Go 代码规范错误处理示例经验总结
目录
- 引言
- 一、相关联的声明放到一起
- 1、导包规范
- 2、常量、变量、类型声明
- 二、Go错误处理
- 1、失败的原因只有一个时,不使用 error
- 2、没有失败时,不使用 error
- 3、错误值统一定义
- 三、代码规范与实践
- 1、良好的命名与注释
- 2、美化SQL语句,避免 Select
- 3、避免阶梯缩进与代码紧凑
- 4、避免循环IO、上下文无关联的耗时动作采用Go协程
引言
编写代码应该要有极客追求,不要一味的只为了完成功能不加思索而噼里啪啦一顿操作,我认为应该要像一位设计者一样去设计代码完成功能,因为好的代码设计清晰可读易扩展、好修复、更少的学习成本。
因此我们应该学习并制定一些代码规范,如下是我学习Go语言中实战总结的一些经验,仅代表个人观点,大家可以互相讨论一下
一、相关联的声明放到一起
1、导包规范
// Bad import "logics/user_logic" import "logics/admin_logic" import "logics/goods_logic" // good import ( "logics/user_logic" "logics/admin_logic" "logics/goods_logic" )
分组导包
内置库
其他库
相关联库放在一起
// Bad import ( "fmt" "logics/user_logic" "logics/admin_logic" "strings" ) // Good import ( "fmt" "strings" // 逻辑处理 "logics/user_logic" "logics/admin_logic" // 数据库相关操作 "db/managers" "db/models" )
2、常量、变量、类型声明
在定义一些常量、变量与类型声明的时候,也是一样可以把相关联放到一起
常量
// Bad const YearMonthDay = "2006-01-02" const YearMonthDayHourMinSec = "2006-01-02 15:04:05" const DefaultTimeFmt = YearMonthDayHourMinSec // Good // TimeFormat 时间格式化 type TimeFormat string const ( YearMonthDay TimeFormat = "2006-01-02" // 年月日 yyyy-mm-dd YearMonthDayHourMinSec TimeFormat = "2006-01-02 15:04:05" // 年月年时分秒 yyyy-mm-dd HH:MM:SS DefaultTimeFmt TimeFormat = YearMonthDayHourMinSec // 默认时间格式化 )
变量
// Bad
var querySQL string
var queryParams []interface{}
// Good
var (
querySQL string
queryParams []interface{}
)
类型声明
// Bad type Area float64 type Volume float64 type Perimeter float64 // Good type ( Area float64 // 面积 Volume float64 // 体积 Perimeter float64 // 周长 )
枚举常量
// TaskAuditState 任务审核状态 type TaskAuditState int8 // Bad const TaskWaitHandle TaskAuditState = 0 // 待审核 const TaskSecondReview TaskAuditState = 1 // 复审 const TaskPass TaskAuditState = 2 // 通过 const TaskRefuse TaskAuditState = 3 // 拒绝 // Good const ( TaskWaitHandle TaskAuditState = iota // 待审核 TaskSecondReview // 复审 TaskPass // 通过 TaskRefuse // 拒绝 )
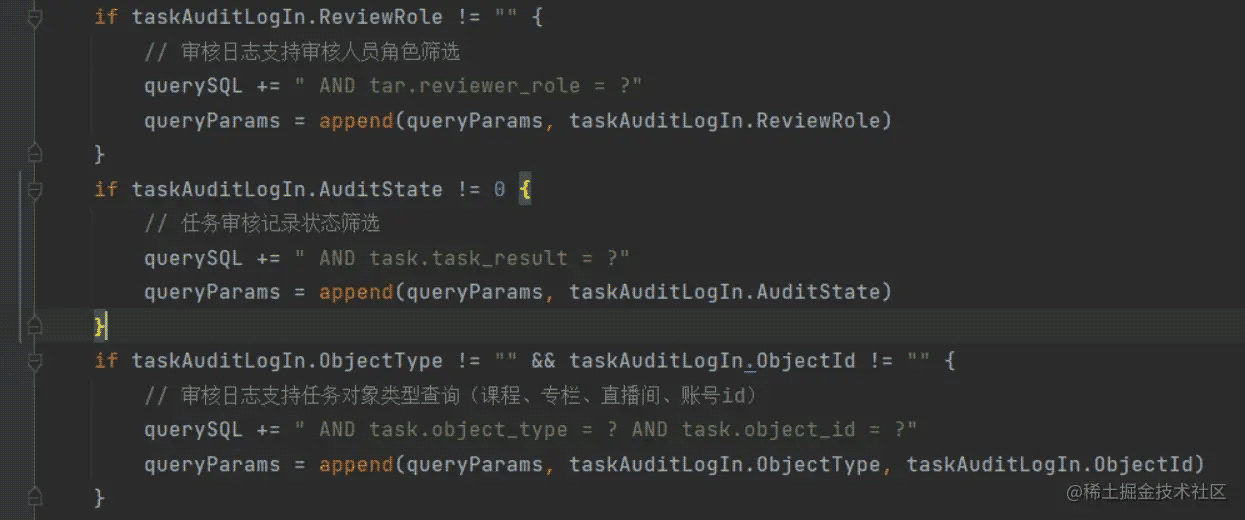
在进行Go开发时,指定一些非必选的入参时,不好区别空值是否有意义
如下 AuditState 是非必选参数,而 AuditState 在后端定义是 0 审核中、1复审、2通过、3拒绝,这都没什么问题,但框架解析参数时会把入参模型结构没有传值的参数设置成默认值,字符串类型是空串、数字类型是0等, 这样就会有问题如果前端传递参数的值是0、空值或者没有传递时,则无法判断是前端传递过来的还是框架默认设置的,导致后续逻辑不好写。
// QueryAuditTaskIn 查询任务入参
type QueryAuditTaskIn struct {
TeamCode string `query:"team_code" validate:"required"` // 团队编码
TaskType enums.RiskType `query:"task_type" validate:"required"` // 任务类型
TagId int `query:"tag_id" validate:"required"` // 标签id
AuditState constants.TaskAuditState `query:"audit_state"` // 审核状态
}
解决办法就是设计时让前端不要传递一些空值,整型枚举常量设置成 从1开始,这样更好的处理后续逻辑。
// TaskAuditState 定义审核状态类型 type TaskAuditState int8 const ( TaskWaitHandle TaskAuditState = iota + 1 // 待审核 TaskSecondReview // 复审 TaskPass // 通过 TaskRefuse // 拒绝 )
二、Go错误处理
在Go开发中会出现好多if err != nil 的判断
尤其我在使用 manager 操作数据库时一调用方法就要处理错误,还要向上层依次传递
manager(数据库操作层) -> logic(逻辑层) -> api(接口层),每一层都要处理错误从而导致
一大堆的 if err != nil
// DelSensitive 删除内部敏感词
func (sl SensitiveLogic) DelSensitive(banWordId uint32) error {
banWordManager, err := managers.NewBanWordsManager()
if err != nil {
return err
}
banWords, err := banWordManager.GetById(banWordId)
if err != nil{
return err
}
if banWords == nil {
return exceptions.NewBizError("屏蔽词不存在")
}
_, err = banWordManager.DeleteById(banWordId)
if err != nil {
return err
}
// 删除对应的敏感词前缀树,下一次文本审核任务进来的时候会重新构造敏感词前缀树
banWordsModel := banWords.(*models.BanWordsModel)
sensitive.DelTrie(banWordsModel.Scene, banWordsModel.TeamCode)
return nil
}
这样代码太不美观了如果改成如下看看
// DelSensitive 删除内部敏感词
func (sl SensitiveLogic) DelSensitive(banWordId uint32) {
banWordManager := managers.NewBanWordsManager()
banWords := banWordManager.GetById(banWordId)
if banWords == nil {
return
}
banWordManager.DeleteById(banWordId)
// 删除对应的敏感词前缀树,下一次文本审核任务进来的时候会重新构造敏感词前缀树
banWordsModel := banWords.(*models.BanWordsModel)
sensitive.DelTrie(banWordsModel.Scene, banWordsModel.TeamCode)
}
是不是美观多了,但这样出现出错误不能很好的定位到错误的位置以及日志记录,还会 panic 抛错误出来,导致协程终止执行,要等到 recover 恢复协程来中止 panic 造成的程序崩溃,从而影响性能。处理与不处理各有好处,我个人认为错误应该要处理但不要无脑的 if err != nil , 从而
可以在设计与规范上面来解决,对于一些严重的一定会导致程序奔溃的错误,可以自己统一设计错误类型,例如 数据库error 和 网络error 等,这种是很难避免的,即是避免了,系统也不能正常处理逻辑,因此对于这些 严重的错误可以手动 panic 然后在全局错误处理中记录日志信息,从而减少代码中的 if err != nil 的次数。如下
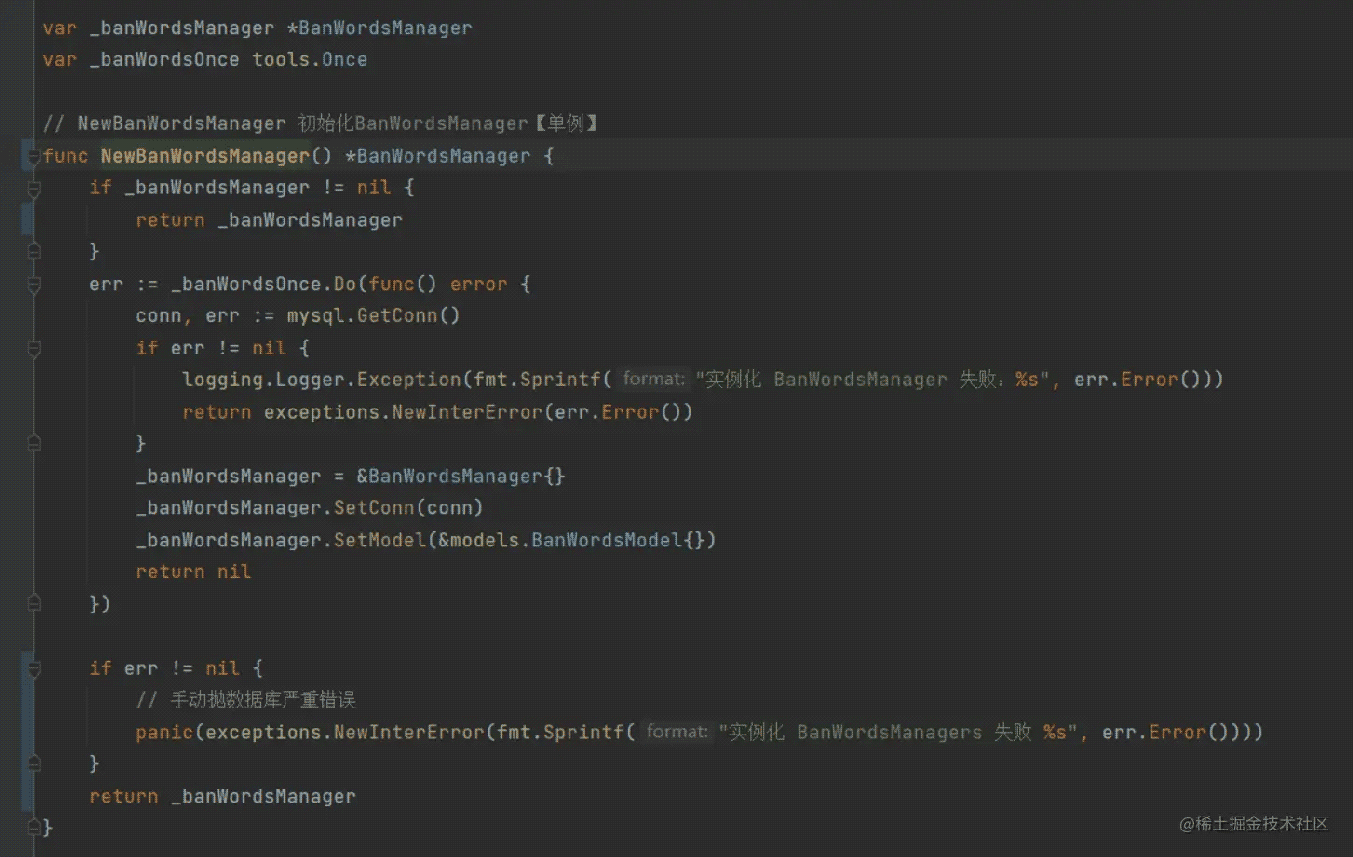
这样就不用一层一层传递 error ,但缺乏日志信息,虽然可以在上面的代码中打印日志信息,这样不太好,因此可以到全局错误那统一处理
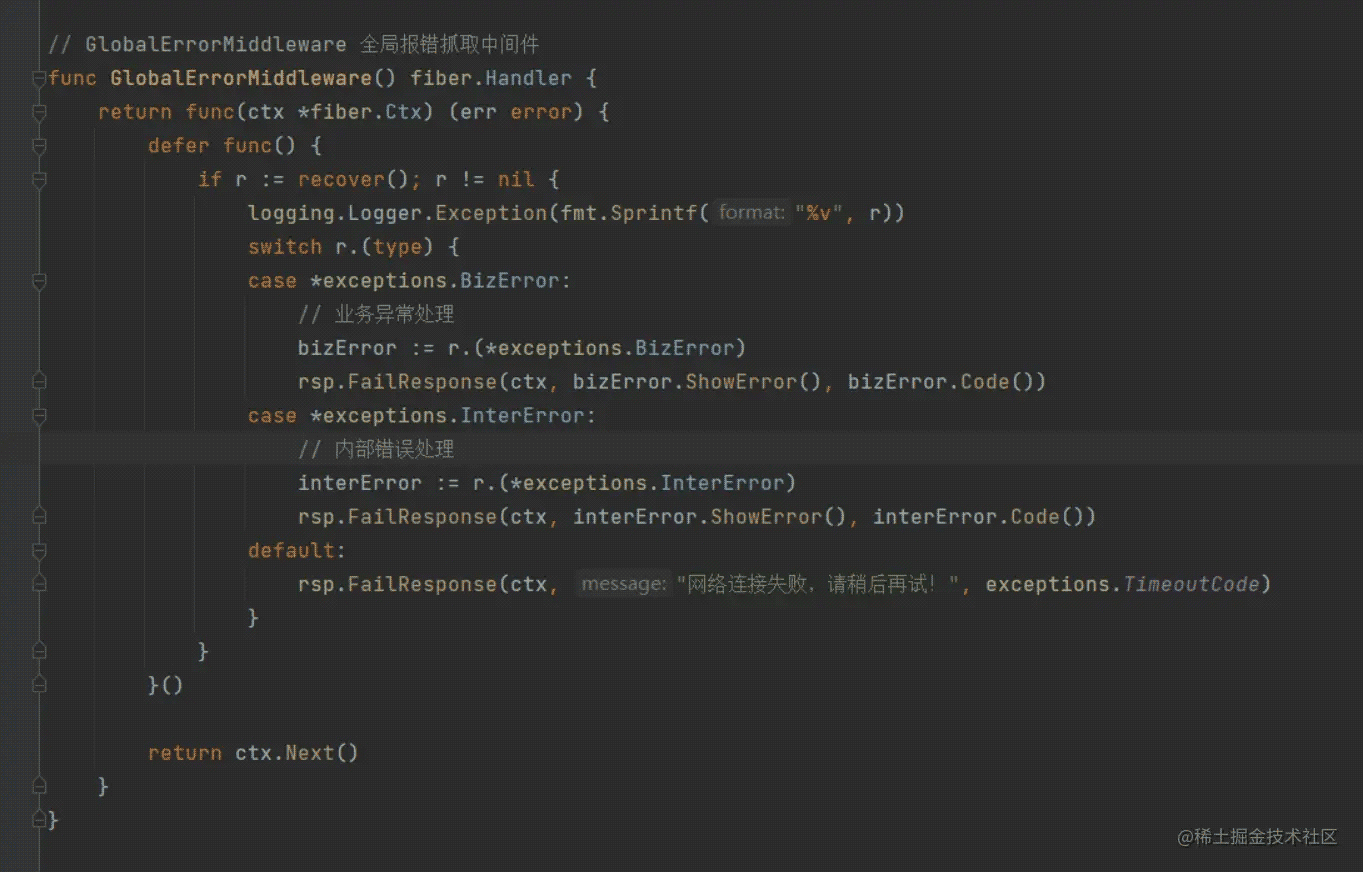
这里是之前的想法可以考虑下,但像一些业务异常太多了就会频繁 panic,导致性能不佳以及后续的一些协程问题,所以我上文提到自己设计错误以及规范,什么错误、异常可以 panic 什么不可以,从而来减少 if err != nil。
其次就是在设计函数的来避免错误的出现
1、失败的原因只有一个时,不使用 error
我们看一个案例:
func (self *AgentContext) CheckHostType(host_type string) error {
switch host_type {
case "virtual_machine":
return nil
case "bare_metal":
return nil
}
return errors.New("CheckHostType ERROR:" + host_type)
}
我们可以看出,该函数失败的原因只有一个,所以返回值的类型应该为 bool,而不是 error,重构一下代码:
func (self *AgentContext) IsValidHostType(hostType string) bool {
return hostType == "virtual_machine" || hostType == "bare_metal"
}
说明:大多数情况,导致失败的原因不止一种,尤其是对 I/O 操作而言,用户需要了解更多的错误信息,这时的返回值类型不再是简单的 bool,而是 error。
2、没有失败时,不使用 error
error 在 Golang 中是如此的流行,以至于很多人设计函数时不管三七二十一都使用 error,即使没有一个失败原因。我们看一下示例代码:
func (self *CniParam) setTenantId() error {
self.TenantId = self.PodNs
return nil
}
对于上面的函数设计,就会有下面的调用代码:
err := self.setTenantId()
if err != nil {
// log
// free resource return errors.New(...)
}
根据我们的正确姿势,重构一下代码:
func (self *CniParam) setTenantId() {
self.TenantId = self.PodNs
}
于是调用代码变为:
self.setTenantId()
3、错误值统一定义
很多人写代码时,到处 return errors.New(value),而错误 value 在表达同一个含义时也可能形式不同,比如“记录不存在”的错误 value 可能为:
errors.New("record is not existed.")
errors.New("record is not exist!")
errors.New("订单不存在")
这使得相同的错误 value 撒在一大片代码里,当上层函数要对特定错误 value 进行统一处理时,需要漫游所有下层代码,以保证错误 value 统一,不幸的是有时会有漏网之鱼,而且这种方式严重阻碍了错误 value 的重构。
在每个业务系统中维护一个错误对象定义文件,一些公用的错误则封装到Go的公用库中
业务系统错误封装:
package exceptions
// err_struct.go
// OrderBizError 订单系统业务错误结构体
type OrderBizError struct {
message string // 错误信息
code ErrorCode // 响应码
sysName string // 系统名称
}
func NewOrderBizError(message string, errorCode ...ErrorCode) *OrderBizError {
code := FailCode
if len(errorCode) > 0 {
code = errorCode[0]
}
return &OrderBizError{
code: code,
message: message,
sysName: "HuiYiMall—OrderSystem", // 可抽到微服务公用库中
}
}
// Code 状态码
func (b OrderBizError) Code() ErrorCode {
return b.code
}
// Message 错误信息
func (b OrderBizError) Message() string {
return b.message
}
// err_const.go
// ErrorCode 定义错误code类型
type ErrorCode string
const (
OrderTimeoutErrCode ErrorCode = "4000" // 订单超时
OrderPayFailErrCode ErrorCode = "4001" // 订单支付失败
)
var (
OrderTimeoutErr = NewOrderBizError("order timeout", OrderTimeoutErrCode)
OrderPayFailErr = NewOrderBizError("order pay fail", OrderPayFailErrCode)
)
返回错误信息给前端则返回状态码和信息,日志则记录全部的错误信息
Go公用库错误封装:
// err_struct.go
// BizError 业务错误结构体
type BizError struct {
message string // 错误信息
code ErrorCode // 响应码
}
// Code 状态码
func (b BizError) Code() ErrorCode {
return b.code
}
// Message 错误信息
func (b BizError) Message() string {
return b.message
}
func NewBizError(message string, errorCode ...ErrorCode) *BizError {
code := FailCode
if len(errorCode) > 0 {
code = errorCode[0]
}
return &BizError{
code: code,
message: message,
}
}
// err_const.go
const (
SuccessCode ErrorCode = "0000" // 成功
FailCode ErrorCode = "0403" // 失败
AuthorizationCode ErrorCode = "0403" // 认证错误
// ...
)
var (
Success = NewOrderBizError("Success", SuccessCode)
FailErr = NewOrderBizError("Fail", FailCode)
AuthorizationErr = NewOrderBizError("Authorization Error", AuthorizationCode)
// ...
)
其实每个业务系统的结构体可以继承公用的
// BizError 业务错误结构体
type BizError struct {
message string // 错误信息
code ErrorCode // 响应码
}
// OrderBizError 订单系统业务错误结构体
type OrderBizError struct {
BizError
sysName string // 系统名称
}
然后使用的时候就可以不要每次都自己单独的定义错误码和信息
三、代码规范与实践
1、良好的命名与注释
生成Swaager接口文档注释尽量对齐
// QueryAuditTask 查询已领取的审核任务
// @Summary 查询已领取的审核任务
// @Tags 审核管理接口
// @Accept json
// @Produce json
// @Param team_code query string true "团队编码"
// @Param task_type query string true "风控类型"
// @Param tag_id query string true "审核任务类型标签ID"
// @Param audit_state query int false "任务审核状态 1待审核 2复审 3通过 4拒绝"
// @Success 200 {object} rsp.ResponseData
// @Router /task.audit.list_get [get]
func QueryAuditTask(ctx *fiber.Ctx) error {
路由注释少不
入参出参结构体注释少不了
// QueryAuditTaskIn 领取任务入参
type QueryAuditTaskIn struct {
TeamCode string `query:"team_code" validate:"required"` // 团队编码
TaskType enums.RiskType `query:"task_type" validate:"required"` // 任务类型
TagId int `query:"tag_id" validate:"required"` // 标签id
AuditState constants.TaskResultType `query:"audit_state"` // 审核状态
}
// TaskListItem 任务列表项
type TaskListItem struct {
Id uint32 `json:"id"` // 主键id
TeamCode string `json:"team_code"` // 团队编码
ObjectType enums.ObjectType `json:"object_type"` // 对象类型
ObjectId string `json:"object_id"` // 对象ID
TaskType enums.RiskType `json:"task_type"` // 任务类型
Content datatypes.JSON `json:"content"` // 任务内容
TagId uint32 `json:"tag_id"` // 标签ID
TaskResult constants.TaskResultType `json:"task_result"` // 任务审核结果
ReviewerId uint32 `json:"reviewer_id"` // 领取任务人ID
AuditReason string `json:"audit_reason"` // 审核理由
SourceList []interface{} `json:"source_list"` // 溯源列表
CreateTs int64 `json:"create_ts"` // 任务创建的时间戳
}
一些复杂的嵌套结构最好写上样例
// 获取全部的团队列表
teamSlice := rmc.getAllTeam()
// 统计各审核任务未领取数量
tagTaskCountMap := rmc.getTagTaskCount()
// 获取所有task_group标签与其二级标签
tagMenuSlice := rmc.getTagMenu()
// 将风控审核菜单信息组装到各个团队中并填充统计数量
// eg: [
// {
// "team_code": "lihua",
// "team_name": "梨花"
// "task_count": 1
// "tag_menus": [{"tag_id": 1, "tag_name": "文本", "tag_type": "task_group", "task_count":1, "child_tags": []}, ...]
// },
// ...
//]
riskMenuSlice := make([]*TeamMenuItem, 0)
for _, team := range *teamSlice {
// 填充各审核类型未领取任务数量
newTagMenuSlice := rmc.FillTagTaskCount(tagTaskCountMap, team, tagMenuSlice)
// 填充各团队未领取任务总数
teamTaskCount := uint32(0)
if tagCountMap, ok := tagTaskCountMap[team.TeamCode]; ok {
for _, tagTaskCount := range tagCountMap {
teamTaskCount += tagTaskCount
}
}
teamMenuItem := TeamMenuItem{
TeamCode: team.TeamCode,
TeamName: team.TeamName,
TaskCount: teamTaskCount,
TagMenus: newTagMenuSlice,
}
riskMenuSlice = append(riskMenuSlice, &teamMenuItem)
}
riskMenuMap := map[string]interface{}{
"work_menu": riskMenuSlice,
}
2、美化SQL语句,避免 Select
一些长的SQL语句不要写到一行里面去,可以使用 `` 原生字符串 达到在字符串中换行的效果从而美化SQL语句,然后就是尽量需要什么业务数据就查什么,避免Select * 后再逻辑处理去筛选
queryField := `
task.id AS task_id,
tag_name,
staff.real_name AS staff_real_name,
staff_tar.audit_reason AS staff_audit_reason,
staff_tar.review_result AS staff_review_result,
staff_tar.review_ts AS staff_review_ts,
chief.real_name AS chief_real_name,
chief_tar.audit_reason AS chief_audit_reason,
chief_tar.review_result AS chief_review_result,
chief_tar.review_ts AS chief_review_ts,
task.content AS task_content,
task.json_extend AS task_json_ext,
tar.json_extend AS audit_record_json_ext`
querySQL := `
SELECT
%s
FROM
task_audit_log AS tar
JOIN task ON tar.task_id = task.id
JOIN tag ON task.tag_id = tag.id
LEFT JOIN task_audit_log AS staff_tar ON task.id = staff_tar.task_id AND staff_tar.reviewer_role = "staff"
LEFT JOIN reviewer AS staff ON staff.account_id = staff_tar.reviewer_id
LEFT JOIN task_audit_log AS chief_tar ON task.id = chief_tar.task_id AND chief_tar.reviewer_role = "chief"
LEFT JOIN reviewer AS chief ON chief.account_id = chief_tar.reviewer_id
WHERE
team_code = ?`
queryParams := []interface{}{taskAuditLogIn.TeamCode}
3、避免阶梯缩进与代码紧凑
阶梯缩进、代码紧凑会导致代码不易阅读,理解更难,可以通过一些反向判断来拒绝一些操作,从而减少阶梯缩进,代码紧凑则可以把一些相关的逻辑放到一起,不同的处理步骤适当换行。
// Bad
// 校验参数
VerifyParams(requestIn)
// 获取信息
orderSlice := GetDBInfo(params)
// 逻辑处理
// ...
// 组织返参
for _, order := range(orderSlice){
...
}
// Good
// 校验参数
VerifyParams(requestIn)
// 获取信息
orderSlice := GetDBInfo(params)
// 逻辑处理
// ...
// 组织返参
for _, order := range(orderSlice){
...
}
同一步骤的逻辑太长可以封装成函数、方法。
// Bad
for _, v := range data {
if v.F1 == 1 {
v = process(v)
if err := v.Call(); err == nil {
v.Send()
} else {
return err
}
} else {
log.Printf("Invalid v: %v", v)
}
}
// Good
for _, v := range data {
if v.F1 != 1 {
log.Printf("Invalid v: %v", v)
continue
}
v = process(v)
if err := v.Call(); err != nil {
return err
}
v.Send()
}
不必要的else
// Bad
var a int
if b {
a = 100
} else {
a = 10
}
// Good
a := 10
if b {
a = 100
}
4、避免循环IO、上下文无关联的耗时动作采用Go协程
避免循环IO,可以用批量就改用批量。
func (itm InspectionTaskManager) BatchCreateInspectionTask(taskIdList []uint32) error {
inspectionTaskList := make([]models.InspectionTaskModel, 0)
// 组装好批量创建的抽查任务
for _, id := range taskIdList {
inspectionTaskList = append(inspectionTaskList, models.InspectionTaskModel{
TaskId: id,
})
}
// 批量创建
_, err := itm.BulkCreate(inspectionTaskList)
return err
}
有些数据库表结构可以使用自关联的方式简化查询从而避免循环IO、减少查询次数。
// GetTagMenu 获取所有task_group标签与其二级标签
func (tm *TagManager) GetTagMenu() []*TagMenuResult {
querySql := `
SELECT
t1.id, t1.tag_name, t1.tag_type,
t2.id as two_tag_id, t2.tag_name as two_tag_name,
t2.tag_type as two_tag_type,
t2.pid
FROM
tag AS t1
INNER JOIN tag AS t2 ON t2.pid = t1.id
WHERE
t1.tag_type = "task_group"`
tagMenuSlice := make([]*TagMenuResult, 0)
tm.Conn.Raw(querySql).Scan(&tagMenuSlice)
return tagMenuSlice
}
然后就是上下文无关联的可以并行执行,提高性能。
// GetPageWithTotal 获取分页并返回总数
func (bm BaseManager) GetPageWithTotal(condition *Condition) (*PageResult, error) {
errChan := make(chan error)
resultChan := make(chan PageResult)
defer close(errChan)
defer close(resultChan)
var pageResult PageResult
pageResult.Total = -1 // 设置默认值为-1, 用于判断没有获取到数据的时候
go func() {
// 获取总数
total, err := bm.GetCount(condition)
if err != nil {
errChan <- err
return
}
pageResult.Total = total
resultChan <- pageResult
}()
go func() {
// 获取分页数据
result, err := bm.GetPage(condition)
if err != nil {
errChan <- err
return
}
pageResult.ResultList = result
resultChan <- pageResult
}()
for {
select {
case err := <-errChan:
return nil, err
case result := <-resultChan:
if result.Total != -1 && result.ResultList != nil {
return &result, nil
}
case <-time.After(time.Second * 5):
return nil, exceptions.NewInterError(fmt.Sprintf("超时,分页查询失败"))
}
}
}
以上是借鉴网上一些处理方法和自己的一些想法与实践经验,可以互相探讨与学习,更多关于Go 代码规范错误处理的资料请关注我们其它相关文章!
相关推荐
-

golang常用库之pkg/errors包第三方错误处理包案例详解
目录 golang常用库之-pkg/errors包 背景 关于官方errors包 官方errors包使用demo 什么是pkg/errors包 pkg/errors包使用demo 优秀开源项目使用案例 参考 golang常用库之-pkg/errors包 背景 golang自带了错误信息包error 只提供了简单的用法, 如errors.New(),和errors.Error()用来传递和获取错误信息. 明显官方的包已经不能满足了, 只能采取其他方法补救, 如:采用三方errors包. 关于官方e
-
详解Go多协程并发环境下的错误处理
引言 在Go语言中,我们通常会用到panic和recover来抛出错误和捕获错误,这一对操作在单协程环境下我们正常用就好了,并不会踩到什么坑.但是在多协程并发环境下,我们常常会碰到以下两个问题.假设我们现在有2个协程,我们叫它们协程A和B好了: 如果协程A发生了panic,协程B是否会因为协程A的panic而挂掉? 如果协程A发生了panic,协程B是否能用recover捕获到协程A的panic? 答案分别是:会.不能. 那么下面我们来一一验证,并给出在具体的业务场景下的最佳实践. 问题一 如果
-
关于Google发布的JavaScript代码规范你要知道哪些
Google为了那些还不熟悉代码规范的人发布了一个JS代码规范.其中列出了编写简洁易懂的代码所应该做的最佳实践. 代码规范并不是一种编写正确JavaScript代码的规则,而是为了保持源代码编写模式一致的一种选择.对于JavaScript语言尤其如此,因为它灵活并且约束较少,允许开发者使用许多不同的编码样式. Google和Airbnb各自占据着当前最流行的编码规范的半壁江山.如果你会在编写JS代码上投入很长时间的话,我强烈推荐你通读一遍这两家公司的编码规范. 接下来要写的是我个人认为在Goog
-
Go程序员踩过的defer坑错误处理
目录 前言 一.简单的例子 二.一定不要在 for 循环中使用 defer 语句 三.定义函数时就不要使用命名返回值 四.defer 表达式的函数如果在 panic 后面,则这个函数无法被执行. 五.执行顺序 五.捕获异常执行顺序 六.函数执行顺序 七.外部函数捕获异常执行顺序 八.recover 的返回值问题 前言 先声明:我被坑过. 之前写 Go 专栏时,写过一篇文章:Go 专栏|错误处理:defer,panic 和 recover.有小伙伴留言说:道理都懂,但还是不知道怎么用,而且还总出现
-
Go语言开发编程规范命令风格代码格式
前言 今天这篇文章是站在巨人的肩膀上,汇总了目前主流的开发规范,同时结合Go语言的特点,以及自己的项目经验总结出来的:爆肝分享两千字Go编程规范. 后续还会更新更多优雅的规范. 命名风格 1. [强制]代码中的命名均不能以下划线或美元符号开始,也不能以下划线或美元符号结束. 反 例 : _name / __name / $name / name_ / name$ / name__ 2. [强制]代码中的命名严禁使用拼音与英文混合的方式,更不允许直接使用中文的方式. 说明:正确的英文拼写和语法可以
-
golang gorm错误处理事务以及日志用法示例
目录 1. 高级用法 1.1. 错误处理 1.2. 事物 1.2.1. 一个具体的例子 1.3. SQL构建 1.3.1. 执行原生SQL 1.3.2. sql.Row & sql.Rows 1.3.3. 迭代中使用sql.Rows的Scan 1.4. 通用数据库接口sql.DB 1.4.1. 连接池 1.5. 复合主键 1.6. 日志 1.6.1. 自定义日志 1. 高级用法 1.1. 错误处理 执行任何操作后,如果发生任何错误,GORM将其设置为*DB的Error字段 if err := d
-
go goroutine 怎样进行错误处理
目录 前言 通过错误日志记录 利用 channel 传输 使用 sync/errgroup 总结 前言 在 Go 语言程序开发中,goroutine 的使用是比较频繁的,因此在日常编码的时候 goroutine 里的错误处理,怎么做会比较好呢? 一般我们的业务代码如下: func main() { var wg sync.WaitGroup wg.Add(2) go func() { //... 业务逻辑 wg.Done() }() go func() { //... 业务逻辑 wg.Done(
-
Go 代码规范错误处理示例经验总结
目录 引言 一.相关联的声明放到一起 1.导包规范 2.常量.变量.类型声明 二.Go错误处理 1.失败的原因只有一个时,不使用 error 2.没有失败时,不使用 error 3.错误值统一定义 三.代码规范与实践 1.良好的命名与注释 2.美化SQL语句,避免 Select 3.避免阶梯缩进与代码紧凑 4.避免循环IO.上下文无关联的耗时动作采用Go协程 引言 编写代码应该要有极客追求,不要一味的只为了完成功能不加思索而噼里啪啦一顿操作,我认为应该要像一位设计者一样去设计代码完成功能,因为好
-
代码规范需要防微杜渐code review6个小错误纠正
目录 code review 分析一下我的错误代码行为 1.写没必要的函数 2.Promise传递不明值 3.使用没必要try catch 4.Promise.all并发限制 5.Nodejs中使用过多sync函数 6.判空要放前面 code review 所谓code review,意思很明确,就是代码回顾,这个环节能帮你发现一些你代码中的不好的习惯,或者一些错误的行为.这个工作一般是团队的老大来做的,但是 我们的团队人均大佬 所以我们都是一起code review的,人多力量大,参加的人越多
-
vue2项目增加eslint配置代码规范示例
目录 正文 1.安装以下eslint插件 1.1 .eslintrc.js文件配置 1.2 .eslintignore文件的配置 2. 安装prettier 3. package.json相关代码 4. vscode的配置 5. 启动项目 正文 eslint用于代码检查,prettier用于代码格式化,具体操作如下 1.安装以下eslint插件 安装以下eslint插件,并增加.eslintrc.js配置文件,.eslintignore配置忽略检查的文件 (1)eslint 用于检查和标示出EC
-
java线程池不同场景下使用示例经验总结
目录 引导语 1.coreSize == maxSize 2.maxSize 无界 + SynchronousQueue 3.maxSize 有界 + Queue 无界 4.maxSize 有界 + Queue 有界 5.keepAliveTime 设置无穷大 6.线程池的公用和独立 7.如何算线程大小和队列大小 8.总结 引导语 ThreadPoolExecutor 初始化时,主要有如下几个参数: public ThreadPoolExecutor(int corePoolSize, int
-
总结PHP代码规范、流程规范、git规范
代码规范.git规范.teambition规范.yii规范 1. 命名规范 (1).变量命名规范 1.变量使用驼峰命名法 禁止使用拼音或者拼音加数字 2.变量也应具有描述性,杜绝一切拼音.或拼音英文混杂的命名方式 3.变量包数字.字母和下划线字符,不允许使用其他字符,变量命名最好使用项目 中有据可查的英文缩写方式, 尽可以要使用一目了然容易理解的形式: 4.变量以字母开头,如果变量包多个单词,首字母小写,当包多个单词时,后面 的每个单词的首字母大写.例如 :$itSports 5.变量使用有效命
-
使用pycharm和pylint检查python代码规范操作
pylint是一个不错的代码静态检查工具.将其配置在pycharm中,随时对代码进行分析,确保所有代码都符合pep8规范,以便于养成良好的习惯,将来受用无穷. 第一步,配置pylint - program: python安装目录下scripts/pylint.exe - arguments: --output-format=parseable --disable=R -rn --msg-template="{abspath}:{line}: [{msg_id}({symbol}), {obj}]
-
解决阿里代码规范检测中方法缺少javadoc注释的问题
一.问题描述 安装了阿里代码检测的插件后,敲一个简单的方法,发现提示有问题,如下 /** * 查找User的集合 */ List<User> findAll(); 提示信息为: 方法[findAll]缺少javadoc注释 进一步查看完整文档里面关于方法注释的规范为 所有的抽象方法(包括接口中的方法)必须要用javadoc注释.除了返回值.参数.异常说明外,还必须指出该方法做什么事情,实现什么功能. 说明:如有实现和调用注意事项,请一并说明. /** * fetch data by rule
-
vue-cli3项目配置eslint代码规范的完整步骤
前言 最近接手了一个项目,由于之前为了快速开发,没有做代码检查.为了使得代码更加规范以及更易读,所以就要eslint上场了. 安装依赖 安装依赖有两种方法: 在cmd中打上把相应的依赖加到devDependencies下,再npm install对应依赖. 在package.json文件加上相应依赖: "eslint-plugin-html": "^6.0.3", "@vue/cli-plugin-eslint": "^3.3.0&qu
-
idea中使用SonarLint进行代码规范检测及使用方法
安装 idea中选择file-setting-plugins,输入SonarLint,安装后重启idea 使用 重启完成后,在需要检测的单个文件或者单个项目上右键 --> Analyze --> Analyze with SonarLint 结果查看 有了代码质量检测工具以后,在一定程度上可以保证代码的质量 对于每一个问题,SonarLint都给出了示例,还有相应的解决方案,教我们怎么修改,极大的方便了我们的开发 比如,对于日期类型尽量用LocalDate.LocalTime.LocalDat