利用numpy和pandas处理csv文件中的时间方法
环境:numpy,pandas,python3
在机器学习和深度学习的过程中,对于处理预测,回归问题,有时候变量是时间,需要进行合适的转换处理后才能进行学习分析,关于时间的变量如下所示,利用pandas和numpy对csv文件中时间进行处理。
date (UTC) Price 01/01/2015 0:00 48.1 01/01/2015 1:00 47.33 01/01/2015 2:00 42.27
#coding:utf-8
import datetime
import pandas as pd
import numpy as np
import pickle
#用pandas将时间转为标准格式
dateparse = lambda dates: pd.datetime.strptime(dates,'%d/%m/%Y %H:%M')
#将时间栏合并,并转为标准时间格式
rawdata = pd.read_csv('RealMarketPriceDataPT.csv',parse_dates={'timeline':['date','(UTC)']},date_parser=dateparse)
#定义一个将时间转为数字的函数,s为字符串
def datestr2num(s):
#toordinal()将时间格式字符串转为数字
return datetime.datetime.strptime(s,'%Y-%m-%d %H:%M:%S').toordinal()
x = []
y = []
new_date = []
for i in range(rawdata.shape[0]):
x_convert = int(datestr2num(str(rawdata.ix[i,0])))
new_date.append(x_convert)
y_convert = rawdata.ix[i,1].astype(np.float32)
x.append(x_convert)
y.append(y_convert)
x = np.array(x).astype(np.float32)
"""
with open('price.pickle','wb') as f:
pickle.dump((x,y),f)
"""
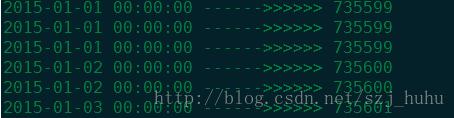
print(datetime.datetime.fromordinal(new_date[0]),'------>>>>>>',new_date[0])
print(datetime.datetime.fromordinal(new_date[10]),'------>>>>>>',new_date[10])
print(datetime.datetime.fromordinal(new_date[20]),'------>>>>>>',new_date[20])
print(datetime.datetime.fromordinal(new_date[30]),'------>>>>>>',new_date[30])
print(datetime.datetime.fromordinal(new_date[40]),'------>>>>>>',new_date[40])
print(datetime.datetime.fromordinal(new_date[50]),'------>>>>>>',new_date[50])
结果
将csv文件中的时间栏合并为一列,并转为方便数据分析的float或int类型
以上这篇利用numpy和pandas处理csv文件中的时间方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
您可能感兴趣的文章:
- python处理csv数据的方法
- python:pandas合并csv文件的方法(图书数据集成)
- 在Python中利用Pandas库处理大数据的简单介绍
- python学习教程之Numpy和Pandas的使用
- Python遍历pandas数据方法总结
相关推荐
-

Python遍历pandas数据方法总结
前言 Pandas是python的一个数据分析包,提供了大量的快速便捷处理数据的函数和方法.其中Pandas定义了Series 和 DataFrame两种数据类型,这使数据操作变得更简单.Series 是一种一维的数据结构,类似于将列表数据值与索引值相结合.DataFrame 是一种二维的数据结构,接近于电子表格或者mysql数据库的形式. 在数据分析中不可避免的涉及到对数据的遍历查询和处理,比如我们需要将dataframe两列数据两两相除,并将结果存储于一个新的列表中.本文通过该例程介绍对pa
-
python:pandas合并csv文件的方法(图书数据集成)
数据集成:将不同表的数据通过主键进行连接起来,方便对数据进行整体的分析. 两张表:ReaderInformation.csv,ReaderRentRecode.csv ReaderInformation.csv: ReaderRentRecode.csv: pandas读取csv文件,并进行csv文件合并处理: # -*- coding:utf-8 -*- import csv as csv import numpy as np # ------------- # csv读取表格数据 # ---
-
python学习教程之Numpy和Pandas的使用
前言 本文主要给大家介绍了关于python中Numpy和Pandas使用的相关资料,分享出来供大家参考学习,下面话不多说了,来一起看看详细的介绍吧. 它们是什么? NumPy是Python语言的一个扩充程序库.支持高级大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库. Pandas是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的.Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具.Pandas提供了大量能使我们快速便捷地处理数据
-
在Python中利用Pandas库处理大数据的简单介绍
在数据分析领域,最热门的莫过于Python和R语言,此前有一篇文章<别老扯什么Hadoop了,你的数据根本不够大>指出:只有在超过5TB数据量的规模下,Hadoop才是一个合理的技术选择.这次拿到近亿条日志数据,千万级数据已经是关系型数据库的查询分析瓶颈,之前使用过Hadoop对大量文本进行分类,这次决定采用Python来处理数据: 硬件环境 CPU:3.5 GHz Intel Core i7 内存:32 GB HDDR 3 1600 MHz 硬
-
python处理csv数据的方法
本文实例讲述了python处理csv数据的方法.分享给大家供大家参考.具体如下: Python代码: 复制代码 代码如下: #coding=utf-8 __author__ = 'dehua.li' from datetime import * import datetime import csv import sys import time import string import os import os.path import pylab as plt rootdir='/nethome/
-
利用numpy和pandas处理csv文件中的时间方法
环境:numpy,pandas,python3 在机器学习和深度学习的过程中,对于处理预测,回归问题,有时候变量是时间,需要进行合适的转换处理后才能进行学习分析,关于时间的变量如下所示,利用pandas和numpy对csv文件中时间进行处理. date (UTC) Price 01/01/2015 0:00 48.1 01/01/2015 1:00 47.33 01/01/2015 2:00 42.27 #coding:utf-8 import datetime import pandas as
-
使用pandas读取csv文件的指定列方法
根据教程实现了读取csv文件前面的几行数据,一下就想到了是不是可以实现前面几列的数据.经过多番尝试总算试出来了一种方法. 之所以想实现读取前面的几列是因为我手头的一个csv文件恰好有后面几列没有可用数据,但是却一直存在着.原来的数据如下: GreydeMac-mini:chapter06 greyzhang$ cat data.csv 1,name_01,coment_01,,,, 2,name_02,coment_02,,,, 3,name_03,coment_03,,,, 4,name_04
-
使用NumPy和pandas对CSV文件进行写操作的实例
数组存储成CSV之类的区隔型文件: 下面代码给随机数生成器指定种子,并生成一个3*4的NumPy数组 将一个数组元素的值设为NaN: In [26]: import numpy as np In [27]: np.random.seed(42) In [28]: a = np.random.randn(3,4) In [29]: a[2][2] = np.nan In [30]: print(a) [[ 0.49671415 -0.1382643 0.64768854 1.52302986] [
-
Python使用Pandas对csv文件进行数据处理的方法
今天接到一个新的任务,要对一个140多M的csv文件进行数据处理,总共有170多万行,尝试了导入本地的MySQL数据库进行查询,结果用Navicat导入直接卡死....估计是XAMPP套装里面全默认配置的MySQL性能不给力,又尝试用R搞一下吧结果发现光加载csv文件就要3分钟左右的时间,相当不给力啊,翻了翻万能的知乎发现了Python下的一个神器包:Pandas(熊猫们?),加载这个140多M的csv文件两秒钟就搞定,后面的分类汇总等操作也都是秒开,太牛逼了!记录一下这次数据处理的过程: 使用
-
Pandas操作CSV文件的读写实现方法
(1).导库 import pandas as pd from pandas import Series (2).读取csv文件的两种方式 #读取csv文件的两种方式 f = open('E:/建模/第5周/data/ex1.csv') #方法一 df = pd.read_csv(f) print(df) f.close f = open('E:/建模/第5周/data/ex1.csv') #方法二,必须指定分隔符为',',否则会读取失败 df = pd.read_table(f,sep=','
-
Python 3.x读写csv文件中数字的方法示例
前言 本文主要给大家介绍了关于Python3.x读写csv文件中数字的相关内容,分享出来供大家参考学习,下面话不多说了,来一起看看详细的介绍吧. 读写csv文件 读文件时先产生str的列表,把最后的换行符删掉:然后一个个str转换成int ## 读写csv文件 csv_file = 'datas.csv' csv = open(csv_file,'w') for i in range(1,20): csv.write(str(i) + ',') if i % 10 == 0: csv.write
-
python中pandas读取csv文件时如何省去csv.reader()操作指定列步骤
优点: 方便,有专门支持读取csv文件的pd.read_csv()函数. 将csv转换成二维列表形式 支持通过列名查找特定列. 相比csv库,事半功倍 1.读取csv文件 import pandas as pd file="c:\data\test.csv" csvPD=pd.read_csv(file) df = pd.read_csv('data.csv', encoding='gbk') #指定编码 read_csv()方法参数介绍 filepath_or_buf
-
解决Python中pandas读取*.csv文件出现编码问题
1.问题 在使用Python中pandas读取csv文件时,由于文件编码格式出现以下问题: Traceback (most recent call last): File "pandas\_libs\parsers.pyx", line 1134, in pandas._libs.parsers.TextReader._convert_tokens File "pandas\_libs\parsers.pyx", line 1240, in pandas._libs
-
利用Python如何将数据写到CSV文件中
前言 我们从网上爬取数据,最后一步会考虑如何存储数据.如果数据量不大,往往不会选择存储到数据库,而是选择存储到文件中,例如文本文件.CSV 文件.xls 文件等.因为文件具备携带方便.查阅直观. Python 作为胶水语言,搞定这些当然不在话下.但在写数据过程中,经常因数据源中带有中文汉字而报错.最让人头皮发麻的编码问题. 我先说下编码相关的知识.编码方式有很多种:UTF-8, GBK, ASCII 等. ASCII 码是美国在上个世纪 60 年代制定的一套字符编码.主要是规范英语字符和二进制位