详解hibernate4基本实现原理
整体流程
1:通过configuration来读cfg.xml文件
2:得到SessionFactory工厂
3:通过SessionFactory工厂来创建Session实例
4:通过Session打开事务
5:通过session的api操作数据库
6:事务提交
7:关闭连接
说明:以下分方法描述的实现流程并不是Hibernate的完整实现流程,也不是Hibernate的完整实现顺序,只是描述了Hibernate实现这些方法的主干和基本方式,主要是用来理解这些方法背后都发生了些什么,如果需要详细完整的实现流程,请查阅Hibernate相应文档和源代码

当我们调用了session.save(UserModel)后:
1:TO--->PO:Hibernate先在缓存中查找,如果发现在内部缓存中已经存在相同id的PO,就认为这个数据已经保存了,抛出例外。
如果缓存中没有,Hibernate会把传入的这个TO对象放到session控制的实例池去,也就是把一个瞬时对象变成了一个持久化对象。
如果需要Hibernate生成主键值,Hibernate就会去生成id并设置到PO上
2:客户端提交事务或者刷新内存
3:根据model类型和cfg.xml中映射文件的注册来找到相应的hbm.xml文件
4:根据hbm.xml文件和model来动态的拼sql,如下:
insert into表名(来自hbm.xml) (字段名列表(来自hbm.xml ))values(对应的值的列表(根据hbm.xml从传入的model中获取值))
5:真正用JDBC执行sql,把值添加到数据库
6:返回这个PO的id。

当我们调用了session.update(UserModel)后:
1:DO--->PO:首先根据model的主键在hibernate的实例池中查找该对象,找到就抛出错误。
如果没有就DO--->PO,Hibernate会把传入的这个DO对象放到session控制的实例池去,也就是把一个瞬时对象变成了一个持久化对象
2:客户端提交事务或者刷新内存
3:根据model类型和cfg.xml中映射文件的注册来找到相应的hbm.xml文件
4:根据hbm.xml文件和model来动态的拼sql,不进行脏数据检查,如下:
update表名(来自hbm.xml) set 字段名(来自hbm.xml )=值(根据hbm.xml从传入的model中获取值) where条件
5:真正用JDBC执行sql,把值修改到数据库


当我们调用了session.update(UserModel)后:
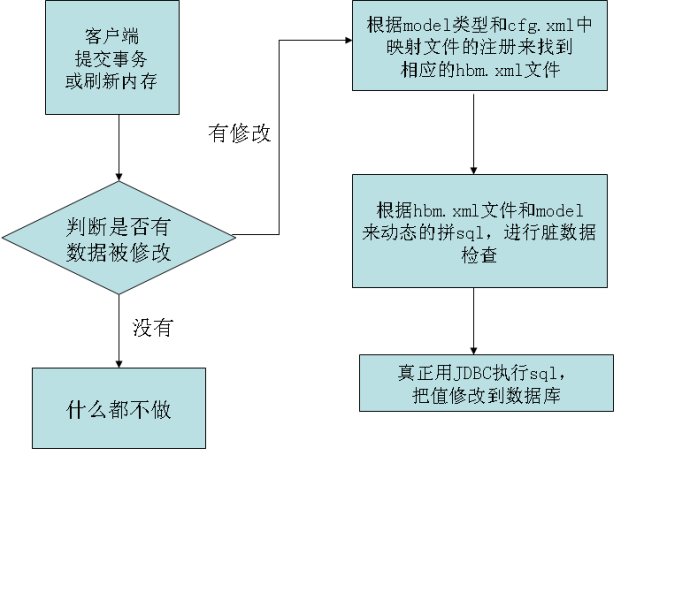
1:首先根据model的主键在hibernate的实例池中查找该对象,找到就使用该PO对象(用来检查脏数据)。
2:客户端提交事务或者刷新内存
3:Hibernate会进行脏数据检查,如果没有数据被修改,就不执行下面的步骤了。
4:根据model类型和cfg.xml中映射文件的注册来找到相应的hbm.xml文件
5:根据hbm.xml文件和model来动态的拼sql,进行脏数据检查(如果开启了dynamic-update的话),如下:
update表名(来自hbm.xml) set 字段名(来自hbm.xml )=值(根据hbm.xml从传入的model中获取值) where条件
6:真正用JDBC执行sql,把值修改到数据库
Id的生成方式为assigned的情况
当我们调用了session.delete(UserModel)后:
1:根据model的主键在数据库里面查找数据,来保证对象的存在,然后把找到的对象放到内存里面,如果此时在hibernate的实例池中已经存在对应的实体对象(注意:代理对象不算实体对象),就抛出例外。
2:如果此时在hibernate的实例池中不存在对应的实体对象,那么就把对象放到内存里面,但会标识成待删除的对象,就不可以被load等使用了。
3:如果对象还是不存在,那么就直接返回了(注意,这个时候是不抛出例外的)。也就是说,delete之前会执行一个查询语句。
4:客户端提交事务或者刷新内存
5:判断待删除的PO是否存在,存在才需要删除,否则不需要删除
6:如果要删除,才执行以下的步骤。先根据model类型和cfg.xml中映射文件的注册来找到相应的hbm.xml文件
7:根据hbm.xml文件和model来动态的拼sql,如下:
delete from表名(来自hbm.xml) where 主键=值(来自model)
8:真正的JDBC执行sql,把数据从数据库中删除


Id的生成方式为非assigned的情况
当我们调用了session.delete(UserModel)后:
1:根据model的主键在hibernate的实例池中查找对应的实体对象(注意:代理对象不算实体对象),找到就抛出例外。
2:如果内存中没有对应的实体对象,就什么都不做。
3:客户端提交事务或者刷新内存
4:先根据model类型和cfg.xml中映射文件的注册来找到相应的hbm.xml文件
5:根据hbm.xml文件和model来动态的拼sql,如下:
delete from表名(来自hbm.xml) where 主键=值(来自model)
6:真正用JDBC执行sql,把数据从数据库中删除,如果数据不存在,就抛出例外
当我们调用了session.delete(UserModel)后:
1:根据model的主键在hibernate的实例池中查找对应的实体对象(注意:代理对象不算实体对象),找到就使用该对象。
2:如果内存中没有对应的实体对象,就到数据库中查找来保证对象的存在,把找到的对象放到内存里面,而且不会标识成待删除的对象,可以继续被load等使用。代理对象也需要去数据库中查找数据。
3:如果对象还是不存在,那么就抛出例外。也就是说,delete之前可能会执行一个查询语句。
4:客户端提交事务或者刷新内存
5:根据model类型和cfg.xml中映射文件的注册来找到相应的hbm.xml文件
6:根据hbm.xml文件和model来动态的拼sql,如下:
delete from表名(来自hbm.xml) where 主键=值(来自model)
7:真正用JDBC执行sql,把数据从数据库中删除

当我们调用了s.load(UserModel.class,“主键值");后:
1:根据model类型和主键值在一级缓存中查找对象,找到就返回该对象
2:如果没有找到,判断是否lazy=true,如果是,那就生成一个代理对象并返回;否则就先查找二级缓存,二级缓存没有,就查找数据库。如果是返回代理对象的,在第一次访问非主键属性的时候,先查找二级缓存,二级缓存中没有才真正查找数据库。
3:如果需要查找数据库的话,会根据model类型和cfg.xml中映射文件的注册来找到相应的hbm.xml文件
4:根据hbm.xml文件和model来动态的拼sql,如下:
select字段列表(来自hbm.xml) from 表名(来自hbm.xml) where 主键=值
5:真正用JDBC执行sql,把数据从数据库中查询出来到rs里面。如果找不到就报错
6:从结果集---〉Model,然后返回model
注意:load方法开不开事务都可以执行查询语句。


当我们调用了s.get(UserModel.class, “主键值");后:
1:先根据model类型和主键值查找缓存,如果存在具体的实体对象,就返回;如果存在实体的代理对象(比如前面load这条数据,但是还没有使用,那么load生成的是一个只有主键值的代理对象),那么查找数据库,把具体的数据填充到这个代理对象里面,然后返回这个代理对象,当然这个代理对象此时已经完全装载好数据了,跟实体对象没有什么区别了。
2:如果要查找数据库,先根据model类型和cfg.xml中映射文件的注册来找到相应的hbm.xml文件
3:根据hbm.xml文件和model来动态的拼sql,如下:
select字段列表(来自hbm.xml) from 表名(来自hbm.xml) where 主键=值
4:真正用JDBC执行sql,把数据从数据库中查询出来到rs里面,没有值就返回null
5:从结果集---〉Model,然后返回model
注意:get方法开不开事务都可以执行查询语句。


当我们调用了q.list();后:
1:对HQL进行语义分析,分析出model来
2:根据model类型和cfg.xml中映射文件的注册来找到相应的hbm.xml文件
3:根据hbm.xml文件和model,来解析HQL,从而实现动态的把HQL转换成对应的sql,(从hql---〉sql这个过程是非常复杂的,不但区分不同的数据库,还包括了对sql进行自动的优化),这里只能简单的示例如下:
select字段列表(来自hbm.xml) from 表名(来自hbm.xml) where 条件
4:真正用JDBC执行sql,把数据从数据库中查询出来到rs里面
5:从结果集---〉Model集合(或对象数组),然后返回model集合(或对象数组)
注意:list()方法开不开事务都可以执行查询语句。

总结
以上所述是小编给大家介绍的hibernate4基本实现原理,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
相关推荐
-
解决Hibernate4执行save()或update()无效问题的方法
最近在写网上商城项目时,遇到一个问题:Hibernate在执行save()或者update()方法后,并没有任何效果,数据库中没有任何改动,而且控制台也没有报任何错,这让我很无语-- 我在网上查了下,有的人说是主键的自增长问题,有的人说是没有开启事务,所以无法写入或更新数据库,我详细看了他们的分析,说的都有道理,但是这些解决方法对我都不管用,因为我的主键是没有问题的,事务是由Spring管理的,在其他save操作都可以,都没有问题. 既然客观上都没有问题,于是我把焦点放在了具体要save或upd
-

浅谈SpringMVC+Spring3+Hibernate4开发环境搭建
早期的项目比较简单,多是用JSP .Servlet + JDBC 直接搞定,后来使用 Struts1(Struts2)+Spring+Hibernate, 严格按照分层概念驱动项目开发,这次又使用 Spring MVC取代Struts来进行开发. MVC已经是现代Web开发中的一个很重要的部分,下面介绍一下SpringMVC+Spring3+Hibernate4的开发环境搭建 先大致看一下项目结构: 具体的代码不再演示,主要是走了一个很平常的路线,mvc-servcie-dao-hibernat
-
spring mvc4.1.6 spring4.1.6 hibernate4.3.11 mysql5.5.25开发环境搭建图文教程
一.准备工作 开始之前,先参考上一篇: struts2.3.24 + spring4.1.6 + hibernate4.3.11 + mysql5.5.25 开发环境搭建及相关说明 思路都是一样的,只不过把struts2替换成了spring mvc 二.不同的地方 工程目录及jar包: action包改成controller: 删除struts2 jar包,添加spring mvc包(已有的话,不需添加): web.xml配置: 跟之前不同的地方是把struts2的过滤器替换成了一个ser
-
SSH框架网上商城项目第1战之整合Struts2、Hibernate4.3和Spring4.2
本文开始做一个网上商城的项目,首先从搭建环境开始,一步步整合S2SH.这篇博文主要总结一下如何整合Struts2.Hibernate4.3和Spring4.2. 整合三大框架得先从搭建各部分环境开始,也就是说首先得把Spring,Hibernate和Struts2的环境搭建好,确保它们没有问题了,再做整合.这篇博文遵从的顺序是:先搭建Spring环境-->然后搭建Hibernate环境--> 整合Spring和Hibernate --> 搭建Struts2环境 --> 整合Spri
-
hibernate4快速入门实例详解
Hibernate是什么 Hibernate是一个轻量级的ORMapping框架 ORMapping原理(Object RelationalMapping) ORMapping基本对应规则: 1:类跟表相对应 2:类的属性跟表的字段相对应 3:类的实例与表中具体的一条记录相对应 4:一个类可以对应多个表,一个表也可以对应对个类 5:DB中的表可以没有主键,但是Object中必须设置主键字段 6:DB中表与表之间的关系(如:外键)映射成为Object之间的关系 7:Object中属性的个数和名称可
-
struts2.3.24+spring4.1.6+hibernate4.3.11+mysql5.5.25开发环境搭建图文教程
struts2.3.24 + spring4.1.6 + hibernate4.3.11+ mysql5.5.25开发环境搭建及相关说明. 一.目标 1.搭建传统的ssh开发环境,并成功运行(插入.查询) 2.了解c3p0连接池相关配置 3.了解验证hibernate的二级缓存,并验证 4.了解spring事物配置,并验证 5.了解spring的IOC(依赖注入),将struts2的action对象(bean)交给spring管理,自定义bean等...并验证 6.了解spring aop(面向
-
Hibernate4在MySQL5.1以上版本创建表出错 type=InnDB
在搭建springmvc框架时,底层使用hibernate4.1.8,数据库使用mysql5.1,使用hibernate自动生成数据库表时,hibernate方言使用org.hibernate.dialect.MySQLInnoDBDialect,自动生成表时会出现错误,如下: 复制代码 代码如下: [13-04-13 19:11:37.190] {resin-60} You have an error in your SQL syntax; check the manual that corr
-
springmvc4+hibernate4分页查询功能实现
Springmvc+hibernate成为现在很多人用的框架整合,最近自己也在学习摸索,由于我们在开发项目中很多项目都用到列表分页功能,在此参考网上一些资料,以springmvc4+hibnerate4边学边总结,得出分页功能代码,虽然不一定通用,对于初学者来说有参考价值. 分页实现的基本过程: 一.分页工具类 思路: 1.编写Page类,定义属性,应该包括:查询结果集合.查询记录总数.每页显示记录数.当前第几页等属性. 2.编写Page类,定义方法,应该包括:总页数.当前页开始记录.首页.下一
-
详解hibernate4基本实现原理
整体流程 1:通过configuration来读cfg.xml文件 2:得到SessionFactory工厂 3:通过SessionFactory工厂来创建Session实例 4:通过Session打开事务 5:通过session的api操作数据库 6:事务提交 7:关闭连接 说明:以下分方法描述的实现流程并不是Hibernate的完整实现流程,也不是Hibernate的完整实现顺序,只是描述了Hibernate实现这些方法的主干和基本方式,主要是用来理解这些方法背后都发生了些什么,如果需要详细
-
详解jquery选择器的原理
详解jquery选择器的原理 html部分 <!doctype html> <html lang="en"> <head> <meta charset="UTF-8" /> <title>Document</title> <script src="js/minijquery.js"></script> </head> <body>
-
详解C#扩展方法原理及其使用
1.写在前面 今天群里一个小伙伴问了这样一个问题,扩展方法与实例方法的执行顺序是什么样子的,谁先谁后(这个问题会在文章结尾回答).所以写了这边文章,力图从原理角度解释扩展方法及其使用. 以下为主要内容: 什么是扩展方法 扩展方法原理及自定义扩展方法 扩展方法的使用及其注意事项 2.什么是扩展方法 一般而言,扩展方法为现有类型添加新的方法(从面向对象的角度来说,是为现有对象添加新的行为)而无需修改原有类型,这是一种无侵入而且非常安全的方式.扩展方法是静态的,它的使用和其他实例方法几乎没有什么区别.
-
详解 Java HashMap 实现原理
HashMap 是 Java 中最常见数据结构之一,它能够在 O(1) 时间复杂度存储键值对和根据键值读取值操作.本文将分析其内部实现原理(基于 jdk1.8.0_231). 数据结构 HashMap 是基于哈希值的一种映射,所谓映射,即可以根据 key 获取到相应的 value.例如:数组是一种的映射,根据下标能够取到值.不过相对于数组,HashMap 占用的存储空间更小,复杂度却同样为 O(1). HashMap 内部定义了一排"桶",用一个叫 table 的 Node 数组表示:
-
详解PHP的执行原理和流程
简介 先看看下面这个过程: • 我们从未手动开启过PHP的相关进程,它是随着Apache的启动而运行的: • PHP通过mod_php5.so模块和Apache相连(具体说来是SAPI,即服务器应用程序编程接口): • PHP总共有三个模块:内核.Zend引擎.以及扩展层: • PHP内核用来处理请求.文件流.错误处理等相关操作: • Zend引擎(ZE)用以将源文件转换成机器语言,然后在虚拟机上运行它: • 扩展层是一组函数.类库和流,PHP使用它们来执行一些特定的操作.比如,我们需要mysq
-
详解App保活实现原理
概述 早期的 Android 系统不完善,导致 App 侧有很多空子可以钻,因此它们有着有着各种各样的姿势进行保活.譬如说在 Android 5.0 以前,App 内部通过 native 方式 fork 出来的进程是不受系统管控的,系统在杀 App 进程的时候,只会去杀 App 启动的 Java 进程:因此诞生了一大批"毒瘤",他们通过 fork native 进程,在 App 的 Java 进程被杀死的时候通过am命令拉起自己从而实现永生.那时候的 Android 可谓是魑魅横行,群
-
详解Bagging算法的原理及Python实现
目录 一.什么是集成学习 二.Bagging算法 三.Bagging用于分类 四.Bagging用于回归 一.什么是集成学习 集成学习是一种技术框架,它本身不是一个单独的机器学习算法,而是通过构建并结合多个机器学习器来完成学习任务,一般结构是:先产生一组"个体学习器",再用某种策略将它们结合起来,目前,有三种常见的集成学习框架(策略):bagging,boosting和stacking 也就是说,集成学习有两个主要的问题需要解决,第一是如何得到若干个个体学习器,第二是如何选择一种结合策
-
详解Feign的实现原理
目录 一.什么是Feign 二.为什么用Feign 三.实例 3.1.原生使用方式 3.2.结合 Spring Cloud 使用方式 四.探索Feign 五.总结 一.什么是Feign Feign 是⼀个 HTTP 请求的轻量级客户端框架.通过 接口 + 注解的方式发起 HTTP 请求调用,面向接口编程,而不是像 Java 中通过封装 HTTP 请求报文的方式直接调用.服务消费方拿到服务提供方的接⼝,然后像调⽤本地接⼝⽅法⼀样去调⽤,实际发出的是远程的请求.让我们更加便捷和优雅的去调⽤基于 HT
-
详解高性能缓存Caffeine原理及实战
目录 一.简介 二.Caffeine 原理 2.1.淘汰算法 2.1.1.常见算法 2.1.2.W-TinyLFU 算法 2.2.高性能读写 2.2.1.读缓冲 2.2.2.写缓冲 三.Caffeine 实战 3.1.配置参数 3.2.项目实战 四.总结 一.简介 下面是Caffeine 官方测试报告. 由上面三幅图可见:不管在并发读.并发写还是并发读写的场景下,Caffeine 的性能都大幅领先于其他本地开源缓存组件. 本文先介绍 Caffeine 实现原理,再讲解如何在项目中使用 Caffe
-
详解Redis数据类型实现原理
目录 1. 对象的类型与编码 ① type属性 ② encoding 属性和 *prt 指针 2. 字符串对象 ① 编码 ② 编码的转换 3. 列表对象 ① 编码 ② 编码转换 4. 哈希对象 ① 编码 ② 编码转换 5. 集合对象 ① 编码 ② 编码转换 6. 有序集合对象 ① 编码 ② 编码转换 7. 五大数据类型的应用场景 1. 对象的类型与编码 Redis使用前面说的五大数据类型来表示键和值,每次在Redis数据库中创建一个键值对时,至少会创建两个对象,一个是键对象,一个是值对象,而Re