spring cloud 分布式链路追踪的方法
一篇讲了微服务之间的调用spring cloud eureka 微服务之间的调用
微服务之间进行调用 那么如果我负责一个模块 别人负责另一个模块 我调用了他的方法 测试那边却报了错 那是我的问题还是他的问题
这个时候大家应该就能想到日志可以解决这个问题
如何使用日志呢 先在配置文件中加
logging: path: D:\logs\poppy-mall #日志的存放地址 最好再加个项目名的文件夹 可以更容易的区分 level: org.poppy.mall: info #日志的级别 org.poppy.mall 是你的包名
然后就可以在你想添加日志的类中写上
public static Logger logger =LoggerFactory.getLogger(类名.class);
之后就在你想加日志的地方加上 logger.info("日志信息")
运行后会自动在你写的日志存放的地址加入日志文件 (它会自动生成文件夹)
查看一下内容


是这个样子的 这样就解决了排错的问题
那么新问题又来了 如果我调用了几万次这个方法 我怎么才能找得到我这个服务调用的到底是那次请求的另一个微服务?
这时候就用到了分布式链路追踪
先引入依赖 想要追踪那个项目 都要在里面加入这个依赖
compile group: 'org.springframework.cloud', name: 'spring-cloud-starter-sleuth'
之后再运行 查看日志 发现是这个样子
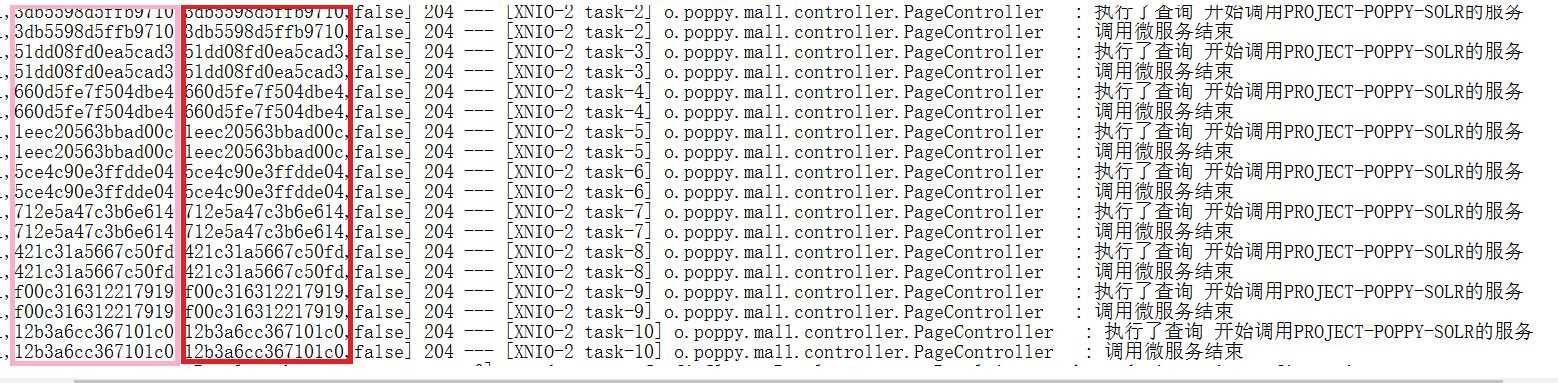

可以发现多出来一串编码 它有什么用呢
粉色框的编码 它代表的是在同一次请求中 编码就相同 红色框的代码 代表的是在同一服务中 它会相同
这样就解决了我们的问题 我们只要找到报错的一次请求 复制粉色框内的编码 到另一个服务的日志中进行查找 就能找到
这就是分布式链路跟踪
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

浅谈Spring-cloud 之 sleuth 服务链路跟踪
这篇文章主要讲述服务追踪组件zipkin,Spring Cloud Sleuth集成了zipkin组件. 一.简介 Add sleuth to the classpath of a Spring Boot application (see below for Maven and Gradle examples), and you will see the correlation data being collected in logs, as long as you are logging re
-
spring cloud 分布式链路追踪的方法
一篇讲了微服务之间的调用spring cloud eureka 微服务之间的调用 微服务之间进行调用 那么如果我负责一个模块 别人负责另一个模块 我调用了他的方法 测试那边却报了错 那是我的问题还是他的问题 这个时候大家应该就能想到日志可以解决这个问题 如何使用日志呢 先在配置文件中加 logging: path: D:\logs\poppy-mall #日志的存放地址 最好再加个项目名的文件夹 可以更容易的区分 level: org.poppy.mall: info #日志的级别 org.po
-
详解spring cloud分布式整合zipkin的链路跟踪
为什么使用zipkin? 上篇主要写了:spring cloud分布式日志链路跟踪 从上篇中可以看出服务之间的调用,假设现在有十几台服务,那么在查找日志的时候比较繁琐.复杂,而且在查看调用的时候也会像蜘蛛网一样,量太大. 这时候zipkin可以把链路调用整个过程给升级起来,只需要到一个地方去查找,就可以知道哪一步出错. zipkin也分为服务器和客户端,服务器就是zipkin,微服务就是客户端. 首先,建立服务器zipkin 在此服务build.gradle加上zipkin的依赖: compil
-
SpringCloud分布式链路跟踪的方法
注:作者使用IDEA + Gradle 注:需要有一定的java SpringBoot and SSM+Springcloud基础 程序测试错误追责 我举个例子,我现在要做一个电商项目,项目里面有一个购买模块,那我这边可能要执行一个代码,比如减库存之类的东西,那我两个服务不就是要相互调用嘛,我自身是一个服务,我现在要调用减库存这个服务: 你调用它,你知道它一定能执行成功吗?肯定是不一定: 比如说,我现在要执行一个减库存的代码,我调用这个方法会进行库存的一个更改,这个库存减少成功还好,万一要是失败
-
详解spring cloud分布式关于熔断器
spring cloud分布式中,熔断器就是断路器,其实都是一个意思. 为什么要使用熔断器呢? 在分布式中,我们会根据业务或功能将项目拆分为多个服务单元,各个服务单元之间通过服务注册和订阅的方式相互依赖和调用功能,随着项目和业务的不断拓展,服务单元数量也逐渐增多,相互之间的依赖关系也越来越复杂,这时候,可能会某个服务单元出现问题或网络原因依赖调用出错或延迟,此时如果调用该依赖的请求不断增加,那么要调用该服务的服务将都会等待或者出现故障,如果后续连锁反应越来越多,Servlet容器的线程资源会被消
-
Go 分布式链路追踪实现原理解析
目录 为什么需要分布式链路追踪系统 微服务架构给运维.排障带来新挑战 分布式链路追踪系统如何帮助我们 分布式链路追踪系统架构概览 核心概念 一般架构 协议标准和开源实现 应用侧调用链跟踪实现方案概览 应用侧核心任务 基于 OTEL 库实现调用拦截 HttpServer Handler 生成 Span 过程 HttpClient 请求生成 Span 过程 基于 OTEL 库实现调用链跟踪总结 非侵入调用链跟踪实现思路 Go 非侵入链路追踪实现原理 在分布式.微服务架构下,应用一个请求往往贯穿多个分
-
Spring Cloud OpenFeign实例介绍使用方法
目录 一. OpenFeign概述 二. 使用步骤 2.1 feign接口模块 2.1.1依赖配置 2.1.2编写FeignClient的接口, 并加@FeignCleint 注解 2.2 消费端使用fegin接口 2.2.1在消费者端添加feign接口依赖 2.2.2在消费者端配置文件中添加 feign.client.url 2.2.3在消费者端启动类中添加@EnableFeignClients 2.2.4在消费者端使用fegin接口 2.3 测试 一. OpenFeign概述 OpenFei
-
Spring Cloud分布式定时器之ShedLock的实现
在实际的项目开发工作中,我们经常会遇到需要做一些定时任务的工作,那么在Spring Cloud中是如何实现的?今天来介绍下其中的一种解决方案--轻量级分布式定时锁ShedLock ShedLock ShedLock是一个在分布式环境中使用的定时任务框架,用于解决在分布式环境中的多个实例的相同定时任务在同一时间点重复执行的问题. 解决思路是通过对公用的数据库中的某个表进行记录和加锁,使得同一时间点只有第一个执行定时任务并成功在数据库表中写入相应记录的节点能够成功执行而其他节点直接跳过该任务. 目前
-
.NET Core分布式链路追踪框架的基本实现原理
分布式追踪 什么是分布式追踪 分布式系统 当我们使用 Google 或者 百度搜索时,查询服务会将关键字分发到多台查询服务器,每台服务器在自己的索引范围内进行搜索,搜索引擎可以在短时间内获得大量准确的搜索结果:同时,根据关键字,广告子系统会推送合适的相关广告,还会从竞价排名子系统获得网站权重.通常一个搜索可能需要成千上万台服务器参与,需要经过许多不同的系统提供服务. 多台计算机通过网络组成了一个庞大的系统,这个系统即是分布式系统. 在微服务或者云原生开发中,一般认为分布式系统是通过各种中间件/服
-
.NET Core分布式链路追踪框架的基本实现原理
目录 分布式追踪 什么是分布式追踪 分布式系统 分布式追踪 分布式追踪有什么用呢 Dapper 分布式追踪系统的实现 跟踪树和 span Jaeger 和 OpenTracing OpenTracing Jaeger 结构 OpenTracing 数据模型 Span 格式 Trace Span OpenTracing API 分布式追踪 什么是分布式追踪 分布式系统 当我们使用 Google 或者 百度搜索时,查询服务会将关键字分发到多台查询服务器,每台服务器在自己的索引范围内进行搜索,搜索引擎
-
详解spring cloud分布式日志链路跟踪
首先要明白一点,为什么要使用链路跟踪? 当我们微服务之间调用的时候可能会出错,但是我们不知道是哪个服务的问题,这时候就可以通过日志链路跟踪发现哪个服务出错. 它还有一个好处:当我们在企业中,可能每个人都负责一个服务,我们可以通过日志来检查自己所负责的服务不会出错,当调用其它服务时,这时候出现错误,那么就可以判定出不是自己的服务出错,从而也可以发现责任不是自己的. 基于微服务之间的调用开始,如果看不懂的小伙伴,请先参考我上篇博客:spring cloud中微服务之间的调用以及eureka的自我保护