Python Counting Bloom Filter原理与实现详细介绍
目录
- 前言
- 原理
- 一、BF 为什么不支持删除
- 二、什么是 Counting Bloom Filter
- 三、Counter 大小的选择
- 简单的实现
- 总结
前言
标准的 Bloom Filter 是一种比较简单的数据结构,只支持插入和查找两种操作。在所要表达的集合是静态集合的时候,标准 Bloom Filter 可以很好地工作,但是如果要表达的集合经常变动,标准Bloom Filter的弊端就显现出来了,因为它不支持删除操作。这就引出来了本文要谈的 Counting Bloom Filter,后文简写为 CBF。
原理
一、BF 为什么不支持删除
BF 为什么不能删除元素?我们可以举一个例子来说明。
比如要删除集合中的成员 dantezhao,那么就会先用 k 个哈希函数对其计算,因为 dantezhao 已经是集合成员,那么在位数组的对应位置一定是 1,我们如要要删除这个成员 dantezhao,就需要把计算出来的所有位置上的 1 置为 0,即将 5 和 16 两位置为 0 即可。
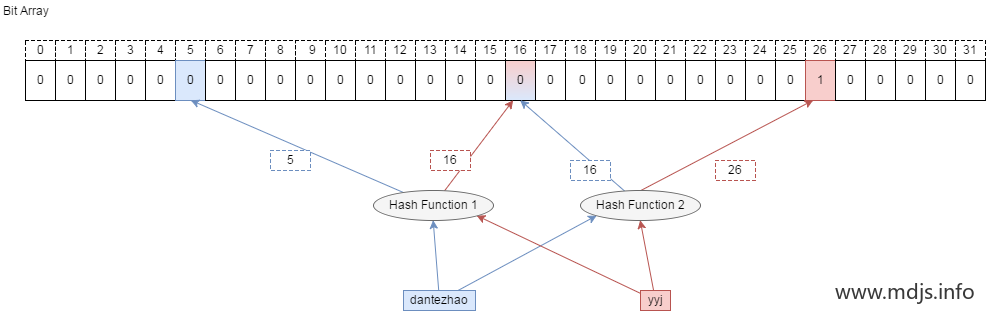
问题来了!现在,先假设 yyj 本身是属于集合的元素,如果需要查询 yyj 是否在集合中,通过哈希函数计算后,我们会去判断第 16 和 第 26 位是否为 1, 这时候就得到了第 16 位为 0 的结果,即 yyj 不属于集合。 显然这里是误判的。
二、什么是 Counting Bloom Filter
Counting Bloom Filter 的出现,解决了上述问题,它将标准 Bloom Filter 位数组的每一位扩展为一个小的计数器(Counter),在插入元素时给对应的 k (k 为哈希函数个数)个 Counter 的值分别加 1,删除元素时给对应的 k 个 Counter 的值分别减 1。Counting Bloom Filter 通过多占用几倍的存储空间的代价, 给 Bloom Filter 增加了删除操作。基本原理是不是很简单?看下图就能明白它和 Bloom Filter 的区别在哪。

三、Counter 大小的选择
CBF 和 BF 的一个主要的不同就是 CBF 用一个 Counter 取代了 BF 中的一位,那么 Counter 到底取多大才比较合适呢?这里就要考虑到空间利用率的问题了,从使用的角度来看,当然是越大越好,因为 Counter 越大就能表示越多的信息。但是越大的 Counter 就意味着更多的资源占用,而且在很多时候会造成极大的空间浪费。
因此,我们在选择 Counter 的时候,可以看 Counter 取值的范围多小就可以满足需求。
根据论文中描述,某一个 Counter 的值大于或等于 i 的概率可以通过如下公式描述,其中 n 为集合的大小,m 为 Counter 的数量,k 为 哈希函数的个数。

在之前的文章《Bloom Filter 的数学背景》中已经得出,k 的最佳取值为 k = m/n * ln2,将其带入公式后可得。

如果每个 Counter 分配 4 位,那么当 Counter 的值达到 16 时就会溢出。这个概率如下,这个值足够小,因此对于大多数应用程序来说,4位就足够了。

关于 CBF 中 Counter 大小的选择,主要参考这篇论文:《Summary Cache: A Scalable Wide-Area Web Cache Sharing Protocol》,在论文的第 6、7 两页专门对其做了一番阐述。这里不再推导细节,只给出一个大概的说明,感兴趣的童鞋可以参考原论文。
简单的实现
还是实现一个简单的程序来熟悉 CBF 的原理,这里和 BF 的区别有两个:
- 一个是我们没有用 bitarray 提供的位数组,而是使用了 bytearray 提供的一个 byte数组,因此每一个 Counter 的取值范围在 0~255。
- 另一个是多了一个 remove 方法来删除集合中的元素。
代码很简单,只是为了理解概念,实际中使用的库会有很大差别。
import mmh3
class CountingBloomFilter:
def __init__(self, size, hash_num):
self.size = size
self.hash_num = hash_num
self.byte_array = bytearray(size)
def add(self, s):
for seed in range(self.hash_num):
result = mmh3.hash(s, seed) % self.size
if self.bit_array[result] < 256:
self.bit_array[result] += 1
def lookup(self, s):
for seed in range(self.hash_num):
result = mmh3.hash(s, seed) % self.size
if self.bit_array[result] == 0:
return "Nope"
return "Probably"
def remove(self, s):
for seed in range(self.hash_num):
result = mmh3.hash(s, seed) % self.size
if self.bit_array[result] > 0:
self.bit_array[result] -= 1
cbf = CountingBloomFilter(500000, 7)
cbf.add("dantezhao")
cbf.add("yyj")
cbf.remove("dantezhao")
print (cbf.lookup("dantezhao"))
print (cbf.lookup("yyj"))
总结
CBF 虽说解决了 BF 的不能删除元素的问题,但是自身仍有不少的缺陷有待完善,比如 Counter 的引入就会带来很大的资源浪费,CBF 的 FP 还有很大可以降低的空间, 因此在实际的使用场景中会有很多 CBF 的升级版。
比如 SBF(Spectral Bloom Filter)在 CBF 的基础上提出了元素出现频率查询的概念,将CBF的应用扩展到了 multi-set 的领域;dlCBF(d-Left Counting Bloom Filter)利用 d-left hashing 的方法存储 fingerprint,解决哈希表的负载平衡问题;ACBF(Accurate Counting Bloom Filter)通过 offset indexing 的方式将 Counter 数组划分成多个层级,来降低误判率。这些内容,有机会再分享。
到此这篇关于Python Counting Bloom Filter原理与实现详细介绍的文章就介绍到这了,更多相关Python Counting Bloom Filter内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
一文详解Python中的Map,Filter和Reduce函数
目录 1. 引言 2. 高阶函数 3. Lambda表达式 4. Map函数 5. Filter函数 6. Reduce函数 7. 总结 1. 引言 本文重点介绍Python中的三个特殊函数Map,Filter和Reduce,以及如何使用它们进行代码编程.在开始介绍之前,我们先来理解两个简单的概念高阶函数和Lambda函数. 2. 高阶函数 把函数作为参数传入,这样的函数称为高阶函数,函数式编程就是指这种高度抽象的编程范式. 举例如下: def higher(your_function, som
-
python中filter,map,reduce的作用
目录 一.map函数 1. lambda函数 2. 自定义函数 二.filter函数 1. lambda函数 2. 自定义函数 三.reduce函数 1. lambda函数 2. 自定义函数 一.map函数 作用:map主要作用是计算一个序列或者多个序列进行函数映射之后的值 语法:map(function,iterable1,iterable2) 说明:function中参数值可以是一个,也可以是多个:iterable代表function运算中的参数值,有几个参数值就传入几个iterable 注
-
Python简明讲解filter函数的用法
目录 一.filter函数的定义 二.filter函数实例 求一个序列中大于零的元素组成的新序列 求序列中非零数组成的新序列 求字典中大于2的键组成的新序列 求100以内既是3的倍数又是奇数的正整数 任何事情都是由量变到质变的过程,学习Python也不例外.只有把一个语言中的常用函数了如指掌了,才能在处理问题的过程中得心应手,快速地找到最优方案. 一.filter函数的定义 filter函数是Python中常用的内置函数,调用无需加载库,直接使用即可.它主要用来根据特定条件过滤迭代器中不符合条件
-

Python Counting Bloom Filter原理与实现详细介绍
目录 前言 原理 一.BF 为什么不支持删除 二.什么是 Counting Bloom Filter 三.Counter 大小的选择 简单的实现 总结 前言 标准的 Bloom Filter 是一种比较简单的数据结构,只支持插入和查找两种操作.在所要表达的集合是静态集合的时候,标准 Bloom Filter 可以很好地工作,但是如果要表达的集合经常变动,标准Bloom Filter的弊端就显现出来了,因为它不支持删除操作.这就引出来了本文要谈的 Counting Bloom Filter,后文简
-
Python标准库datetime date模块的详细介绍
目录 前言 1.定义 1.2.常见错误 2.date类常用的函数 2.1.获取当期日期 2.2.格式化日期 2.2.1.ctime() 2.2.2.datetime.date对象 2.2.3.replace(self, year=None, month=None, day=None) 2.2.4.格式化日期 2.3.ISO标准格式日期 2.3.1.获取符合ISO标准格式的日期字符串的星期几(1~7) 2.3.2.返回日期或者时间对象的星期几(0~6) 2.3.3.根据时间戳计算日期 2.3.4.
-
golang RPC包原理和使用详细介绍
目录 工作流程 工作模式 http模式 服务器模式 本篇文章旨在通过学习rpc包和github上的一个rpc小项目,熟悉和学习golang中各个包的使用 工作流程 通过阅读官方文档,了解了rpc的基本工作模式 第一步,建立一个用于远程调用的包,存放仅供远程调用使用的方法和类型- 第二步,实例化包的对象,并在rpc中注册该包,以便之后的调用 第三步,建立一个服务端,接收客户端的请求,使用编码器解析请求后,根据请求中的方法和参数,调用第二步注册的实例的方法,然后使用编码器把返回值加密后,返回给客户端
-
python cx_Oracle模块的安装和使用详细介绍
python cx_Oracle模块的安装 最近需要写一个数据迁移脚本,将单一Oracle中的数据迁移到MySQL Sharding集群,在linux下安装cx_Oracle感觉还是有一点麻烦的,整理一下,做个总结. 对于Oracle客户端,不只需要安装相应的python模块(这里我用了Oracle官方的python模块--cx_Oracle),还需要安装Oracle Client,一般选择Instant Client就足够了,还需要配置tnsnames.ora(当然也可以简单的通过host:p
-
python 开发的三种运行模式详细介绍
Python 三种运行模式 Python作为一门脚本语言,使用的范围很广.有的同学用来算法开发,有的用来验证逻辑,还有的作为胶水语言,用它来粘合整个系统的流程.不管怎么说,怎么使用python既取决于你自己的业务场景,也取决于你自己的python应用能力.就我个人而言,我觉得python作为既可以用来进行业务的开发,也可以进行产品原型的开发.一般来说,python的运行主要下面这三种模式. 1.单循环模式 单循环模式使用的最多,也最简单,当然也最稳定.为什么呢,因为单循环本来代码就写的很少,出错
-
Python中字符串格式化str.format的详细介绍
前言 Python 在 2.6 版本中新加了一个字符串格式化方法: str.format() .它的基本语法是通过 {} 和 : 来代替以前的 %.. 格式化时的占位符语法: replacement_field ::= "{" [field_name] ["!" conversion] [":" format_spec] "}" "映射"规则 通过位置 str.format() 可以接受不限个参数,位置可以
-
Python机器学习多层感知机原理解析
目录 隐藏层 从线性到非线性 激活函数 ReLU函数 sigmoid函数 tanh函数 隐藏层 我们在前面描述了仿射变换,它是一个带有偏置项的线性变换.首先,回想下之前下图中所示的softmax回归的模型结构.该模型通过单个仿射变换将我们的输入直接映射到输出,然后进行softmax操作.如果我们的标签通过仿射变换后确实与我们的输入数据相关,那么这种方法就足够了.但是,仿射变换中的线性是一个很强的假设. 我们的数据可能会有一种表示,这种表示会考虑到我们的特征之间的相关交互作用.在此表示的基础上建立
-
python机器学习Logistic回归原理推导
目录 前言 Logistic回归原理与推导 sigmoid函数 目标函数 梯度上升法 Logistic回归实践 数据情况 训练算法 算法优缺点 前言 Logistic回归涉及到高等数学,线性代数,概率论,优化问题.本文尽量以最简单易懂的叙述方式,以少讲公式原理,多讲形象化案例为原则,给读者讲懂Logistic回归.如对数学公式过敏,引发不适,后果自负. Logistic回归原理与推导 Logistic回归中虽然有回归的字样,但该算法是一个分类算法,如图所示,有两类数据(红点和绿点)分布如下,如果
-
Python包和模块的分发详细介绍
发布Python包 上一篇介绍了如何使用别人的轮子,现在我们讨论下如何自己造轮子给别人用. 作为一个流行的开源开发项目,Python拥有一个活跃的贡献者和用户支持社区,这些社区也可以让他们的软件可供其他Python开发人员在开源许可条款下使用.这允许Python用户有效地共享和协作,从其他人已经创建的解决方案中受益于常见(有时甚至是罕见的)问题,以及可以提供他们自己的解决方案. Pypi( Python Package Index) ,公共的模块存储中心 准备 distutils 官方库dist
-
Python迭代器的实现原理
目录 前言: 迭代器的创建 迭代器的底层结构 迭代器是怎么迭代元素的? 小结 前言: 在Python里面,只要类型对象实现了__iter__,那么它的实例对象就被称为可迭代对象(Iterable),比如字符串.元组.列表.字典.集合等等.而整数.浮点数,由于其类型对象没有实现__iter__,所以它们不是可迭代对象. from typing import Iterable print( isinstance("", Iterable), isinstance((), Iterable)