java抓取12306信息实现火车余票查询示例
最近在弄一个微信的公众帐号,涉及到火车票查询,之前用的网上找到的一个接口,但只能查到火车时刻表,12306又没有提供专门的查票的接口。今天突然想起自己直接去12306上查询,抓取查询返回的数据包,这样就可以得到火车票的信息。这里就随笔记一下获取12306余票的过程。
首先,我用firefox浏览器上12306查询余票。打开firefox的Web控制台,选上网络中的“记录请求和响应主体”
然后输入地址日期信息之后点击网页上的查询按钮,就能在Web控制台下看到网页请求的地址了:

就是图片中的第二条,即当你点击查询按钮时,处理该事件的实际地址。点开它可以看到
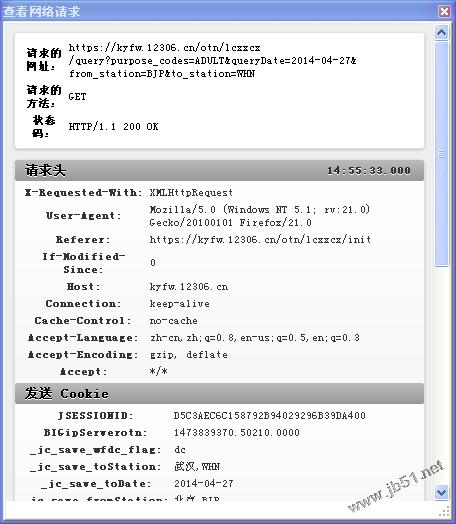
请求网址,请求头,响应头和响应主体这些东西,响应主体里就是我们需要的火车票信息。
有了这个请求网址了就可以到实际代码中进行操作了。可以发现网址的格式是
前面是处理请求的地址,后面接的参数purpose_codes是指成人票(AADULT),学生票(自己去试试吧),queryDate就是日期,from_station和to_station顾名思义就是出发站和到达站了。这里北京和武汉分别表示为BJP和WHN。
到java代码里就可以直接写https请求来获取火车票信息数据包了
public static List<NewTrain> getmsg(String startCity,String endCity,int isAdult) throws Exception{
List<NewTrain> trains = new ArrayList<NewTrain>();
String sstartCity = CityCode.format(startCity);
String sendCity = CityCode.format(endCity);
TrustManager[] tm = {new MyX509TrustManager()};
SSLContext sslContext = SSLContext.getInstance("SSL", "SunJSSE");
sslContext.init(null, tm, new java.security.SecureRandom());
// 从上述SSLContext对象中得到SSLSocketFactory对象
SSLSocketFactory ssf = sslContext.getSocketFactory();
String type = "ADULT";
if(isAdult == 1){
type = "0X00";
}
String urlStr = "https://kyfw.12306.cn/otn/lcxxcx/query?purpose_codes="+type+"&queryDate=2014-04-27&from_station="+sstartCity+"&to_station="+sendCity;
URL url = new URL(urlStr);
HttpsURLConnection con = (HttpsURLConnection) url.openConnection();
con.setSSLSocketFactory(ssf);
InputStreamReader in = new InputStreamReader(con.getInputStream(),"utf-8");
BufferedReader bfreader = new BufferedReader(in);
StringBuffer sb = new StringBuffer();
String line = "";
while ((line = bfreader.readLine()) != null) {
sb.append(line);
}
System.out.println(sb.toString());
}
这段代码的cityCode.format()是自己写的将中文的站名转换为字母组合,下面那几行是关于https请求的。网址就是刚才获取到的网址。这段代码执行后得到的输出内容如下:

很容易看出来这些数据是一条条的json数据(我进行了简单的处理,让他一条条打印出来)。
既然是json数据就好办了。取出一条数据来进行分析就可以分析出来key值代表的意思。我只分析了几个我需要的key值

然后就直接写一个Train类来储存火车票的信息,便于之后显示用了。
public class NewTrain {
private String to_station_name; //到达地
private String station_train_code; //火车编号
private String from_station_name; //出发地
private String start_time; //出发时间
private String arrive_time; // 到达时间
private String lishi; // 需要时间
private String zy_num; // 一等座数量
private String ze_num; // 二等座数量
private String swz_num; // 商务座数量
private String gr_num; // 高级软卧数量
private String rw_num; // 软卧数量
private String rz_num; // 软座数量
private String yw_num; // 硬卧数量
private String yz_num; // 硬座数量
private String tz_num; // 特等座数量
private String wz_num; // 无座数量
}
接下来的工作就很简单了,将json数据放入Train类对象中。
好了,基本工作完成了,接下来的工作就是将功能整合到项目里去了。
这其中用到的中文站名跟字母组合的一个txt文件(读txt获取中文站名对应的字母的组合,有一些可能不全
相关推荐
-
java 抓取网页内容实现代码
复制代码 代码如下: package test; import java.io.BufferedReader; import java.io.IOException; import java.io.InputStream; import java.io.InputStreamReader; import java.net.Authenticator; import java.net.HttpURLConnection; import java.net.PasswordAuthentication
-
JAVA使用爬虫抓取网站网页内容的方法
本文实例讲述了JAVA使用爬虫抓取网站网页内容的方法.分享给大家供大家参考.具体如下: 最近在用JAVA研究下爬网技术,呵呵,入了个门,把自己的心得和大家分享下 以下提供二种方法,一种是用apache提供的包.另一种是用JAVA自带的. 代码如下: // 第一种方法 //这种方法是用apache提供的包,简单方便 //但是要用到以下包:commons-codec-1.4.jar // commons-httpclient-3.1.jar // commons-logging-1.0.4.jar
-
java抓取鼠标事件和鼠标滚轮事件示例
java抓取鼠标事件和滚轮事件 复制代码 代码如下: package demo; import java.awt.event.MouseEvent;import java.awt.event.MouseListener;import java.awt.event.MouseWheelEvent;import java.awt.event.MouseWheelListener; import javax.swing.JButton;import javax.swing.JFrame;import
-
java简单网页抓取的实现方法
本文实例讲述了java简单网页抓取的实现方法.分享给大家供大家参考.具体分析如下: 背景介绍 一 tcp简介 1 tcp 实现网络中点对点的传输 2 传输是通过ports和sockets ports提供了不同类型的传输(例如 http的port是80) 1)sockets可以绑定在特定端口上,并且提供传输功能 2)一个port可以连接多个socket 二 URL简介 URL 是对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址. 互联网上的每个文件都有一个唯一的
-

零基础写Java知乎爬虫之抓取知乎答案
前期我们抓取标题是在该链接下: http://www.zhihu.com/explore/recommendations 但是显然这个页面是无法获取答案的. 一个完整问题的页面应该是这样的链接: http://www.zhihu.com/question/22355264 仔细一看,啊哈我们的封装类还需要进一步包装下,至少需要个questionDescription来存储问题描述: import java.util.ArrayList;public class Zhihu { public St
-
零基础写Java知乎爬虫之将抓取的内容存储到本地
说到Java的本地存储,肯定使用IO流进行操作. 首先,我们需要一个创建文件的函数createNewFile: 复制代码 代码如下: public static boolean createNewFile(String filePath) { boolean isSuccess = true; // 如有则将"\\"转为"/",没有则不产生任何变化 String filePathTurn = filePath.r
-
java代码抓取网页邮箱的实现方法
实现思路: 1.使用java.net.URL对象,绑定网络上某一个网页的地址 2.通过java.net.URL对象的openConnection()方法获得一个HttpConnection对象 3.通过HttpConnection对象的getInputStream()方法获得该网络文件的输入流对象InputStream 4.循环读取流中的每一行数据,并由Pattern对象编译的正则表达式区配每一行字符,取得email地址 package cn.sdhzzl; import java.io.Buf
-
java抓取网页或文件中的邮箱号码
本文实例为大家分享了java抓取邮箱号码的具体代码,供大家参考,具体内容如下 java抓取文件中邮箱号码的具体代码 package reg; import java.io.BufferedReader; import java.io.FileNotFoundException; import java.io.FileReader; import java.io.IOException; import java.util.ArrayList; import java.util.List; impo
-
java抓取网页数据获取网页中所有的链接实例分享
效果图 复制代码 代码如下: import java.io.BufferedReader;import java.io.IOException;import java.io.InputStreamReader;import java.net.HttpURLConnection;import java.net.URL;import java.util.ArrayList;import java.util.regex.Matcher;import java.util.regex.Pattern; p
-
java使用正则抓取网页邮箱
使用正则抓捕网上邮箱 这就是我们需要抓捕的网站. 实现思路: 1.使用java.net.URL对象,绑定网络上某一个网页的地址 2.通过java.net.URL对象的openConnection()方法获得一个HttpConnection对象 3.通过HttpConnection对象的getInputStream()方法获得该网络文件的输入流对象InputStream 4.循环读取流中的每一行数据,并由Pattern对象编译的正则表达式区配每一行字符,取得email地址 下面是我们的代码: pa