详解NumPy中的线性关系与数据修剪压缩
目录
- 摘要
- 一、用线性模型预测价格
- 二、趋势线
- 三、数组的修剪和压缩
- 四、阶乘
摘要
总结股票均线计算原理--线性关系,也是以后大数据处理的基础之一,NumPy的 linalg 包是专门用于线性代数计算的。作一个假设,就是一个价格可以根据N个之前的价格利用线性模型计算得出。
前一篇,在计算均线,指数均线时,分别计算了不同的权重,比如

和
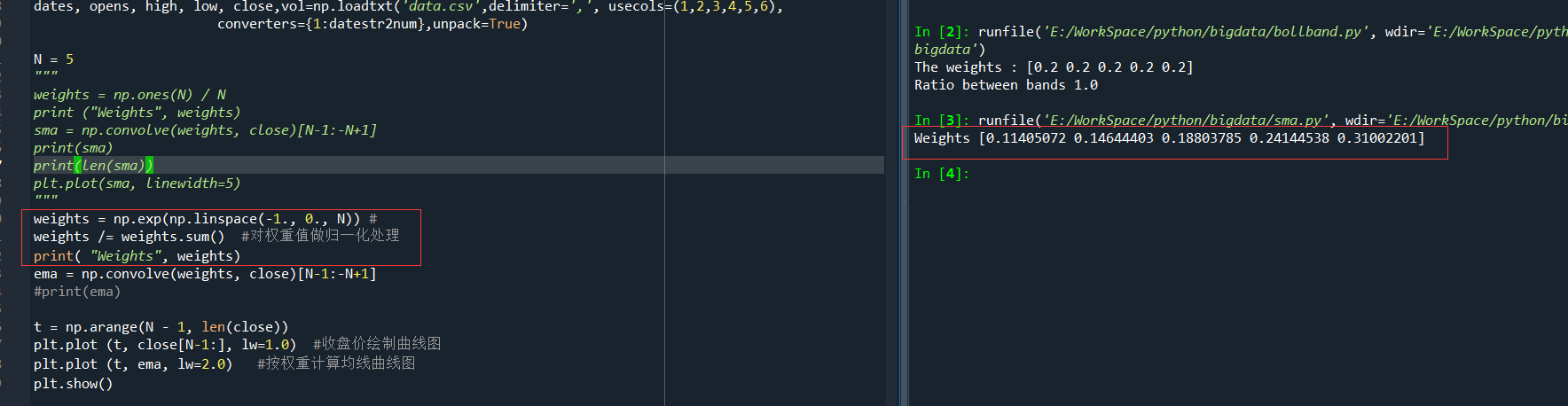
都是按不同的计算方法来计算出相关的权重,一个股价可以用之前股价的线性组合表示出来,也即,这个股价等于之前的股价与各自的系数相乘后再做加和的结果,但是,这些系数是需要我们来确定的,也即一个线性相关的权重。
一、用线性模型预测价格
创建步骤如下:
1)先获取一个包含N个收盘价的向量(数组):
N=10 #N=len(close) new_close = close[-N:] new_closes= new_close[::-1] print (new_closes)
运行结果:
[39.96 38.03 38.5 38.6 36.89 37.15 36.61 37.21 36.98 36.47]
2)初始化一个N×N的二维数组 A ,元素全部为 0
A = np.zeros((N, N), float)
print ("Zeros N by N", A)
3)用数组new_closes的股价填充数组A
for i in range(N):
A[i,] = close[-N-i-1: -1-i]
print( "A", A)
试一下运行结果,并观察填充后的数组A

4)选取合适的权重
Weights [0.11405072 0.14644403 0.18803785 0.24144538 0.31002201]和The weights : [0.2 0.2 0.2 0.2 0.2]哪一种权重更合理?用线性代数的术语来说,就是解一个最小二乘法的问题。
要确定线性模型中的权重系数,就是解决最小平方和的问题,可以使用 linalg包中的 lstsq 函数来完成这个任务
(x, residuals, rank, s) = np.linalg.lstsq(A,new_closes)
其中,x是由A,new_closes通过np.linalg.lstsq()函数,即生成的权重(向量),residuals为残差数组、rank为A的秩、s为A的奇异值。
5)预测股价,用NumPy中的 dot()函数计算系数向量与最近N个价格构成的向量的点积(dot product),这个点积就是向量new_closes中价格的线性组合,系数由向量 x 提供
print( np.dot(new_closes, x))
完整代码如下:
import numpy as np
from datetime import datetime
import matplotlib.pyplot as plt
def datestr2num(s): #定义一个函数
return datetime.strptime(s.decode('ascii'),"%Y-%m-%d").date().weekday()
dates, opens, high, low, close,vol=np.loadtxt('data.csv',delimiter=',', usecols=(1,2,3,4,5,6),
converters={1:datestr2num},unpack=True)
N=10
#N=len(close)
new_close = close[-N:]
new_closes= new_close[::-1]
A = np.zeros((N, N), float)
for i in range(N):
A[i,] = close[-N-i-1: -1-i]
print( "A", A)
(x, residuals, rank, s) = np.linalg.lstsq(A,new_closes)
print(x) #权重系数向量
print('\n')
print(residuals) #残差数组
print('\n')
print(rank) #A的秩
print(s)
print('\n')#奇异值
print( np.dot(new_closes, x))
运行结果如下:

二、趋势线
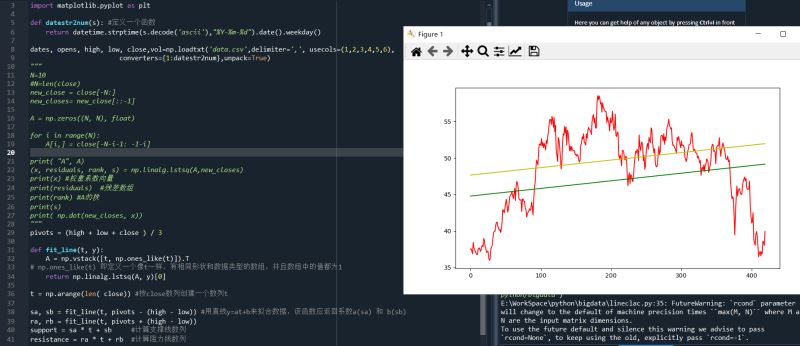
趋势线,是根据股价走势图上很多所谓的枢轴点绘成的曲线。描绘价格变化的趋势。可以让计算机来用非常简易的方法来绘制趋势线
(1) 确定枢轴点的位置。假定枢轴点位置 为最高价、最低价和收盘价的算术平均值。pivots = (high + low + close ) / 3
从枢轴点出发,可以推导出股价所谓的阻力位和支撑位。阻力位是指股价上升时遇到阻力,在转跌前的最高价格;支撑位是指股价下跌时遇到支撑,在反弹前的最低价格(阻力位和支撑位并非客观存在,它们只是一个估计量)。基于这些估计量,就可以绘制出阻力位和支撑位的趋势线。我们定义当日股价区间为最高价与最低价之差
(2) 定义一个函数用直线 y= at + b 来拟合数据,该函数应返回系数 a 和 b,再次用到 linalg 包中的 lstsq 函数。将直线方程重写为 y = Ax 的形式,其中 A = [t 1] , x = [a b] 。使用 ones_like 和 vstack 函数来构造数组 A
numpy.ones_like(a, dtype=None, order='K', subok=True) 返回与指定数组具有相同形状和数据类型的数组,并且数组中的值都为1。
numpy.vstack(tup) [source] 垂直(行)按顺序堆叠数组。 这等效于形状(N,)的1-D数组已重塑为(1,N)后沿第一轴进行concatenation。 重建除以vsplit的数组。如下两小例:
>>> a = np.array([1, 2, 3])
>>> b = np.array([2, 3, 4])
>>> np.vstack((a,b))
array([[1, 2, 3],
[2, 3, 4]])
>>> a = np.array([[1], [2], [3]])
>>> b = np.array([[2], [3], [4]])
>>> np.vstack((a,b))
array([[1],
[2],
[3],
[2],
[3],
[4]])
完整代码如下:
import numpy as np
from datetime import datetime
import matplotlib.pyplot as plt
def datestr2num(s): #定义一个函数
return datetime.strptime(s.decode('ascii'),"%Y-%m-%d").date().weekday()
dates, opens, high, low, close,vol=np.loadtxt('data.csv',delimiter=',', usecols=(1,2,3,4,5,6),
converters={1:datestr2num},unpack=True)
"""
N=10
#N=len(close)
new_close = close[-N:]
new_closes= new_close[::-1]
A = np.zeros((N, N), float)
for i in range(N):
A[i,] = close[-N-i-1: -1-i]
print( "A", A)
(x, residuals, rank, s) = np.linalg.lstsq(A,new_closes)
print(x) #权重系数向量
print(residuals) #残差数组
print(rank) #A的秩
print(s)
print( np.dot(new_closes, x))
"""
pivots = (high + low + close ) / 3
def fit_line(t, y):
A = np.vstack([t, np.ones_like(t)]).T
# np.ones_like(t) 即定义一个像t一样,有相同形状和数据类型的数组,并且数组中的值都为1
return np.linalg.lstsq(A, y)[0]
t = np.arange(len( close)) #按close数列创建一个数列t
sa, sb = fit_line(t, pivots - (high - low)) #用直线y=at+b来拟合数据,该函数应返回系数a(sa) 和 b(sb)
ra, rb = fit_line(t, pivots + (high - low))
support = sa * t + sb #计算支撑线数列
resistance = ra * t + rb #计算阻力线数列
condition = (close > support) & (close < resistance)#设置一个判断数据点是否位于趋势线之间的条件,作为 where 函数的参数
between_bands = np.where(condition)
plt.plot(t, close,color='r')
plt.plot(t, support,color='g')
plt.plot(t, resistance,color='y')
plt.show()
运行结果:
三、数组的修剪和压缩
NumPy中的 ndarray 类定义了许多方法,可以对象上直接调用。通常情况下,这些方法会返回一个数组。
ndarray 对象的方法相当多,像前面遇到的 var 、 sum 、 std 、 argmax 、argmin 以及 mean 函数也均为 ndarray 方法。下面介绍一下数组的修前与压缩。
1、 clip 方法返回一个修剪过的数组:将所有比给定最大值还大的元素全部设为给定的最大值,而所有比给定最小值还小的元素全部设为给定的最小值
a = np.arange(10)
print("a =", a)
print("Clipped", a.clip(3, 7))
运行结果:
a = [0 1 2 3 4 5 6 7 8 9]
Clipped [3 3 3 3 4 5 6 7 7 7]
很明显,a.clip(3,7)将数组a中的小于3的设置为3,大于7的全部设置为7.
2、 compress 方法返回一个根据给定条件筛选后的数组
b = np.arange(10)
print (a)
print ("Compressed", a.compress(a >3))
运行结果:
[0 1 2 3 4 5 6 7 8 9]
Compressed [4 5 6 7 8 9]
四、阶乘
prod() 方法,可以计算数组中所有元素的乘积.
c = np.arange(1,5)
print("b =", c)
print("Factorial", c.prod())
运行结果:
b = [1 2 3 4]
Factorial 24
如果想知道1~8的所有阶乘值,调用 cumprod()方法,计算数组元素的累积乘积。
print( "Factorials", c.cumprod())
运行结果:
Factorials [ 1 2 6 24 120]

本篇主要介绍了一个通过现在有数据,用函数 y= at + b 来拟合数据进行线性拟合后,用 linalg包中的 lstsq 函数来完成最小二乘相关后,预测股价的实例,来了解了一些numpy的函数及作用;同时介绍了数据修剪及压缩和阶乘的计算。
以上就是详解NumPy中的线性关系与数据修剪压缩的详细内容,更多关于NumPy线性关系 数据修剪压缩的资料请关注我们其它相关文章!
相关推荐
-

NumPy实现多维数组中的线性代数
目录 简介 图形加载和说明 图形的灰度 灰度图像的压缩 原始图像的压缩 总结 简介 本文将会以图表的形式为大家讲解怎么在NumPy中进行多维数据的线性代数运算. 多维数据的线性代数通常被用在图像处理的图形变换中,本文将会使用一个图像的例子进行说明. 图形加载和说明 熟悉颜色的朋友应该都知道,一个颜色可以用R,G,B来表示,如果更高级一点,那么还有一个A表示透明度.通常我们用一个四个属性的数组来表示. 对于一个二维的图像来说,其分辨率可以看做是一个X*Y的矩阵,矩阵中的每个点的颜色都可以用(R,G
-
Numpy实现矩阵运算及线性代数应用
一.创建矩阵的方法 import numpy as np # 1直接创建 mat=np.mat("1 2 3;4 5 6;7 8 9") print(mat) # 2使用numpy数组创建矩阵 mat2=np.mat(np.arange(1,10).reshape(3,3)) print(mat2) # 3从已有的矩阵中通过bmat函数创建 A=np.eye(2) B=A*2 mat3=np.bmat("A B;B A") print(mat3) #类似于拼接 二.
-
Python numpy线性代数用法实例解析
这篇文章主要介绍了Python numpy线性代数用法实例解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 numpy中线性代数用法 矩阵乘法 >>> import numpy as np >>> x=np.array([[1,2,3],[4,5,6]]) >>> y=np.array([[7,8],[-1,7],[8,9]]) >>> x array([[1, 2, 3], [4
-
Python数据分析之NumPy常用函数使用详解
目录 文件读入 1.保存或创建新文件 2.读取csv文件的函数loadtxt 3.常见的函数 4.股票的收益率等 5.对数收益与波动率 6.日期分析 总结 本篇我们将以分析历史股价为例,介绍怎样从文件中载入数据,以及怎样使用NumPy的基本数学和统计分析函数.学习读写文件的方法,并尝试函数式编程和NumPy线性代数运算,来学习NumPy的常用函数. 文件读入 读写文件是数据分析的一项基本技能 CSV(Comma-Separated Value,逗号分隔值)格式是一种常见的文件格式.通常,数据库的
-
Python Numpy中数据的常用保存与读取方法
在经常性读取大量的数值文件时(比如深度学习训练数据),可以考虑现将数据存储为Numpy格式,然后直接使用Numpy去读取,速度相比为转化前快很多. 下面就常用的保存数据到二进制文件和保存数据到文本文件进行介绍: 1.保存为二进制文件(.npy/.npz) numpy.save 保存一个数组到一个二进制的文件中,保存格式是.npy 参数介绍 numpy.save(file, arr, allow_pickle=True, fix_imports=True) file:文件名/文件路径 arr:要存
-
详解NumPy中的线性关系与数据修剪压缩
目录 摘要 一.用线性模型预测价格 二.趋势线 三.数组的修剪和压缩 四.阶乘 摘要 总结股票均线计算原理--线性关系,也是以后大数据处理的基础之一,NumPy的 linalg 包是专门用于线性代数计算的.作一个假设,就是一个价格可以根据N个之前的价格利用线性模型计算得出. 前一篇,在计算均线,指数均线时,分别计算了不同的权重,比如 和 都是按不同的计算方法来计算出相关的权重,一个股价可以用之前股价的线性组合表示出来,也即,这个股价等于之前的股价与各自的系数相乘后再做加和的结果,但是,这些系数是
-
详解Mybatis-plus中更新date类型数据遇到的坑
最近一年的项目都是在使用Mybatis-plus,感觉挺好用的,也没遇到很多问题,但是在最近项目上线之后,遇到了一些新的需要,在进行新版本开发的时候就开始遇到坑了,今天来说一下更新数据中有date类型数据的时候会出现的问题. 实体类部分字段如下: @Data @Builder @NoArgsConstructor @AllArgsConstructor public class ProductPo implements Serializable { /** * 产品主键,自增 */ privat
-
详解Numpy中的数组拼接、合并操作(concatenate, append, stack, hstack, vstack, r_, c_等)
Numpy中提供了concatenate,append, stack类(包括hsatck.vstack.dstack.row_stack.column_stack),r_和c_等类和函数用于数组拼接的操作. 各种函数的特点和区别如下标: concatenate 提供了axis参数,用于指定拼接方向 append 默认先ravel再拼接成一维数组,也可指定axis stack 提供了axis参数,用于生成新的维度 hstack 水平拼接,沿着行的方向,对列进行拼接 vstack 垂直拼接,沿着列的
-
详解angularJs中自定义directive的数据交互
就我对directive的粗浅理解,它一般用于独立Dom元素的封装,应用场合为控件重用和逻辑模块分离.后者我暂时没接触,但数据交互部分却是一样的.所以举几个前者的例子,以备以后忘记. directive本身的作用域$scope可以选择是否封闭,不封闭则和其controller共用一个作用域$scope.例子如下: <body ng-app="myApp" ng-controller="myCtrl"> <test-directive><
-
详解vue 中使用 AJAX获取数据的方法
在VUE开发时,数据可以使用jquery和vue-resource来获取数据.在获取数据时,一定需要给一个数据初始值. 看下例: <script type="text/javascript"> new Vue({ el:'#app', data:{data:""}, created:function(){ var url="json.jsp"; var _self=this; $.get(url,function(data){ _se
-
详解Numpy中的广播原则/机制
广播的原则 如果两个数组的后缘维度(从末尾开始算起的维度)的轴长度相符或其中一方的长度为1,则认为它们是广播兼容的.广播会在缺失维度和(或)轴长度为1的维度上进行. 在上面的对arr每一列减去列平均值的例子中,arr的后缘维度为3,arr.mean(0)后缘维度也是3,满足轴长度相符的条件,广播会在缺失维度进行. 这里有点奇怪的是缺失维度不是axis=1,而是axis=0,个人理解是缺失维度指的是两个arr除了轴长度匹配的维度,在上面的例子中,正好是axis=0.这块欢迎指正 arr.mean(
-
对numpy中二进制格式的数据存储与读取方法详解
使用save可以实现对numpy数据的磁盘存储,存储的方式是二进制.查看使用说明,说明专门提到了是未经压缩的二进制形式.存储后的数据可以进行加载或者读取,通过使用load方法. In [81]:np.save('demo',data1) 通过以上操作,数据data1被存储到了demo文件中,numpy会自动加上npy的文件后缀名. In [82]: a =np.load('demo.npy') In [83]: a Out[83]: array([0,1, 2, 3, 4, 5, 6, 7, 8
-
详解pandas中利用DataFrame对象的.loc[]、.iloc[]方法抽取数据
pandas的DataFrame对象,本质上是二维矩阵,跟常规二维矩阵的差别在于前者额外指定了每一行和每一列的名称.这样内部数据抽取既可以用"行列名称(对应.loc[]方法)",也可以用"矩阵下标(对应.iloc[]方法)"两种方式进行. 下面具体说明: (以下程序均在Jupyter notebook中进行,部分语句的print()函数省略) 首先生成一个DataFrame对象: import pandas as pd score = [[34,67,87],[68
-
详解Python中生成随机数据的示例详解
目录 随机性有多随机 加密安全性 PRNG random 模块 数组 numpy.random 相关数据的生成 random模块与NumPy对照表 CSPRNG 尽可能随机 os.urandom() secrets 最佳保存方式 UUID 工程随机性的比较 在日常工作编程中存在着各种随机事件,同样在编程中生成随机数字的时候也是一样,随机有多随机呢?在涉及信息安全的情况下,它是最重要的问题之一.每当在 Python 中生成随机数据.字符串或数字时,最好至少大致了解这些数据是如何生成的. 用于在 P
-
详解javaweb中jstl如何循环List中的Map数据
详解javaweb中jstl如何循环List中的Map数据 第一种方式: 1:后台代码(测试) List<Map<String, Object>> list = new ArrayList<Map<String,Object>>(); Map<String, Object> map = null; for (int i = 0; i < 4; i++) { map = new HashMap<String, Object>();