使用Python对EXCEL数据的预处理
一、熟悉数据
我们将EXCEL中的数据导入之后,需要对数据进行大致性的了解,当对数据充分地了解之后,才便于后期的分析工作。
该部分涉及到四个基本方法,分别为“shape”“info”“head”“describe”。下面会具体介绍四者的用法与功能。
以下是我准备好的一组简单的excel数据:
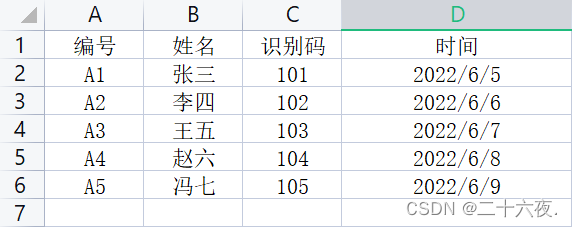
其中:“编号”“姓名”“识别码”“时间”称为索引列;左边的“1”“2”···“6”称为索引行。
通过第一篇的方法,将数据导入python中。代码与输出结果如下所示:
import pandas as pd df=pd.read_excel(r"D:\杂货\新编码.xlsx",sheet_name='Sheet1') print(df)

此部分不再详述,请见第一篇。
1.1 shape
在导入excel表格数据后,使用该方法可以查看该表格的数据一共有多少行多少列,并以元组的形式输出。需要表明的是,该方法输出的行数和列数不包括索引行和索引列。
代码与输出结果如下:
m=df.shape#输出导入的列表有多少行多少列 print(m)
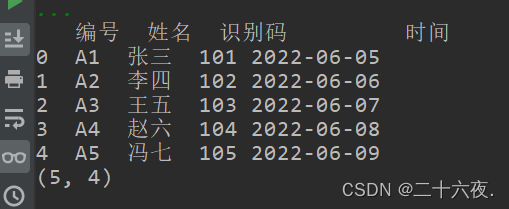
最下面的(5,4)即为该方法输出的结果,解释为5行4列。
1.2 info
该方法可以帮助我们查看所导入的每一列的数据类型,并且还能查看是否有缺省值。
代码与结果如下:
import pandas as pd df=pd.read_excel(r"D:\杂货\新编码.xlsx",sheet_name='Sheet1') df.info()#查看每一列的数据类型

从输出结果可以看到,Column一列显示为头部的名称,即为我们的索引列;Non-Null Count一列表示该列有几个非缺省值,5 non-null表示该列中的每一个单元格都有内容填入,没有缺省值;Dtype一列则为每一列的数据类型,分别为object,int64,datetime64[ns]类型。
1.3 head
该方法能够帮助我们预览表格的前几行的内容。
形式为:head()需要预览前面几行就在括号里填数字几。
代码与结果如下:
import pandas as pd df=pd.read_excel(r"D:\杂货\新编码.xlsx",sheet_name='Sheet1') n=df.head(1)#可选择预览前几行 k=df.head(2) j=df.head(3) print(n) print(k) print(j)

以上分别输出了前1行,前2行,前3行。
1.4 describe
该方法能够帮助我们查看某一列int64类型数据的个数、平均数、标准差、最大值、最小值、分位数。
代码与结果如下:
import pandas as pd df=pd.read_excel(r"D:\杂货\新编码.xlsx",sheet_name='Sheet1') i=df.describe()#可查看数据的基本情况,int64类型的数据 print(i)

由于只有“识别码”一列的数据为int64类型的数据,因此该方法最终输出的结果只有识别码的结果。
二、数据预处理
2.1 缺省值的处理
2.1.1 isnull()检查缺省值
首先我们要查看我们的数据里是否含有缺省值。在1.2部分已经介绍了使用info()方法查看缺省值,以下将介绍另一个检查缺省值的方法。代码与结果如下:
n=df.isnull()#true为缺省值print(n)

可以看到,False表示该单元格不是缺省值,若该单元格为缺省值,则结果会显示为True。
2.1.2 dropna()缺省值的删除
对于缺省值,我们可以选择删除它,代码与结果如下:
n=df.isnull()#true为缺省值 print(n)
上面介绍了两条代码,第一条从其注释可知道,当某一行存在一个单元格的内容为缺省值,那么无论其他单元格是否为缺省值,该行整行都会被删除;第二条代码的不同之处即在括号中有how='all',该方法下,只有当某一行的所有单元格皆为缺省值时,才会将该行整行删除,否则不会删除该行。
作为对比,我将一个单元格的内容删除。

输出后的内容可以看到,王五所对应的识别码为NaN,这就表示该单元格无内容,是空的,即所说的缺省值。
首先输出的是dropna(how='all')的结果:

可以看到,当只有王五的识别码为缺省值时,并没有删除该行。
接下来输出dropna()的结果:

可以看到,王五那一行因为有一个缺省值,整行都被删除掉了。
2.1.3 fillna()缺省值的填充
对于缺省值,我们也可以选择对其进行填充。
为了对比,我删除了两个单元格的值。

输出结果可知,姓名一列于识别码一列共有两个缺省值。
x=df.dropna()#只要带有缺省值就整行删除 print(x) y=df.dropna(how='all')#只删除整行是缺省值的行 print(y)
上面提供了两条代码,第一条代码表示将所有的缺省值都用“好”这个值填充,结果如下:

第二条代码为指定用某个值填充某一列的缺省部分,即将姓名一列的缺省部分都用“王五”填充,识别码一列的缺省部分都用“103”填充。结果如下:

2.2 重复值的处理
对于表单中出现的重复项,我们可以使用drop_duplicates()方法来保留其中一个。默认保留第一个值。
为了对比,将数据修改为以下形式:
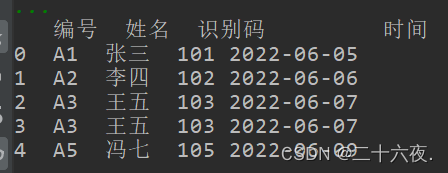
可以看到,此时有两行的内容是相同的。
接下来使用所介绍的方法来解决重复项的问题,代码与结果如下:
x=df.fillna("好")#填缺省值,括号里写要填入的值
print(x)
y=df.fillna({'姓名':'王五','识别码':'103'})#指定列填入值,且可以多列填写,但都写在同一个字典里
print(y)

首先来看代码的第一行,该方法的作用在其注释处已经说明,不再赘述,从其输出结果看,索引行为“3”的那一行“王五”重复项被删除了,只保留了索引行为“2”的那一行“王五”。
接着看第二行代码的结果:

其输出的结果其实和第一种是一样的,虽然结果一样,但是两者的目的是不一样的,第二行代码括号中写入了一个列表['姓名','识别码'],该列表达到的作用就是指明我们要删除的哪一列中存在的重复项,即是说:我想将“姓名”一列中的重复项和“识别码”一列中的重复项进行处理。在此我以两个列名作为示例,若只想按照一个列名来删除重复项的,则只需写入一个列名即可。
2.3 数据类型的转换
2.3.1 数据类型的查看
在前面已经介绍了使用info()方法查看数据类型,在此再介绍一种方法,代码与结果如下:
x=df['姓名'].dtype#针对查看某一列的数据类型print(x)

该方法是只能查看某一列的数据类型,只能查看一列,不能查看多列。只需将想查看的那一列的索引列名称写入中括号即可。最后输出结果可以看到“姓名”一列的数据类型为object。
2.3.2 数据类型的转换
这里我们使用的方法为astype()方法,首先查看原始数据中“识别码”的数据类型。

可以看到其数据类型为int64。
接下来我们来修改该列的数据类型为float64,代码与结果如下:
y=df['识别码'].astype('float64')print(y)
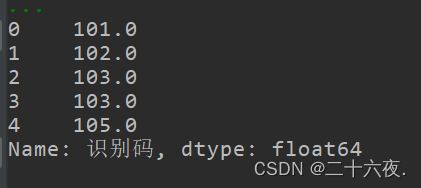
可以看到输出结果中识别码一列的数据有了小数点后一位,且其dtype显示为float64。
2.4 索引的设置
2.4.1 添加索引
索引的添加很简单,以下是索引列的添加(修改)代码与结果如下:
df.columns=['号编','名姓','码别识','间时']print(df)

可以看到,最上面的索引列名称被我替换掉了。
以下是索引行的添加(修改)。
df.index=['2','4','6','8','10']print(df)

可以看到,最左边的索引行名称被我改成了2,4,6,8,10。
需要注意的是,有多少行多少列就要添加多少行多少列的索引,不然会报错。
2.4.2 重新设置索引
我们还可以使用列表中的某一列数据作为索引。方法是set_index()。
代码与结果如下:
x=df.set_index("姓名")print(x)
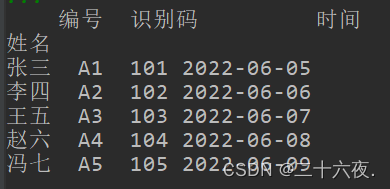
从结果可以看出,最左边的索引不再是数字,而成了姓名。
2.4.3 索引的重命名
针对重命名索引,有以下三种写法:
df.rename(columns={"原来的索引":"想要修改成的索引"}) 该方法只修改索引列的名称
df.rename(index={"原来的索引":"想要修改成的索引"}) 该方法只修改索引行的名称
df.rename(columns={"原来的索引":"想要修改成的索引"},index={"原来的索引":"想要修改成的索引"}) 该方法能同时修改索引列和索引行的名称
需要注意:该方法都使用了列表。代码与结果如下:
x=df.drop_duplicates()#对所有值进行重复值判断,并且默认保留第一个(行)值 y=df.drop_duplicates(subset=['姓名','识别码'])#只针对某一列或某几列进行重复值删除的判断。 print(x) print(y)

上面的结果可以看出,索引行与索引列都分别修改成功,成为我所想要修改的名称。
2.4.4 重置索引
该部分主要是针对层次化的excel表格使用,相对而言较为繁琐,在这里暂时不过多讲述,仅仅对方法进行展示。
x=df['姓名'].dtype#针对查看某一列的数据类型 print(x)
由于本人在使用该方法时无法成功重置,因此暂时不对该方法进行详解,待之后找到原因再详细介绍该方法。
三、结语
本篇内容较多,但仍然是基于已有的表格进行的一些基础操作,后期介绍会逐步深入。若有错误还请指出。
到此这篇关于使用Python处理EXCEL基础操作篇2Python对EXCEL数据的预处理的文章就介绍到这了,更多相关Python对EXCEL数据预处理内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
如何使用Python对Excel表格进行拼接合并
目录 准备工作 一.横向拼接 1.1 一般拼接 1.2 指定键进行拼接,即指定某一列作为两个表的连接依据. 1.2.1 多对一 1.2.2 多对多 1.2.3 用on来指定多个连接键 1.2.4 指定左右连接键 1.2.5 索引当作连接键 1.3 连接的方式 1.3.1 内连接(inner) 1.3.2 左连接(left) 1.3.3 右连接(right) 1.3.4 外连接(outer) 二.纵向拼接 2.1 普通合并 2.2 重叠数据的合并 三.整合代码 准备工作 我准备了两个表格数据,以此
-
14个Python处理Excel的常用操作分享
目录 一.关联公式:Vlookup 二.数据透视表 三.对比两列差异 四.去除重复值 五.缺失值处理 六.多条件筛选 七. 模糊筛选数据 八.分类汇总 九.条件计算 十.删除数据间的空格 十一.数据分列 十二.异常值替换 十三.分组 十四.根据业务逻辑定义标签 自从学了Python后就逼迫用Python来处理Excel,所有操作用Python实现.目的是巩固Python,与增强数据处理能力. 这也是我写这篇文章的初衷.废话不说了,直接进入正题. 数据是网上找到的销售数据,长这样: 一.关联公式:
-
Python+Requests+PyTest+Excel+Allure 接口自动化测试实战
Unittest是Python标准库中自带的单元测试框架,Unittest有时候也被称为PyUnit,就像JUnit是Java语言的标准单元测试框架一样,Unittest则是Python语言的标准单元测试框架. Pytest是Python的另一个第三方单元测试库.它的目的是让单元测试变得更容易,并且也能扩展到支持应用层面复杂的功能测试. 两者对比: Pytest项目实战: 第一步.搭建项目框架(创建Gwyc_Api_Script_Pytest项目目录) 依次创建子目录如下:base:存放一些最底
-
如何在Python中导入EXCEL数据
目录 一.前期准备 二.编写代码基本思路 三.编写代码读取数据 3.1 3.2 四.结语 一.前期准备 此篇使用两种导入excel数据的方式,形式上有差别,但两者的根本方法实际上是一样的. 首先需要安装两个模块,一个是pandas,另一个是xlrd. 在顶部菜单栏中点击文件,再点击设置,然后在设置中找到以下界面,并点击“+”号. 然后会出现以下界面,在搜索框中分别搜索以上两个模块:pandas/xlrd. 选中搜索出来的模块,并点击左下角的的安装按钮,便可将模块安装到自己电脑中. 需要注意的是,
-
Python Excel数据处理之xlrd/xlwt/xlutils模块详解
目录 1.模块说明 2.xlrd处理 3.xlwt处理 4.xlutils处理 常规的Excel数据处理中,就是对Excel数据文件的读/写/文件对象操作. 通过对应的python非标准库xlrd/xlwt/xlutils,来实现具体的数据处理业务逻辑. 在复杂的Excel业务数据处理中,三兄弟扮演的角色缺一不可.如何能够使用xlrd/xlwt/xlutils三个模块来实现数据处理就是今天的内容. 1.模块说明 使用该三个模块来处理Excel数据最好的地方就是他们和Excel文件对象对应的数据处
-
使用Python对EXCEL数据的预处理
一.熟悉数据 我们将EXCEL中的数据导入之后,需要对数据进行大致性的了解,当对数据充分地了解之后,才便于后期的分析工作. 该部分涉及到四个基本方法,分别为“shape”“info”“head”“describe”.下面会具体介绍四者的用法与功能. 以下是我准备好的一组简单的excel数据: 其中:“编号”“姓名”“识别码”“时间”称为索引列:左边的“1”“2”···“6”称为索引行. 通过第一篇的方法,将数据导入python中.代码与输出结果如下所示: import pandas as pd
-
Python修改Excel数据的实例代码
在前面的文章中介绍了如何用Python读写Excel数据,今天再介绍一下如何用Python修改Excel数据.需要用到xlutils模块.下载地址为https://pypi.python.org/pypi/xlutils.下载后执行python setup.py install命令进行安装即可.具体使用代码如下: 复制代码 代码如下: #-*-coding:utf-8-*-from xlutils.copy import copy # http://pypi.python.org/pypi
-
用Python将Excel数据导入到SQL Server的例子
使用环境:Win10 x64 Python:3.6.4 SqlServer:2008R2 因为近期需要将excel导入到SQL Server,但是使用的是其他语言,闲来无事就尝试着用python进行导入,速度还是挺快的,1w多条数据,也只用了1s多,代码也比较简单,就不多解释了. 用到的库有xlrd(用来处理excel),pymssql(用来连接使用sql server) import xlrd import pymssql import datetime # 连接本地sql server
-
python读取excel数据绘制简单曲线图的完整步骤记录
python读写excel文件有很多种方法: 用xlrd和xlwt进行excel读写 用openpyxl进行excel读写 用pandas进行excel读写 本文使用xlrd读取excel文件(xls,sxls格式),使用xlwt向excel写入数据 一.xlrd和xlwt的安装 安装很简单,windos+r调出运行窗口,输入cmd,进入命令行窗口,输入以下命令. 安装xlrd: pip install xlrd 安装xlwt: pip install xlwt xlrd的API(applica
-

python读取excel数据并且画图的实现示例
一,要读取的数据的格式: 二,数据读取部分: b站视频参考:https://www.bilibili.com/video/BV14C4y1W7Nj?t=148 # 1930 workbook=xlrd.open_workbook('1930.xlsx') sheet= workbook.sheet_by_index(0) A1=[] B1=[] # sheet.cell_value(i,0):第i行的第0个元素 for i in range(1,sheet.nrows): A1.append(s
-
Python读取Excel数据实现批量生成合同
目录 一.背景 二.准备 三.实战 1.安装相关库 2.读取合同数据 3.批量合同生成 大家好,我是J哥. 在我们的工作中,面临着大量的重复性工作,通过人工方式处理往往耗时耗力易出错.而Python在自动化办公方面具有极大的优势,可以解决我们工作中遇到的很多重复性问题,分分钟搞定办公需求. 一.背景 在我们经济交往中,有时会涉及到销售合同的批量制作.比如我们需要根据如下合同数据(Excel),进行批量生成销售合同(Word). 二.准备 我们首先要准备好一份合同模板(Word),将需要替换的合同
-
Python读取Excel数据实现批量生成PPT
目录 背景 需求 准备 PPT数据 PPT模板 实战 导入相关模块 读取电影数据 读取PPT模板插入数据 背景 大家好,我是J哥. 我们常常面临着大量的重复性工作,通过人工方式处理往往耗时耗力易出错.而Python在办公自动化方面具有天然优势,分分钟解决你的办公需求,提前下班不是梦. 需求 前几天我发表了一篇办公自动化文章Python读取Excel数据并批量生成合同,获得许多小伙伴的认可和喜欢.其中有一位粉丝提议,能否出一篇PPT自动化的教程,通过读取Excel数据批量生成幻灯片.于是,我以豆瓣
-
使用python将excel数据导入数据库过程详解
因为需要对数据处理,将excel数据导入到数据库,记录一下过程. 使用到的库:xlrd 和 pymysql (如果需要写到excel可以使用xlwt) 直接丢代码,使用python3,注释比较清楚. import xlrd import pymysql # import importlib # importlib.reload(sys) #出现呢reload错误使用 def open_excel(): try: book = xlrd.open_workbook("XX.xlsx")
-
python读写excel数据--pandas详解
目录 一.读写excel数据 1.1 读: 1.2写: 二.举例 2.1 要求 2.2 实现 总结 一.读写excel数据 利用pandas可以很方便的读写excel数据 1.1 读: data_in = pd.read_excel('M2FENZISHI.xlsx') 1.2写: 首先要创建数据框 # example df = pd.DataFrame({'A':[0,1,2]}) writer = pd.ExcelWriter('test.xlsx') #name of excel file
-
Python读取Excel数据并生成图表过程解析
一.需求背景 自己一直在做一个周基金定投模拟,每周需要添加一行数据,并生成图表.以前一直是用Excel实现的.但数据行多后,图表大小调整总是不太方便,一般只能通过缩放比例解决. 二.需求实现目标 通过Python程序读取Excel文件中的数据,生成图表,最好将生成图表生成至浏览器页面,后期数据多之后,也能自动缩放,而不会出现显示不全问题. 三.需求实现代码 # 调用本地echarts.min.js 文件 from pyecharts.globals import CurrentConfig Cu