python机器学习理论与实战(六)支持向量机
上节基本完成了SVM的理论推倒,寻找最大化间隔的目标最终转换成求解拉格朗日乘子变量alpha的求解问题,求出了alpha即可求解出SVM的权重W,有了权重也就有了最大间隔距离,但是其实上节我们有个假设:就是训练集是线性可分的,这样求出的alpha在[0,infinite]。但是如果数据不是线性可分的呢?此时我们就要允许部分的样本可以越过分类器,这样优化的目标函数就可以不变,只要引入松弛变量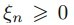 即可,它表示错分类样本点的代价,分类正确时它等于0,当分类错误时
即可,它表示错分类样本点的代价,分类正确时它等于0,当分类错误时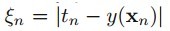 ,其中Tn表示样本的真实标签-1或者1,回顾上节中,我们把支持向量到分类器的距离固定为1,因此两类的支持向量间的距离肯定大于1的,当分类错误时
,其中Tn表示样本的真实标签-1或者1,回顾上节中,我们把支持向量到分类器的距离固定为1,因此两类的支持向量间的距离肯定大于1的,当分类错误时 肯定也大于1,如(图五)所示(这里公式和图标序号都接上一节)。
肯定也大于1,如(图五)所示(这里公式和图标序号都接上一节)。

(图五)
这样有了错分类的代价,我们把上节(公式四)的目标函数上添加上这一项错分类代价,得到如(公式八)的形式:
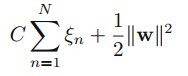
(公式八)
重复上节的拉格朗日乘子法步骤,得到(公式九):

(公式九)
多了一个Un乘子,当然我们的工作就是继续求解此目标函数,继续重复上节的步骤,求导得到(公式十):

(公式十)
又因为alpha大于0,而且Un大于0,所以0<alpha<C,为了解释的清晰一些,我们把(公式九)的KKT条件也发出来(上节中的第三类优化问题),注意Un是大于等于0:

推导到现在,优化函数的形式基本没变,只是多了一项错分类的价值,但是多了一个条件,0<alpha<C,C是一个常数,它的作用就是在允许有错误分类的情况下,控制最大化间距,它太大了会导致过拟合,太小了会导致欠拟合。接下来的步骤貌似大家都应该知道了,多了一个C常量的限制条件,然后继续用SMO算法优化求解二次规划,但是我想继续把核函数也一次说了,如果样本线性不可分,引入核函数后,把样本映射到高维空间就可以线性可分,如(图六)所示的线性不可分的样本:

(图六)
在(图六)中,现有的样本是很明显线性不可分,但是加入我们利用现有的样本X之间作些不同的运算,如(图六)右边所示的样子,而让f作为新的样本(或者说新的特征)是不是更好些?现在把X已经投射到高维度上去了,但是f我们不知道,此时核函数就该上场了,以高斯核函数为例,在(图七)中选几个样本点作为基准点,来利用核函数计算f,如(图七)所示:

(图七)
这样就有了f,而核函数此时相当于对样本的X和基准点一个度量,做权重衰减,形成依赖于x的新的特征f,把f放在上面说的SVM中继续求解alpha,然后得出权重就行了,原理很简单吧,为了显得有点学术味道,把核函数也做个样子加入目标函数中去吧,如(公式十一)所示:

(公式十一)
其中K(Xn,Xm)是核函数,和上面目标函数比没有多大的变化,用SMO优化求解就行了,代码如下:
def smoPK(dataMatIn, classLabels, C, toler, maxIter): #full Platt SMO
oS = optStruct(mat(dataMatIn),mat(classLabels).transpose(),C,toler)
iter = 0
entireSet = True; alphaPairsChanged = 0
while (iter < maxIter) and ((alphaPairsChanged > 0) or (entireSet)):
alphaPairsChanged = 0
if entireSet: #go over all
for i in range(oS.m):
alphaPairsChanged += innerL(i,oS)
print "fullSet, iter: %d i:%d, pairs changed %d" % (iter,i,alphaPairsChanged)
iter += 1
else:#go over non-bound (railed) alphas
nonBoundIs = nonzero((oS.alphas.A > 0) * (oS.alphas.A < C))[0]
for i in nonBoundIs:
alphaPairsChanged += innerL(i,oS)
print "non-bound, iter: %d i:%d, pairs changed %d" % (iter,i,alphaPairsChanged)
iter += 1
if entireSet: entireSet = False #toggle entire set loop
elif (alphaPairsChanged == 0): entireSet = True
print "iteration number: %d" % iter
return oS.b,oS.alphas
下面演示一个小例子,手写识别。
(1)收集数据:提供文本文件
(2)准备数据:基于二值图像构造向量
(3)分析数据:对图像向量进行目测
(4)训练算法:采用两种不同的核函数,并对径向基函数采用不同的设置来运行SMO算法。
(5)测试算法:编写一个函数来测试不同的核函数,并计算错误率
(6)使用算法:一个图像识别的完整应用还需要一些图像处理的只是,此demo略。
完整代码如下:
from numpy import *
from time import sleep
def loadDataSet(fileName):
dataMat = []; labelMat = []
fr = open(fileName)
for line in fr.readlines():
lineArr = line.strip().split('\t')
dataMat.append([float(lineArr[0]), float(lineArr[1])])
labelMat.append(float(lineArr[2]))
return dataMat,labelMat
def selectJrand(i,m):
j=i #we want to select any J not equal to i
while (j==i):
j = int(random.uniform(0,m))
return j
def clipAlpha(aj,H,L):
if aj > H:
aj = H
if L > aj:
aj = L
return aj
def smoSimple(dataMatIn, classLabels, C, toler, maxIter):
dataMatrix = mat(dataMatIn); labelMat = mat(classLabels).transpose()
b = 0; m,n = shape(dataMatrix)
alphas = mat(zeros((m,1)))
iter = 0
while (iter < maxIter):
alphaPairsChanged = 0
for i in range(m):
fXi = float(multiply(alphas,labelMat).T*(dataMatrix*dataMatrix[i,:].T)) + b
Ei = fXi - float(labelMat[i])#if checks if an example violates KKT conditions
if ((labelMat[i]*Ei < -toler) and (alphas[i] < C)) or ((labelMat[i]*Ei > toler) and (alphas[i] > 0)):
j = selectJrand(i,m)
fXj = float(multiply(alphas,labelMat).T*(dataMatrix*dataMatrix[j,:].T)) + b
Ej = fXj - float(labelMat[j])
alphaIold = alphas[i].copy(); alphaJold = alphas[j].copy();
if (labelMat[i] != labelMat[j]):
L = max(0, alphas[j] - alphas[i])
H = min(C, C + alphas[j] - alphas[i])
else:
L = max(0, alphas[j] + alphas[i] - C)
H = min(C, alphas[j] + alphas[i])
if L==H: print "L==H"; continue
eta = 2.0 * dataMatrix[i,:]*dataMatrix[j,:].T - dataMatrix[i,:]*dataMatrix[i,:].T - dataMatrix[j,:]*dataMatrix[j,:].T
if eta >= 0: print "eta>=0"; continue
alphas[j] -= labelMat[j]*(Ei - Ej)/eta
alphas[j] = clipAlpha(alphas[j],H,L)
if (abs(alphas[j] - alphaJold) < 0.00001): print "j not moving enough"; continue
alphas[i] += labelMat[j]*labelMat[i]*(alphaJold - alphas[j])#update i by the same amount as j
#the update is in the oppostie direction
b1 = b - Ei- labelMat[i]*(alphas[i]-alphaIold)*dataMatrix[i,:]*dataMatrix[i,:].T - labelMat[j]*(alphas[j]-alphaJold)*dataMatrix[i,:]*dataMatrix[j,:].T
b2 = b - Ej- labelMat[i]*(alphas[i]-alphaIold)*dataMatrix[i,:]*dataMatrix[j,:].T - labelMat[j]*(alphas[j]-alphaJold)*dataMatrix[j,:]*dataMatrix[j,:].T
if (0 < alphas[i]) and (C > alphas[i]): b = b1
elif (0 < alphas[j]) and (C > alphas[j]): b = b2
else: b = (b1 + b2)/2.0
alphaPairsChanged += 1
print "iter: %d i:%d, pairs changed %d" % (iter,i,alphaPairsChanged)
if (alphaPairsChanged == 0): iter += 1
else: iter = 0
print "iteration number: %d" % iter
return b,alphas
def kernelTrans(X, A, kTup): #calc the kernel or transform data to a higher dimensional space
m,n = shape(X)
K = mat(zeros((m,1)))
if kTup[0]=='lin': K = X * A.T #linear kernel
elif kTup[0]=='rbf':
for j in range(m):
deltaRow = X[j,:] - A
K[j] = deltaRow*deltaRow.T
K = exp(K/(-1*kTup[1]**2)) #divide in NumPy is element-wise not matrix like Matlab
else: raise NameError('Houston We Have a Problem -- \
That Kernel is not recognized')
return K
class optStruct:
def __init__(self,dataMatIn, classLabels, C, toler, kTup): # Initialize the structure with the parameters
self.X = dataMatIn
self.labelMat = classLabels
self.C = C
self.tol = toler
self.m = shape(dataMatIn)[0]
self.alphas = mat(zeros((self.m,1)))
self.b = 0
self.eCache = mat(zeros((self.m,2))) #first column is valid flag
self.K = mat(zeros((self.m,self.m)))
for i in range(self.m):
self.K[:,i] = kernelTrans(self.X, self.X[i,:], kTup)
def calcEk(oS, k):
fXk = float(multiply(oS.alphas,oS.labelMat).T*oS.K[:,k] + oS.b)
Ek = fXk - float(oS.labelMat[k])
return Ek
def selectJ(i, oS, Ei): #this is the second choice -heurstic, and calcs Ej
maxK = -1; maxDeltaE = 0; Ej = 0
oS.eCache[i] = [1,Ei] #set valid #choose the alpha that gives the maximum delta E
validEcacheList = nonzero(oS.eCache[:,0].A)[0]
if (len(validEcacheList)) > 1:
for k in validEcacheList: #loop through valid Ecache values and find the one that maximizes delta E
if k == i: continue #don't calc for i, waste of time
Ek = calcEk(oS, k)
deltaE = abs(Ei - Ek)
if (deltaE > maxDeltaE):
maxK = k; maxDeltaE = deltaE; Ej = Ek
return maxK, Ej
else: #in this case (first time around) we don't have any valid eCache values
j = selectJrand(i, oS.m)
Ej = calcEk(oS, j)
return j, Ej
def updateEk(oS, k):#after any alpha has changed update the new value in the cache
Ek = calcEk(oS, k)
oS.eCache[k] = [1,Ek]
def innerL(i, oS):
Ei = calcEk(oS, i)
if ((oS.labelMat[i]*Ei < -oS.tol) and (oS.alphas[i] < oS.C)) or ((oS.labelMat[i]*Ei > oS.tol) and (oS.alphas[i] > 0)):
j,Ej = selectJ(i, oS, Ei) #this has been changed from selectJrand
alphaIold = oS.alphas[i].copy(); alphaJold = oS.alphas[j].copy();
if (oS.labelMat[i] != oS.labelMat[j]):
L = max(0, oS.alphas[j] - oS.alphas[i])
H = min(oS.C, oS.C + oS.alphas[j] - oS.alphas[i])
else:
L = max(0, oS.alphas[j] + oS.alphas[i] - oS.C)
H = min(oS.C, oS.alphas[j] + oS.alphas[i])
if L==H: print "L==H"; return 0
eta = 2.0 * oS.K[i,j] - oS.K[i,i] - oS.K[j,j] #changed for kernel
if eta >= 0: print "eta>=0"; return 0
oS.alphas[j] -= oS.labelMat[j]*(Ei - Ej)/eta
oS.alphas[j] = clipAlpha(oS.alphas[j],H,L)
updateEk(oS, j) #added this for the Ecache
if (abs(oS.alphas[j] - alphaJold) < 0.00001): print "j not moving enough"; return 0
oS.alphas[i] += oS.labelMat[j]*oS.labelMat[i]*(alphaJold - oS.alphas[j])#update i by the same amount as j
updateEk(oS, i) #added this for the Ecache #the update is in the oppostie direction
b1 = oS.b - Ei- oS.labelMat[i]*(oS.alphas[i]-alphaIold)*oS.K[i,i] - oS.labelMat[j]*(oS.alphas[j]-alphaJold)*oS.K[i,j]
b2 = oS.b - Ej- oS.labelMat[i]*(oS.alphas[i]-alphaIold)*oS.K[i,j]- oS.labelMat[j]*(oS.alphas[j]-alphaJold)*oS.K[j,j]
if (0 < oS.alphas[i]) and (oS.C > oS.alphas[i]): oS.b = b1
elif (0 < oS.alphas[j]) and (oS.C > oS.alphas[j]): oS.b = b2
else: oS.b = (b1 + b2)/2.0
return 1
else: return 0
def smoP(dataMatIn, classLabels, C, toler, maxIter,kTup=('lin', 0)): #full Platt SMO
oS = optStruct(mat(dataMatIn),mat(classLabels).transpose(),C,toler, kTup)
iter = 0
entireSet = True; alphaPairsChanged = 0
while (iter < maxIter) and ((alphaPairsChanged > 0) or (entireSet)):
alphaPairsChanged = 0
if entireSet: #go over all
for i in range(oS.m):
alphaPairsChanged += innerL(i,oS)
print "fullSet, iter: %d i:%d, pairs changed %d" % (iter,i,alphaPairsChanged)
iter += 1
else:#go over non-bound (railed) alphas
nonBoundIs = nonzero((oS.alphas.A > 0) * (oS.alphas.A < C))[0]
for i in nonBoundIs:
alphaPairsChanged += innerL(i,oS)
print "non-bound, iter: %d i:%d, pairs changed %d" % (iter,i,alphaPairsChanged)
iter += 1
if entireSet: entireSet = False #toggle entire set loop
elif (alphaPairsChanged == 0): entireSet = True
print "iteration number: %d" % iter
return oS.b,oS.alphas
def calcWs(alphas,dataArr,classLabels):
X = mat(dataArr); labelMat = mat(classLabels).transpose()
m,n = shape(X)
w = zeros((n,1))
for i in range(m):
w += multiply(alphas[i]*labelMat[i],X[i,:].T)
return w
def testRbf(k1=1.3):
dataArr,labelArr = loadDataSet('testSetRBF.txt')
b,alphas = smoP(dataArr, labelArr, 200, 0.0001, 10000, ('rbf', k1)) #C=200 important
datMat=mat(dataArr); labelMat = mat(labelArr).transpose()
svInd=nonzero(alphas.A>0)[0]
sVs=datMat[svInd] #get matrix of only support vectors
labelSV = labelMat[svInd];
print "there are %d Support Vectors" % shape(sVs)[0]
m,n = shape(datMat)
errorCount = 0
for i in range(m):
kernelEval = kernelTrans(sVs,datMat[i,:],('rbf', k1))
predict=kernelEval.T * multiply(labelSV,alphas[svInd]) + b
if sign(predict)!=sign(labelArr[i]): errorCount += 1
print "the training error rate is: %f" % (float(errorCount)/m)
dataArr,labelArr = loadDataSet('testSetRBF2.txt')
errorCount = 0
datMat=mat(dataArr); labelMat = mat(labelArr).transpose()
m,n = shape(datMat)
for i in range(m):
kernelEval = kernelTrans(sVs,datMat[i,:],('rbf', k1))
predict=kernelEval.T * multiply(labelSV,alphas[svInd]) + b
if sign(predict)!=sign(labelArr[i]): errorCount += 1
print "the test error rate is: %f" % (float(errorCount)/m)
def img2vector(filename):
returnVect = zeros((1,1024))
fr = open(filename)
for i in range(32):
lineStr = fr.readline()
for j in range(32):
returnVect[0,32*i+j] = int(lineStr[j])
return returnVect
def loadImages(dirName):
from os import listdir
hwLabels = []
trainingFileList = listdir(dirName) #load the training set
m = len(trainingFileList)
trainingMat = zeros((m,1024))
for i in range(m):
fileNameStr = trainingFileList[i]
fileStr = fileNameStr.split('.')[0] #take off .txt
classNumStr = int(fileStr.split('_')[0])
if classNumStr == 9: hwLabels.append(-1)
else: hwLabels.append(1)
trainingMat[i,:] = img2vector('%s/%s' % (dirName, fileNameStr))
return trainingMat, hwLabels
def testDigits(kTup=('rbf', 10)):
dataArr,labelArr = loadImages('trainingDigits')
b,alphas = smoP(dataArr, labelArr, 200, 0.0001, 10000, kTup)
datMat=mat(dataArr); labelMat = mat(labelArr).transpose()
svInd=nonzero(alphas.A>0)[0]
sVs=datMat[svInd]
labelSV = labelMat[svInd];
print "there are %d Support Vectors" % shape(sVs)[0]
m,n = shape(datMat)
errorCount = 0
for i in range(m):
kernelEval = kernelTrans(sVs,datMat[i,:],kTup)
predict=kernelEval.T * multiply(labelSV,alphas[svInd]) + b
if sign(predict)!=sign(labelArr[i]): errorCount += 1
print "the training error rate is: %f" % (float(errorCount)/m)
dataArr,labelArr = loadImages('testDigits')
errorCount = 0
datMat=mat(dataArr); labelMat = mat(labelArr).transpose()
m,n = shape(datMat)
for i in range(m):
kernelEval = kernelTrans(sVs,datMat[i,:],kTup)
predict=kernelEval.T * multiply(labelSV,alphas[svInd]) + b
if sign(predict)!=sign(labelArr[i]): errorCount += 1
print "the test error rate is: %f" % (float(errorCount)/m)
'''''#######********************************
Non-Kernel VErsions below
'''#######********************************
class optStructK:
def __init__(self,dataMatIn, classLabels, C, toler): # Initialize the structure with the parameters
self.X = dataMatIn
self.labelMat = classLabels
self.C = C
self.tol = toler
self.m = shape(dataMatIn)[0]
self.alphas = mat(zeros((self.m,1)))
self.b = 0
self.eCache = mat(zeros((self.m,2))) #first column is valid flag
def calcEkK(oS, k):
fXk = float(multiply(oS.alphas,oS.labelMat).T*(oS.X*oS.X[k,:].T)) + oS.b
Ek = fXk - float(oS.labelMat[k])
return Ek
def selectJK(i, oS, Ei): #this is the second choice -heurstic, and calcs Ej
maxK = -1; maxDeltaE = 0; Ej = 0
oS.eCache[i] = [1,Ei] #set valid #choose the alpha that gives the maximum delta E
validEcacheList = nonzero(oS.eCache[:,0].A)[0]
if (len(validEcacheList)) > 1:
for k in validEcacheList: #loop through valid Ecache values and find the one that maximizes delta E
if k == i: continue #don't calc for i, waste of time
Ek = calcEk(oS, k)
deltaE = abs(Ei - Ek)
if (deltaE > maxDeltaE):
maxK = k; maxDeltaE = deltaE; Ej = Ek
return maxK, Ej
else: #in this case (first time around) we don't have any valid eCache values
j = selectJrand(i, oS.m)
Ej = calcEk(oS, j)
return j, Ej
def updateEkK(oS, k):#after any alpha has changed update the new value in the cache
Ek = calcEk(oS, k)
oS.eCache[k] = [1,Ek]
def innerLK(i, oS):
Ei = calcEk(oS, i)
if ((oS.labelMat[i]*Ei < -oS.tol) and (oS.alphas[i] < oS.C)) or ((oS.labelMat[i]*Ei > oS.tol) and (oS.alphas[i] > 0)):
j,Ej = selectJ(i, oS, Ei) #this has been changed from selectJrand
alphaIold = oS.alphas[i].copy(); alphaJold = oS.alphas[j].copy();
if (oS.labelMat[i] != oS.labelMat[j]):
L = max(0, oS.alphas[j] - oS.alphas[i])
H = min(oS.C, oS.C + oS.alphas[j] - oS.alphas[i])
else:
L = max(0, oS.alphas[j] + oS.alphas[i] - oS.C)
H = min(oS.C, oS.alphas[j] + oS.alphas[i])
if L==H: print "L==H"; return 0
eta = 2.0 * oS.X[i,:]*oS.X[j,:].T - oS.X[i,:]*oS.X[i,:].T - oS.X[j,:]*oS.X[j,:].T
if eta >= 0: print "eta>=0"; return 0
oS.alphas[j] -= oS.labelMat[j]*(Ei - Ej)/eta
oS.alphas[j] = clipAlpha(oS.alphas[j],H,L)
updateEk(oS, j) #added this for the Ecache
if (abs(oS.alphas[j] - alphaJold) < 0.00001): print "j not moving enough"; return 0
oS.alphas[i] += oS.labelMat[j]*oS.labelMat[i]*(alphaJold - oS.alphas[j])#update i by the same amount as j
updateEk(oS, i) #added this for the Ecache #the update is in the oppostie direction
b1 = oS.b - Ei- oS.labelMat[i]*(oS.alphas[i]-alphaIold)*oS.X[i,:]*oS.X[i,:].T - oS.labelMat[j]*(oS.alphas[j]-alphaJold)*oS.X[i,:]*oS.X[j,:].T
b2 = oS.b - Ej- oS.labelMat[i]*(oS.alphas[i]-alphaIold)*oS.X[i,:]*oS.X[j,:].T - oS.labelMat[j]*(oS.alphas[j]-alphaJold)*oS.X[j,:]*oS.X[j,:].T
if (0 < oS.alphas[i]) and (oS.C > oS.alphas[i]): oS.b = b1
elif (0 < oS.alphas[j]) and (oS.C > oS.alphas[j]): oS.b = b2
else: oS.b = (b1 + b2)/2.0
return 1
else: return 0
def smoPK(dataMatIn, classLabels, C, toler, maxIter): #full Platt SMO
oS = optStruct(mat(dataMatIn),mat(classLabels).transpose(),C,toler)
iter = 0
entireSet = True; alphaPairsChanged = 0
while (iter < maxIter) and ((alphaPairsChanged > 0) or (entireSet)):
alphaPairsChanged = 0
if entireSet: #go over all
for i in range(oS.m):
alphaPairsChanged += innerL(i,oS)
print "fullSet, iter: %d i:%d, pairs changed %d" % (iter,i,alphaPairsChanged)
iter += 1
else:#go over non-bound (railed) alphas
nonBoundIs = nonzero((oS.alphas.A > 0) * (oS.alphas.A < C))[0]
for i in nonBoundIs:
alphaPairsChanged += innerL(i,oS)
print "non-bound, iter: %d i:%d, pairs changed %d" % (iter,i,alphaPairsChanged)
iter += 1
if entireSet: entireSet = False #toggle entire set loop
elif (alphaPairsChanged == 0): entireSet = True
print "iteration number: %d" % iter
return oS.b,oS.alphas
运行结果如(图八)所示:

(图八)
上面代码有兴趣的可以读读,用的话,建议使用libsvm。
参考文献:
[1]machine learning in action. PeterHarrington
[2] pattern recognition and machinelearning. Christopher M. Bishop
[3]machine learning.Andrew Ng
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
您可能感兴趣的文章:
- python机器学习理论与实战(五)支持向量机
- Python实现KNN邻近算法
- Python KNN分类算法学习
- python实现kMeans算法
- python机器学习实战之最近邻kNN分类器
- Python代码实现KNN算法
- 使用python实现knn算法
- python实现kNN算法
- python机器学习理论与实战(一)K近邻法
相关推荐
-
python机器学习理论与实战(五)支持向量机
做机器学习的一定对支持向量机(support vector machine-SVM)颇为熟悉,因为在深度学习出现之前,SVM一直霸占着机器学习老大哥的位子.他的理论很优美,各种变种改进版本也很多,比如latent-SVM, structural-SVM等.这节先来看看SVM的理论吧,在(图一)中A图表示有两类的数据集,图B,C,D都提供了一个线性分类器来对数据进行分类?但是哪个效果好一些? (图一) 可能对这个数据集来说,三个的分类器都一样足够好了吧,但是其实不然,这个只是训练集,现实测试的样本
-
python机器学习理论与实战(一)K近邻法
机器学习分两大类,有监督学习(supervised learning)和无监督学习(unsupervised learning).有监督学习又可分两类:分类(classification.)和回归(regression),分类的任务就是把一个样本划为某个已知类别,每个样本的类别信息在训练时需要给定,比如人脸识别.行为识别.目标检测等都属于分类.回归的任务则是预测一个数值,比如给定房屋市场的数据(面积,位置等样本信息)来预测房价走势.而无监督学习也可以成两类:聚类(clustering)和密度估计
-
Python代码实现KNN算法
kNN算法是k-近邻算法的简称,主要用来进行分类实践,主要思路如下: 1.存在一个训练数据集,每个数据都有对应的标签,也就是说,我们知道样本集中每一数据和他对应的类别. 2.当输入一个新数据进行类别或标签判定时,将新数据的每个特征值与训练数据集中的每个数据进行比较,计算其到训练数据集中每个点的距离(下列代码实现使用的是欧式距离). 3.然后提取k个与新数据最接近的训练数据点所对应的标签或类别. 4.出现次数最多的标签或类别,记为当前预测新数据的标签或类别. 欧式距离公式为: distance=
-

使用python实现knn算法
本文实例为大家分享了python实现knn算法的具体代码,供大家参考,具体内容如下 knn算法描述 对需要分类的点依次执行以下操作: 1.计算已知类别数据集中每个点与该点之间的距离 2.按照距离递增顺序排序 3.选取与该点距离最近的k个点 4.确定前k个点所在类别出现的频率 5.返回前k个点出现频率最高的类别作为该点的预测分类 knn算法实现 数据处理 #从文件中读取数据,返回的数据和分类均为二维数组 def loadDataSet(filename): dataSet = [] labels
-
Python实现KNN邻近算法
简介 邻近算法,或者说K最近邻(kNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一.所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表. kNN算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性.该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别. kNN方法在类别决策时,只与极少量的相邻样本有关.由于kNN
-
python实现kNN算法
kNN(k-nearest neighbor)是一种基本的分类与回归的算法.这里我们先只讨论分类中的kNN算法. k邻近算法的输入为实例的特征向量,对对应于特征空间中的点:输出为实例的类别,可以取多类,k近邻法是建设给定一个训练数据集,其中的实例类别已定,分类时,对于新的实例,根据其k个最邻近的训练实例的类别,通过多数表决等方式进行预测.所以可以说,k近邻法不具有显示的学习过程.k临近算法实际上是利用训练数据集对特征向量空间进行划分,并作为其分类的"模型" k值的选择,距离的度量和分类
-
python实现kMeans算法
聚类是一种无监督的学习,将相似的对象放到同一簇中,有点像是全自动分类,簇内的对象越相似,簇间的对象差别越大,则聚类效果越好. 1.k均值聚类算法 k均值聚类将数据分为k个簇,每个簇通过其质心,即簇中所有点的中心来描述.首先随机确定k个初始点作为质心,然后将数据集分配到距离最近的簇中.然后将每个簇的质心更新为所有数据集的平均值.然后再进行第二次划分数据集,直到聚类结果不再变化为止. 伪代码为 随机创建k个簇质心 当任意一个点的簇分配发生改变时: 对数据集中的每个数据点: 对
-
python机器学习实战之最近邻kNN分类器
K近邻法是有监督学习方法,原理很简单,假设我们有一堆分好类的样本数据,分好类表示每个样本都一个对应的已知类标签,当来一个测试样本要我们判断它的类别是, 就分别计算到每个样本的距离,然后选取离测试样本最近的前K个样本的标签累计投票, 得票数最多的那个标签就为测试样本的标签. 源代码详解: #-*- coding:utf-8 -*- #!/usr/bin/python # 测试代码 约会数据分类 import KNN KNN.datingClassTest1() 标签为字符串 KNN.datingC
-
Python KNN分类算法学习
本文实例为大家分享了Python KNN分类算法的具体代码,供大家参考,具体内容如下 1.KNN分类算法 KNN分类算法(K-Nearest-Neighbors Classification),又叫K近邻算法,是一个概念极其简单,而分类效果又很优秀的分类算法. 他的核心思想就是,要确定测试样本属于哪一类,就寻找所有训练样本中与该测试样本"距离"最近的前K个样本,然后看这K个样本大部分属于哪一类,那么就认为这个测试样本也属于哪一类.简单的说就是让最相似的K个样本来投票决定. 这里所说的距
-
python机器学习理论与实战(六)支持向量机
上节基本完成了SVM的理论推倒,寻找最大化间隔的目标最终转换成求解拉格朗日乘子变量alpha的求解问题,求出了alpha即可求解出SVM的权重W,有了权重也就有了最大间隔距离,但是其实上节我们有个假设:就是训练集是线性可分的,这样求出的alpha在[0,infinite].但是如果数据不是线性可分的呢?此时我们就要允许部分的样本可以越过分类器,这样优化的目标函数就可以不变,只要引入松弛变量即可,它表示错分类样本点的代价,分类正确时它等于0,当分类错误时,其中Tn表示样本的真实标签-1或者1,回顾
-
python机器学习理论与实战(二)决策树
决策树也是有监督机器学习方法. 电影<无耻混蛋>里有一幕游戏,在德军小酒馆里有几个人在玩20问题游戏,游戏规则是一个设迷者在纸牌中抽出一个目标(可以是人,也可以是物),而猜谜者可以提问题,设迷者只能回答是或者不是,在几个问题(最多二十个问题)之后,猜谜者通过逐步缩小范围就准确的找到了答案.这就类似于决策树的工作原理.(图一)是一个判断邮件类别的工作方式,可以看出判别方法很简单,基本都是阈值判断,关键是如何构建决策树,也就是如何训练一个决策树. (图一) 构建决策树的伪代码如下: Check i
-
python机器学习理论与实战(四)逻辑回归
从这节算是开始进入"正规"的机器学习了吧,之所以"正规"因为它开始要建立价值函数(cost function),接着优化价值函数求出权重,然后测试验证.这整套的流程是机器学习必经环节.今天要学习的话题是逻辑回归,逻辑回归也是一种有监督学习方法(supervised machine learning).逻辑回归一般用来做预测,也可以用来做分类,预测是某个类别^.^!线性回归想比大家都不陌生了,y=kx+b,给定一堆数据点,拟合出k和b的值就行了,下次给定X时,就可以计
-
python接口自动化框架实战
python接口测试的原理,就不解释了,百度一大堆. 先看目录,可能这个框架比较简单,但是麻雀虽小五脏俱全. 各个文件夹下的文件如下: 一.理清思路 我这个自动化框架要实现什么 1.从excel里面提取测试用例 2.测试报告的输出,并且测试报告得包括执行的测试用例的数量.成功的数量.失败的数量以及哪条成功了,失败的是哪一个,失败的原因是什么:测试结果的总体情况通过图表来表示. 3.测试报告用什么形式输出,excel,还是html,还是其他的,这里我选择了excel 4.配置文件需要配置什么东西
-
Python爬虫框架Scrapy实战之批量抓取招聘信息
网络爬虫抓取特定网站网页的html数据,但是一个网站有上千上万条数据,我们不可能知道网站网页的url地址,所以,要有个技巧去抓取网站的所有html页面.Scrapy是纯Python实现的爬虫框架,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便- Scrapy 使用wisted这个异步网络库来处理网络通讯,架构清晰,并且包含了各种中间件接口,可以灵活的完成各种需求.整体架构如下图所示: 绿线是数据流向,首先从初始URL 开始,Scheduler 会将其
-
详解Python Celery和RabbitMQ实战教程
前言 Celery是一个异步任务队列.它可以用于需要异步运行的任何内容.RabbitMQ是Celery广泛使用的消息代理.在本这篇文章中,我将使用RabbitMQ来介绍Celery的基本概念,然后为一个小型演示项目设置Celery .最后,设置一个Celery Web控制台来监视我的任务 基本概念 来!看图说话: Broker Broker(RabbitMQ)负责创建任务队列,根据一些路由规则将任务分派到任务队列,然后将任务从任务队列交付给worker Consumer (Celery Wo
-
Python+Appium自动化测试的实战
目录 一.环境准备 二.真机测试 一.环境准备 1.脚本语言:Python3.x IDE:安装Pycharm 2.安装Java JDK .Android SDK 3.adb环境,path添加E:\Software\Android_SDK\platform-tools 4.安装Appium for windows,官网地址http://appium.io/ 点击下载按钮会到GitHub的下载页面,选择对应平台下载 安装完成后,启动Appium,host和port默认的即可,然后设置Android
-
python动态网站爬虫实战(requests+xpath+demjson+redis)
目录 前言 一.主要思路 1.观察网站 2.编写爬虫代码 二.爬虫实战 1.登陆获取cookie 三.总结 前言 之前简单学习过python爬虫基础知识,并且用过scrapy框架爬取数据,都是直接能用xpath定位到目标区域然后爬取.可这次碰到的需求是爬取一个用asp.net编写的教育网站并且将教学ppt一次性爬取下来,由于该网站部分内容渲染采用了js,所以比较难用xpath直接定位,同时发起下载ppt的请求比较难找. 经过琢磨和尝试后爬取成功,记录整个爬取思路供自己和大家学习.文章比较详细,对