sqlServer实现分页查询的三种方式
目录
- 一、offset /fetch next关键字
- 二、利用max(主键)
- 三、利用row_number关键字
- 总结
sqlServer的分页查询和mysql语句不一样,有三种实现方式。分别是:offset /fetch next、利用max(主键)、利用row_number关键字
一、offset /fetch next关键字
2012版本及以上才有,SQL server公司升级后推出的新方法。
公式:
-- 分页查询公式-offset /fetch next select * from 表名 order by 主键 或 其他索引列 -- @pageIndex:页码、@pageSize:每页记录数 offset ((@pageIndex-1)*@pageSize) rows fetch next @pageSize rows only;
示例:
-- 分页查询第2页,每页有10条记录 select * from tb_user order by uid offset 10 rows fetch next 10 rows only ;
说明:
offset 10 rows ,将前10条记录舍去,fetch next 10 rows only ,向后再读取10条数据。
二、利用max(主键)
公式:
-- 分页查询公式-利用max(主键) select top @pageSize * from 表名 where 主键>= (select max(主键) from ( select top ((@pageIndex-1)*@pageSize+1) 主键 from 表名 order by 主键 asc) temp_max_ids) order by 主键;
示例:
-- 分页查询第2页,每页有10条记录 select top 10 * from tb_user -- 3、再重新在这个表查询前10条,条件: id>=max(id) where uid>= -- 2、利用max(id)得到前11条记录中最大的id (select max(uid) from ( -- 1、先top前11条行记录 select top 11 uid from tb_user order by uid asc) temp_max_ids) order by uid;
说明:
先top前11条行记录,然后利用max(id)得到最大的id,之后再重新在这个表查询前10条,不过要加上条件,where id>=max(id)。
中心思想:其实就是先得到该页的初始id,PS:别忘了加上排序哦
三、利用row_number关键字
这种方式也是比较常用的,直接利用row_number() over(order by id)函数计算出行数,选定相应行数返回即可,不过该关键字只有在SQL server 2005版本以上才有。
公式:
-- 分页查询公式-row_number() select top @pageSize * from ( -- rownumber是别名,可按自己习惯取 select row_number() over(order by 主键 asc) as rownumber,* from 表名) temp_row where rownumber>((@pageIndex-1)*@pageSize);
示例:
-- 分页查询第2页,每页有10条记录 select top 10 * from ( -- 子查询,多加一个rownumber列返回 select row_number() over(order by uid asc) as rownumber,* from tb_user) temp_row --限制起始行标 where rownumber>10;
说明:
利用row_number函数给每行记录标了一个序号,相当于在原表中多加了1列返回。
上述示例,是以序号11为起始行,查询前10条记录,即为第2页数据。
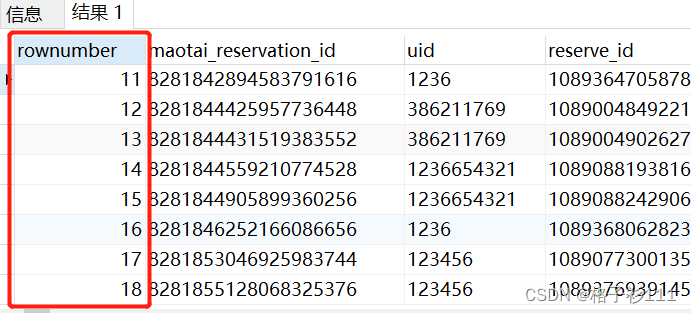
优化:
可以看到,子查询查询了全表数据,如果数据量大,效率是比较低的。
下面是优化后的SQL,
公式:
-- 分页查询公式-row_number()-优化版本 select * from ( -- rownumber是别名,可按自己习惯取 select top (@pageIndex*@pageSize) row_number() over(order by 主键 asc) as rownumber,* from 表名) temp_row where rownumber>((@pageIndex-1)*@pageSize);
示例:
-- 分页查询第2页,每页有10条记录 select * from ( -- 子查询,限制了返回前20条数据 select top 20 row_number() over(order by uid asc) as rownumber,* from tb_user) temp_row --限制起始行标 where rownumber>10;
说明:
这里,子查询仅查询到当前页的最后一行,没有进行全表查询,所以效率上要快一点。在外层限制起始行标,是没变的,但是却在内层控制了结尾行标。
上述示例,是以序号11为起始行,查询20以内的记录,即为第2页数据。
总结
更多介绍,可查看我的另外篇文章:SQL Server中row_number函数用法介绍
到此这篇关于sqlServer实现分页查询的三种方式的文章就介绍到这了,更多相关sqlServer分页查询实现内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
sqlserver分页查询处理方法小结
sqlserver2008不支持关键字limit ,所以它的分页sql查询语句将不能用MySQL的方式进行,幸好sqlserver2008提供了top,rownumber等关键字,这样就能通过这几个关键字实现分页. 下面是本人在网上查阅到的几种查询脚本的写法: 几种sqlserver2008高效分页sql查询语句 top方案: sql code: select top 10 * from table1 where id not in(select top 开始的位置 id from table1
-
高效的SQLSERVER分页查询(推荐)
第一种方案.最简单.普通的方法: 复制代码 代码如下: SELECT TOP 30 * FROM ARTICLE WHERE ID NOT IN(SELECT TOP 45000 ID FROM ARTICLE ORDER BY YEAR DESC, ID DESC) ORDER BY YEAR DESC,ID DESC 平均查询100次所需时间:45s 第二种方案: 复制代码 代码如下: SELECT * FROM ( SELECT TOP 30 * FROM (SELECT TOP 4503
-
真正高效的SQLSERVER分页查询(多种方案)
Sqlserver数据库分页查询一直是Sqlserver的短板,闲来无事,想出几种方法,假设有表ARTICLE,字段ID.YEAR...(其他省略),数据53210条(客户真实数据,量不大),分页查询每页30条,查询第1500页(即第45001-45030条数据),字段ID聚集索引,YEAR无索引,Sqlserver版本:2008R2 第一种方案.最简单.普通的方法: 复制代码 代码如下: SELECT TOP 30 * FROM ARTICLE WHERE ID NOT IN(SELECT T
-
oracle,mysql,SqlServer三种数据库的分页查询的实例
MySql: MySQL数据库实现分页比较简单,提供了 LIMIT函数.一般只需要直接写到sql语句后面就行了.LIMIT子 句可以用来限制由SELECT语句返回过来的数据数量,它有一个或两个参数,如果给出两个参数, 第一个参数指定返回的第一行在所有数据中的位置,从0开始(注意不是1),第二个参数指定最多返回行数.例如:select * from table WHERE - LIMIT 10; #返回前10行select * from table WHERE - LIMIT 0,10; #返回前
-
sqlServer实现分页查询的三种方式
目录 一.offset /fetch next关键字 二.利用max(主键) 三.利用row_number关键字 总结 sqlServer的分页查询和mysql语句不一样,有三种实现方式.分别是:offset /fetch next.利用max(主键).利用row_number关键字 一.offset /fetch next关键字 2012版本及以上才有,SQL server公司升级后推出的新方法. 公式: -- 分页查询公式-offset /fetch next select * from 表
-

SQLServer批量插入数据的三种方式及性能对比
昨天下午快下班的时候,无意中听到公司两位同事在探讨批量向数据库插入数据的性能优化问题,顿时来了兴趣,把自己的想法向两位同事说了一下,于是有了本文. 公司技术背景:数据库访问类(xxx.DataBase.Dll)调用存储过程实现数据库的访问. 技术方案一: 压缩时间下程序员写出的第一个版本,仅仅为了完成任务,没有从程序上做任何优化,实现方式是利用数据库访问类调用存储过程,利用循环逐条插入.很明显,这种方式效率并不高,于是有了前面的两位同事讨论效率低的问题. 技术方案二: 由于是考虑到大数据量的批量
-
vue实现input输入模糊查询的三种方式
目录 1 计算属性实现模糊查询 2 watch 监听实现模糊查询 3 通过按钮点击实现模糊查询 1 计算属性实现模糊查询 vue 中通过计算属性实现模糊查询,创建 html 文件,代码直接放入即可. 这里自己导入 vue,我是导入本地已经下载好的. <script src="./lib/vue-2.6.12.js"></script> 演示: 打开默认显示全部 输入关键字模糊查询,名字和年龄都可以 完整代码如下: <!DOCTYPE html> &l
-
SQLSERVER分页查询关于使用Top方式和row_number()解析函数的不同
临近春节,心早已飞了不在工作上了,下面小编给大家整理些数据库的几种分页查询. Sql Sever 2005之前版本: select top 页大小 * from 表名 where id not in ( select top 页大小*(查询第几页-1) id from 表名 order by id ) order by id 例如: select top 10 * --10 为页大小 from [TCCLine].[dbo].[CLine_CommonImage] where id not in
-
Java项目开发中实现分页的三种方式总结
目录 前言 使用 1.SpringDataJPA分页 2.MyBatis分页 3.Hutools工具类分页 总结 前言 Java项目开发中经常要用到分页功能,现在普遍使用SpringBoot进行快速开发,而数据层主要整合SpringDataJPA和MyBatis两种框架,这两种框架都提供了相应的分页工具,使用方式也很简单,可本人在工作中除此以外还用到第三种更方便灵活的分页方式,在这里一同分享给大家. 使用 主要分为SpringDataJPA分页.MyBatis分页.Hutools工具类分页几个部
-
C#批量插入数据到Sqlserver中的三种方式
本篇,我将来讲解一下在Sqlserver中批量插入数据. 先创建一个用来测试的数据库和表,为了让插入数据更快,表中主键采用的是GUID,表中没有创建任何索引.GUID必然是比自增长要快的,因为你生成一个GUID算法所花的时间肯定比你从数据表中重新查询上一条记录的ID的值然后再进行加1运算要少.而如果存在索引的情况下,每次插入记录都会进行索引重建,这是非常耗性能的.如果表中无可避免的存在索引,我们可以通过先删除索引,然后批量插入,最后再重建索引的方式来提高效率. create database C
-
SqlServer2016模糊匹配的三种方式及效率问题简析
本文实例讲述了SqlServer2016模糊匹配的三种方式及效率问题.分享给大家供大家参考,具体如下: 数据库是Sqlserver 2016版 现在业务需求是:要查询出企业名称为以下几个的,XXX,XXXX等等: 第一种方式:like '%XXX%' OR like '%XXXX%' select cName from tAccountAuditing where cName like '%测试moa000154%' OR cName like '%测试集团上海事业部%' and activeA
-
MySQL中SQL分页查询的几种实现方法及优缺点
[SQL]SQL分页查询总结 开发过程中经常遇到分页的需求,今天在此总结一下吧. 简单说来方法有两种,一种在源上控制,一种在端上控制.源上控制把分页逻辑放在SQL层:端上控制一次性获取所有数据,把分页逻辑放在UI上(如GridView).显然,端上控制开发难度低,适于小规模数据,但数据量增大时性能和IO消耗无法接受:源上控制在性能和开发难度上较为平衡,适应大多数业务场景:除此之外,还可以根据客观情况(性能要求,源与端的资源占用等)在源和端之间加一层,应用特殊算法和技术进行处理.以下主要讨论源上,
-
python 使用elasticsearch 实现翻页的三种方式
使用ES做搜索引擎拉取数据的时候,如果数据量太大,通过传统的from + size的方式并不能获取所有的数据(默认最大记录数10000),因为随着页数的增加,会消耗大量的内存,导致ES集群不稳定.因此延伸出了scroll,search_after等翻页方式. 一.from + size 浅分页 "浅"分页可以理解为简单意义上的分页.它的原理很简单,就是查询前20条数据,然后截断前10条,只返回10-20的数据.这样其实白白浪费了前10条的查询. GET test/_search { &
-
sql跨表查询的三种方案总结
目录 前言 方案一:连接多个库,同步执行查询 优点 缺点 代码执行 方案二:在主数据库增加冗余表,通过定时更新,造成同库联表查询 优点 缺点 相似实现场景 方案三:dbLink本地连接多个库,在本地进行数据分析 优点 缺点 前言 最近又个朋友问我,如何进行sql的跨库关联查询? 首先呢,我们知道mysql是不支持跨库连接的,但是老话说得好,只要思想不滑坡,思想总比困难多! PS: 问题摆在这里了,还能不解决是怎么的? 经过一番思考我给他提出了三个方案,虽然都不尽善尽美,但各领风骚! 连接方案,以