使用Redis实现UA池的方案
最近忙于业务开发、交接和游戏,加上碰上了不定时出现的犹豫期和困惑期,荒废学业了一段时间。天冷了,要重新拾起开始下阶段的学习了。之前接触到的一些数据搜索项目,涉及到请求模拟,基于反爬需要使用随机的 User Agent ,于是使用 Redis 实现了一个十分简易的 UA 池。
背景
最近的一个需求,有模拟请求的逻辑,要求每次请求的请求头中的 User Agent 要满足下面几点:
- 每次获取的
User Agent是随机的。 - 每次获取的
User Agent(短时间内)不能重复。 - 每次获取的
User Agent必须带有主流的操作系统信息(可以是Uinux、Windows、IOS和安卓等等)。
这里三点都可以从 UA 数据的来源解决,实际上我们应该关注具体的实现方案。简单分析一下,流程如下:

在设计 UA 池的时候,它的数据结构和环形队列十分类似:

上图中,假设不同颜色的 UA 是完全不同的 UA ,它们通过洗牌算法打散放进去环形队列中,实际上每次取出一个 UA 之后,只需要把游标 cursor 前进或者后退一格即可(甚至可以把游标设置到队列中的任意元素)。最终的实现就是:需要通过中间件实现分布式队列(只是队列,不是消息队列)。
具体实现方案
毫无疑问需要一个分布式数据库类型的中间件才能存放已经准备好的 UA ,第一印象就感觉 Redis 会比较合适。接下来需要选用 Redis 的数据类型,主要考虑几个方面:
UA
支持这几个方面的 Redis 数据类型就是 List ,不过注意 List 本身不能去重,去重的工作可以用代码逻辑实现。然后可以想象客户端获取 UA 的流程大致如下:
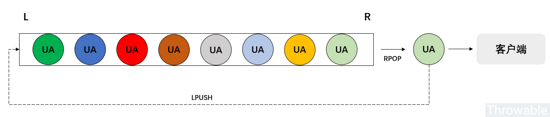
结合前面的分析,编码过程有如下几步:
准备好需要导入的 UA 数据,可以从数据源读取,也可以直接文件读取。
- 因为需要导入的
UA数据集合一般不会太大,考虑先把这个集合的数据随机打散,如果使用Java开发可以直接使用Collections#shuffle()洗牌算法,当然也可以自行实现这个数据随机分布的算法, 这一步对于一些被模拟方会严格检验UA合法性的场景是必须的 。 - 导入
UA数据到Redis列表中。 - 编写
RPOP + LPUSH的Lua脚本,实现分布式循环队列。
编码和测试示例
引入 Redis 的高级客户端 Lettuce 依赖:
<dependency> <groupId>io.lettuce</groupId> <artifactId>lettuce-core</artifactId> <version>5.2.1.RELEASE</version> </dependency>
编写 RPOP + LPUSH 的 Lua 脚本, Lua 脚本名字暂称为 L_RPOP_LPUSH.lua ,放在 resources/scripts/lua 目录下:
local key = KEYS[1]
local value = redis.call('RPOP', key)
redis.call('LPUSH', key, value)
return value
这个脚本十分简单,但是已经实现了循环队列的功能。剩下来的测试代码如下:
public class UaPoolTest {
private static RedisCommands<String, String> COMMANDS;
private static AtomicReference<String> LUA_SHA = new AtomicReference<>();
private static final String KEY = "UA_POOL";
@BeforeClass
public static void beforeClass() throws Exception {
// 初始化Redis客户端
RedisURI uri = RedisURI.builder().withHost("localhost").withPort(6379).build();
RedisClient redisClient = RedisClient.create(uri);
StatefulRedisConnection<String, String> connect = redisClient.connect();
COMMANDS = connect.sync();
// 模拟构建UA池的原始数据,假设有10个UA,分别是UA-0 ... UA-9
List<String> uaList = Lists.newArrayList();
IntStream.range(0, 10).forEach(e -> uaList.add(String.format("UA-%d", e)));
// 洗牌
Collections.shuffle(uaList);
// 加载Lua脚本
ClassPathResource resource = new ClassPathResource("/scripts/lua/L_RPOP_LPUSH.lua");
String content = StreamUtils.copyToString(resource.getInputStream(), StandardCharsets.UTF_8);
String sha = COMMANDS.scriptLoad(content);
LUA_SHA.compareAndSet(null, sha);
// Redis队列中写入UA数据,数据量多的时候可以考虑分批写入防止长时间阻塞Redis服务
COMMANDS.lpush(KEY, uaList.toArray(new String[0]));
}
@AfterClass
public static void afterClass() throws Exception {
COMMANDS.del(KEY);
}
@Test
public void testUaPool() {
IntStream.range(1, 21).forEach(e -> {
String result = COMMANDS.evalsha(LUA_SHA.get(), ScriptOutputType.VALUE, KEY);
System.out.println(String.format("第%d次获取到的UA是:%s", e, result));
});
}
}
某次运行结果如下:
第1次获取到的UA是:UA-0
第2次获取到的UA是:UA-8
第3次获取到的UA是:UA-2
第4次获取到的UA是:UA-4
第5次获取到的UA是:UA-7
第6次获取到的UA是:UA-5
第7次获取到的UA是:UA-1
第8次获取到的UA是:UA-3
第9次获取到的UA是:UA-6
第10次获取到的UA是:UA-9
第11次获取到的UA是:UA-0
第12次获取到的UA是:UA-8
第13次获取到的UA是:UA-2
第14次获取到的UA是:UA-4
第15次获取到的UA是:UA-7
第16次获取到的UA是:UA-5
第17次获取到的UA是:UA-1
第18次获取到的UA是:UA-3
第19次获取到的UA是:UA-6
第20次获取到的UA是:UA-9
可见洗牌算法的效果不差,数据相对分散。
小结
其实 UA 池的设计难度并不大,需要注意几个要点:
- 一般主流的移动设备或者桌面设备的系统版本不会太多,所以来源
UA数据不会太多,最简单的实现可以使用文件存放,一次读取直接写入Redis中。 - 注意需要随机打散
UA数据,避免同一个设备系统类型的UA数据过于密集,这样可以避免触发模拟某些请求时候的风控规则。 - 需要熟悉
Lua的语法,毕竟Redis的原子指令一定离不开Lua脚本。
总结
以上所述是小编给大家介绍的使用Redis实现UA池的方案,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!
相关推荐
-
利用Lua定制Redis命令的方法详解
前言 Redis作为一个非常成功的数据库,提供了非常丰富的数据类型和命令,使用这些,我们可以轻易而高效地完成很多缓存操作,可是总有一些比较特殊的问题或需求需要解决,这时候可能就需要我们自己定制自己的 Redis 数据结构和命令. Redis命令问题 线程安全问题 我们都知道 Redis 是单线程的,可是它怎么会有 线程安全 问题呢? 我们正常理解的线程安全问题是指单进程多线程模型内部多个线程操作进程内共享内存导致的数据资源充突.而 Redis 的线程安全问题的产生,并不是来自于 Redis 服务
-
简介Lua脚本与Redis数据库的结合使用
可能你已经听说过Redis 中嵌入了脚本语言,但是你还没有亲自去尝试吧? 这个入门教程会让你学会在你的Redis 服务器上使用强大的lua语言. Hello, Lua! 我们的第一个Redis Lua 脚本仅仅返回一个字符串,而不会去与redis 以任何有意义的方式交互. 复制代码 代码如下: local msg = "Hello, world!" return msg 这是非常简单的,第一行代码定义了一个本地变量msg存储我们的信息, 第二行代码表示 从redis 服务端返回msg
-
lua读取redis数据的null判断示例代码
前言 为什么要用lua脚本操作redis数据库? 1.减少开销–减少向redis服务器的请求次数 2.原子操作–redis将lua脚本作为一个原子执行 3.可复用–其他客户端可以使用已经执行过的lua脚本 4.增加redis灵活性–lua脚本可以帮助redis做更多的事情 lua脚本本身体积小,启动速度快. 因此,从redis 2.6.0开始,redis在服务器端内置lua解释器,下面话不多说了,来开始本文的正文: 最近在配合移动端调试的时候,被抓去debug一个在清除redis缓存之后才会出现
-
Go语言中通过Lua脚本操作Redis的方法
前言 为了在我的一个基本库中降低与Redis的通讯成本,我将一系列操作封装到LUA脚本中,借助Redis提供的EVAL命令来简化操作. EVAL能够提供的特性: 可以在LUA脚本中封装若干操作,如果有多条Redis指令,封装好之后只需向Redis一次性发送所有参数即可获得结果 Redis可以保证Lua脚本运行期间不会有其他命令插入执行,提供像数据库事务一样的原子性 Redis会根据脚本的SHA值缓存脚本,已经缓存过的脚本不需要再次传输Lua代码,减少了通信成本,此外在自己代码中改变Lua脚本,执
-
详解利用redis + lua解决抢红包高并发的问题
抢红包的需求分析 抢红包的场景有点像秒杀,但是要比秒杀简单点. 因为秒杀通常要和库存相关.而抢红包则可以允许有些红包没有被抢到,因为发红包的人不会有损失,没抢完的钱再退回给发红包的人即可. 另外像小米这样的抢购也要比淘宝的要简单,也是因为像小米这样是一个公司的,如果有少量没有抢到,则下次再抢,人工修复下数据是很简单的事.而像淘宝这么多商品,要是每一个都存在着修复数据的风险,那如果出故障了则很麻烦. 基于redis的抢红包方案 下面介绍一种基于Redis的抢红包方案. 把原始的红包称为大红包,拆分
-
利用nginx+lua+redis实现反向代理方法教程
前言 最近因为工作需要,要进行IVR的重构, 我们现在系统接了三家IVR服务商, N个业务, 由于IVR这玩意一般只能外网回调, 而开发环境又不允许外网随便访问, 着实烦人. 所有我们打算重构一把, 封装多家IVR, 对业务透明, 同时回调可以针对多家IVR服务商的不同callid直接转发到当时请求的同学的 开发域名去. 而不同的IVR服务商的callid参数是不同的,有的是在url里面(call_id), 有的则是直接post的json数据(callid), 所以太扯了. 直接用lua处理下,
-
使用Redis实现UA池的方案
最近忙于业务开发.交接和游戏,加上碰上了不定时出现的犹豫期和困惑期,荒废学业了一段时间.天冷了,要重新拾起开始下阶段的学习了.之前接触到的一些数据搜索项目,涉及到请求模拟,基于反爬需要使用随机的 User Agent ,于是使用 Redis 实现了一个十分简易的 UA 池. 背景 最近的一个需求,有模拟请求的逻辑,要求每次请求的请求头中的 User Agent 要满足下面几点: 每次获取的 User Agent 是随机的. 每次获取的 User Agent (短时间内)不能重复. 每次获取的 U
-
java客户端Jedis操作Redis Sentinel 连接池的实现方法
pom.xml配置 <dependency> <groupId>org.springframework.data</groupId> <artifactId>spring-data-redis</artifactId> <version>1.0.2.RELEASE</version> </dependency> <dependency> <groupId>redis.clients<
-
java 优雅关闭线程池的方案
我们经常在项目中使用的线程池,但是是否关心过线程池的关闭呢,可能很多时候直接再项目中直接创建线程池让它一直运行当任务执行结束不在需要了也不去关闭,这其实是存在非常大的风险的,大量的线程常驻在后台对系统资源的占用是巨大的 ,甚至引发异常.所以在我们平时使用线程池时需要注意优雅的关闭,这样可以保证资源的管控. 在 Java 中和关闭线程池相关的方法主要有如下: void shutdown() List<Runnable> shutDownNow boolean awaitTermination b
-

关于Redis数据库三种持久化方案介绍
目录 一.回顾Redis 二.方案一:bgsave 三.方案二:配置文件rdb 四.方案三:aof 总结 一.回顾Redis 1.redis的特点 redis是一个内存中的数据结构存储系统.优点:内存操作速度比硬盘很快.缺点:但是内存没有办法保存数据. 2.redis提供了磁盘持久化 通过磁盘持久化功能,就可以把内存中的数据,持久化到磁盘当中去.数据就可以长时间的进行保存. 二.方案一:bgsave 1.如何操作 启动redis-cli 客户端,输入一条数据,并输入持久化命令basave就可以完
-
基于Redis验证码发送及校验方案实现
在我们的业务中,经常存在需要通过发送验证码.校验验证码来完成的一些业务逻辑,比如账号注册.找回密码.用户身份确认等. 在该类业务中,发送验证码的方式可以有各种各样,比如最常见的手机验证,最古老的邮箱验证,到现在相对少见的微信公众号.钉钉通知等:而验证码服务端存储的方式也可以各式各样,比如存储在关系型数据库中,当然也可以如本文标题所示,存储在Redis中. 既然已经预见到了各式各样的发送方式,也预见到了各式各样的存储方式,所以,虽然本文标题是基于Redis,但Redis其实只是其中的一种存储方式,
-
redis的2种持久化方案深入讲解
前言 Redis是一种高级key-value数据库.它跟memcached类似,不过数据可以持久化,而且支持的数据类型很丰富.有字符串,链表,集 合和有序集合.支持在服务器端计算集合的并,交和补集(difference)等,还支持多种排序功能.所以Redis也可以被看成是一个数据结构服务 器. Redis的所有数据都是保存在内存中,然后不定期的通过异步方式保存到磁盘上(这称为"半持久化模式"):也可以把每一次数据变化都写入到一个append only file(aof)里面(这称为&q
-
redis实现多级缓存同步方案详解
目录 前言 多级缓存数据同步 如何使用redis6客户端缓存 总结 前言 前阵子参加业务部门的技术方案评审,故事的背景是这样:业务部门上线一个专为公司高管使用的系统.这个系统技术架构形如下图 按理来说这个系统因为受众很小,可以说基本上没并发,业务也没很复杂,但就是这么一个系统,连续2次出现数据库宕机,而导致系统无法正常运行.因为这几次事故,业务部门负责人组织这次技术方案评审,主题如何避免再次出现类似这种故障? 当时有个比较资深的技术,他提出当数据库出现宕机时,可以切换到redis,redis里面
-
详解SpringBoot集成Redis来实现缓存技术方案
概述 在我们的日常项目开发过程中缓存是无处不在的,因为它可以极大的提高系统的访问速度,关于缓存的框架也种类繁多,今天主要介绍的是使用现在非常流行的NoSQL数据库(Redis)来实现我们的缓存需求. Redis简介 Redis 是一个开源(BSD许可)的,内存中的数据结构存储系统,它可以用作数据库.缓存和消息中间件,Redis 的优势包括它的速度.支持丰富的数据类型.操作原子性,以及它的通用性. 案例整合 本案例是在之前一篇SpringBoot + Mybatis + RESTful的基础上来集
-
Scala 操作Redis使用连接池工具类RedisUtil
本文介绍了Scala 操作Redis,分享给大家,具体如下: package com.zjw.util import java.util import org.apache.commons.pool2.impl.GenericObjectPoolConfig import org.apache.logging.log4j.scala.Logging import redis.clients.jedis.{Jedis, JedisPool, Response} import redis.clien
-
Redis瞬时高并发秒杀方案总结
1.Redis 丰富的数据结构(Data Structures) 字符串(String) Redis字符串能包含任意类型的数据;: 一个字符串类型的值最多能存储512M字节的内容: 利用INCR命令簇(INCR, DECR, INCRBY)来把字符串当作原子计数器使用: 使用APPEND命令在字符串后添加内容. 列表(List) Redis列表是简单的字符串列表,按照插入顺序排序: 你可以添加一个元素到列表的头部(左边:LPUSH)或者尾部(右边:RPUSH): 一个列表最多可以包含232-1个