MySQL中replace into与replace区别详解
目录
- 0.故事的背景
- 1.replace into 的使用方法
- 2.有唯一索引时—replace into & 与replace 效果
- 3.没有唯一索引时—replace into 与 replace
- 1).replace函数的具体情况
- 2).replace into 函数的具体情况
- 4.replace的用法
本篇为抛砖引玉篇,之前没关注过replace into 与replace 的区别。经过多个场景测试,居然没找到在插入数据的时候两者有什么本质的区别?如果了解详情的伙伴们,请告知留言告知一二,不胜感激!!!
0.故事的背景
【表格结构】
CREATE TABLE `xtp_algo_white_list` ( `strategy_type` int DEFAULT NULL, `user_name` varchar(64) COLLATE utf8_bin DEFAULT NULL, `status` int DEFAULT NULL, `destroy_at` datetime DEFAULT NULL, `created_at` datetime DEFAULT CURRENT_TIMESTAMP, `updated_at` datetime DEFAULT CURRENT_TIMESTAMP, UNIQUE KEY `xtp_algo_white_list_UN` (`strategy_type`,`user_name`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin # `strategy_type`,`user_name` 这两个是联合唯一索引,多关注后续需要用到!!!
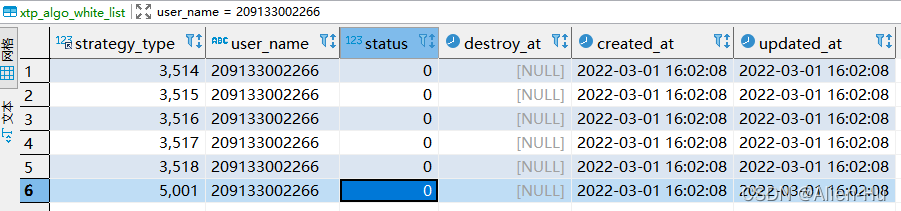
【需求:】
- 根据表格里面, 209133002266账户的数据,重新插入一个用户20220302001, 使得新生成的数据中strategy_type & status & destroy_at 字段与209133002266用户的一致。
- 使用update 一条一条更新也行,但是比较慢。
- 使用replace into 效果会高很多,但是深入研究发现也有一些坑的地方
1.replace into 的使用方法
replace into xtp_algo_white_list (`strategy_type`, `user_name`, `status`, `destroy_at`) select strategy_type ,20220302001, status, destroy_at from xtp_algo_white_list xawl where xawl.user_name = 209133002266; # replace into 后面跟表格+需要插入的所有字段名(自动递增字段不用写) # select 后面选择的字段,如果根据查询结果取值,则写字段名;如果是写死的,则直接写具体值即可 # 可以理解为,第一部分是插入表格的结构,第二部分是你查询的数据结果
2.有唯一索引时—replace into & 与replace 效果
step1: 第一次执行sql情况
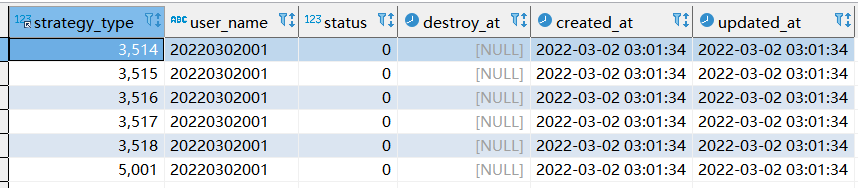
replace into xtp_algo_white_list (`strategy_type`, `user_name`, `status`, `destroy_at`) select strategy_type ,20220302001, status, destroy_at from xtp_algo_white_list xawl where xawl.user_name = 209133002266;

【执行完之后,查询结果如下:】
step2: 第二次执行sql情况

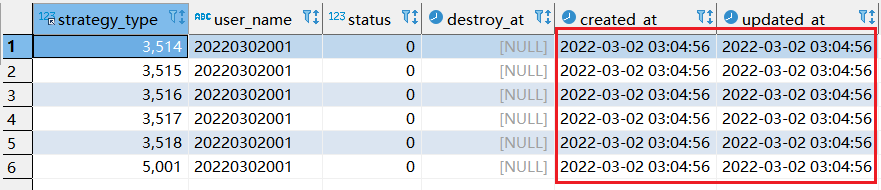
为什么第二次执行的时候,显示update 12行的数据且created at 数据更新了,而第一次会显示update 6行???
1.因为在执行sql的时候,replace into 其实分了两个步骤执行。第一步是将查询到数据转化为新的数据。第二步, 新的数据如果表中已经有相同的内容,则删除掉。如果没有相同的内容,则直接插入新的数据。
2.因如上第一次执行的时候,已经生成一次新数据了,第二次会先删除,再把最新的数据插入进去,最终才显示update 12 行
step3: 第三次执行sql情况
# 此时执行的是replace replace xtp_algo_white_list (`strategy_type`, `user_name`, `status`, `destroy_at`) select strategy_type ,20220302001, status, destroy_at from xtp_algo_white_list xawl where xawl.user_name = 209133002266;

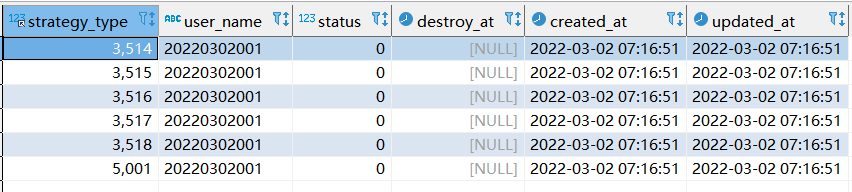
- 最终查看到的情况与第二次执行的sql一样。
- 当新数据已经存在的时候,replace into 与replace是一样的
- 后续删除所有20220302001,执行1次,2次sql,发现replace into 与 replace 效果都是一样的
【总结:】当有唯一索引限制的时候,如果新增的数据会受限于唯一索引,则数据只会插入一次,如果已经存在则会先删除再插入。此时replace into 与replace 效果一样。
3.没有唯一索引时—replace into 与 replace
我们将strategy_type & user_name 联合唯一索引删除,且删除20220302001用户所有数据。最终表格结构如下:
CREATE TABLE `xtp_algo_white_list` ( `strategy_type` int DEFAULT NULL, `user_name` varchar(64) COLLATE utf8_bin DEFAULT NULL, `status` int DEFAULT NULL, `destroy_at` datetime DEFAULT NULL, `created_at` datetime DEFAULT CURRENT_TIMESTAMP, `updated_at` datetime DEFAULT CURRENT_TIMESTAMP ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin
1).replace函数的具体情况
step1:执行如下replace 对应sql:
replace xtp_algo_white_list (`strategy_type`, `user_name`, `status`, `destroy_at`) select strategy_type ,20220302001, status, destroy_at from xtp_algo_white_list xawl where xawl.user_name = 209133002266;


step2:再次执行replace 对应sql:


- 第二次执行replace 对应sql ,因为没有唯一索引限制,结果原始数据居然没变动。又重新生成了新的6条数据。
- 如果后续还执行如上的sql,则数据还会继续增加
2).replace into 函数的具体情况
执行之前,先清理数据,将所有20220302001的数据都删除掉
step1:执行如下replace into 对应sql:
replace into xtp_algo_white_list (`strategy_type`, `user_name`, `status`, `destroy_at`) select strategy_type ,20220302001, status, destroy_at from xtp_algo_white_list xawl where xawl.user_name = 209133002266;

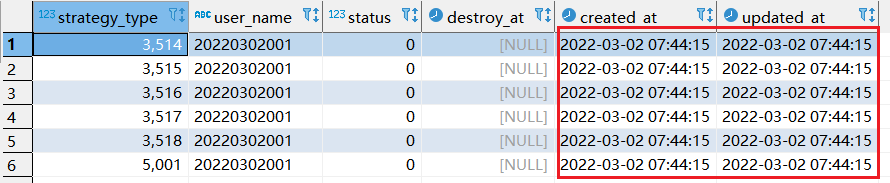
step2:再次执行replace into 对应sql:

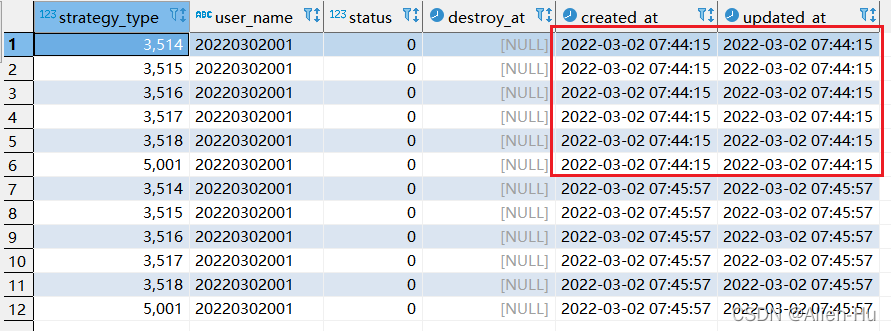
最终发现,没有唯一索引的时候,replace into 与replace 居然一摸一样的效果,都是继续增加数据。
通过以上分析,没看出replace into 与replace 具体有啥区别????有谁知道呢?
4.replace的用法
- 单独replace的作用是替换字段中某数值的显示效果。可以数值中的部分替换、也可以全部替换。
- 如下表格,将user_name的字段,20220302改为"A_20220303"显示,并且新字段叫做new_name显示

select *, replace(user_name,20220302,'A_20220303') as "new_name" from xtp_algo_white_list where user_name = 20220302001;

到此这篇关于MySQL中replace into与replace区别详解的文章就介绍到这了,更多相关MySQL replace into与replace内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

细说mysql replace into用法
replace语句在一般的情况下和insert差不多,但是如果表中存在primary 或者unique索引的时候,如果插入的数据和原来的primary key或者unique相同的时候,会删除原来的数据,然后增加一条新的数据,所以有的时候执行一条replace语句相当于执行了一条delete和insert语句.直接上实例吧: 新建一个test表,三个字段,id,title,uid, id是自增的主键,uid是唯一索引: CREATE TABLE `test` ( `Id` int(11) NO
-
Mysql中replace与replace into的用法讲解
Mysql replace与replace into都是经常会用到的功能:replace其实是做了一次update操作,而不是先delete再insert:而replace into其实与insert into很相像,但对于replace into,假如表中的一个旧记录与一个用于PRIMARY KEY或一个UNIQUE索引的新记录具有相同的值,则在新记录被插入之前,旧记录被删除. replace是mysql 里面处理字符串比较常用的函数,可以替换字符串中的内容.类似的处理字符串的还有trim截取
-
mysql 中 replace into 与 insert into on duplicate key update 的用法和不同点实例分析
本文实例讲述了mysql 中 replace into 与 insert into on duplicate key update 的用法和不同点.分享给大家供大家参考,具体如下: replace into和insert into on duplicate key update都是为了解决我们平时的一个问题 就是如果数据库中存在了该条记录,就更新记录中的数据,没有,则添加记录. 我们创建一个测试表test CREATE TABLE `test` ( `id` int(11) unsigned N
-
MySQL into_Mysql中replace与replace into用法案例详解
Mysql replace与replace into都是经常会用到的功能:replace其实是做了一次update操作,而不是先delete再insert:而replace into其实与insert into很相像,但对于replace into,假如表中的一个旧记录与一个用于PRIMARY KEY或一个UNIQUE索引的新记录具有相同的值,则在新记录被插入之前,旧记录被删除. replace是mysql 里面处理字符串比较常用的函数,可以替换字符串中的内容.类似的处理字符串的还有trim截取
-
MySQL中replace into语句的用法详解
在向表中插入数据的时候,经常遇到这样的情况: 1.首先判断数据是否存在: 2.如果不存在,则插入: 3.如果存在,则更新. 在 SQL Server 中可以这样写: 复制代码 代码如下: if not exists (select 1 from table where id = 1) insert into table(id, update_time) values(1, getdate()) else update table set update_time = getdate() whe
-
mysql 的replace into实例详解
mysql 的replace into实例详解 replace into 跟 insert 功能类似,不同点在于:replace into 首先尝试插入数据到表中. 1.如果发现表中已经有此行数据(根据主键或者唯一索引判断)则先删除此行数据,然后插入新的数据. 2. 否则,直接插入新数据. 要注意的是:插入数据的表必须有主键或者是唯一索引!否则的话,replace into 会直接插入数据,这将导致表中出现重复的数据. MySQL中replace into有三种写法: 代码如下: replac
-
MySQL Replace INTO的使用
REPLACE的运行与INSERT很相像.只有一点除外,如果表中的一个旧记录与一个用于PRIMARY KEY或一个UNIQUE索引的新记录具有相同的值,则在新记录被插入之前,旧记录被删除.请参见13.2.4节,"INSERT语法". 注意,除非表有一个PRIMARY KEY或UNIQUE索引,否则,使用一个REPLACE语句没有意义.该语句会与INSERT相同,因为没有索引被用于确定是否新行复制了其它的行. 所有列的值均取自在REPLACE语句中被指定的值.所有缺失的列被设置为各自的默
-
MySQL中REPLACE INTO和INSERT INTO的区别分析
注意,除非表有一个PRIMARY KEY或UNIQUE索引,否则,使用一个REPLACE语句没有意义.该语句会与INSERT相同,因为没有索引被用于确定是否新行复制了其它的行. [separator] 所有列的值均取自在REPLACE语句中被指定的值.所有缺失的列被设置为各自的默认值,这和INSERT一样.您不能从当前行中引用值,也不能在新行中使用值.如果您使用一个例如"SET col_name = col_name + 1"的赋值,则对位于右侧的列名称的引用会被作为DEFAULT(c
-
浅析MySQL replace into 的用法
在 SQL Server 中可以这样处理: 复制代码 代码如下: if not exists (select 1 from t where id = 1) insert into t(id, update_time) values(1, getdate())else update t set update_time = getdate() where id = 1 那么 MySQL 中如何实现这样的逻辑呢?别着急!MySQL 中有更简单的方法: replace into 复制代码 代码如
-
Vue中$router与 $route的区别详解
目录 前言 路由跳转分为编程式和声明式 前言 点击视频讲解更加详细 this.$route:当前激活的路由的信息对象.每个对象都是局部的,可以获取当前路由的 path, name, params, query 等属性. this.$router:全局的 router 实例.通过 vue 根实例中注入 router 实例,然后再注入到每个子组件,从而让整个应用都有路由功能.其中包含了很多属性和对象(比如 history 对象),任何页面也都可以调用其 push(), replace(), go()
-
mysql中decimal数据类型小数位填充问题详解
前言 在开发过程中,我们往往会用到decimal数据类型.因为decimal是MySQL中存在的精准数据类型. MySQL中的数据类型有:float,double等非精准数据类型和decimal这种精准. 区别:float,double等非精准类型,在DB中保存的是近似值. Decimal则以字符串的形式保存精确的原始数值. decimal介绍: decimal(a,b) 其中:a指定指定小数点左边和右边可以存储的十进制数字的最大个数,最大精度38.b指定小数点右边可以存储的十进制数字的最大个数
-
基于python中staticmethod和classmethod的区别(详解)
例子 class A(object): def foo(self,x): print "executing foo(%s,%s)"%(self,x) @classmethod def class_foo(cls,x): print "executing class_foo(%s,%s)"%(cls,x) @staticmethod def static_foo(x): print "executing static_foo(%s)"%x a=A(
-
node.js中grunt和gulp的区别详解
node.js中grunt和gulp的区别详解 自nodeJS登上前端舞台,自动化构建变得越来越流行.目前最流行的当属grunt和gulp,这两个光看名字挺像,功能也差不多,不过gulp能在grunt这位大哥如日中天的境况下开辟出自己的一片天地,有着她独到的优点. 易用 Gulp相比Grunt更简洁,而且遵循代码优于配置策略,维护Gulp更像是写代码. 高效 Gulp相比Grunt更有设计感,核心设计基于Unix流的概念,通过管道连接,不需要写中间文件. 高质量 Gulp的每个插件只完成一个功能
-
基于js中this和event 的区别(详解)
今天在看javascript入门经典-事件一章中看到了 this 和 event 两种传参形式.因为作为一个初级的前端开发人员平时只用过 this传参,so很想弄清楚,this和event的区别是什么,什么情况下用什么比较合适. onclick = changeImg(this) vs onclick = changeImg(event) <img src='usa.gif' onclick="changeImg(event)" /> <scrip
-
iOS中setValue和setObject的区别详解
网上关于setValue和setObject的区别的文章很多,说的并不准确,首先我们得知道: setObject:ForKey: 是NSMutableDictionary特有的:setValue:ForKey:是KVC的主要方法 话不多说,上代码: - (void)viewDidLoad { [super viewDidLoad]; //setObject和setvalue的区别 NSMutableDictionary *dic = [NSMutableDictionary dictionary
-
python中import reload __import__的区别详解
import 作用:导入/引入一个python标准模块,其中包括.py文件.带有__init__.py文件的目录(自定义模块). import module_name[,module1,...] from module import *|child[,child1,...] 注意:多次重复使用import语句时,不会重新加载被指定的模块,只是把对该模块的内存地址给引用到本地变量环境. 实例: pythontab.py #!/usr/bin/env python #encoding: utf-8
-
JavaScript中object和Object的区别(详解)
JavaScript中object和Object有什么区别,为什么用typeof检测对象,返回object,而用instanceof 必须要接Object呢 这个问题和我之前遇到的问题非常相似,我认为这里有两个问题需要解决,一个是运算符new的作用机制,一个是function关键字和Funtion内置对象之间的区别.看了一些前辈的博客和标准,这里帮提问者总结一下. 1.new new运算符的作用是创建一个对象实例.这个对象可以是用户自定义的,也可以是带构造函数的一些系统自带的对象.如果 new
-
Android中asset和raw的区别详解
*res/raw和assets的相同点: 1.两者目录下的文件在打包后会原封不动的保存在apk包中,不会被编译成二进制. *res/raw和assets的不同点: 1.res/raw中的文件会被映射到R.java文件中,访问的时候直接使用资源ID即R.id.filename:assets文件夹下的文件不会被映射到 R.java中,访问的时候需要AssetManager类. 2.res/raw不可以有目录结构,而assets则可以有目录结构,也就是assets目录下可以再建立文件夹 *读取文件资源
-
基于Java中throw和throws的区别(详解)
系统自动抛出的异常 所有系统定义的编译和运行异常都可以由系统自动抛出,称为标准异常,并且 Java 强烈地要求应用程序进行完整的异常处理,给用户友好的提示,或者修正后使程序继续执行. 语句抛出的异常 用户程序自定义的异常和应用程序特定的异常,必须借助于 throws 和 throw 语句来定义抛出异常. throw是语句抛出一个异常. 语法:throw (异常对象); throw e; throws是方法可能抛出异常的声明.(用在声明方法时,表示该方法可能要抛出异常) 语法:[(修饰符)](返回