点击选择Community选项: 4.在左侧选项卡中选择MySQL Connectors选项: 5.单击选择Connector/J选项: 6.在此处下拉选择Platform Independent 选项: 7.选择下载第二个即可: 8.最后选择No thanks,just start my download: 到
-
IDEA对使用了第三方依赖jar包的非Maven项目打jar包的问题(图文详解)
前言: 最近,遇到了一个问题,都快把我整疯了:这个问题开始是由 使用IDEA 对 非Maven项目进行打 Jar 包 引起的:本来就是想简简单单的打个 jar 包,并将使用的第三方依赖 jar 包打进去,但是问题就出现在了项目中依赖的第三方 jar 包( bcprov-jdk15on-1.54.jar )存在签名,那在打包过程中会把 签名 破坏掉,导致在使用打好的jar包时报错: JCE cannot authenticate the provider BC . 注意:如果依赖的第三方jar包不
-
Spring Boot 通过 Mvc 扩展方便进行货币单位转换的代码详解
由于公司是支付平台,所以很多项目都涉及到金额,业务方转递过来的金额是单位是元,而我们数据库保存的金额单位是分.一般金额的流向有以下几个方向: 外部业务方请求我们服务,传递过来的金额单位是元,需要把元转换成分.比如:下单接口. 内部系统之间的流转,不管是向下传递还是向上传递系统间的流程都是分,不需要扭转.比如:调用支付引擎(向下传递),支付引擎回调收单业务(向上传递). 向业务方返回数据,这个时候需要把分转换成元.比如:商户调用查询订单接口. 内部系统的展示,这个时候需要把分转换成元.比如:显示收
-
Spring Boot创建非可执行jar包的实例教程
我们经常会有这种场景,只需要把Spring Boot打成普通的jar包,不包含配置文件,供其他程序应用 本文介绍如何使用Maven将Spring Boot应用打成普通的非可执行jar包. 配置maven-jar-plugin <build> <plugins> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugi
-
SpringBoot集成本地缓存性能之王Caffeine示例详解
目录 引言 Spring Cache 是什么 集成 Caffeine 核心原理 引言 使用缓存的目的就是提高性能,今天码哥带大家实践运用 spring-boot-starter-cache 抽象的缓存组件去集成本地缓存性能之王 Caffeine. 大家需要注意的是:in-memeory 缓存只适合在单体应用,不适合与分布式环境. 分布式环境的情况下需要将缓存修改同步到每个节点,需要一个同步机制保证每个节点缓存数据最终一致. Spring Cache 是什么 不使用 Spring Cache 抽象
-
spring boot实战之本地jar包引用示例
部分情况下无法通过maven仓库直接下载需要的jar包,只能讲jar包下载至本地来使用,spring boot框架内通过maven加载第三方jar包可以通过以下方式来实现(本地jar放在lib/目录下),项目会打包为jar包来运行. 1.添加maven依赖 <dependency> <groupId>org.ansj</groupId> <artifactId>ansj_seg</artifactId> <version>3.0<
-
怎么把本地jar包放入本地maven仓库和远程私服仓库
1.将本地jar包放入本地仓库.只需执行如下命令即可: mvn install:install-file -Dfile=D:/demo/fiber.jar -DgroupId=com.sure -DartifactId=fiber -Dversion=1.0 -Dpackaging=jar 打开本地maven仓库所在目录即可看到被添加的本地jar包. 2.将本地jar包放入远程私服仓库 A.先到maven的安装目录的conf目录下面的setting.xml查看下私服的地址.如下图是我的的sett
-
详解IDEA使用Maven项目不能加入本地Jar包的解决方法
使用IDEA编辑Web项目已经逐渐超过了使用eclipse的人数,但是IDEA对于pom.xml的执行也就是Maven方式导包支持并不是很完善,简单来说就是pom.xml上面记录的依赖库一般都能导入,但是如果pom.xml上面的某个依赖库失效,比如远程服务器关闭或者网络不通,或者是你想要加入本地硬盘上的某个jar包而不修改pom.xml的时候,IDEA的弊端就会显现出来.主要表现就是无法获得的依赖库或者本地Jar包无法放到/WEB-INF/lib目录下,导致Web项目部署时报错. 一个常见的错误
-
在maven中引入本地jar包的步骤
目录 1 起因 2 解决方案 2.1 在pom中引入 2.2 Spring Boot 打包处理 2.3 拓展: Spring Boot 打包加入其它资源 1 起因 在和一些第三方厂商对接的过程中, 偶尔会遇到对方提供的SDK自带maven无法获取的jar包的情况(对于开源激进者的笔者很讨厌这种行为) 我们该如何处理这种情况呢, 其实解决思路很简单: 在pom中引入本地jar 打包时本地jar包含在内 让我们来看看具体怎么操作吧 idea中虽然可以在项目配置加入, 但打包时会报错, 相关的处理方案