Go 数据结构之堆排序示例详解
目录
- 堆排序
- 堆排序过程
- 动画显示
- 开始堆排序
- 代码实现
- 总结
堆排序
堆排序是一种树形选择排序算法。
简单选择排序算法每次选择一个关键字最小的记录需要 O(n) 的时间,而堆排序选择一个关键字最小的记录需要 O(nlogn)的时间。
堆可以看作一棵完全二叉树的顺序存储结构。
在这棵完全二叉树中,如果每个节点的值都大于等于左边孩子的值,称为大根堆(最大堆、又叫大顶堆)。如果每个节点的值都小于等于左边孩子的值,称为小根堆(最小堆,小顶堆)。
可以,用数学符号表示如下:

堆排序过程
- 构建初始堆
- 在输出堆的顶层元素后,从上到下进行调整,将顶层元素与其左右子树的根节点进行比较,并将最小的元素交换到堆的顶部;然后不断调整直到叶子节点得到新的堆。
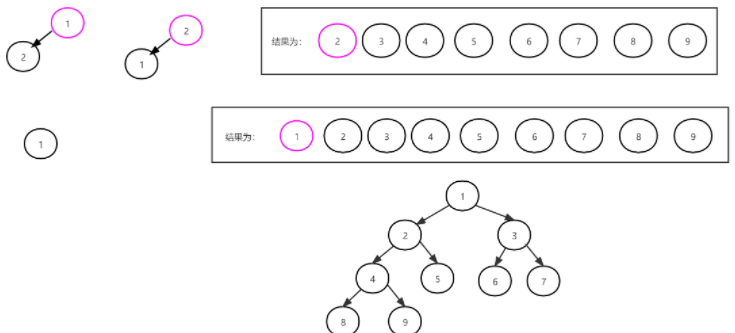
假如,{1, 7, 9, 2, 4, 6, 3, 5, 8} 建堆,然后进行堆排序输出。
动画显示
- 初始化堆,建堆操作图画演示:
首先根据无序序列 {1, 7, 9, 2, 4, 6, 3, 5, 8} 按照完全二叉树的顺序构建一棵完全二叉树,如图:

然后从最后一个分支节点 n/2开始调整堆,这里 9 / 2 = 4:

然后从 n/2−1 开始调整,即序号 3 开始调整,接着从 n/2-2 执行调整操作,如图所示:
一直重复到序号为 1 的节点:

最终通过此次调整堆,得到新的堆为 [9, 8, 6, 7, 4, 1, 3, 5, 2] ,得到新的堆后开始堆排序过程
开始堆排序
构建完初始堆后,此时,我们可以进入堆排序,从上面的方法中,
我们可以已知我们构建的最大堆的堆顶是最大的记录,可以可以将堆顶交换到最后一个元素的位置,然后执行堆顶下沉操作,然后再执行堆调整操作(新的堆顶也是最大值),直到剩余一个节点,得到一个有序序列。

此时,我们又可以进行堆调整操作,如下图:

堆调整完毕,开始把新的堆顶 8 和最后一个记录 2 进行交换,然后将堆顶下沉,调整为堆,如下图所示:

从此我们得到新的堆顶 7 ,然后把 7 跟最后一个元素 3 进行交换,7 下沉,然后堆调整,慢慢得到堆顶 6 和 堆顶5,如图所示:

然后是 3 下沉:

最后,堆顶 2 与最后一个记录 1 进行交换,只剩一个节点,堆排序结束,如下图所示:
我们得到的新的序列按序号读取数据,就是一个有序序列。
代码实现
最后,我们用代码来检验一下我们的动画过程是否正确,如下:
package main
import "fmt"
// 调整堆
func adjustHeap(array []int, currentIndex int, maxLength int) {
var noLeafValue = array[currentIndex] // 当前非叶子节点
// j 指向左孩子
// 当前非叶子节点的左节点为:2 * currentIndex + 1
for j := 2*currentIndex + 1; j <= maxLength; j = currentIndex*2 + 1 {
if j < maxLength && array[j] < array[j+1] { // 如果有右孩子,且左孩子比右孩子小
j++ // j 指向右孩子
}
if noLeafValue >= array[j] {
break // 非叶子节点大于孩子节点,跳过不交换
}
array[currentIndex] = array[j] // 移动到当前节点的父节点
currentIndex = j // j 指向交换后的新位置,继续向下比较
}
array[currentIndex] = noLeafValue // 放在合适的位置
}
// 初始化堆
func createHeap(array []int, length int) {
// 建堆
for i := length / 2; i >= 0; i-- {
adjustHeap(array, i, length-1)
}
}
func heapSort(array []int, length int) {
for i := length - 1; i > 0; i-- {
array[0], array[i] = array[i], array[0]
adjustHeap(array, 0, i-1)
}
}
func main() {
var unsorted = []int{1, 7, 9, 2, 4, 6, 3, 5, 8}
var length = len(unsorted)
fmt.Println("建堆之前:")
for i := 0; i < length; i++ {
fmt.Printf("%d,", unsorted[i])
}
fmt.Println()
fmt.Println("建堆之后:")
createHeap(unsorted, length)
for i := 0; i < length; i++ {
fmt.Printf("%d,", unsorted[i])
}
fmt.Printf("\n堆排序之后: \n")
heapSort(unsorted, length)
for i := 0; i < length; i++ {
fmt.Printf("%d,", unsorted[i])
}
}
运行结果:
[Running] go run "e:\Coding Workspaces\LearningGoTheEasiestWay\Go 数据结构\堆排序\main.go"
建堆之前:
1,7,9,2,4,6,3,5,8,
建堆之后:
9,8,6,7,4,1,3,5,2,
堆排序之后:
1,2,3,4,5,6,7,8,9,
可以看到,创建堆的结果 9,8,6,7,4,1,3,5,2 和排序结果 1,2,3,4,5,6,7,8,9 都是和我们图中的堆一样,所以说图看懂了代码也就变得有意思了。
总结
总结一下堆排序的复杂度:
时间复杂度:堆排序主要耗费时间在初始堆和反复调整堆上,所以时间复杂度为 O(nlogn)O(nlogn)O(nlogn)
空间复杂度:交换记录需要一个辅助空间,所以空间复杂度为 O(1)O(1)O(1)
稳定性:堆排序多次交换关键字,可能会发生相等关键字排序前后位置不一样的情况,所以不稳定
推荐大家都自己画图体验一下堆排序的过程,这中间设计除了涉及到算法的精妙,也能体会到二叉树的遍历过程。
以上就是Go 数据结构之堆排序示例详解的详细内容,更多关于Go 数据结构堆排序的资料请关注我们其它相关文章!
相关推荐
-
使用go实现常见的数据结构
1 golang常见数据结构实现 1.1 链表 举单链表的例子,双向链表同理只是多了pre指针. 定义单链表结构: type LinkNode struct { Data int64 NextNode *LinkNode } 构造链表及打印链表: func main() { node := new(LinkNode) node.Data = 1 node1 := new(LinkNode) node1.Data = 2 node.NextNode = node1 // node1 链接到 nod
-

Go语言数据结构之希尔排序示例详解
目录 希尔排序 算法思想 图解算法 Go 代码实现: 总结 希尔排序 在插入排序中,在待排序序列的记录个数比较少,而且基本有序,则排序的效率较高. 1959 年,Donald Shell 从“减少记录个数” 和 “基本有序” 两个方面对直接插入排序进行了改进,提出了希尔排序算法. 希尔排序又称为“缩小增量排序”.即将待排序记录按下标的一定增量分组(减少记录个数),对每组记录使用直接插入排序算法排序(达到基本有序): 随着增量逐渐减少,每组包含的关键词越来越多,当增量减至1,整个序列基本有序,再对
-
Go语言数据结构之插入排序示例详解
目录 插入排序 动画演示 Go 代码实现 总结 插入排序 插入排序,英文名(insertion sort)是一种简单且有效的比较排序算法. 思想: 在每次迭代过程中算法随机地从输入序列中移除一个元素,并将改元素插入待排序序列的正确位置.重复该过程,直到所有输入元素都被选择一次,排序结束. 插入排序有点像小时候我们抓扑克牌的方式,如果抓起一张牌,我们放在手里:抓起第二张的时候,会跟手里的第一张牌进行比较,比手里的第一张牌小放在左边,否则,放在右边. 因此,对所有的牌重复这样的操作,所以每一次都是插
-
go语言数据结构之前缀树Trie
目录 介绍 流程 代码 初始化 插入 查找 统计以XXX开头的单词个数 删除数据 介绍 Trie树:又称为单词查找树,是一种树形结构,可以应用于统计字符串,会在搜索引擎系统中用于对文本的词频统计,下图是一个Trie树的结构,同时它也是在插入数时的一个顺序图. 流程 首先应该先创建一个结构体,里面保存的是每一个节点的信息 初始化根节点,根节点应该初始化啥?啥也不用初始化,给个空就好看上图 插入:串转字符数组:遍历数组,如果下一个节点为空,创建,则继续遍历 查找:串转字符数组,遍历如何所有字符都在树
-
Go语言数据结构之选择排序示例详解
目录 选择排序 动画演示 Go 代码实现 总结 选择排序 选择排序(selection sort)是一种原地(in-place)排序算法,适用于数据量较少的情况.由于选择操作是基于键值的且交换操作只在需要时才执行,所以选择排序长用于数值较大和键值较小的文件. 思想: 对一个数组进行排序,从未排序的部分反复找到最小的元素,并将其放在开头. 给定长度为 nnn 的序列和位置索引i=0 的数组,选择排序将: 遍历一遍序列,寻找序列中的最小值.在 [i...n−1] 范围内找出最小值 minValue
-
Go语言的数据结构转JSON
目录 结构体转为 JSON 格式 接口转为 JSON 格式 Marshal() 函数的原型 总结 在日常工作中,除了需要从 JSON 转化为 Go 的数据结构.但往往相反的情况是:我们需要将数据以 JSON 字符串的形式发送到 Web 服务器.今天我们将学会如何从一个结构化数据编码为 JSON . Json(Javascript Object Nanotation)是一种数据交换格式,常用于前后端数据传输.任意一端将数据转换成json 字符串,另一端再将该字符串解析成相应的数据结构,如strin
-
Go 数据结构之堆排序示例详解
目录 堆排序 堆排序过程 动画显示 开始堆排序 代码实现 总结 堆排序 堆排序是一种树形选择排序算法. 简单选择排序算法每次选择一个关键字最小的记录需要 O(n) 的时间,而堆排序选择一个关键字最小的记录需要 O(nlogn)的时间. 堆可以看作一棵完全二叉树的顺序存储结构. 在这棵完全二叉树中,如果每个节点的值都大于等于左边孩子的值,称为大根堆(最大堆.又叫大顶堆).如果每个节点的值都小于等于左边孩子的值,称为小根堆(最小堆,小顶堆). 可以,用数学符号表示如下: 堆排序过程 构建初始堆 在输
-
java数据结构图论霍夫曼树及其编码示例详解
目录 霍夫曼树 一.基本介绍 二.霍夫曼树几个重要概念和举例说明 构成霍夫曼树的步骤 霍夫曼编码 一.基本介绍 二.原理剖析 注意: 霍夫曼编码压缩文件注意事项 霍夫曼树 一.基本介绍 二.霍夫曼树几个重要概念和举例说明 构成霍夫曼树的步骤 举例:以arr = {1 3 6 7 8 13 29} public class HuffmanTree { public static void main(String[] args) { int[] arr = { 13, 7, 8
-
C语言数据结构顺序表中的增删改(头插头删)教程示例详解
目录 头插操作 头删操作 小结 头插操作 继上一章内容(C语言数据结构顺序表中的增删改教程示例详解),继续讲讲顺序表的基础操作. 和尾插不一样,尾插出手阔绰直接的开空间,咱头插能开吗?好像没听说过哪个接口可以在数据前面开一片空间吧,那我们思路就只有一个了——挪数据.那应该从第一位开始挪吗?注意,这和 memcpy 函数机制是一样的,并不意味着后面数据一起挪动,也不会彼此独立,而是相互影响,挪动的数据会对后面数据进行覆盖. 那我们的逻辑就应该是从后往前挪,那我们就直接定一个下标,指向这段空间的最后
-
java数据结构算法稀疏数组示例详解
目录 一.什么是稀疏数组 二.场景用法 1.二维数组转稀疏数组思路 2.稀疏数组转二维数组思路 3.代码实现 一.什么是稀疏数组 当一个数组a中大部分元素为0,或者为同一个值,那么可以用稀疏数组b来保存数组a. 首先,稀疏数组是一个数组,然后以一种特定的方式来保存上述的数组a,具体处理方法: 记录数组a一共有几行几列 记录a中有多少个不同的值 最后记录不同值的元素所在行列,以及具体的值,放在一个小规模的数组里,以缩小程序的规模. 这个小规模的数组,就是稀疏数组. 举个栗子,左侧是一个二维数组,一
-
Java 数据结构算法Collection接口迭代器示例详解
目录 Java合集框架 Collection接口 迭代器 Java合集框架 数据结构是以某种形式将数据组织在一起的合集(collection).数据结构不仅存储数据,还支持访问和处理数据的操作 在面向对象的思想里,一种数据结构也被认为是一个容器(container)或者容器对象(container object),它是一个能存储其他对象的对象,这里的其他对象常被称为数据或者元素 定义一种数据结构从实质上讲就是定义一个类.数据结构类应该使用数据域存储数据,并提供方法支持查找.插入和删除等操作 Ja
-
数据结构TypeScript之邻接表实现示例详解
目录 图的结构特点 图的分类 图的表示 面向对象方法封装邻接表 构造函数 增加顶点和边 删除顶点和边 图的遍历 颜色标记 广度优先搜索(队列) 深度优先搜索(栈) 图的结构特点 图由顶点和顶点之间的边构成,记为G(V, E).其中V是顶点集合,E是边集合.作为一种非线性的数据结构,顶点之间存在多对多关系. 图的分类 无向图:两个顶点之间有两条互相关联的边.A和B之间为双向互通. 有向图:两个顶点之间有一条或两条关联的边.从A到B或者从B到A,只能单向通过. 带权无向图:在无向图的基础上增加一个权
-
Golang实现数据结构Stack(堆栈)的示例详解
目录 前言 介绍Stack Stack Push Pop Peek Len & Cap & Clear NewStack 使用 前言 始于此篇,为了学习 Golang 基础,采用了使用 Golang 实现各种数据结构,以此来和 Golang 交朋友,今天的主题就是 把Stack介绍给Golang认识 源码:Stack 介绍Stack 在计算机科学中,stack(栈)是一种基本的数据结构,它是一种线性结构,具有后进先出(Last In First Out)的特点. 上述是通过对 ChatGP