详解Python OpenCV图像分割算法的实现
目录
- 前言
- 1.图像二值化
- 2.自适应阈值分割算法
- 3.Otsu阈值分割算法
- 4.基于轮廓的字符分离
- 4.1轮廓检测
- 4.2轮廓绘制
- 4.3包围框获取
- 4.4矩形绘制
前言
图像分割是指根据灰度、色彩、空间纹理、几何形状等特征把图像划分成若干个互不相交的区域。
最简单的图像分割就是将物体从背景中分割出来
1.图像二值化
cv2.threshold是opencv-python中的图像二值化方法,可以实现简单的分割功能。
retval, dst = cv2.threshold(src, thresh, maxval, thresholdType[, dst])
•src:原图像,要求必须是灰度图像
•dst:结果图像
•thresh:阈值
•maxVal:结果图中像素最大值
•thresholdType:二值化类型

然而,threshold用法,有两个问题:
问题一:
•根据全图统一的阈值对像素进行判断,并非在所有情况下效果都好
•例如,如果图像在不同区域具有不同的光照条件

问题二:
•阈值需要手动设定,不同的图片合适的阈值可能不同,更换图片可能就需要调整代码

针对于全图统一阈值的问题,可以使用自适应阈值分割法
•自适应阈值分割算法基于像素周围的局部区域确定像素的阈值
•同一图像的不同区域具有不同的阈值
•为光照变化的图像提供更好的分割效果
2.自适应阈值分割算法
dst= cv2.adaptiveThreshold(src, maxValue, adaptiveMethod,thresholdType, blockSize, C, dst=None)
参数解释如下:
•src:原图像,它必须是灰度图像
•maxValue:结果图中像素的最大值,一般设置为255
•adaptiveMethod:阈值的计算方法,包括以下两种计算方式:

•thresholdType:二值化方式,例如cv2.THRESH_BINARY、cv2.THRESH_TRUNC、
cv2.THRESH_TOZERO等

•blockSize:局部区域的大小
•C:阈值计算中减去的常数
缺点:blockSize要手动指定,但物体的大小有差异
3.Otsu阈值分割算法
自动根据图像内容计算阈值:
- Otsu阈值分割算法
- 大津法
- 直方图技术
retval, dst = cv2.threshold(src, thresh, maxval, thresholdType[, dst])
参数解释如下:
- src:原图像,要求必须是灰度图像
- dst:结果图像
- thresh:阈值(无作用)
- maxVal:像素灰度最大值
- thresholdType:阈值类型,在原有参数值基础上多传递一个参数值,即cv2.THRESH_OTSU
- 比如cv2.THRESH_BINARY+cv2.THRESH_OTSU
利用固定阈值算法进行分割,适用的图片较为局限
同一个阈值,在一些图像上表现好,在其他图片上效果不佳
如:

利用Otsu阈值算法进行分割,适用的图片范围较广
对每张图片,Otsu阈值算法自动找到针对性的阈值
如:

4.基于轮廓的字符分离
分割步骤
1. 检测出图像中字符的轮廓
2. 得到每一条轮廓的包围框,根据包围框坐标提取ROI
4.1轮廓检测
contours, hierarchy = cv2.findContours(image, mode, method)
参数解释如下:
contours:返回的轮廓列表,每条轮廓包含构成这条轮廓上的一系列点的坐标
hierarchy:轮廓之间的层级关系
image:原始图像,需要是二值图
mode:轮廓的检索模式
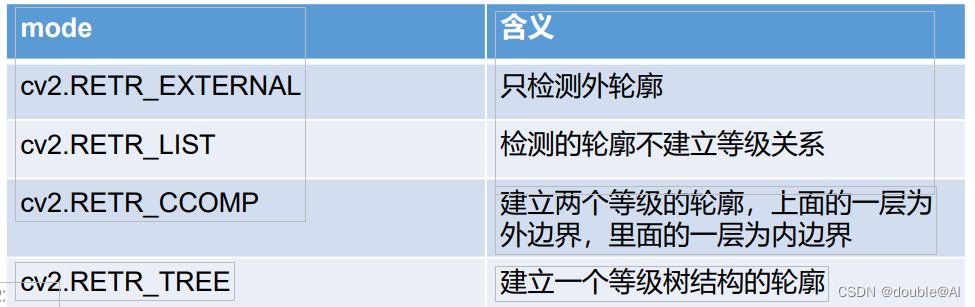
method:轮廓的近似办法

4.2轮廓绘制
cv2.drawContours(image, contours, contourIdx, color, thickness)
- image:指定在哪张图片上绘制轮廓
- contours:轮廓列表
- contourIdx:定绘制轮廓list中的哪条轮廓,如果是-1,则绘制其中的所有轮廓
- color:轮廓颜色
- thickness(可选):轮廓宽度
import cv2
img=cv2.imread("D:\\desk\\images\\car_license\\test1.png")
#去噪
image=cv2.GaussianBlur(img,(3,3),0)
#转为灰度图
gray1 = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
#Ostu阈值分割
ret, th1 = cv2.threshold(gray1, 127,255,cv2.THRESH_BINARY+cv2.THRESH_OTSU)
'''轮廓检测与绘制'''
#检测轮廓(外轮廓)
th1=cv2.dilate(th1,None) #膨胀,保证同一个字符只有一个外轮廓
contours,hierarchy=cv2.findContours(th1,cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_SIMPLE)
#轮廓可视化
th1_bgr=cv2.cvtColor(th1,cv2.COLOR_GRAY2BGR) #转为三通道图
cv2.drawContours(th1_bgr,contours,-1,(0,0,255),2) #轮廓可视化
cv2.imshow("th1_bgr",th1_bgr)
cv2.waitKey()
4.3包围框获取
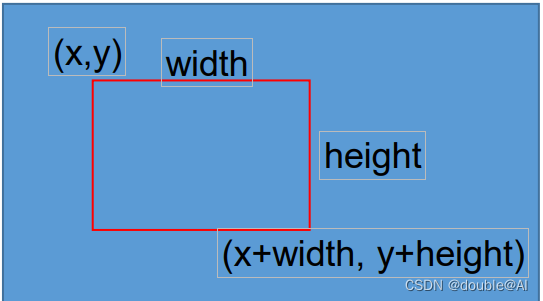
rect= cv2.boundingRect(points)
- points:一系列点的坐标
- rect:能够包围住这些点的最小外接矩形信息,格式为(x,y,width,height)
4.4矩形绘制
cv2.rectangle(img, pt1, pt2, color[, thickness)
- img:指定要绘制的图片
- pt1:矩形的某个顶点的坐标
- pt2:和pt1相对的顶点坐标
- color:矩形的颜色
- thickness(可选):矩形轮廓的宽度
基于轮廓的字符分离完整代码如下:
import cv2
img=cv2.imread("D:\\desk\\images\\car_license\\test1.png")
#去噪
image=cv2.GaussianBlur(img,(3,3),0)
#转为灰度图
gray1 = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
#Ostu阈值分割
ret, th1 = cv2.threshold(gray1, 127,255,cv2.THRESH_BINARY+cv2.THRESH_OTSU)
'''轮廓检测与绘制'''
#检测轮廓(外轮廓)
th1=cv2.dilate(th1,None) #膨胀,保证同一个字符只有一个外轮廓
contours,hierarchy=cv2.findContours(th1,cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_SIMPLE)
#轮廓可视化
th1_bgr=cv2.cvtColor(th1,cv2.COLOR_GRAY2BGR) #转为三通道图
# cv2.drawContours(th1_bgr,contours,-1,(0,0,255),2) #轮廓可视化
'''包围框获取'''
words=[] #保存包围框信息
height,width=th1.shape
for contour in contours: #对于每一条轮廓
rest=cv2.boundingRect(contour) #得到这条轮廓的外接矩阵
#只有高宽比在1.5到3.5之间,且高 度比图片高度大于0.3的矩阵才保留
if rest[3]/rest[2]>1.5 and rest[3]/rest[2]<3.5 and rest[3]/height>0.3:
words.append(rest) #将当前矩形加入矩形列表
cv2.rectangle(th1_bgr,(rest[0],rest[1]),(rest[0]+rest[2],rest[1]+rest[3]),(0,0,255),3) #绘制矩形
#显示
# cv2.imshow("img",img)
cv2.imshow("th1",th1)
cv2.imshow("th1_bgr",th1_bgr)
cv2.waitKey()
以上就是详解Python OpenCV图像分割算法的实现的详细内容,更多关于OpenCV图像分割算法的资料请关注我们其它相关文章!
相关推荐
-

Python 深入了解opencv图像分割算法
使用 OpenCV 函数 cv::filter2D 执行一些拉普拉斯滤波以进行图像锐化 使用 OpenCV 函数 cv::distanceTransform 以获得二值图像的派生(derived)表示,其中每个像素的值被替换为其到最近背景像素的距离 使用 OpenCV 函数 cv::watershed 将图像中的对象与背景隔离 加载源图像并检查它是否加载没有任何问题,然后显示它: # Load the image parser = argparse.ArgumentParser(descript
-
Python 第三方opencv库实现图像分割处理
目录 前言 1.加载图片 2.对图片做灰度处理 3.对图片做二值化处理 3.1.自定义阈值 4.提取轮廓 5.对轮廓画矩形框 6.分割图片并保存 7.查看分割图片 8.完整代码 前言 所需要安装的库有: pip install opencv-python pip install matplotlib Python接口帮助文档网址:https://docs.opencv.org/4.5.2/d6/d00/tutorial_py_root.html 本文所用到的图片素材: 首先,导入所用到的库: i
-
OpenCV学习之图像的分割与修复详解
目录 背景 一.分水岭法 二.GrabCut法 三.MeanShift法 四.MOG前景背景分离法 五.拓展方法 六.图像修复 总结 背景 图像分割本质就是将前景目标从背景中分离出来.在当前的实际项目中,应用传统分割的并不多,大多是采用深度学习的方法以达到更好的效果:当然,了解传统的方法对于分割的整体认知具有很大帮助,本篇将介绍些传统分割的一些算法: 一.分水岭法 原理图如下: 利用二值图像的梯度关系,设置一定边界,给定不同颜色实现分割: 实现步骤: 标记背景 —— 标记前景 —— 标记未知区域
-
基于OpenCV实现图像分割
本文实例为大家分享了基于OpenCV实现图像分割的具体代码,供大家参考,具体内容如下 1.图像阈值化 源代码: #include "opencv2/highgui/highgui.hpp" #include "opencv2/imgproc/imgproc.hpp" #include <iostream> using namespace std; using namespace cv; int thresholds=50; int model=2; Ma
-
openCV实现图像分割
本次实验为大家分享了openCV实现图像分割的具体实现代码,供大家参考,具体内容如下 一.实验目的 进一步理解图像的阈值分割方法和边缘检测方法的原理. 掌握图像基本全局阈值方法和最大类间方差法(otsu法)的原理并编程实现. 编程实现图像的边缘检测. 二.实验内容和要求 编程实现图像阈值分割(基本全局阈值方法和otsu法)和边缘检测. 三.实验主要仪器设备和材料 计算机,VS2017+OpenCV 四.实验原理与方法 图像的阈值分割的基本原理 图像的二值化处理图像分割中的一个主要内容,就是将图像
-
Opencv实现用于图像分割分水岭算法
目标 • 使用分水岭算法基于掩模的图像分割 • 学习函数: cv2.watershed() 原理 任何一幅灰度图像都可以被看成拓扑平面,灰度值高的区域可以被看成是山峰,灰度值低的区域可以被看成是山谷.我们向每一个山谷中灌不同颜色的水,随着水的位的升高,不同山谷的水就会相遇汇合,为了防止不同山谷的水汇合,我们需要在水汇合的地方构建起堤坝.不停的灌水,不停的构建堤坝直到所有的山峰都被水淹没.我们构建好的堤坝就是对图像的分割.这就是分水岭算法的背后哲理. 但是这种方法通常都会得到过度分割的结果
-
详解Python OpenCV图像分割算法的实现
目录 前言 1.图像二值化 2.自适应阈值分割算法 3.Otsu阈值分割算法 4.基于轮廓的字符分离 4.1轮廓检测 4.2轮廓绘制 4.3包围框获取 4.4矩形绘制 前言 图像分割是指根据灰度.色彩.空间纹理.几何形状等特征把图像划分成若干个互不相交的区域. 最简单的图像分割就是将物体从背景中分割出来 1.图像二值化 cv2.threshold是opencv-python中的图像二值化方法,可以实现简单的分割功能. retval, dst = cv2.threshold(src, thresh
-
详解Python+opencv裁剪/截取图片的几种方式
前言 在计算机视觉任务中,如图像分类,图像数据集必不可少.自己采集的图片往往存在很多噪声或无用信息会影响模型训练.因此,需要对图片进行裁剪处理,以防止图片边缘无用信息对模型造成影响.本文介绍几种图片裁剪的方式,供大家参考. 一.手动单张裁剪/截取 selectROI:选择感兴趣区域,边界框框选x,y,w,h selectROI(windowName, img, showCrosshair=None, fromCenter=None): . 参数windowName:选择的区域被显示在的窗口的名字
-
详解Python OpenCV数字识别案例
前言 实践是检验真理的唯一标准. 因为觉得一板一眼地学习OpenCV太过枯燥,于是在网上找了一个以项目为导向的教程学习.话不多说,动手做起来. 一.案例介绍 提供信用卡上的数字模板: 要求:识别出信用卡上的数字,并将其直接打印在原图片上.虽然看起来很蠢,但既然可以将数字打印在图片上,说明已经成功识别数字,因此也可以将其转换为数字文本保存.车牌号识别等项目的思路与此案例类似. 示例: 原图 处理后的图 二.步骤 大致分为如下几个步骤: 1.模板读入 2.模板预处理,将模板数字分开,并排序 3.输入
-
详解python opencv图像混合算术运算
目录 图片相加 cv2.add() 按位运算 图片相加 cv2.add() 要叠加两张图片,可以用 cv2.add() 函数,相加两幅图片的形状(高度 / 宽度 / 通道数)必须相同. numpy中可以直接用res = img + img1相加,但这两者的结果并不相同(看下边代码): add()两个图片进行加和,大于255的使用255计数. numpy会对结果取256(相当于255+1)的模: import numpy as np import c
-
详解Python+OpenCV进行基础的图像操作
目录 介绍 形态变换 腐蚀 膨胀 创建边框 强度变换 对数变换 线性变换 去噪彩色图像 使用直方图分析图像 介绍 众所周知,OpenCV是一个用于计算机视觉和图像操作的免费开源库. OpenCV 是用 C++ 编写的,并且有数千种优化的算法和函数用于各种图像操作.很多现实生活中的操作都可以使用 OpenCV 来解决.例如视频和图像分析.实时计算机视觉.对象检测.镜头分析等. 许多公司.研究人员和开发人员为 OpenCV 的创建做出了贡献.使用OpenCV 很简单,而且 OpenCV 配备了许多工
-
详解Python实现图像分割增强的两种方法
方法一 import random import numpy as np from PIL import Image, ImageOps, ImageFilter from skimage.filters import gaussian import torch import math import numbers import random class RandomVerticalFlip(object): def __call__(self, img): if random.random()
-
详解Python+OpenCV实现图像二值化
目录 一.图像二值化 1.效果 2.源码 二.图像二值化(调节阈值) 1.源码一 2.源码二 一.图像二值化 1.效果 2.源码 import cv2 import numpy as np import matplotlib.pyplot as plt # img = cv2.imread('test.jpg') #这几行是对图像进行降噪处理,但事还存在一些问题. # dst = cv2.fastNlMeansDenoisingColored(img,None,10,10,7,21) # plt
-
详解python OpenCV学习笔记之直方图均衡化
本文介绍了python OpenCV学习笔记之直方图均衡化,分享给大家,具体如下: 官方文档 – https://docs.opencv.org/3.4.0/d5/daf/tutorial_py_histogram_equalization.html 考虑一个图像,其像素值仅限制在特定的值范围内.例如,更明亮的图像将使所有像素都限制在高值中.但是一个好的图像会有来自图像的所有区域的像素.所以你需要把这个直方图拉伸到两端(如下图所给出的),这就是直方图均衡的作用(用简单的话说).这通常会改善图像的
-
详解python opencv、scikit-image和PIL图像处理库比较
进行深度学习时,对图像进行预处理的过程是非常重要的,使用pytorch或者TensorFlow时需要对图像进行预处理以及展示来观看处理效果,因此对python中的图像处理框架进行图像的读取和基本变换的掌握是必要的,接下来python中几个基本的图像处理库进行纵向对比. 项目地址:https://github.com/Oldpan/Pytorch-Learn/tree/master/Image-Processing 比较的图像处理框架: PIL scikit-image opencv-python
-
详解Python Opencv和PIL读取图像文件的差别
前言 之前在进行深度学习训练的时候,偶然发现使用PIL读取图片训练的效果要比使用python-opencv读取出来训练的效果稍好一些,也就是训练更容易收敛.可能的原因是两者读取出来的数据转化为pytorch中Tensor变量稍有不同,这里进行测试. 之后的代码都导入了: from PIL import Image import matplotlib.pyplot as plt import numpy as np import torch import cv2 测试 使用PIL和cv2读取图片时