使用Phantomjs和Node完成网页的截屏快照的方法
由于甲方爸爸的需要,最近使用phantomjs和Node写了一个对网页内容截屏的功能,为了避免忘记,现在将代码内容及配置流程大概描述一下.
1.首先Node是必须安装的,而且网上安装教程一大堆,在此不再赘述,Nodejs官网链接
2.然后,第二个主人公是phantomjs,官网下载地址,选择对应的系统下载对应的安装包
3.将phantomjs配置为系统变量,下面是Windows配置为环境变量:
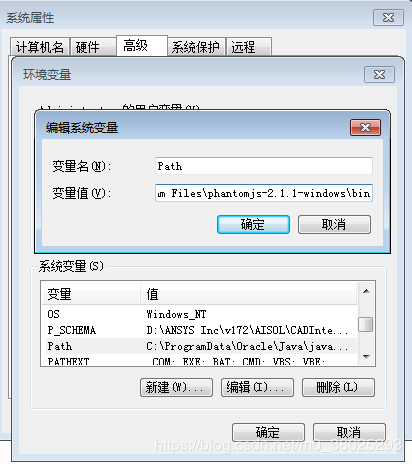
配置完成之后,在cmd命令行中输入 phantomjs -v 检验是否配置成功,配置成功之后,如下图所示:
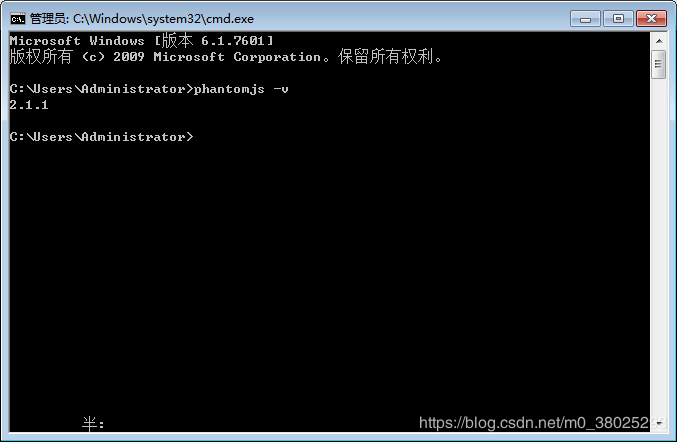
4.撸代码,通过查阅phantomjs入门代码之后,了解到使用phantomjs可以预览一个网页生成图片,PDF,base64格式等等,而我们的项目需要的并不是一个完整的网页,而是网页中的一部分内容,所以在此基础之上要改造部门内容,现在讲解一下代码:
4.1)首先是express的一些设置,由于需要执行phantomjs的命令,所以需要引入child_process模块,具体代码如下:
var process = require('child_process');//执行命令行所需
var express = require('express');//express
var bodyParser = require('body-parser');
var fs = require("fs");//文件操作
var app = express();
app.use('/pages',express.static('pdfs'));//设置静态资源目录
app.use(bodyParser.json({limit:'50mb'}));//请求内容大小限制
app.use(bodyParser.urlencoded({limit:'50mb',extended:false}));
//设置允许跨域访问
var allowCrossDomain = function(req, res, next) {
res.header('Access-Control-Allow-Origin', '*');
res.header('Access-Control-Allow-Methods', 'GET,PUT,POST,DELETE');
res.header('Access-Control-Allow-Headers', 'Content-Type');
res.header('Access-Control-Allow-Credentials','true');
next();
};
app.use(allowCrossDomain);
4.2)然后就是生成页面的base64接口的方法,如下:
app.get('/getBase64',function(req,res){
var url=req.query.url;//读取请求中的url参数,然后访问这个url
url=url.replace(/&/g,'%26');//将请求中的&转换
var resp={
"status":'200'
}
res.writeHead(200,{'Content-Type':'text/html;charset=utf-8'});//设置响应头
if(url==''){
resp.msg='url参数不能为空';
res.end(JSON.stringify(resp));
}
else{
//phantomjs执行的命令行 index.js在后文中给出
var strShell='phantomjs --disk-cache=true --disk-cache-path=. index.js '+url;
process.exec(strShell,{
maxBuffer:5000*1024,
},function(error,stdout,strerr){
if(error!==null){
console.log(error);
resp.msg='转换失败,稍后重试';
res.end(JSON.stringify(resp));
}else{
//执行成功则返回base64的数据
resp.data=stdout;
res.end(JSON.stringify(resp));
}
})
}
})
4.3)phantomjs执行的脚本,即index.js,如下:
var page = require('webpage').create();//获取webpage
var system = require('system'),
address;
if (system.args.length === 1) {//执行的命令应该包括请求的URL,否则退出phantom
console.log('Usage: URL error');
phantom.exit();
}
address = system.args[1];//请求的地址
address = address.replace(/%26/g, '&');//phantom不能识别%26,所以转为&
page.viewportSize = {//设置viewport
width: 1920,
height: 1080,
}
page.open(address, function(status) {//打开页面
setTimeout(function() {//2s之后获取base64结果,如果直接生成有可能页面还没有加载完成
if (status == 'success') {
var base64 = page.renderBase64('PNG');
console.log(base64);//将base64结果输出之后,在上边的getBase64接口中获取
phantom.exit();
}
}, 2000);
})
4.4)获取页面中部分内容的截图,可以将需要截图的DOM字符串,发送至后台,然后新建一个空的页面,使用phantom访问该空白页面,并将DOM字符串添加到预览的页面,然后生成截图,具体代码如下:
app.post('/getPartPage', function(req, res) {
var xmlObj = req.body.xmlObj;//获取DOM字符串
const reqUrl = 'http:example.com/tmp.html';//要访问的空页面
var response = {
"status": '200',
};
if (xmlObj == undefined || xmlObj == '' || xmlObj == null) {
response.msg = 'DOM字符串内容未输入';
res.end(JSON.stringify(response));
}else {
fs.writeFile('tmp.txt', xmlObj, function(err) { //由于dom字符串内容过多,所以写入txt文本
if (err) {
response.msg = '生成页面失败,请稍后重试';
return res.end(JSON.stringify(response));
}
var strShell = 'phantomjs pages/index.js ' + reqUrl;//phantomjs执行的命令
process.exec(strShell, {
maxBuffer: 5000 * 1024,
}, function(error, stdout, strerr) {
if (error !== null) {
response.msg = '脚本执行错误,请稍后重试';
res.end(JSON.stringify(response));
} else {
response.data = stdout.replace("\r\n", "");
res.end(JSON.stringify(response));//返回结果
}
})
})
}
})
var server = app.listen(8808,function(){ //接口监听,访问的端口
var host = server.address().address
var port = server.address().port
console.log('http://%s:%s',host,port);
})
4.5)pages下的index.js内容如下所示:
var page = require('webpage').create();//获取webpage
var fs = require('fs');
var system = require('system'),
address,filename;
if (system.args.length === 1) {
console.log('Usage: URL error');
phantom.exit();
}
address = system.args[1];//请求的路径
address = address.replace(/%26/g, '&');
filename = (new Data()).getTime();
page.viewportSize = {
width: 750,
}
page.paperSize = { //生成A4大小的PDF文件
format: 'A4',
orientation: 'portrait',
margin: '0.8cm'
}
page.open(address, function(status) {
var info = fs.read('tmp.txt');//读取DOM字符串
var result = page.evaluate(function(info) {
try {
document.querySelector('#dom').innerHTML = info;//将dom字符串拼接
} catch (e) {
console.log(e);
}
return document.querySelector('#dom').innerHTML;//返回页面
}, info);
setTimeout(function() {
page.paperSize = {
format: 'A4',
orientation: 'portrait',
margin: '0.8cm'
};
page.viewportSize = {
width: 750,
};
//生成PDF文件
page.render('pages/' + filename + '.pdf', { format: 'pdf', quality: '100' });
console.log('http://example.com/pages/' + filename + '.pdf');//返回PDF文件的访问路径
phantom.exit();
}, 500);
})
OK,以上就是全部接口的内容,全部的代码可以访问https://github.com/kim095/node-phantom进行下载.希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

利用NodeJS和PhantomJS抓取网站页面信息以及网站截图
利用PhantomJS做网页截图经济适用,但其API较少,做其他功能就比较吃力了.例如,其自带的Web Server Mongoose最高只能同时支持10个请求,指望他能独立成为一个服务是不怎么实际的.所以这里需要另一个语言来支撑服务,这里选用NodeJS来完成. 安装PhantomJS 首先,去PhantomJS官网下载对应平台的版本,或者下载源代码自行编译.然后将PhantomJS配置进环境变量,输入 $ phantomjs 如果有反应,那么就可以进行下一步了. 利用PhantomJS进行简
-
Node.JS利用PhantomJs抓取网页入门教程
前言 当想用 nodejs 抓取一些网页 , 我第一反应想到的就是使用 http 模块 , 比如抓取百度首页: var http = require('http'); var req = http.request('http://www.baidu.com/', function (res) { res.setEncoding('utf8'); res.on('data', function (chunk) { //响应内容 console.log(chunk) }); }); req.end(
-
Nodejs中使用phantom将html转为pdf或图片格式的方法
最近在项目中遇到需要把html页面转换为pdf的需求,并且转换成的pdf文件要保留原有html的样式和图片.也就是说,html页面的图片.表格.样式等都需要完整的保存下来. 最初找到三种方法来实现这个需求,这三种方法都只是粗浅的看了使用方法,从而找出适合这个需求的方案: html-pdf 模块 wkhtmltopdf 工具 phantom 模块 最终使用了phantom模块,也达到了预期效果.现在简单的记录三种方式的使用方法,以及三者之间主要的不同之处. 1.html-pdf github:ht
-
nodejs通过phantomjs实现下载网页
功能其实很见简单,通过 phantomjs.exe 采集 url 加载的资源,通过子进程的方式,启动nodejs 加载所有的资源,对于css的资源,匹配css内容,下载里面的url资源 当然功能还是很简单的,在响应式设计和异步加载的情况下,还是有很多资源没有能够下载,需要根据实际情况处理下 首先当然是下载 nodejs 和 phantomjs 下面是 phantomjs.exe 执行的 down.js var page = require('webpage').create(), system
-
使用Phantomjs和Node完成网页的截屏快照的方法
由于甲方爸爸的需要,最近使用phantomjs和Node写了一个对网页内容截屏的功能,为了避免忘记,现在将代码内容及配置流程大概描述一下. 1.首先Node是必须安装的,而且网上安装教程一大堆,在此不再赘述,Nodejs官网链接 2.然后,第二个主人公是phantomjs,官网下载地址,选择对应的系统下载对应的安装包 3.将phantomjs配置为系统变量,下面是Windows配置为环境变量: 配置完成之后,在cmd命令行中输入 phantomjs -v 检验是否配置成功,配置成功之后,如下图所
-
Android Activity 不能被截屏的解决方法
在Activity 添加即可 getWindow().addFlags(WindowManager.LayoutParams.FLAG_SECURE); 以上这篇Android Activity 不能被截屏的解决方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们. 您可能感兴趣的文章: Android截屏方案实现原理解析 Android截屏分享功能 Android 下调试手机截屏的方法 Android 实现截屏功能的实例 android长截屏原理及实现代码 Andr
-
Python实现截屏的函数
本文实例讲述了Python实现截屏的函数.分享给大家供大家参考.具体如下: 1.可指定保存目录. 2.截屏图片名字以时间为文件名 3.截屏图片存为JPG格式图片,比BMP小多的,一个1024*800的截屏BMP有3M多,一个1024*800的JPG只有300K左右. 就可做一个简单的监控了,每10秒截一屏,放到一个指定隐藏的文件夹里,基本掌握机子的使用了,适合监控自家小孩的使用情况 # -*- coding: cp936 -*- import time,Image import os, win3
-
详解Android截屏事件监听
1. 前言 Android系统没有直接对截屏事件监听的接口,也没有广播,只能自己动手来丰衣足食,一般有三种方法. 利用FileObserver监听某个目录中资源变化情况 利用ContentObserver监听全部资源的变化 监听截屏快捷按键 由于厂商自定义Android系统的多样性,再加上快捷键的不同以及第三方应用,监听截屏快捷键这事基本不靠谱,可以直接忽略. 本文使用的测试手机,一加2(One Plus 2). 2. FileObserver 添加权限: <uses-permission an
-
Android截屏分享功能
最近项目需要实现Android截屏分享功能,包括Android截屏获取图片.将图片保存到本地.通知系统相册更新.通过微信.QQ.微博分享截屏图片,本篇文章作为总结回顾. 一.Android截屏获取图片 通过对view进行绘制,得到bitmap,可以对Activity.Fragment进行绘制,也可以对其他的View进行绘制. 1 Activity截图(带空白的状态栏) public Bitmap shotScreen(Activity activity) { View view =
-
Android截屏方案实现原理解析
Android截屏的原理:获取具体需要截屏的区域的Bitmap,然后绘制在画布上,保存为图片后进行分享或者其它用途 在截屏功能中,有时需要截取全屏的内容,有时需要截取超过一屏的内容(比如:Listview,Scrollview,RecyclerView).下面介绍各种场景获取Bitmap的方法 普通截屏的实现 获取当前Window的DrawingCache的方式,即decorView的DrawingCache /** * shot the current screen ,with the sta
-
Android利用反射机制调用截屏方法和获取屏幕宽高的方法
想要在应用中进行截屏,可以直接调用 View 的 getDrawingCache 方法,但是这个方法截图的话是没有状态栏的,想要整屏截图就要自己来实现了. 还有一个方法可以调用系统隐藏的 screenshot 方法,来进行截屏,这种方法截图是整屏的. 通过调用 SurfaceControl.screenshot() / Surface.screenshot() 截屏,在 API Level 大于 17 使用 SurfaceControl ,小于等于 17 使用 Surface,但是 screen
-
Python使用Phantomjs截屏网页的方法
实例如下所示: #!/usr/bin/python # -*- coding:utf8 -*- from selenium import webdriver import os driver1 = webdriver.PhantomJS(executable_path='/usr/local/bin/phantomjs') driver1.get("http://www.csdn.net") data = driver1.title driver1.save_screenshot('c
-
Java实现的简单网页截屏功能示例
本文实例讲述了Java实现的简单网页截屏功能.分享给大家供大家参考,具体如下: package awtDemo; import java.awt.AWTException; import java.awt.Desktop; import java.awt.Dimension; import java.awt.Graphics; import java.awt.Image; import java.awt.Rectangle; import java.awt.Robot; import java.
-
js利用clipboardData实现截屏粘贴功能
本文实例为大家分享了clipboardData截屏粘贴实现代码,供大家参考,具体内容如下 <!DOCTYPE html> <html> <head lang="en"> <meta charset="UTF-8"> <title>copyimg</title> <style type="text/css"> #box{ width:200px; height:20