python 机器学习之支持向量机非线性回归SVR模型
本文介绍了python 支持向量机非线性回归SVR模型,废话不多说,具体如下:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets, linear_model,svm
from sklearn.model_selection import train_test_split
def load_data_regression():
'''
加载用于回归问题的数据集
'''
diabetes = datasets.load_diabetes() #使用 scikit-learn 自带的一个糖尿病病人的数据集
# 拆分成训练集和测试集,测试集大小为原始数据集大小的 1/4
return train_test_split(diabetes.data,diabetes.target,test_size=0.25,random_state=0)
#支持向量机非线性回归SVR模型
def test_SVR_linear(*data):
X_train,X_test,y_train,y_test=data
regr=svm.SVR(kernel='linear')
regr.fit(X_train,y_train)
print('Coefficients:%s, intercept %s'%(regr.coef_,regr.intercept_))
print('Score: %.2f' % regr.score(X_test, y_test))
# 生成用于回归问题的数据集
X_train,X_test,y_train,y_test=load_data_regression()
# 调用 test_LinearSVR
test_SVR_linear(X_train,X_test,y_train,y_test)
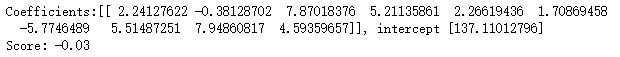
def test_SVR_poly(*data):
'''
测试 多项式核的 SVR 的预测性能随 degree、gamma、coef0 的影响.
'''
X_train,X_test,y_train,y_test=data
fig=plt.figure()
### 测试 degree ####
degrees=range(1,20)
train_scores=[]
test_scores=[]
for degree in degrees:
regr=svm.SVR(kernel='poly',degree=degree,coef0=1)
regr.fit(X_train,y_train)
train_scores.append(regr.score(X_train,y_train))
test_scores.append(regr.score(X_test, y_test))
ax=fig.add_subplot(1,3,1)
ax.plot(degrees,train_scores,label="Training score ",marker='+' )
ax.plot(degrees,test_scores,label= " Testing score ",marker='o' )
ax.set_title( "SVR_poly_degree r=1")
ax.set_xlabel("p")
ax.set_ylabel("score")
ax.set_ylim(-1,1.)
ax.legend(loc="best",framealpha=0.5)
### 测试 gamma,固定 degree为3, coef0 为 1 ####
gammas=range(1,40)
train_scores=[]
test_scores=[]
for gamma in gammas:
regr=svm.SVR(kernel='poly',gamma=gamma,degree=3,coef0=1)
regr.fit(X_train,y_train)
train_scores.append(regr.score(X_train,y_train))
test_scores.append(regr.score(X_test, y_test))
ax=fig.add_subplot(1,3,2)
ax.plot(gammas,train_scores,label="Training score ",marker='+' )
ax.plot(gammas,test_scores,label= " Testing score ",marker='o' )
ax.set_title( "SVR_poly_gamma r=1")
ax.set_xlabel(r"$\gamma$")
ax.set_ylabel("score")
ax.set_ylim(-1,1)
ax.legend(loc="best",framealpha=0.5)
### 测试 r,固定 gamma 为 20,degree为 3 ######
rs=range(0,20)
train_scores=[]
test_scores=[]
for r in rs:
regr=svm.SVR(kernel='poly',gamma=20,degree=3,coef0=r)
regr.fit(X_train,y_train)
train_scores.append(regr.score(X_train,y_train))
test_scores.append(regr.score(X_test, y_test))
ax=fig.add_subplot(1,3,3)
ax.plot(rs,train_scores,label="Training score ",marker='+' )
ax.plot(rs,test_scores,label= " Testing score ",marker='o' )
ax.set_title( "SVR_poly_r gamma=20 degree=3")
ax.set_xlabel(r"r")
ax.set_ylabel("score")
ax.set_ylim(-1,1.)
ax.legend(loc="best",framealpha=0.5)
plt.show()
# 调用 test_SVR_poly
test_SVR_poly(X_train,X_test,y_train,y_test)
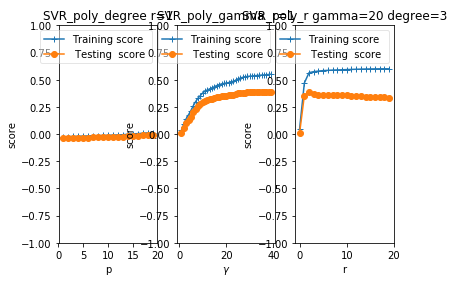
def test_SVR_rbf(*data):
'''
测试 高斯核的 SVR 的预测性能随 gamma 参数的影响
'''
X_train,X_test,y_train,y_test=data
gammas=range(1,20)
train_scores=[]
test_scores=[]
for gamma in gammas:
regr=svm.SVR(kernel='rbf',gamma=gamma)
regr.fit(X_train,y_train)
train_scores.append(regr.score(X_train,y_train))
test_scores.append(regr.score(X_test, y_test))
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
ax.plot(gammas,train_scores,label="Training score ",marker='+' )
ax.plot(gammas,test_scores,label= " Testing score ",marker='o' )
ax.set_title( "SVR_rbf")
ax.set_xlabel(r"$\gamma$")
ax.set_ylabel("score")
ax.set_ylim(-1,1)
ax.legend(loc="best",framealpha=0.5)
plt.show()
# 调用 test_SVR_rbf
test_SVR_rbf(X_train,X_test,y_train,y_test)
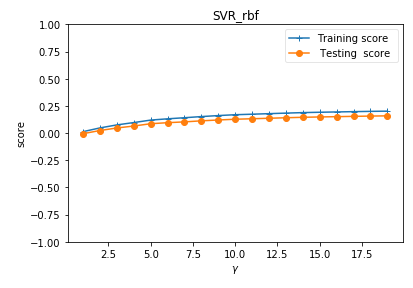
def test_SVR_sigmoid(*data):
'''
测试 sigmoid 核的 SVR 的预测性能随 gamma、coef0 的影响.
'''
X_train,X_test,y_train,y_test=data
fig=plt.figure()
### 测试 gammam,固定 coef0 为 0.01 ####
gammas=np.logspace(-1,3)
train_scores=[]
test_scores=[]
for gamma in gammas:
regr=svm.SVR(kernel='sigmoid',gamma=gamma,coef0=0.01)
regr.fit(X_train,y_train)
train_scores.append(regr.score(X_train,y_train))
test_scores.append(regr.score(X_test, y_test))
ax=fig.add_subplot(1,2,1)
ax.plot(gammas,train_scores,label="Training score ",marker='+' )
ax.plot(gammas,test_scores,label= " Testing score ",marker='o' )
ax.set_title( "SVR_sigmoid_gamma r=0.01")
ax.set_xscale("log")
ax.set_xlabel(r"$\gamma$")
ax.set_ylabel("score")
ax.set_ylim(-1,1)
ax.legend(loc="best",framealpha=0.5)
### 测试 r ,固定 gamma 为 10 ######
rs=np.linspace(0,5)
train_scores=[]
test_scores=[]
for r in rs:
regr=svm.SVR(kernel='sigmoid',coef0=r,gamma=10)
regr.fit(X_train,y_train)
train_scores.append(regr.score(X_train,y_train))
test_scores.append(regr.score(X_test, y_test))
ax=fig.add_subplot(1,2,2)
ax.plot(rs,train_scores,label="Training score ",marker='+' )
ax.plot(rs,test_scores,label= " Testing score ",marker='o' )
ax.set_title( "SVR_sigmoid_r gamma=10")
ax.set_xlabel(r"r")
ax.set_ylabel("score")
ax.set_ylim(-1,1)
ax.legend(loc="best",framealpha=0.5)
plt.show()
# 调用 test_SVR_sigmoid
test_SVR_sigmoid(X_train,X_test,y_train,y_test)
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
Python中使用支持向量机SVM实践
在机器学习领域,支持向量机SVM(Support Vector Machine)是一个有监督的学习模型,通常用来进行模式识别.分类(异常值检测)以及回归分析. 其具有以下特征: (1)SVM可以表示为凸优化问题,因此可以利用已知的有效算法发现目标函数的全局最小值.而其他分类方法都采用一种基于贪心学习的策略来搜索假设空间,这种方法一般只能获得局部最优解. (2) SVM通过最大化决策边界的边缘来实现控制模型的能力.尽管如此,用户必须提供其他参数,如使用核函数类型和引入松弛变量等. (3)SVM一般
-

Python机器学习之SVM支持向量机
SVM支持向量机是建立于统计学习理论上的一种分类算法,适合与处理具备高维特征的数据集. SVM算法的数学原理相对比较复杂,好在由于SVM算法的研究与应用如此火爆,CSDN博客里也有大量的好文章对此进行分析,下面给出几个本人认为讲解的相当不错的: 支持向量机通俗导论(理解SVM的3层境界) JULY大牛讲的是如此详细,由浅入深层层推进,以至于关于SVM的原理,我一个字都不想写了..强烈推荐. 还有一个比较通俗的简单版本的:手把手教你实现SVM算法 SVN原理比较复杂,但是思想很简单,一句话概括,就
-
Python中支持向量机SVM的使用方法详解
除了在Matlab中使用PRTools工具箱中的svm算法,Python中一样可以使用支持向量机做分类.因为Python中的sklearn库也集成了SVM算法,本文的运行环境是Pycharm. 一.导入sklearn算法包 Scikit-Learn库已经实现了所有基本机器学习的算法,具体使用详见官方文档说明 skleran中集成了许多算法,其导入包的方式如下所示, 逻辑回归:from sklearn.linear_model import LogisticRegression 朴素贝叶斯:fro
-
Python中使用支持向量机(SVM)算法
在机器学习领域,支持向量机SVM(Support Vector Machine)是一个有监督的学习模型,通常用来进行模式识别.分类(异常值检测)以及回归分析. 其具有以下特征: (1)SVM可以表示为凸优化问题,因此可以利用已知的有效算法发现目标函数的全局最小值.而其他分类方法都采用一种基于贪心学习的策略来搜索假设空间,这种方法一般只能获得局部最优解. (2) SVM通过最大化决策边界的边缘来实现控制模型的能力.尽管如此,用户必须提供其他参数,如使用核函数类型和引入松弛变量等. (3)S
-
Python SVM(支持向量机)实现方法完整示例
本文实例讲述了Python SVM(支持向量机)实现方法.分享给大家供大家参考,具体如下: 运行环境 Pyhton3 numpy(科学计算包) matplotlib(画图所需,不画图可不必) 计算过程 st=>start: 开始 e=>end: 结束 op1=>operation: 读入数据 op2=>operation: 格式化数据 cond=>condition: 是否达到迭代次数 op3=>operation: 寻找超平面分割最小间隔 ccond=>cond
-
python机器学习理论与实战(五)支持向量机
做机器学习的一定对支持向量机(support vector machine-SVM)颇为熟悉,因为在深度学习出现之前,SVM一直霸占着机器学习老大哥的位子.他的理论很优美,各种变种改进版本也很多,比如latent-SVM, structural-SVM等.这节先来看看SVM的理论吧,在(图一)中A图表示有两类的数据集,图B,C,D都提供了一个线性分类器来对数据进行分类?但是哪个效果好一些? (图一) 可能对这个数据集来说,三个的分类器都一样足够好了吧,但是其实不然,这个只是训练集,现实测试的样本
-
python机器学习理论与实战(六)支持向量机
上节基本完成了SVM的理论推倒,寻找最大化间隔的目标最终转换成求解拉格朗日乘子变量alpha的求解问题,求出了alpha即可求解出SVM的权重W,有了权重也就有了最大间隔距离,但是其实上节我们有个假设:就是训练集是线性可分的,这样求出的alpha在[0,infinite].但是如果数据不是线性可分的呢?此时我们就要允许部分的样本可以越过分类器,这样优化的目标函数就可以不变,只要引入松弛变量即可,它表示错分类样本点的代价,分类正确时它等于0,当分类错误时,其中Tn表示样本的真实标签-1或者1,回顾
-
python 机器学习之支持向量机非线性回归SVR模型
本文介绍了python 支持向量机非线性回归SVR模型,废话不多说,具体如下: import numpy as np import matplotlib.pyplot as plt from sklearn import datasets, linear_model,svm from sklearn.model_selection import train_test_split def load_data_regression(): ''' 加载用于回归问题的数据集 ''' diabetes =
-
python机器学习库scikit-learn:SVR的基本应用
scikit-learn是python的第三方机器学习库,里面集成了大量机器学习的常用方法.例如:贝叶斯,svm,knn等. scikit-learn的官网 : http://scikit-learn.org/stable/index.html点击打开链接 SVR是支持向量回归(support vector regression)的英文缩写,是支持向量机(SVM)的重要的应用分支. scikit-learn中提供了基于libsvm的SVR解决方案. PS:libsvm是台湾大学林智仁教授等开发设
-
python机器学习朴素贝叶斯算法及模型的选择和调优详解
目录 一.概率知识基础 1.概率 2.联合概率 3.条件概率 二.朴素贝叶斯 1.朴素贝叶斯计算方式 2.拉普拉斯平滑 3.朴素贝叶斯API 三.朴素贝叶斯算法案例 1.案例概述 2.数据获取 3.数据处理 4.算法流程 5.注意事项 四.分类模型的评估 1.混淆矩阵 2.评估模型API 3.模型选择与调优 ①交叉验证 ②网格搜索 五.以knn为例的模型调优使用方法 1.对超参数进行构造 2.进行网格搜索 3.结果查看 一.概率知识基础 1.概率 概率就是某件事情发生的可能性. 2.联合概率 包
-
Python机器学习入门(六)优化模型
目录 1.集成算法 1.1袋装算法 1.1.1袋装决策树 1.1.2随机森林 1.1.3极端随机树 1.2提升算法 1.2.1AdaBoost 1.2.2随机梯度提升 1.3投票算法 2.算法调参 2.1网络搜索优化参数 2.2随机搜索优化参数 总结 有时提升一个模型的准确度很困难.你会尝试所有曾学习过的策略和算法,但模型正确率并没有改善.这时你会觉得无助和困顿,这也正是90%的数据科学家开始放弃的时候.不过,这才是考验真正本领的时候!这也是普通的数据科学家和大师级数据科学家的差距所在. 1.集
-
Python机器学习入门(四)选择模型
目录 1.数据分离与验证 1.1分离训练数据集和评估数据集 1.2K折交叉验证分离 1.3弃一交叉验证分离 1.4重复随机分离评估数据集与训练数据集 2.算法评估 2.1分类算法评估 2.1.1分类准确度 2.1.2分类报告 2.2回归算法评估 2.2.1平均绝对误差 2.2.2均方误差 2.2.3判定系数() 总结 1.数据分离与验证 要知道算法模型对未知的数据表现如何,最好的评估办法是利用已经明确知道结果的数据运行生成的算法模型进行验证.此外还可以使用新的数据来评估算法模型. 在评估机器学习
-
Python机器学习NLP自然语言处理基本操作词向量模型
目录 概述 词向量 词向量维度 Word2Vec CBOW 模型 Skip-Gram 模型 负采样模型 词向量的训练过程 1. 初始化词向量矩阵 2. 神经网络反向传播 词向量模型实战 训练模型 使用模型 概述 从今天开始我们将开启一段自然语言处理 (NLP) 的旅程. 自然语言处理可以让来处理, 理解, 以及运用人类的语言, 实现机器语言和人类语言之间的沟通桥梁. 词向量 我们先来说说词向量究竟是什么. 当我们把文本交给算法来处理的时候, 计算机并不能理解我们输入的文本, 词向量就由此而生了.
-
Python机器学习pytorch模型选择及欠拟合和过拟合详解
目录 训练误差和泛化误差 模型复杂性 模型选择 验证集 K折交叉验证 欠拟合还是过拟合? 模型复杂性 数据集大小 训练误差和泛化误差 训练误差是指,我们的模型在训练数据集上计算得到的误差. 泛化误差是指,我们将模型应用在同样从原始样本的分布中抽取的无限多的数据样本时,我们模型误差的期望. 在实际中,我们只能通过将模型应用于一个独立的测试集来估计泛化误差,该测试集由随机选取的.未曾在训练集中出现的数据样本构成. 模型复杂性 在本节中将重点介绍几个倾向于影响模型泛化的因素: 可调整参数的数量.当可调
-
Python机器学习应用之支持向量机的分类预测篇
目录 1.Question? 2.Answer!——SVM 3.软间隔 4.超平面 支持向量机常用于数据分类,也可以用于数据的回归预测 1.Question? 我们经常会遇到这样的问题,给你一些属于两个类别的数据(如子图1),需要一个线性分类器将这些数据分开,有很多分法(如子图2),现在有一个问题,两个分类器,哪一个更好?为了判断好坏,我们需要引入一个准则:好的分类器不仅仅能够很好的分开已有的数据集,还能对为知的数据进行两个划分,假设现在有一个属于红色数据点的新数据(如子图3中的绿三角),可以看
-
Python机器学习应用之基于线性判别模型的分类篇详解
目录 一.Introduction 1 LDA的优点 2 LDA的缺点 3 LDA在模式识别领域与自然语言处理领域的区别 二.Demo 三.基于LDA 手写数字的分类 四.小结 一.Introduction 线性判别模型(LDA)在模式识别领域(比如人脸识别等图形图像识别领域)中有非常广泛的应用.LDA是一种监督学习的降维技术,也就是说它的数据集的每个样本是有类别输出的.这点和PCA不同.PCA是不考虑样本类别输出的无监督降维技术. LDA的思想可以用一句话概括,就是"投影后类内方差最小,类间方
-
Python机器学习入门(四)之Python选择模型
目录 1.数据分离与验证 1.1分离训练数据集和评估数据集 1.2K折交叉验证分离 1.3弃一交叉验证分离 1.4重复随机分离评估数据集与训练数据集 2.算法评估 2.1分类算法评估 2.1.1分类准确度 2.1.2分类报告 2.2回归算法评估 2.2.1平均绝对误差 2.2.2均方误差 2.2.3判定系数() 1.数据分离与验证 要知道算法模型对未知的数据表现如何,最好的评估办法是利用已经明确知道结果的数据运行生成的算法模型进行验证.此外还可以使用新的数据来评估算法模型. 在评估机器学习算法时