使用Tensorflow hub完成目标检测过程详解
目录
- 前言
- 导入必要的库
- 准备数据和模型
- 目标检测
前言
本文主要介绍使用 tensorflow hub 中的 CenterNet HourGlass104 Keypoints 模型来完成简单的目标检测任务。使用到的主要环境是:
- tensorflow-cpu=2.10
- tensorflow-hub=0.11.0
- tensorflow-estimator=2.6.0
- python=3.8
- protobuf=3.20.1
导入必要的库
首先导入必要的 python 包,后面要做一些复杂的安装和配置工作,需要一点耐心和时间。在运行下面代码的时候可能会报错:
TypeError: Descriptors cannot not be created directly. If this call came from a _pb2.py file, your generated code is out of date and must be regenerated with protoc >= 3.19.0. If you cannot immediately regenerate your protos, some other possible workarounds are: 1. Downgrade the protobuf package to 3.20.x or lower. 2. Set PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION=python (but this will use pure-Python parsing and will be much slower).
你只需要重新使用 pip 安装,将 protobuf 降低到 3.20.x 版本即可。
import os
import pathlib
import matplotlib
import matplotlib.pyplot as plt
import io
import scipy.misc
import numpy as np
from six import BytesIO
from PIL import Image, ImageDraw, ImageFont
from six.moves.urllib.request import urlopen
import tensorflow as tf
import tensorflow_hub as hub
tf.get_logger().setLevel('ERROR')
准备数据和模型
(1)到 github.com/protocolbuf… 用迅雷下载对应操作系统的压缩包,我的是 win7 版本: github.com/protocolbuf…
(2)下载好之后随便解压到自定义目录,我的是 “主目录\protoc-22.1-win64”,然后将其中的 “主目录\protoc-22.1-win64\bin” 路径添加到用户环境变量中的 PATH 变量中,重新打开命令行,输入 protoc --version ,如果能正常返回版本号说明配置成功,可以开始使用。
(3)进入命令行,在和本文件同一个目录下,执行命令
git clone --depth 1 https://github.com/tensorflow/models
,将 models 文件夹下载下来,进入 models/research/ 下,使用命令执行
protoc object_detection/protos/*.proto --python_out=.
将 models/research/object_detection/packages/tf2/setup.py 拷贝到和 models/research/ 下,然后使用执行本文件的 python 对应的 pip 去执行安装包操作
..\Anaconda3\envs\tfcpu2.10_py38\Scripts\pip.exe install . -i https://pypi.tuna.tsinghua.edu.cn/simple
中间可能会报错“error: netadata-generation-failed”,一般都是某个包安装的时候出问题了,我们只需要看详细的日志,单独用 pip 进行安装即可,单独安装完之后,再去执行上面的根据 setup.py 的整装操作,反复即可,过程有点麻烦但还是都可以安装成功的。
(4)这里的模型本来在:
https://tfhub.dev/tensorflow/centernet/hourglass\_512x512\_kpts/1
但是由于网络问题无法获取,所以我们可以改为从
https://storage.googleapis.com/tfhub-modules/tensorflow/centernet/hourglass\_512x512\_kpts/1.tar.gz
获取模型。
from object_detection.utils import label_map_util
from object_detection.utils import visualization_utils as viz_utils
from object_detection.utils import ops as utils_ops
PATH_TO_LABELS = './models/research/object_detection/data/mscoco_label_map.pbtxt'
category_index = label_map_util.create_category_index_from_labelmap(PATH_TO_LABELS, use_display_name=True)
model_path = 'https://storage.googleapis.com/tfhub-modules/tensorflow/centernet/hourglass_512x512_kpts/1.tar.gz'
print('TensorFlow Hub 中的模型地址: {}'.format(model_path))
print('加载模型...')
hub_model = hub.load(model_path)
print('加载成功!')
打印结果:
TensorFlow Hub 中的模型地址: https://storage.googleapis.com/tfhub-modules/tensorflow/centernet/hourglass_512x512_kpts/1.tar.gz 加载模型... WARNING:absl:Importing a function (__inference_batchnorm_layer_call_and_return_conditional_losses_42408) with ops with custom gradients. Will likely fail if a gradient is requested. WARNING:absl:Importing a function (__inference_batchnorm_layer_call_and_return_conditional_losses_209416) with ops with custom gradients. Will likely fail if a gradient is requested. ... WARNING:absl:Importing a function (__inference_batchnorm_layer_call_and_return_conditional_losses_56488) with ops with custom gradients. Will likely fail if a gradient is requested. 加载成功!
(5)在这里我们主要定义了一个函数 load_image_into_numpy_array 来加载从网上下载图片的图片,并将其转换为模型可以适配的输入类型。
(6)IMAGES_FOR_TEST 字典中记录了多个可以用来测试的图片,但是这些都是在网上,用的使用需要调用 load_image_into_numpy_array 函数。
(7)COCO17_HUMAN_POSE_KEYPOINTS 记录了人体姿态关键点。
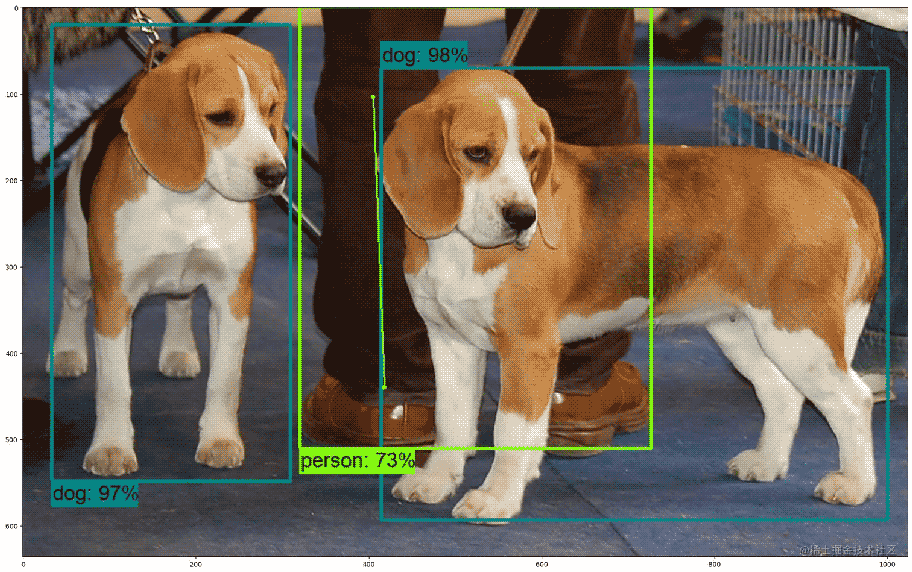
(8)我们这里展示了 dogs 这张图片,可以看到两条可爱的小狗。
def load_image_into_numpy_array(path):
image = None
if(path.startswith('http')):
response = urlopen(path)
image_data = response.read()
image_data = BytesIO(image_data)
image = Image.open(image_data)
else:
image_data = tf.io.gfile.GFile(path, 'rb').read()
image = Image.open(BytesIO(image_data))
(im_width, im_height) = image.size
return np.array(image.getdata()).reshape((1, im_height, im_width, 3)).astype(np.uint8)
IMAGES_FOR_TEST = {
'Beach' : 'models/research/object_detection/test_images/image2.jpg',
'Dogs' : 'models/research/object_detection/test_images/image1.jpg',
'Naxos Taverna' : 'https://upload.wikimedia.org/wikipedia/commons/6/60/Naxos_Taverna.jpg',
'Beatles' : 'https://upload.wikimedia.org/wikipedia/commons/1/1b/The_Coleoptera_of_the_British_islands_%28Plate_125%29_%288592917784%29.jpg',
'Phones' : 'https://upload.wikimedia.org/wikipedia/commons/thumb/0/0d/Biblioteca_Maim%C3%B3nides%2C_Campus_Universitario_de_Rabanales_007.jpg/1024px-Biblioteca_Maim%C3%B3nides%2C_Campus_Universitario_de_Rabanales_007.jpg',
'Birds' : 'https://upload.wikimedia.org/wikipedia/commons/0/09/The_smaller_British_birds_%288053836633%29.jpg',
}
COCO17_HUMAN_POSE_KEYPOINTS = [(0, 1), (0, 2),(1, 3),(2, 4),(0, 5),(0, 6),(5, 7),(7, 9),(6, 8),(8, 10),(5, 6),(5, 11), (6, 12),(11, 12),(11, 13),(13, 15),(12, 14),(14, 16)]
%matplotlib inline
selected_image = 'Dogs'
image_path = IMAGES_FOR_TEST[selected_image]
image_np = load_image_into_numpy_array(image_path)
plt.figure(figsize=(24,32))
plt.imshow(image_np[0])
plt.show()

目标检测
我们这里将经过处理的小狗的图片传入模型中,会返回结果,我们只要使用结果来绘制出所检测目标的框,以及对应的类别,分数,可以看出来结果是相当的准确的,甚至通过人的腿就能识别出人的框。
results = hub_model(image_np)
result = {key:value.numpy() for key,value in results.items()}
label_id_offset = 0
image_np_with_detections = image_np.copy()
keypoints, keypoint_scores = None, None
if 'detection_keypoints' in result:
keypoints = result['detection_keypoints'][0]
keypoint_scores = result['detection_keypoint_scores'][0]
viz_utils.visualize_boxes_and_labels_on_image_array(
image_np_with_detections[0],
result['detection_boxes'][0],
(result['detection_classes'][0] + label_id_offset).astype(int),
result['detection_scores'][0],
category_index,
use_normalized_coordinates=True,
max_boxes_to_draw=200,
min_score_thresh=.30,
agnostic_mode=False,
keypoints=keypoints,
keypoint_scores=keypoint_scores,
keypoint_edges=COCO17_HUMAN_POSE_KEYPOINTS)
plt.figure(figsize=(24,32))
plt.imshow(image_np_with_detections[0])
plt.show()
以上就是使用Tensorflow hub完成目标检测过程详解的详细内容,更多关于Tensorflow hub目标检测的资料请关注我们其它相关文章!
相关推荐
-
Tensorflow 2.4 搭建单层和多层 Bi-LSTM 模型
目录 前言 实现过程 1. 获取数据 2. 处理数据 3. 单层 Bi-LSTM 模型 4. 多层 Bi-LSTM 模型 前言 本文使用 cpu 版本的 TensorFlow 2.4 ,分别搭建单层 Bi-LSTM 模型和多层 Bi-LSTM 模型完成文本分类任务. 确保使用 numpy == 1.19.0 左右的版本,否则在调用 TextVectorization 的时候可能会报 NotImplementedError . 实现过程 1. 获取数据 (1)我们本文用到的数据是电影的影评数据,每
-
Tensorflow2.4从头训练Word Embedding实现文本分类
目录 前言 具体介绍 1. 三种文本向量化方法 2. 获取数据 3. 处理数据 4. 搭建.训练模型 5. 导出训练好的词嵌入向量 前言 本文主要使用 cpu 版本的 tensorflow 2.4 版本完成文本的 word embedding 训练,并且以此为基础完成影评文本分类任务. 具体介绍 1. 三种文本向量化方法 通常在深度学习模型中我们的输入都是以向量形式存在的,所以我们处理数据过程的重要一项任务就是将文本中的 token (一个 token 可以是英文单词.一个汉字.一个中文词语等,
-
使用TensorFlow创建生成式对抗网络GAN案例
目录 导入必要的库和模块 定义训练循环 最后定义主函数 导入必要的库和模块 以下是使用TensorFlow创建一个生成式对抗网络(GAN)的案例: 首先,我们需要导入必要的库和模块: import tensorflow as tf from tensorflow.keras import layers import matplotlib.pyplot as plt import numpy as np 然后,我们定义生成器和鉴别器模型.生成器模型将随机噪声作为输入,并输出伪造的图像.鉴别器模型则
-
TensorFlow.js实现AI换脸使用示例详解
目录 前言 步骤 1:准备工作 步骤 2:加载模型 步骤 3:加载图片 步骤 4:提取面部关键点 步骤 5:应用变形 写在最后 前言 相信很多小伙伴对TensorFlow.js早已有所耳闻,它是一个基于JavaScript的深度学习库,可以在Web浏览器中运行深度学习模型.AI换脸是一种基于深度学习的图像处理技术,将一张人脸照片的表情.头发.嘴唇等特征转移到另一张人脸照片上,从而实现换脸效果.本文将介绍如何使用TensorFlow.js实现AI换脸 步骤 1:准备工作 在开始之前,需要确保已经安
-
深度学习Tensorflow2.8 使用 BERT 进行文本分类
目录 前言 1. python 库准备 2. BERT 是什么? 3. 获取并处理 IMDB 数据 4. 初识 TensorFlow Hub 中的 BERT 处理器和模型 5. 搭建模型 6. 训练模型 7. 测试模型 8. 保存模型 9. 重新加载模型并进行预测 前言 本文使用 cpu 版本的 Tensorflow 2.8 ,通过搭建 BERT 模型完成文本分类任务. 1. python 库准备 为了保证能正常运行本文代码,需要保证以下库的版本: tensorflow==2.8.4 tenso
-

python目标检测yolo2详解及预测代码复现
目录 前言 实现思路 1.yolo2的预测思路(网络构建思路) 2.先验框的生成 3.利用先验框对网络的输出进行解码 4.进行得分排序与非极大抑制筛选 实现结果 前言 ……最近在学习yolo1.yolo2和yolo3,写这篇博客主要是为了让自己对yolo2的结构有更加深刻的理解,同时要理解清楚先验框的含义. 尽量配合代码观看会更容易理解. 直接下载 实现思路 1.yolo2的预测思路(网络构建思路) YOLOv2使用了一个新的分类网络DarkNet19作为特征提取部分,DarkNet19包含19
-
python目标检测yolo3详解预测及代码复现
目录 学习前言 实现思路 1.yolo3的预测思路(网络构建思路) 2.利用先验框对网络的输出进行解码 3.进行得分排序与非极大抑制筛选 实现结果 学习前言 对yolo2解析完了之后当然要讲讲yolo3,yolo3与yolo2的差别主要在网络的特征提取部分,实际的解码部分其实差距不大 代码下载 本次教程主要基于github中的项目点击直接下载,该项目相比于yolo3-Keras的项目更容易看懂一些,不过它的许多代码与yolo3-Keras相同. 我保留了预测部分的代码,在实际可以通过执行dete
-
Python Flask搭建yolov3目标检测系统详解流程
[人工智能项目]Python Flask搭建yolov3目标检测系统 后端代码 from flask import Flask, request, jsonify from PIL import Image import numpy as np import base64 import io import os from backend.tf_inference import load_model, inference os.environ['CUDA_VISIBLE_DEVICES'] = '
-
opencv调用yolov3模型深度学习目标检测实例详解
目录 引言 建立相关目录 代码详解 附源代码 引言 opencv调用yolov3模型进行深度学习目标检测,以实例进行代码详解 对于yolo v3已经训练好的模型,opencv提供了加载相关文件,进行图片检测的类dnn. 下面对怎么通过opencv调用yolov3模型进行目标检测方法进行详解,付源代码 建立相关目录 在训练结果backup文件夹下,找到模型权重文件,拷到win的工程文件夹下 在cfg文件夹下,找到模型配置文件,yolov3-voc.cfg拷到win的工程文件夹下 在data文件夹下
-
jenkins和sonar实现代码检测过程详解
一.首先安装sonar scanner的客户端 我的jenkins版本为2.176.2 安装sonar需要安装客户端和服务端,这里只讲述客户端的相关配置.安装步骤省略 二.然后配置sonar scanner的环境变量 编辑服务器的profile文件, vim /etc/profile,添加环境变量 export MAVEN_HOME=/opt/servers/apache-maven-3.6.1 export SONAR_SCANNER_HOME=/opt/sonar-scanner 三.首先安
-
基于迁移学习的JS目标检测器构建过程详解
目录 正文 步骤一:安装依赖 步骤二:加载预先训练的模型 步骤三:处理图像 步骤四:运行模型 步骤五:显示检测结果 最后 正文 在计算机视觉领域,目标检测是一个非常重要的任务.它可以应用于许多领域,如自动驾驶.安防.医疗等.在本文中,我们将介绍如何使用迁移学习构建一个基于JavaScript的目标检测器. 迁移学习是一种将已训练好的模型应用于新问题的方法.我们可以使用已经训练好的模型作为起点,并在新数据集上进行微调来解决新问题.这种方法可以大大减少模型的训练时间,并获得更好的性能. 在本文中,我
-
C#中应用程序集的装载过程详解
了解程序集如何在C#.NET中加载 我们一直在处理库和NuGet软件包.不管是好是坏,高级.NET开发人员都需要了解.NET运行时如何加载程序集. 这些库依赖于其他流行的库,并且有很多共享的依赖项.有了足够大的依赖关系网络,您最终将陷入冲突或困境.处理此类问题的最佳方法是了解该机制在内部的工作方式. 在本文中,您将看到.NET进程如何以及何时加载引用的程序集. 您将了解加载了哪个库版本,当有多个可用版本时会发生什么,以及为什么有时由于版本冲突而出现问题. 您将看到如何调试这些类型的问题,查看程序
-
docker 使用GPU的过程详解
目录 下载tf-gpu 基于拉的tf-gpu镜像构建自己的镜像 启动镜像检查GPU是否可用 以TensorFlow2.0为例 下载tf-gpu 在docker hub里选择要下载的tf版本(注意选带GPU和py3的) https://hub.docker.com/r/tensorflow/tensorflow/ 如: docker pull tensorflow/tensorflow:2.0.3-gpu-py3 如果上述下载超时,可以配置清华源. 或者通过如下命令下载: docker pull
-
Python OpenCV实现图形检测示例详解
目录 1. 轮廓识别与描绘 1.1 cv2.findComtours()方法 1.2 cv2.drawContours() 方法 1.3 代码示例 2. 轮廓拟合 2.1 矩形包围框拟合 - cv2.boundingRect() 2.2圆形包围框拟合 - cv2.minEnclosingCircle() 3. 凸包 绘制 4. Canny边缘检测 - cv2.Canny() 4.1 cv2.Canny() 用法简介 4.2 代码示例 5. 霍夫变换 5.1 概述 5.2 cv2.HoughLin
-
Android4.X中SIM卡信息初始化过程详解
本文实例讲述了Android4.X中SIM卡信息初始化过程详解.分享给大家供大家参考,具体如下: Phone 对象初始化的过程中,会加载SIM卡的部分数据信息,这些信息会保存在IccRecords 和 AdnRecordCache 中.SIM卡的数据信息的初始化过程主要分为如下几个步骤 1.RIL 和 UiccController 建立监听关系 ,SIM卡状态发生变化时,UiccController 第一个去处理. Phone 应用初始化 Phone 对象时会建立一个 RIL 和UiccCont