基于java下载中getContentLength()一直为-1的一些思路
如果Content Length 在头文件中没有描述
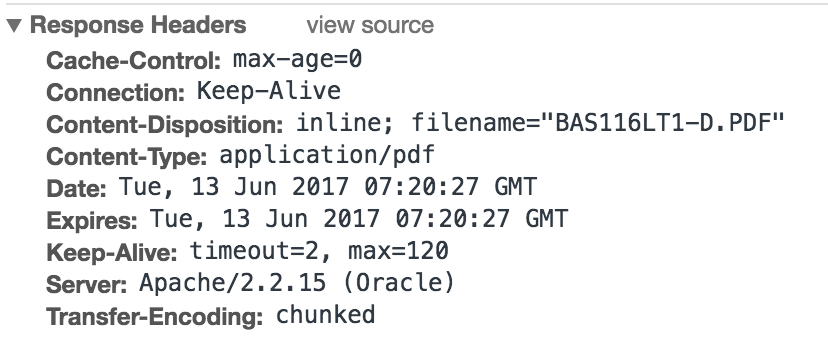
暂时还没有解决方案
如果Content Long在头文件中有描述
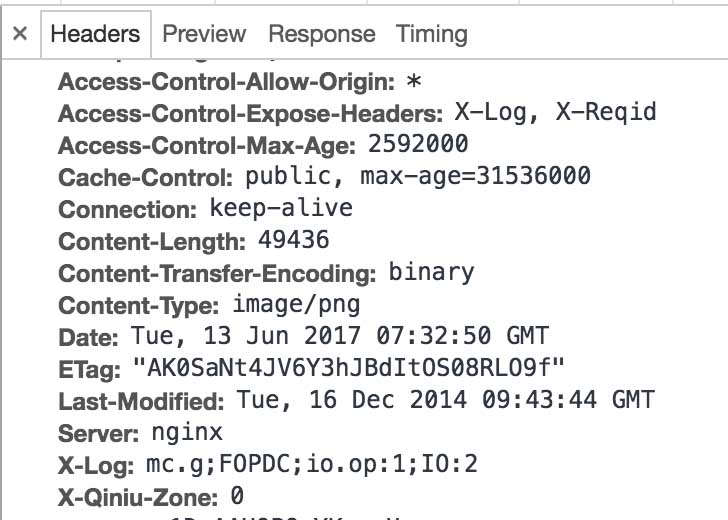
方案一:
伪装成浏览器
conn.setRequestProperty("User-Agent", " Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36");
代码中加入代理
String host = "127.0.0.1";
String port = "8888";
setProxy(host, port);
public static void setProxy(String host, String port) {
System.setProperty("proxySet", "true");
System.setProperty("proxyHost", host);
System.setProperty("proxyPort", port);
}
方案二:
加入以下属性,让服务器不要gzip方式压缩:
Java Doc 有对此的描述:
By default, this implementation of HttpURLConnection requests that servers use gzip compression. Since getContentLength() returns the number of bytes transmitted, you cannot use that method to predict how many bytes can be read from getInputStream(). Instead, read that stream until it is exhausted: whenread() returns -1.
conn.setRequestProperty("Accept-Encoding", "identity");
以上这篇基于java下载中getContentLength()一直为-1的一些思路就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

基于java下载中getContentLength()一直为-1的一些思路
如果Content Length 在头文件中没有描述 暂时还没有解决方案 如果Content Long在头文件中有描述 方案一: 伪装成浏览器 conn.setRequestProperty("User-Agent", " Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36")
-
基于java集合中的一些易混淆的知识点(详解)
(一) collection和collections 这两者均位于java.util包下,不同的是: collection是一个集合接口,有ListSet等常见的子接口,是集合框架图的第一个节点,,提供了对集合对象进行基本操作的一系列方法. 常见的方法有: boolean add(E e) 往容器中添加元素:int size() 返回collection的元素数:boolean isEmpty() 判断此容器是否为空: boolean contains(Object o) 如果此collecti
-
基于JAVA文件中获取路径及WEB应用程序获取路径的方法
1. 基本概念的理解 `绝对路径`:你应用上的文件或目录在硬盘上真正的路径,如:URL.物理路径 例如: c:/xyz/test.txt代表了test.txt文件的绝对路径: http://www.sun.com/index.htm也代表了一个URL绝对路径: `相对路径`:相对与某个基准目录的路径,包含Web的相对路径(HTML中的相对目录). 例如: 在Servlet中,"/"代表Web应用的根目录,和物理路径的相对表示. 例如: "./"代表当前目录,&quo
-
Java下载远程服务器文件到本地(基于http协议和ssh2协议)
Java中java.io包为我们提供了输入流和输出流,对文件的读写基本上都依赖于这些封装好的关于流的类中来实现.前段时间遇到了以下两种需求: 1.与某系统对接,每天获取最新的图片并显示在前端页面.该系统提供的是一个http协议的图片URL,本来获取到该系统的图片地址以后在HTML中显示就可以了,但是该系统不太稳定,图片URL经常不能使用,而且每天生成图片不一定成功, 对自己系统的功能影响很大,emm...所以就考虑每天从该系统下载最新的图片到本地更新保存,没有新图片就继续使用上次的图片. 2.公
-
基于Java中的StringTokenizer类详解(推荐)
StringTokenizer是字符串分隔解析类型,属于:Java.util包. 1.StringTokenizer的构造函数 StringTokenizer(String str):构造一个用来解析str的StringTokenizer对象.java默认的分隔符是"空格"."制表符('\t')"."换行符('\n')"."回车符('\r')". StringTokenizer(String str,String delim)
-
基于Java中字符串内存位置详解
前言 之前写过一篇关于JVM内存区域划分的文章,但是昨天接到蚂蚁金服的面试,问到JVM相关的内容,解释一下JVM的内存区域划分,这部分答得还不错,但是后来又问了Java里面String存放的位置,之前只记得String是一个不变的量,应该是要存放在常量池里面的,但是后来问到new一个String出来应该是放到哪里的,这个应该是放到堆里面的,后来又问到String的引用是放在什么地方的,当时傻逼的说也是放在堆里面的,现在总结一下:基本类型的变量数据和对象的引用都是放在栈里面的,对象本身放在堆里面,
-
java开发中基于JDBC连接数据库实例总结
本文实例讲述了java开发中基于JDBC连接数据库的方法.分享给大家供大家参考,具体如下: 创建一个以JDBC连接数据库的程序,包含7个步骤: 1.加载JDBC驱动程序: 在连接数据库之前,首先要加载想要连接的数据库的驱动到JVM(Java虚拟机),这通过java.lang.Class类的静态方法forName(String className)实现. 例如: try{ //加载MySql的驱动类 Class.forName("com.mysql.jdbc.Driver") ; }c
-
基于Java中Math类的常用函数总结
Java中比较常用的几个数学公式的总结: //取整,返回小于目标函数的最大整数,如下将会返回-2 Math.floor(-1.8): //取整,返回发育目标数的最小整数 Math.ceil() //四舍五入取整 Math.round() //计算平方根 Math.sqrt() //计算立方根 Math.cbrt() //返回欧拉数e的n次幂 Math.exp(3); //计算乘方,下面是计算3的2次方 Math.pow(3,2); //计算自然对数 Math.log(); //计算绝对值 Mat
-
基于java中cookie和session的比较
cookie和session的比较 一.对于cookie: ①cookie是创建于服务器端 ②cookie保存在浏览器端 ③cookie的生命周期可以通过cookie.setMaxAge(2000);来设置,如果没有设置setMaxAge, 则cookie的生命周期当浏览器关闭的时候,就消亡了 ④cookie可以被多个同类型的浏览器共享 可以把cookie想象成一张表 比较: ①存在的位置: cookie 存在于客户端,临时文件夹中 session:存在于服务器的内存中,一个session域对
-
基于java中的PO VO DAO BO POJO(详解)
一.PO:persistant object 持久对象,可以看成是与数据库中的表相映射的ava对象. 最简单的PO就是对应数据库中某个表中的一条记录,多个记录可以用PO的集合PO中应该不包含任何对数据库的操作. 二.VO:value object值对象.通常用于业务层之间的数据传递,和PO一样也是仅仅包含数据而已.但应是抽象出的业务对象可以和表对应也可以不这根据业务的需要 三.DAO:data access object 数据访问对象,此对象用于访问数据库.通常和PO结合使用,DAO中包含了各种