Apache Hive 通用调优featch抓取机制 mr本地模式
目录
- Apache Hive-通用优化-featch抓取机制 mr本地模式
- Fetch抓取机制
- mapreduce本地模式
- 切换Hive的执行引擎
- Apache Hive-通用优化-join优化
- - reduce端join
- -map端join
- reduce 端 join 优化
- map 端 join 优化
- Apache Hive--通用调优--数据倾斜优化
- group by数据倾斜
- join数据倾斜
- Apache Hive--通用调优--MR程序task个数调整
- maptask个数
- reducetask个数
- 通用优化-执行计划
- 通用优化-并行机制,推测执行机制
- Hive的严格模式
Apache Hive-通用优化-featch抓取机制 mr本地模式
Fetch抓取机制
- 功能:在执行sql的时候,能不走MapReduce程序处理就尽量不走MapReduce程序处理.
- 尽量直接去操作数据文件。
设置: hive.fetch.task.conversion= more。
--在下述3种情况下 sql不走mr程序 --全局查找 select * from student; --字段查找 select num,name from student; --limit 查找 select num,name from student limit 2;
mapreduce本地模式
- MapReduce程序除了可以提交到yarn集群分布式执行之外,还可以使用本地模拟环境运行,当然此时就不是分布式执行的程序,但是针对小文件小数据处理特别有效果。
- 用户可以通过设置hive.exec.mode.local.auto的值为true,来让Hive在适当的时候自动启动这个 优化。
功能:如果非要执行==MapReduce程序,能够本地执行的,尽量不提交yarn上执行==。
默认是关闭的。意味着只要走MapReduce就提交yarn执行。
mapreduce.framework.name = local 本地模式 mapreduce.framework.name = yarn 集群模式
Hive提供了一个参数,自动切换MapReduce程序为本地模式,如果不满足条件,就执行yarn模式。
set hive.exec.mode.local.auto = true; --3个条件必须都满足 自动切换本地模式 The total input size of the job is lower than: hive.exec.mode.local.auto.inputbytes.max (128MB by default) --数据量小于128M The total number of map-tasks is less than: hive.exec.mode.local.auto.tasks.max (4 by default) --maptask个数少于4个 The total number of reduce tasks required is 1 or 0. --reducetask个数是0 或者 1
切换Hive的执行引擎
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
如果针对Hive的调优依然无法满足你的需求 还是效率低, 尝试使用spark计算引擎 或者Tez.
Apache Hive-通用优化-join优化
在了解join优化的时候,我们需要了解一个前置知识点:map端join 和reduce端join
- reduce端join
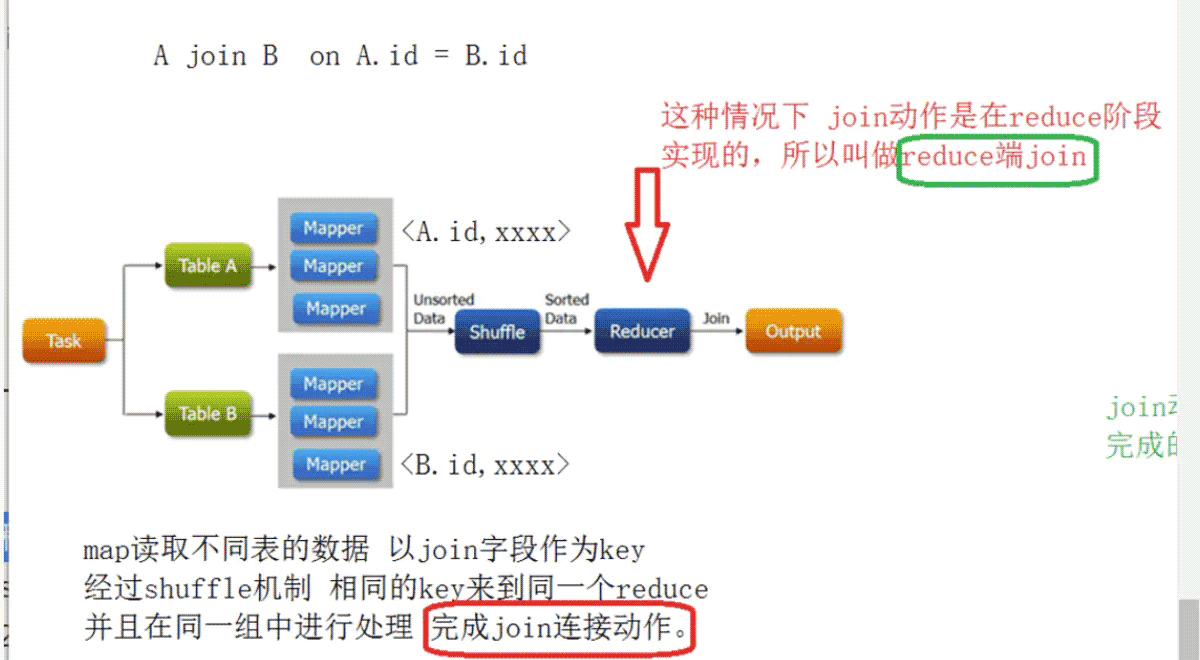
- 这种join的弊端在于map阶段没有承担太多的责任,所有的数据在经过shuffle在reduce阶段实现的,而shuffle又是影响性能的核心点.
-map端join
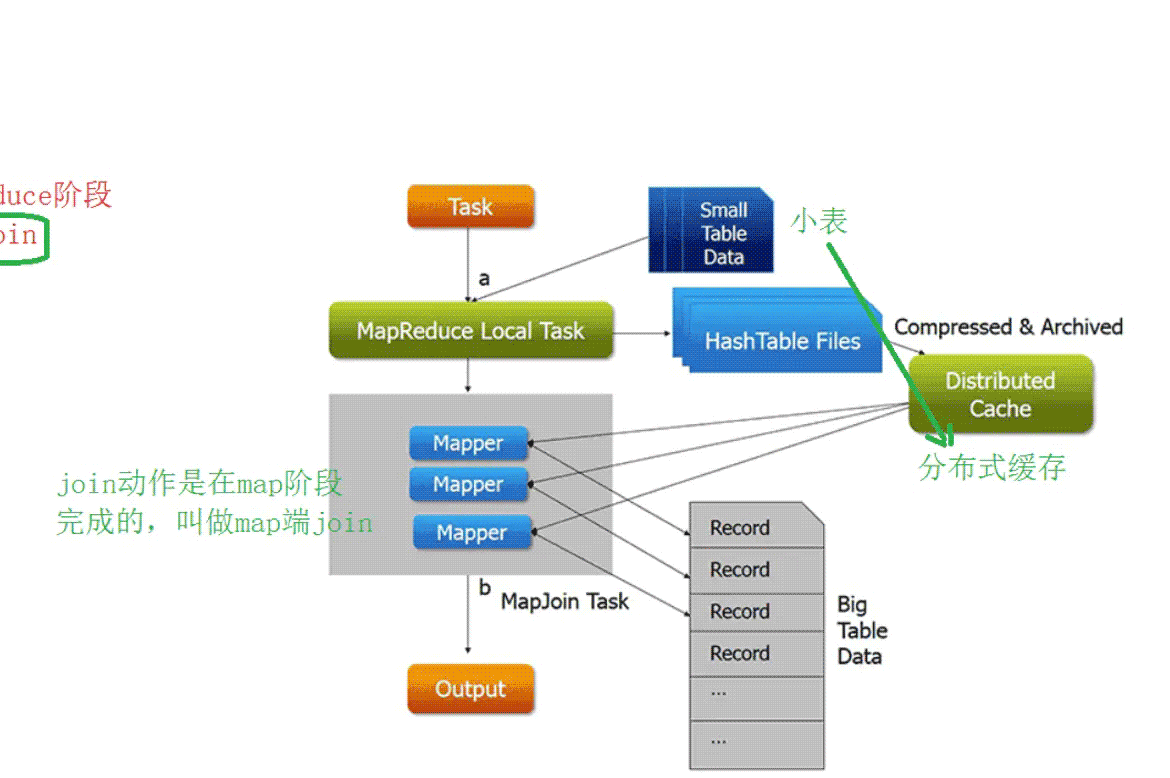
- 首先启动本地任务将join中小表数据进行分布式缓存
- 启动mr程序(只有map阶段)并行处理大数据,并且从自己的缓存中读取小表数据,进行join,结果直接输出到文件中
- 没有shuffle过程 也没有reduce过程
- 弊端:缓存太小导致表数据不能太大
reduce 端 join 优化
适合于大表Join大表
bucket join-- 适合于大表Join大表
方式1:Bucktet Map Join 分桶表
语法: clustered by colName(参与join的字段)
参数: set hive.optimize.bucketmapjoin = true
要求: 分桶字段 = Join字段 ,分桶的个数相等或者成倍数,必须是在map join中
方式2:Sort Merge Bucket Join(SMB)
基于有序的数据Join
语法:clustered by colName sorted by (colName)
参数
set hive.optimize.bucketmapjoin = true;
set hive.auto.convert.sortmerge.join=true;
set hive.optimize.bucketmapjoin.sortedmerge = true;
set hive.auto.convert.sortmerge.join.noconditionaltask=true;
要求: 分桶字段 = Join字段 = 排序字段,分桶的个数相等或者成倍数
map 端 join 优化
- hive.auto.convert.join.noconditionaltask
hive.auto.convert.join=true Hive老版本 #如果参与的一个表大小满足条件 转换为map join hive.mapjoin.smalltable.filesize=25000000 Hive2.0之后版本 #是否启用基于输入文件的大小,将reduce join转化为Map join的优化机制。假设参与join的表(或分区)有N个,如果打开这个参数,并且有N-1个表(或分区)的大小总和小于hive.auto.convert.join.noconditionaltask.size参数指定的值,那么会直接将join转为Map join。 hive.auto.convert.join.noconditionaltask=true hive.auto.convert.join.noconditionaltask.size=512000000
Apache Hive--通用调优--数据倾斜优化
数据倾斜优化
什么是数据倾斜
描述的数据进行分布式处理 分配不平均的现象
数据倾斜的后果
某个task数据量过大 执行时间过长 导致整体job任务迟迟不结束
执行时间长 出bug及风险几率提高
霸占运算资源 迟迟不释放
通常如何发现数据倾斜
在yarn或者其他资源监控软件上 发现某个job作业 卡在某个进度迟迟不动 (注意 倒不是报错)
造成数据倾斜的原因
数据本身就倾斜
自定义分区、分组规则不合理
业务影响 造成数据短期高频波动
数据倾斜的通用解决方案
1、有钱 有预警
增加物理资源 单独处理倾斜的数据
2、没钱 没有预警
倾斜数据打散 分步执行
先将倾斜数据打散成多干份
处理的结果再最终合并
hive中数据倾斜的场景
场景一:group by 、count(distinct)
hive.map.aggr=true; map端预聚合
手动将数据随机分区 select * from table distribute by rand();
如果有数据倾斜问题 开启负载均衡
先启动第一个mr程序 把倾斜的数据随机打散分散到各个reduce中
然后第二个mr程序把上一步结果进行最终汇总
hive.groupby.skewindata=true;
场景二:join
提前过滤,将大数据变成小数据,实现Map Join
使用Bucket Join
使用Skew Join
将Map Join和Reduce Join进行合并,如果某个值出现了数据倾斜,就会将产生数据倾斜的数据单独使用Map Join来实现
最终将Map Join的结果和Reduce Join的结果进行Union合并
Hive中通常指的是在reduce阶段数据倾斜
解决方法
group by数据倾斜
方案一:开启Map端聚合
hive.map.aggr=true; #是否在Hive Group By 查询中使用map端聚合。 #这个设置可以将顶层的部分聚合操作放在Map阶段执行,从而减轻清洗阶段数据传输和Reduce阶段的执行时间,提升总体性能。但是指标不治本。
方案二:实现随机分区
实现随机分区 select * from table distribute by rand();
方案三:数据倾斜时==自动负载均衡==只使用group by
hive.groupby.skewindata=true; #开启该参数以后,当前程序会自动通过两个MapReduce来运行 #第一个MapReduce自动进行随机分布到Reducer中,每个Reducer做部分聚合操作,输出结果 #第二个MapReduce将上一步聚合的结果再按照业务(group by key)进行处理,保证相同的分布到一起,最终聚合得到结果
join数据倾斜
- 方案一:提前过滤,将大数据变成小数据,实现Map Join
- 方案二:使用Bucket Join
- 方案三:使用Skew Join
数据单独使用Map Join来实现
#其他没有产生数据倾斜的数据由Reduce Join来实现,这样就避免了Reduce Join中产生数据倾斜的问题 #最终将Map Join的结果和Reduce Join的结果进行Union合并 #开启运行过程中skewjoin set hive.optimize.skewjoin=true; #如果这个key的出现的次数超过这个范围 set hive.skewjoin.key=100000; #在编译时判断是否会产生数据倾斜 set hive.optimize.skewjoin.compiletime=true; set hive.optimize.union.remove=true; #如果Hive的底层走的是MapReduce,必须开启这个属性,才能实现不合并 set mapreduce.input.fileinputformat.input.dir.recursive=true;
Apache Hive--通用调优--MR程序task个数调整
maptask个数
- 如果是在MapReduce中 maptask是通过==逻辑切片==机制决定的。
- 但是在hive中,影响的因素很多。比如逻辑切片机制,文件是否压缩、压缩之后是否支持切割。
- 因此在==Hive中,调整MapTask的个数,直接去HDFS调整文件的大小和个数,效率较高==。
合并的大小最好=block size
如果大文件多,就调整blocl size
reducetask个数
- 如果在MapReduce中,通过代码可以直接指定 job.setNumReduceTasks(N)
- 在Hive中,reducetask个数受以下几个条件控制的
hive.exec.reducers.bytes.per.reducer=256000000
每个任务最大的 reduce 数,默认为 1009
hive.exec.reducsers.max=1009
mapreduce.job.reduces
该值默认为-1,由 hive 自己根据任务情况进行判断。--如果用户用户不设置 hive将会根据数据量或者sql需求自己评估reducetask个数。
--用户可以自己通过参数设置reducetask的个数
set mapreduce.job.reduces = N
--用户设置的不一定生效,如果用户设置的和sql执行逻辑有冲突,比如order by,在sql编译期间,hive又会将reducetask设置为合理的个数。Number of reduce tasks determined at compile time: 1
通用优化-执行计划
通过执行计划可以看出==hive接下来是如何打算执行这条sql的==。
语法格式:explain + sql语句
通用优化-并行机制,推测执行机制
并行执行机制
- 如果hivesql的底层某些stage阶段可以并行执行,就可以提高执行效率。
- 前提是==stage之间没有依赖== 并行的弊端是瞬时服务器压力变大。
参数
set hive.exec.parallel=true; --是否并行执行作业。适用于可以并行运行的 MapReduce 作业,例如在多次插入期间移动文件以插入目标 set hive.exec.parallel.thread.number=16; --最多可以并行执行多少个作业。默认为8。
Hive的严格模式
- 注意。不要和动态分区的严格模式搞混淆。
- 这里的严格模式指的是开启之后 ==hive会禁止一些用户都影响不到的错误包括效率低下的操作==,不允许运行一些有风险的查询。
设置
set hive.mapred.mode = strict --默认是严格模式 nonstrict
解释
1、如果是分区表,没有where进行分区裁剪 禁止执行
2、order by语句必须+limit限制
推测执行机制 ==建议关闭==。
- MapReduce中task的一个机制。
- 功能:
一个job底层可能有多个task执行,如果某些拖后腿的task执行慢,可能会导致最终job失败。
所谓的==推测执行机制就是通过算法找出拖后腿的task,为其启动备份的task==。
两个task同时处理一份数据,谁先处理完,谁的结果作为最终结果。
- 推测执行机制默认是开启的,但是在企业生产环境中==建议关闭==。
以上就是Apache Hive 通用调优featch抓取机制 mr本地模式的详细内容,更多关于Apache Hive 通用调优的资料请关注我们其它相关文章!
相关推荐
-

利用apache ftpserver搭建ftp服务器的方法步骤
目录 操作环境: 一.usermanager采用文件形式管理xml示例如下 二.usermanager采用mysql数据库管理用户时,ftpd-mysql.xml示例如下 三.usermanager采用Sqlite数据库管理用户时,ftpd-sqlite.xml示例如下 四.解决ftpd.exe在64位windows系统启动失败的问题 五.python操作sqlite的ftp.db管理(增加删除)用户 操作环境: win2012r2 x64 datacenter Apache FtpServer
-
详解apache编译安装httpd-2.4.54及三种风格的init程序特点和区别
目录 源码包编译实例 下载编译工具,httpd以及其两个依赖包的源码包 安装apr 安装apr-util 安装httpd 源码编译报错信息处理 init程序的三种风格 init程序三种风格的特点 源码包编译实例 下面通过编译安装httpd来深入理解源码包安装(httpd-2.4.54) 下载编译工具,httpd以及其两个依赖包的源码包 //源码包建议到官方网站下载 [root@lnh ~]# mkdir xbz [root@lnh ~]# cd xbz/ [root@lnh xbz]# dnf
-
Apache教程Hudi与Hive集成手册
目录 1. Hudi表对应的Hive外部表介绍 2. Hive对Hudi的集成 3. 创建Hudi表对应的hive外部表 4. 查询Hudi表对应的Hive外部表 4.1 操作前提 4.2 COW类型Hudi表的查询 4.2.1 COW表实时视图查询 4.2.2 COW表增量查询 4.3 MOR类型Hudi表的查询 4.3.1 MOR表读优化视图 4.3.2 MOR表实时视图 4.3.3 MOR表增量查询 5. Hive侧源码修改 1. Hudi表对应的Hive外部表介绍 Hudi源表对应一份H
-
hive数据仓库新增字段方法
目录 新增字段 1.方法1 cascade知识 2.方法2 (适用于外部表) 3.方法3(下下策) 修改字段 删除列 新增字段 1.方法1 alter table 表名 add columns (列名 string COMMENT '新添加的列') CASCADE; alter table 表名 add columns (列名 string COMMENT '新添加的列'): hive表中指定位置增加一个字段 分两步,先添加字段到最后(add columns),然后再移动到指定位置(change
-
Apache Maven3.6.0的下载安装和环境配置(图文教程)
目录 apache-maven-3.6.0 下载地址 方法/步骤一 安装 方法/步骤二 环境变量配置 变量 环境 apache-maven-3.6.0 下载地址 不限速下载 或者进入官网按下图下载 方法/步骤一 安装 打开压缩包,将maven压缩包解压至软件安装处,建议D根目录或其他,记住安装位置 类似于 方法/步骤二 环境变量配置 变量 1.新建变量M2_HOME,变量值为maven目录 2.在变量名为Path下新建变量值为maven bin目录 一项 3.通过命令mvn -v验证环境是否配置
-
Hive导入csv文件示例
目录 正文 首先创建表 导入数据及查询 其他注意事项 总结 正文 现有文件为csv格式,需要导入hive中,设csv内容如下 1001,zs,23 1002,lis,24 首先创建表 create table if not exists csv2( uid int, uname string, age int ) row format serde 'org.apache.hadoop.hive.serde2.OpenCSVSerde' stored as textfile ; 导入数据及查询 l
-
Apache Hive 通用调优featch抓取机制 mr本地模式
目录 Apache Hive-通用优化-featch抓取机制 mr本地模式 Fetch抓取机制 mapreduce本地模式 切换Hive的执行引擎 Apache Hive-通用优化-join优化 - reduce端join -map端join reduce 端 join 优化 map 端 join 优化 Apache Hive--通用调优--数据倾斜优化 group by数据倾斜 join数据倾斜 Apache Hive--通用调优--MR程序task个数调整 maptask个数 reducet
-
jquery+thinkphp实现跨域抓取数据的方法
本文实例讲述了jquery+thinkphp实现跨域抓取数据的方法.分享给大家供大家参考,具体如下: 今天做一个远程抓取数据的功能,记得jquery可以用Ajax远程抓取,但不能跨域.再网上找了很多.但我觉得还是来个综合的,所以我现在觉得有点把简单问题复杂化了,但至少目前解决了: 跨域抓取数据到本地数据库再异步更新的效果 我实现的方式:jquery的$.post发送数据到服务器后台,在由后台的PHP代码执行远程抓取,存到数据库ajax返回数据到前台,前台用JS接受数据并显示. //远程抓取获取数
-
PHP实现抓取百度搜索结果页面【相关搜索词】并存储到txt文件示例
本文实例讲述了PHP实现抓取百度搜索结果页面[相关搜索词]并存储到txt文件.分享给大家供大家参考,具体如下: 一.百度搜索关键词[我们] [我们]搜索链接 https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=0&rsv_idx=1&tn=baidu&wd=%E8%84%9A%E6%9C%AC%E4%B9%8B%E5%AE%B6&rsv_pq=ab33cfeb000086a2&rsv_t=7c65vT3KzHCNf
-
百万级别知乎用户数据抓取与分析之PHP开发
这次抓取了110万的用户数据,数据分析结果如下: 开发前的准备 安装Linux系统(Ubuntu14.04),在VMWare虚拟机下安装一个Ubuntu: 安装PHP5.6或以上版本: 安装curl.pcntl扩展. 使用PHP的curl扩展抓取页面数据 PHP的curl扩展是PHP支持的允许你与各种服务器使用各种类型的协议进行连接和通信的库. 本程序是抓取知乎的用户数据,要能访问用户个人页面,需要用户登录后的才能访问.当我们在浏览器的页面中点击一个用户头像链接进入用户个人中心页面的时候,之所以
-
Python3实战之爬虫抓取网易云音乐的热门评论
前言 之前刚刚入门python爬虫,有大概半个月时间没有写python了,都快遗忘了.于是准备写个简单的爬虫练练手,我觉得网易云音乐最优特色的就是其精准的歌曲推荐和独具特色的用户评论,于是写了这个抓取网易云音乐热歌榜里的热评的爬虫.我也是刚刚入门爬虫,有什么意见和问题欢迎提出,大家一起共同进步. 废话就不多说了-下面来一起看看详细的介绍吧. 我们的目标是爬取网易云中的热歌排行榜中所有歌曲的热门评论. 这样既可以减少我们需要爬取的工作量,又可以保存到高质量的评论. 实现分析 首先,我们打开网易云网
-
十分简单易懂的Java应用程序性能调优技巧分享
大多数开发人员理所当然地以为性能优化很复杂,需要大量的经验和知识.好吧,不能说这是完全错误的.优化应用程序以获得最佳性能不是一件容易的事情.但是,这并不意味着如果你不具备这些知识,就不能做任何事情.这里有11个易于遵循的建议和最佳实践可以帮助你创建一个性能良好的应用程序. 大部分建议是针对Java的.但也有若干建议是与语言无关的,可以应用于所有应用程序和编程语言.在讨论专门针对Java的性能调优技巧之前,让我们先来看看通用技巧. 1.在你知道必要之前不要优化 这可能是最重要的性能调整技巧之一.你
-
Scrapy抓取京东商品、豆瓣电影及代码分享
1.scrapy基本了解 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架.可以应用在包括数据挖掘, 信息处理或存储历史数据等一系列的程序中.其最初是为了页面抓取(更确切来说,网络抓取)所设计的,也可以应用在获取API所返回的数据(比如Web Services)或者通用的网络爬虫. Scrapy也能帮你实现高阶的爬虫框架,比如爬取时的网站认证.内容的分析处理.重复抓取.分布式爬取等等很复杂的事. Scrapy主要包括了以下组件: 引擎(Scrapy): 用来处理整个系统的数据流
-
分享Java性能调优的11个实用技巧
大多数开发人员认为性能优化是个比较复杂的问题,需要大量的经验和知识.是的,这并不没有错.诚然,优化应用程序以获得最好的性能并不是一件容易的事情,但这并不意味着你在没有获得这些经验和知识之前就不能做任何事.下面有几个很容易遵循的建议和最佳实践能够帮你创建一个性能良好的应用程序. 这些建议中的大多数都是基于Java的,但是也不一定,也有一些是可以应用于所有的应用程序和编程语言的.在我们分享基于Java的性能调优技巧之前,让我们先讨论一下这些通用的性能调优技巧. 1.在必要之前,先不要优化 这可能是最
-
Logback与Log4j2日志框架性能对比与调优方式
目录 前言 性能测试 logback 同步日志 异步日志(队列扩容) 异步日志(半队列扩容) log4j2 同步日志 异步日志(队列扩容) 异步日志(日志淘汰策略) 异步日志(半队列扩容) 异步日志(等待策略) 性能调优 异步日志 日志可靠性 Logback Log4j2 日志抛弃策略 Log4j2 Logback 日志等待策略 TimeoutWaitStrategy YieldWaitStrategy 队列容量 Logback Log4j2 长度计算公式 消费瓶颈 消费TPS 请求TPS 消费
-
Springboot并发调优之大事务和长连接
目录 1.背景 2.主要参数释义: 2.1 tomcat主要并发参数释义 2.2 数据库连接池参数 2.3 数据库连接数 3.测试程序 4.jmeter测试 4.1.快速组 4.2.慢速组 4.3.对照分析 5.问题与优化 5.1.问题 5.2 .排查 5.3.核心 5.4.调优 6.优化实验 6.1 手动事务 6.2.优化第一组测试 6.3.优化第二组测试 7.总结 1.背景 在当前这个快速开发的环境下,很多时候我们的应用都是测试好好的,正式环境并发一高就一团糟.不了解并发相关参数,看不懂压测