Java xml数据格式返回实现操作
前言:对于服务器后端开发,接口返回的数据格式一般要求都是json,但是也有使用xml格式
RequestBody注解
对于SpringMVC,很多人会认为接口方法使用@Controller搭配@ResponseBody和@RequestMapping注解后,java对象会转换成json格式返回。
但实际上配合@ResponseBody注解后,接口返回的数据类型是根据HTTP Request Header中的Accept属性来确定的,可以是XML或者JSON数据
通过适当的HttpMessageConverter对java对象进行格式转换,常用的有:
ByteArrayHttpMessageConverter
负责读取二进制格式的数据和写出二进制格式的数据;
StringHttpMessageConverter
负责读取字符串格式的数据和写出二进制格式的数据;
ResourceHttpMessageConverter
负责读取资源文件和写出资源文件数据;
FormHttpMessageConverter
负责读取form提交的数据;
MappingJacksonHttpMessageConverter
负责读取和写入json格式的数据;
SouceHttpMessageConverter
负责读取和写入 xml 中javax.xml.transform.Source定义的数据;
Jaxb2RootElementHttpMessageConverter
负责读取和写入xml 标签格式的数据;
AtomFeedHttpMessageConverter
负责读取和写入Atom格式的数据;
RssChannelHttpMessageConverter
负责读取和写入RSS格式的数据
具体使用哪个怎么判断这里就不细讲了,我们关心的是Jaxb2RootElementHttpMessageConverter这个方法,后面会讲为啥会提
java对象与xml之间互相转换
使用Java自带注解的方式实现(@XmlRootElement,@XmlAccessorType,@XmlElement,@XmlAttribute),具体使用方法网上有很多
这里直接代码举例
import javax.xml.bind.annotation.XmlElement;
import javax.xml.bind.annotation.XmlRootElement;
import javax.xml.bind.annotation.XmlType;
@XmlRootElement(name = "city")
@XmlType(propOrder = { "name","province"})
public class City {
private String name;
private String province;
public City() {
}
public City(String name, String province) {
this.name = name;
this.province = province;
}
public String getName() {
return name;
}
@XmlElement
public void setName(String name) {
this.name = name;
}
public String getProvince() {
return province;
}
@XmlElement
public void setProvince(String province) {
this.province = province;
}
}
controller
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.ResponseBody;
@Controller
public class IndexController {
@RequestMapping(path = "/get")
@ResponseBody
public City getXml(){
City city= new City("太原","山西");
return city;
}
}
请求http://localhost:8080/get 返回结果如下

是不很容易就实现接口返回xml格式
使用<![CDATA[]]>
对象属性中有可能存在计算逻辑'<‘或'>',而在xml文件中这两个符号是不合法的,会转换为<和>,这样数据就'坏'了,所以<![CDATA[]]>的加入是非常有必要的!
一般实现:使用XmlAdapter定义一个CDataAdapter类,网上也有很多代码
大概的实现如下
public class CDataAdapter extends XmlAdapter<String, String> {
@Override
public String unmarshal(String v) throws Exception {
// 我们这里没有xml转java对象,这里就不具体实现了
return v;
}
@Override
public String marshal(String v) throws Exception {
return new StringBuilder("<![CDATA[").append(v).append("]]>").toString();
}
}
然后使用注解XmlJavaTypeAdapter作用于属性变量上
@XmlJavaTypeAdapter(value=CDataAdapter.class)
@XmlElement
public void setProvince(String province) {
this.province = province;
}
结果

但是实际上看源码

这个不是我们希望的,产生原因是Jaxb默认会把字符'<', '>'进行转义, 下面解决这个问题
我们使用org.eclipse.persistence.oxm.annotations.XmlCDATA注解来解决
使用EclipseLink JAXB (MOXy)
pom文件增加
<dependency> <groupId>org.eclipse.persistence</groupId> <artifactId>org.eclipse.persistence.moxy</artifactId> <version>xx版本</version> </dependency>
上一节中的属性使用注解
...
import org.eclipse.persistence.oxm.annotations.XmlCDATA;
...
...
@XmlCDATA
@XmlElement
public void setProvince(String province) {
this.province = province;
}
注意:一定要设置jaxb.properties文件,并且要放在要转换成xml的java对象所在目录,并且要编译到target中,不然XmlCDATA注解不生效
jaxb.properties文件内容,就是指定创建JAXBContext对象的工长
javax.xml.bind.context.factory=org.eclipse.persistence.jaxb.JAXBContextFactory
到这里配置完成!
补充知识:Java Document生成和解析XML
一)Document介绍
API来源:在JDK中javax.xml.*包下
使用场景:
1、需要知道XML文档所有结构
2、需要把文档一些元素排序
3、文档中的信息被多次使用的情况
优势:由于Document是java中自带的解析器,兼容性强
缺点:由于Document是一次性加载文档信息,如果文档太大,加载耗时长,不太适用
二)Document生成XML
实现步骤:
第一步:初始化一个XML解析工厂
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
第二步:创建一个DocumentBuilder实例
DocumentBuilder builder = factory.newDocumentBuilder();
第三步:构建一个Document实例
Document doc = builder.newDocument();
doc.setXmlStandalone(true);
standalone用来表示该文件是否呼叫其它外部的文件。若值是 ”yes” 表示没有呼叫外部文件
第四步:创建一个根节点,名称为root,并设置一些基本属性
Element element = doc.createElement("root");
element.setAttribute("attr", "root");//设置节点属性
childTwoTwo.setTextContent("root attr");//设置标签之间的内容
第五步:把节点添加到Document中,再创建一些子节点加入
doc.appendChild(element);
第六步:把构造的XML结构,写入到具体的文件中
实现源码:
package com.oysept.xml;
import java.io.File;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.transform.OutputKeys;
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerConfigurationException;
import javax.xml.transform.TransformerException;
import javax.xml.transform.TransformerFactory;
import javax.xml.transform.dom.DOMSource;
import javax.xml.transform.stream.StreamResult;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
/**
* Document生成XML
* @author ouyangjun
*/
public class CreateDocument {
public static void main(String[] args) {
// 执行Document生成XML方法
createDocument(new File("E:\\person.xml"));
}
public static void createDocument(File file) {
try {
// 初始化一个XML解析工厂
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
// 创建一个DocumentBuilder实例
DocumentBuilder builder = factory.newDocumentBuilder();
// 构建一个Document实例
Document doc = builder.newDocument();
doc.setXmlStandalone(true);
// standalone用来表示该文件是否呼叫其它外部的文件。若值是 ”yes” 表示没有呼叫外部文件
// 创建一个根节点
// 说明: doc.createElement("元素名")、element.setAttribute("属性名","属性值")、element.setTextContent("标签间内容")
Element element = doc.createElement("root");
element.setAttribute("attr", "root");
// 创建根节点第一个子节点
Element elementChildOne = doc.createElement("person");
elementChildOne.setAttribute("attr", "personOne");
element.appendChild(elementChildOne);
// 第一个子节点的第一个子节点
Element childOneOne = doc.createElement("people");
childOneOne.setAttribute("attr", "peopleOne");
childOneOne.setTextContent("attr peopleOne");
elementChildOne.appendChild(childOneOne);
// 第一个子节点的第二个子节点
Element childOneTwo = doc.createElement("people");
childOneTwo.setAttribute("attr", "peopleTwo");
childOneTwo.setTextContent("attr peopleTwo");
elementChildOne.appendChild(childOneTwo);
// 创建根节点第二个子节点
Element elementChildTwo = doc.createElement("person");
elementChildTwo.setAttribute("attr", "personTwo");
element.appendChild(elementChildTwo);
// 第二个子节点的第一个子节点
Element childTwoOne = doc.createElement("people");
childTwoOne.setAttribute("attr", "peopleOne");
childTwoOne.setTextContent("attr peopleOne");
elementChildTwo.appendChild(childTwoOne);
// 第二个子节点的第二个子节点
Element childTwoTwo = doc.createElement("people");
childTwoTwo.setAttribute("attr", "peopleTwo");
childTwoTwo.setTextContent("attr peopleTwo");
elementChildTwo.appendChild(childTwoTwo);
// 添加根节点
doc.appendChild(element);
// 把构造的XML结构,写入到具体的文件中
TransformerFactory formerFactory=TransformerFactory.newInstance();
Transformer transformer=formerFactory.newTransformer();
// 换行
transformer.setOutputProperty(OutputKeys.INDENT, "YES");
// 文档字符编码
transformer.setOutputProperty(OutputKeys.ENCODING, "utf-8");
// 可随意指定文件的后缀,效果一样,但xml比较好解析,比如: E:\\person.txt等
transformer.transform(new DOMSource(doc),new StreamResult(file));
System.out.println("XML CreateDocument success!");
} catch (ParserConfigurationException e) {
e.printStackTrace();
} catch (TransformerConfigurationException e) {
e.printStackTrace();
} catch (TransformerException e) {
e.printStackTrace();
}
}
}
XML文件效果图:
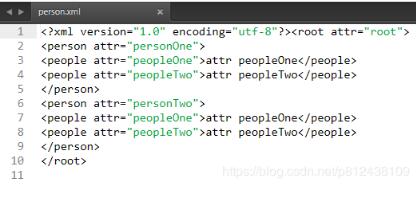
三)Document解析XML
实现步骤:
第一步:先获取需要解析的文件,判断文件是否已经存在或有效
第二步:初始化一个XML解析工厂
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
第三步:创建一个DocumentBuilder实例
DocumentBuilder builder = factory.newDocumentBuilder();
第四步:创建一个解析XML的Document实例
Document doc = builder.parse(file);
第五步:先获取根节点的信息,然后根据根节点递归一层层解析XML
实现源码:
package com.oysept.xml;
import java.io.File;
import java.io.IOException;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import org.w3c.dom.Attr;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.NamedNodeMap;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.xml.sax.SAXException;
/**
* Document解析XML
* @author ouyangjun
*/
public class ParseDocument {
public static void main(String[] args){
File file = new File("E:\\person.xml");
if (!file.exists()) {
System.out.println("xml文件不存在,请确认!");
} else {
parseDocument(file);
}
}
public static void parseDocument(File file) {
try{
// 初始化一个XML解析工厂
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
// 创建一个DocumentBuilder实例
DocumentBuilder builder = factory.newDocumentBuilder();
// 创建一个解析XML的Document实例
Document doc = builder.parse(file);
// 获取根节点名称
String rootName = doc.getDocumentElement().getTagName();
System.out.println("根节点: " + rootName);
System.out.println("递归解析--------------begin------------------");
// 递归解析Element
Element element = doc.getDocumentElement();
parseElement(element);
System.out.println("递归解析--------------end------------------");
} catch (ParserConfigurationException e) {
e.printStackTrace();
} catch (SAXException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
// 递归方法
public static void parseElement(Element element) {
System.out.print("<" + element.getTagName());
NamedNodeMap attris = element.getAttributes();
for (int i = 0; i < attris.getLength(); i++) {
Attr attr = (Attr) attris.item(i);
System.out.print(" " + attr.getName() + "=\"" + attr.getValue() + "\"");
}
System.out.println(">");
NodeList nodeList = element.getChildNodes();
Node childNode;
for (int temp = 0; temp < nodeList.getLength(); temp++) {
childNode = nodeList.item(temp);
// 判断是否属于节点
if (childNode.getNodeType() == Node.ELEMENT_NODE) {
// 判断是否还有子节点
if(childNode.hasChildNodes()){
parseElement((Element) childNode);
} else if (childNode.getNodeType() != Node.COMMENT_NODE) {
System.out.print(childNode.getTextContent());
}
}
}
System.out.println("</" + element.getTagName() + ">");
}
}
XML解析效果图:

以上这篇Java xml数据格式返回实现操作就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
SpringMvc响应数据及结果视图实现代码
响应数据和结果视图 返回值分类 controller 方法返回字符串可以指定逻辑视图名,通过视图解析器解析为物理视图地址. //指定逻辑视图名,经过视图解析器解析为 jsp 物理路径:/WEB-INF/pages/success.jsp @RequestMapping("/testReturnString") public String testReturnString() { System.out.println("AccountController 的 testRetur
-
Java如何读取XML文件 具体实现
今天的CSDN常见问题来讲解下在Java中如何读取XML文件的内容. 直接上代码吧,注释写的很清楚了! 复制代码 代码如下: import java.io.*;import javax.xml.parsers.DocumentBuilder;import javax.xml.parsers.DocumentBuilderFactory;import org.w3c.dom.Document;import org.w3c.dom.Element;import org.w3c.dom.Node;im
-

Java实现后台发送及接收json数据的方法示例
本文实例讲述了Java实现后台发送及接收json数据的方法.分享给大家供大家参考,具体如下: 本篇博客试用于编写java后台接口以及两个项目之间的接口对接功能: 具体的内容如下: 1.java后台给指定接口发送json数据 package com.utils; import java.io.BufferedReader; import java.io.InputStreamReader; import java.io.OutputStreamWriter; import java.net.Htt
-
SpringBoot返回json和xml的示例代码
有些情况接口需要返回的是xml数据,在springboot中并不需要每次都转换一下数据格式,只需做一些微调整即可. 新建一个springboot项目,加入依赖jackson-dataformat-xml,pom文件代码如下: <?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi=&qu
-
Java xml数据格式返回实现操作
前言:对于服务器后端开发,接口返回的数据格式一般要求都是json,但是也有使用xml格式 RequestBody注解 对于SpringMVC,很多人会认为接口方法使用@Controller搭配@ResponseBody和@RequestMapping注解后,java对象会转换成json格式返回. 但实际上配合@ResponseBody注解后,接口返回的数据类型是根据HTTP Request Header中的Accept属性来确定的,可以是XML或者JSON数据 通过适当的HttpMessageC
-
Java访问WebService返回XML数据的方法
本文实例讲述了Java访问WebService返回XML数据的方法.分享给大家供大家参考.具体如下: import java.io.IOException; import java.io.InputStream; import java.net.MalformedURLException; import java.net.URL; import java.net.URLConnection; import java.io.FileNotFoundException; import java.io
-
Java List集合返回值去掉中括号(''[ ]'')的操作
如下所示: 调用StringUtils工具类的strip()方法去掉中括号"[ ]": StringUtils.strip(word.toString(),"[]") //第一个参数放集合,第二个参数去掉中括号"[]" StringUtils工具类代码: package com.ktamr.common.utils; import com.ktamr.common.core.text.StrFormatter; import java.util.
-
Java xml出现错误 javax.xml.transform.TransformerException: java.lang.NullPointerException
Java xml出现错误 javax.xml.transform.TransformerException: java.lang.NullPointerException解决办法: 利用Java操作XML,在操作XML过程中,执行到最后一步,在利用Transformer进行XML转换时出现NullPointerException错误,出问题的部分代码如下: //转换 TransformerFactory tFactory =TransformerFactory.newInstance(); Tr
-
Android利用Document实现xml读取和写入操作
本文实例为大家分享了利用Document实现xml读取和写入操作,供大家参考,具体内容如下 首先先来介绍一下什么xml?xml是可扩展标记语言,他可以用来标记数据,定义数据类型.是一种允许用户对自己标记语言进行定义的源语言.解析XML文件的方法有很多方法:dom解析,就是document以及PULL和SAX方法.今天给大家分享一下如何用Document来操作XML. 效果图: 首先先对布局文件进行操作:activity_main.xml: <?xml version="1.0"
-
Spring实战之获取方法返回值操作示例
本文实例讲述了Spring实战之获取方法返回值操作.分享给大家供大家参考,具体如下: 一 配置文件 <?xml version="1.0" encoding="GBK"?> <beans xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://www.springframework.org/schema/beans" xmlns:
-
java使用反射创建并操作对象的方法
Class 对象可以获得该类里的方法(由 Method 对象表示).构造器(由 Constructor 对象表示).成员变量(由 Field 对象表示),这三个类都位于 java.lang.reflect 包下,并实现了 java.lang.reflect.Member 接口.程序可以通过对象来执行对应的方法,通过 Constructor 对象来调用对应的构造器创建实例,能通过 Field 对象直接访问并修改对象的成员变量值. 创建对象 通过反射来生成对象需要先使用 Class 对象获取指定的
-
Java后台Controller实现文件下载操作
代码 参数: 1.filePath:文件的绝对路径(d:\download\a.xlsx) 2.fileName(a.xlsx) 3.编码格式(GBK) 4.response.request不介绍了,从控制器传入的http对象 代码片. //控制器 @RequestMapping(UrlConstants.BLACKLIST_TESTDOWNLOAD) public void downLoad(String filePath, HttpServletResponse response, Http
-
Java实现Excel导入导出操作详解
目录 前言 1. 功能测试 1.1 测试准备 1.2 数据导入 1.2.1 导入解析为JSON 1.2.2 导入解析为对象(基础) 1.2.3 导入解析为对象(字段自动映射) 1.2.4 导入解析为对象(获取行号) 1.2.5 导入解析为对象(获取原始数据) 1.2.6 导入解析为对象(获取错误提示) 1.2.7 导入解析为对象(限制字段长度) 1.2.8 导入解析为对象(必填字段验证) 1.2.9 导入解析为对象(数据唯一性验证) 1.3 数据导出 1.3.1 动态导出(基础) 1.3.2 动
-
Java实现截取字符串的操作详解
目录 使用JDK截断一个字符串 使用 String 的 substring() 方法 使用 String 的 split() 方法 使用 Pattern 类 使用 CharSequence 的 codePoints() 方法 Apache Commons 库 使用 StringUtils的left() 方法 使用 StringUtils 的 truncate() 方法 Guava库 总结 大家好,我是指北君. 在本文中,我们将学习在Java中把一个String截断到所需的字符数的集中方法. 首先