Python sqlparse解析SQL表血缘追踪实现
目录
- 引言
- 一、主线任务
- 1.数据治理
- 2.血缘追踪
- 3.SQL表血缘
- 二、实现过程
- 1.目标效果
- 2.代码实现
- 1.功能函数识别
- 2.SQL标准格式
- 3.解析AST树
- 4.最终效果:
引言
SQLparse的开源库解析中就说过自己在寻找在python编程内可行的SQL血缘解析,JAVA去解析Hive的源码实践的话我还是打算放到后期来做,先把Python能够实现的先实现完。主要是HiveSQL的底层就是JAVA代码,怎么改写还是绕不开JAVA的。不过上篇系列我有提到过sqlparse,其实这个库用来解析血缘的话也不是不可以,但是能够实现的功能是有限的,目前我实验还行,一些较为复杂的SQL也能解析得出,算是成功达到可部署服务的水准了,但是根据SQL格式来匹配的话肯定是有些SQL格式不能完全匹配成功的,如果大家有需要血缘分析的SQL可以再次验证一下。
算是填完了之前的部分坑,目前的开发进度已经可以将SQL的表血缘分析追踪实现了,实现字段血缘的功能开发等后续将陆续上线。
一、主线任务
首先来对该项目的目标来分析一下,说到SQL血缘分析,这偏向于数据治理。
1.数据治理
数据治理(Data Governance)是组织中涉及数据使用的一整套管理行为。数据要产生价值,需要一个合理的“业务目标”,数据治理的所有活动应该围绕真实的业务目标而开展,建立数据标准、提升数据质量只是手段,而不是目标。
数据治理的本质是管理数据,因此需要加强元数据管理和主数据管理,从源头治理数据,补齐数据的相关属性和信息,比如:元数据、质量、安全、业务逻辑、血缘等,通过元数据驱动的方式管理数据生产、加工和使用。

数据的质量直接影响着数据的价值,并且直接影响着数据分析的结果以及我们以此做出的决策的质量。数据模型血缘与任务调度的一致性是建管一体化的关键,有助于解决数据管理与数据生产口径不一致的问题,避免出现双重管理不一致的低效管理模式。
2.血缘追踪
数据被业务场景使用时,发现数据错误,数据治理团队需要快速定位数据来源,修复数据错误。那么数据治理团队需要知道业务团队的数据来自于哪个核心库,核心库的数据又来自于哪个数据源头。我们的实践是在元数据和数据资源清单之间建立关联关系,且业务团队使用的数据项由元数据组合配置而来,这样,就建立了数据使用场景与数据源头之间的血缘关系。 数据资源目录:数据资源目录一般应用于数据共享的场景,例如部门之间的数据共享,数据资源目录是基于业务场景和行业规范而创建,同时依托于元数据和基础库主题而实现自动化的数据申请和使用。
也就是为什么我们需要解析SQL,追踪建表索引或者引用解析。
3.SQL表血缘
那么其中最重要的就是关于各个数据库之间的数据关系了,关于建表以及插入更新操作都会使数据发生一定的改变,那么这些操作就一定是被允许的?就像原来在网上看到的某某公司程序员删库跑路,或者是一不小心删错数据导致耽误产研线等等。为了防止以上事故的出现必定要为此操作上一层保险,为每个成员设定数据操作权限。这样以来提交的SQL语句就多了一层判断。
二、实现过程
1.目标效果
首先明白一点我们要做出的东西需要呈现一个怎样的形式,其中位于行业前排的无疑是SQLFlow:
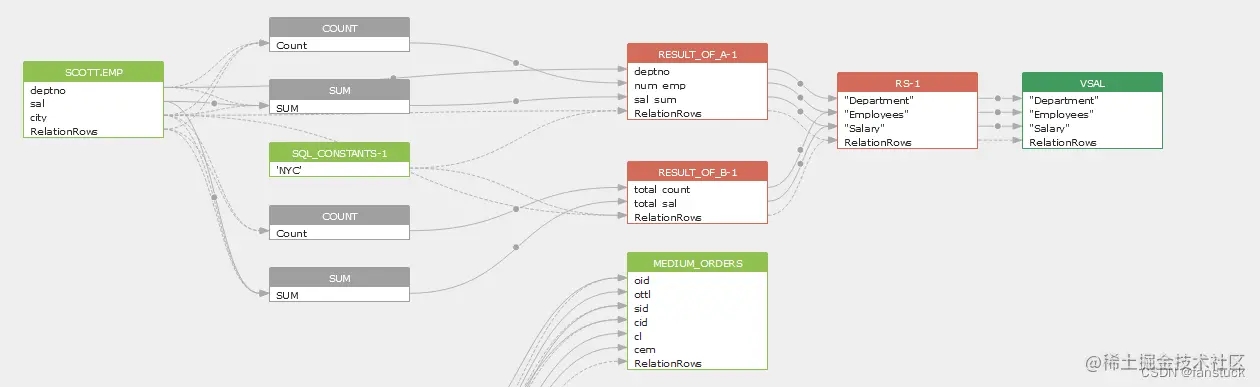
当第一次看到此图我就决定血缘追踪就应该是这个样子,能够清晰的解析出每个字段和表之间的血缘关系。以此我们设定输出的基准,我们要做的项目目标就是如此。

2.代码实现
1.功能函数识别
该功能也是必须要实现的功能,我们需要明白这个SQL主要是干什么事情的。如果是插入INSERT或者是CREATE就有血缘分析的必要,如果是SELECT的话那么做简单的SQL解析即可。有了研究sqlparse源码的成果我们调用相应的函数即可:
sql="select * from table1;insert into table select a,b,c from table2"
if __name__ == '__main__':
table_names=[]
#sql=get_sqlstr('read_sql.txt')
stmt_tuple=analysis_statements(sql)
for each_stmt in stmt_tuple:
type_name=get_main_functionsql(each_stmt)
print(type_name)
输出:

那么对于SELECT我们就SQL涉及到的表追溯即可:

对于CREATE和INSERT的做血缘即可:
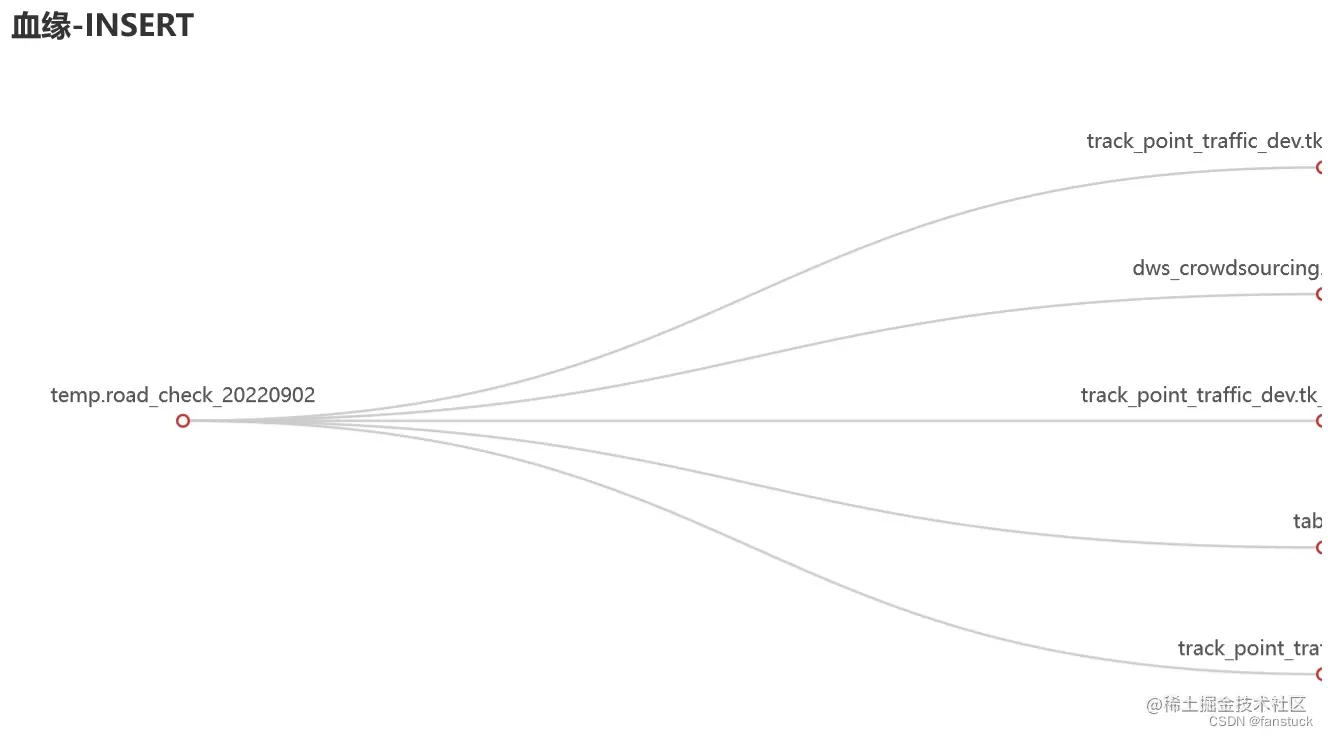
2.SQL标准格式
对于传入的SQL我们首先要让这条语句符合标准的SQL语句格式,这样对于传输格式保持一致,兼容很有作用。一般我们都是通过文本来读入。故需要读取文本做处理: 原始文本:

处理后:
if __name__ == '__main__':
sql=get_sqlstr('read_sql.txt')
print(sql)

3.解析AST树
得到的SQL无论是ANTRL还是SQLPARSE都是解析为一棵树的形式进行递归回溯。最终都要解析生产的SQL树:
sql="select * from table1;insert into table3 select a,b,c from table2"
if __name__ == '__main__':
#sql=get_sqlstr('read_sql.txt')
stmt_tuple=analysis_statements(sql)
for each_stmt in stmt_tuple:
table_names=[]
type_name=get_main_functionsql(each_stmt)
get_ASTTree(each_stmt)

4.最终效果:
SQL:
select
b.product_name "产品",
count(a.order_id) "订单量",
b.selling_price_max "销售价",
b.gross_profit_rate_max/100 "毛利率",
case when b.business_type =1 then '自营消化' when b.business_type =2 then '服务商消化' end "消化模式"
from(select 'CRM签单' label,date(d.update_ymd) close_ymd,c.product_name,c.product_id,
a.order_id,cast(a.recipient_amount as double) amt,d.cost
from mysql4.dataview_fenxiao.fx_order a
left join mysql4.dataview_fenxiao.fx_order_task b on a.order_id = b.order_id
left join mysql7.dataview_trade.ddc_product_info c on cast(c.product_id as varchar) = a.product_ids and c.snapshot_version = 'SELLING'
inner join (select t1.par_order_id,max(t1.update_ymd) update_ymd,
sum(case when t4.product2_type = 1 and t5.shop_id is not null then t5.price else t1.order_hosted_price end) cost
from hive.bdc_dwd.dw_mk_order t1
left join hive.bdc_dwd.dw_mk_order_status t2 on t1.order_id = t2.order_id and t2.acct_day = substring(cast(DATE_ADD('day',-1,CURRENT_DATE) as varchar),9,2)
left join mysql7.dataview_trade.mk_order_merchant t3 on t1.order_id = t3.order_id
left join mysql7.dataview_trade.ddc_product_info t4 on t4.product_id = t3.MERCHANT_ID and t4.snapshot_version = 'SELLING'
left join mysql4.dataview_scrm.sc_tprc_product_info t5 on t5.product_id = t4.product_id and t5.shop_id = t1.seller_id
where t1.acct_day = substring(cast(DATE_ADD('day',-1,CURRENT_DATE) as varchar),9,2)
and t2.valid_state in (100,200) ------有效订单
and t1.order_mode = 10 --------产品消耗订单
and t2.complete_state = 1 -----订单已经完成
group by t1.par_order_id
) d on d.par_order_id = b.task_order_id
where c.product_type = 0 and date(from_unixtime(a.last_recipient_time)) > date('2016-01-01') and a.payee_type <> 1 -----------已收款
UNION ALL
select '企业管家消耗' label,date(c.update_ymd) close_ymd,b.product_name,b.product_id,
a.task_id,(case when a.yb_price = 0 and b.product2_type = 1 then b.selling_price_min else a.yb_price end) amt,
(case when a.yb_price = 0 and b.product2_type = 2 then 0 when b.product2_type = 1 and e.shop_id is not null then e.price else c.order_hosted_price end) cost
from mysql8.dataview_tprc.tprc_task a
left join mysql7.dataview_trade.ddc_product_info b on a.product_id = b.product_id and b.snapshot_version = 'SELLING'
inner join hive.bdc_dwd.dw_mk_order c on a.order_id = c.order_id and c.acct_day = substring(cast(DATE_ADD('day',-1,CURRENT_DATE) as varchar),9,2)
left join hive.bdc_dwd.dw_mk_order_status d on d.order_id = c.order_id and d.acct_day = substring(cast(DATE_ADD('day',-1,CURRENT_DATE) as varchar),9,2)
left join mysql4.dataview_scrm.sc_tprc_product_info e on e.product_id = b.product_id and e.shop_id = c.seller_id
where d.valid_state in (100,200) and d.complete_state = 1 and c.order_mode = 10
union ALL
select '交易管理系统' label,date(t6.close_ymd) close_ymd,t4.product_name,t4.product_id,
t1.order_id,(t1.order_hosted_price-t1.order_refund_price) amt,
(case when t1.order_mode <> 11 then t7.user_amount when t1.order_mode = 11 and t4.product2_type = 1 and t5.shop_id is not null then t5.price else t8.cost end) cost
from hive.bdc_dwd.dw_mk_order t1
left join hive.bdc_dwd.dw_mk_order_business t2 on t1.order_id = t2.order_id and t2.acct_day=substring(cast(DATE_ADD('day',-1,CURRENT_DATE) as varchar),9,2)
left join mysql7.dataview_trade.mk_order_merchant t3 on t1.order_id = t3.order_id
left join mysql7.dataview_trade.ddc_product_info t4 on t4.product_id = t3.MERCHANT_ID and t4.snapshot_version = 'SELLING'
left join mysql4.dataview_scrm.sc_tprc_product_info t5 on t5.product_id = t4.product_id and t5.shop_id = t1.seller_id
left join hive.bdc_dwd.dw_fact_task_ss_daily t6 on t6.task_id = t2.task_id and t6.acct_time=date_format(date_add('day',-1,current_date),'%Y-%m-%d')
left join (select a.task_id,sum(a.user_amount) user_amount
from hive.bdc_dwd.dw_fn_deal_asyn_order a
where a.is_new=1 and a.service='Trade_Payment' and a.state=1 and a.acct_day=substring(cast(DATE_ADD('day',-1,CURRENT_DATE) as varchar),9,2)
group by a.task_id)t7 on t7.task_id = t2.task_id
left join (select t1.par_order_id,sum(t1.order_hosted_price - t1.order_refund_price) cost
from hive.bdc_dwd.dw_mk_order t1
where t1.acct_day = substring(cast(DATE_ADD('day',-1,CURRENT_DATE) as varchar),9,2) and t1.order_type = 1 and t1.order_stype = 4 and t1.order_mode = 12
group by t1.par_order_id) t8 on t1.order_id = t8.par_order_id
where t1.acct_day = substring(cast(DATE_ADD('day',-1,CURRENT_DATE) as varchar),9,2)
and t1.order_type = 1 and t1.order_stype in (4,5) and t1.order_mode <> 12 and t4.product_id is not null and t1.order_hosted_price > 0 and t6.is_deal = 1 and t6.close_ymd >= '2018-12-31'
)a
left join mysql7.dataview_trade.ddc_product_info b on a.product_id = b.product_id and b.snapshot_version = 'SELLING'
where b.product2_type = 1 -------标品
and close_ymd between DATE_ADD('day',-7,CURRENT_DATE) and DATE_ADD('day',-1,CURRENT_DATE)
GROUP BY b.product_name,
b.selling_price_max,
b.gross_profit_rate_max/100,
b.actrul_supply_num,
case when b.business_type =1 then '自营消化' when b.business_type =2 then '服务商消化' end
order by count(a.order_id) desc
limit 10
if __name__ == '__main__':
table_names=[]
sql=get_sqlstr('read_sql.txt')
stmt_tuple=analysis_statements(sql)
for each_stmt in stmt_tuple:
type_name=get_main_functionsql(each_stmt)
blood_table(each_stmt)
Tree_visus(table_names,type_name)
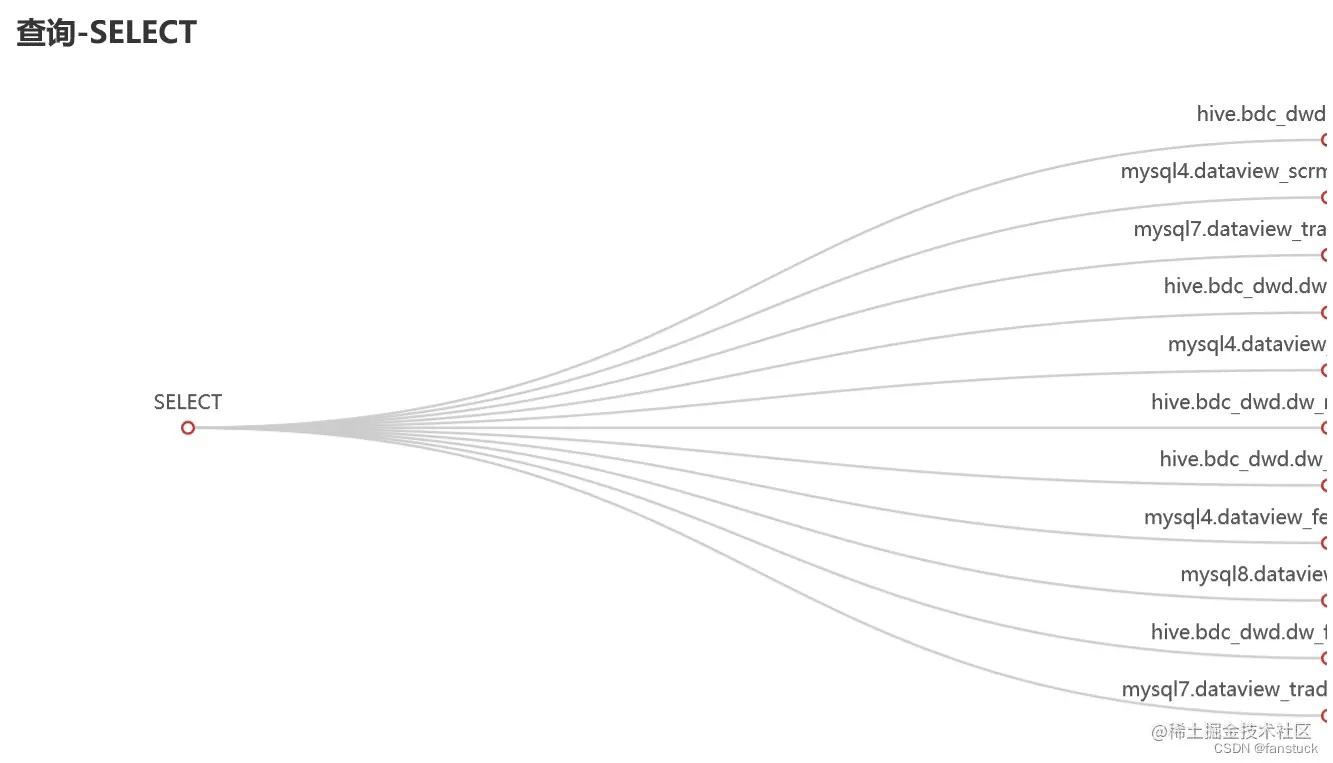
以上就是Python sqlparse解析SQL表血缘追踪实现的详细内容,更多关于Python sqlparse血缘追踪的资料请关注我们其它相关文章!
相关推荐
-

python编写WAF与Sqlmap结合实现指纹探测
目录 编写探测识别WAF脚本 00x1:WAF的特征 00x2:测试 00x3:收集waf Pyhacker 之 编写SQLMAP Waf探测 使用Python编写探测WAF指纹脚本,再结合到Sqlmap中,这样以后再探测网站时,如果识别到此WAF指纹,就会显示出来. 编写探测识别WAF脚本 00x1:WAF的特征 首先我们要了解WAF,寻找WAF的特征 比如安全狗,当访问不存在的页面 寻找关键字:如safedog 00x2:测试 ok,分析完毕,我们来测试一下 没毛病,我们再去找一个waf,加
-
Python操作MySQL MongoDB Oracle三大数据库深入对比
目录 1. Python操作Oracle数据库 2. Python操作MySQL数据库 3. Python操作MongoDB数据库 作为数据分析师,掌握一门数据库语言,是很有必要的. 今天黄同学就带着大家学习两个关系型数据库MySQL.Oracle,了解一个非关系数据库MongoDB. 1. Python操作Oracle数据库 这一部分的难点在于:环境配置有点繁琐.不用担心,我为大家写了一篇关于Oracle环境配置的文章. Python操作Oracle使用的是cx_Oracle库.需要我们使用如
-
Python操作ES的方式及与Mysql数据同步过程示例
目录 Python操作Elasticsearch的两种方式 mysql和Elasticsearch同步数据 haystack的使用 Redis补充 Python操作Elasticsearch的两种方式 # 官方提供的:Elasticsearch # pip install elasticsearch # GUI:pyhon能做图形化界面编程吗? -Tkinter -pyqt # 使用(查询是重点) # pip3 install elasticsearch https://github.com/e
-
Python基于ssh远程连接Mysql数据库操作
目录 背景 安装支持库 连接Mysql 自定义查询函数 背景 如果需要访问远程服务器的Mysql数据库,但是该Mysql数据库为了安全期间,安全措施设置为只允许本地连接(也就是你需要登录到该台服务器才能使用),其他远程连接是不可以直接访问,并且相应的端口也做了修改,那么就需要基于ssh来连接该数据库.这种方式连接数据库与Navicat里面界面化基于ssh连接一样. Navicat 连接数据库 安装支持库 如果要连接Mysql,首先需要安装pymysql pip install pymysql 安
-
python使用pymysql操作MySQL错误代码1054和1064处理方式
目录 错误代码1064处理 错误代码1054处理 最近在学习用Python爬虫,需要用到mysql来存储从网络上爬到的数据, 这里我也是借助了pymysql来操作mysql数据库,但是在实际写代码操作数据库的过程中遇到了好多坑(改到我怀疑人生...),这里记录下我排雷的过程,也供大家来参考,希望对你们有所帮助. 错误代码1064处理 这个错误可以说是我在编写整个代码的遇到的最大的错误,没有之一!这里为了说明这个错误的情况,我将原来的部分代码经过精简过来举例子.麻雀虽小,五脏俱全,话不多说,首先贴
-
Python写入MySQL数据库的三种方式详解
目录 场景一:数据不需要频繁的写入mysql 场景二:数据是增量的,需要自动化并频繁写入mysql 方式一 方式二 总结 大家好,Python 读取数据自动写入 MySQL 数据库,这个需求在工作中是非常普遍的,主要涉及到 python 操作数据库,读写更新等,数据库可能是 mongodb. es,他们的处理思路都是相似的,只需要将操作数据库的语法更换即可. 本篇文章会给大家分享数据如何写入到 mysql,分为两个场景,三种方式. 场景一:数据不需要频繁的写入mysql 使用 navicat 工
-
Python sqlparse解析SQL表血缘追踪实现
目录 引言 一.主线任务 1.数据治理 2.血缘追踪 3.SQL表血缘 二.实现过程 1.目标效果 2.代码实现 1.功能函数识别 2.SQL标准格式 3.解析AST树 4.最终效果: 引言 SQLparse的开源库解析中就说过自己在寻找在python编程内可行的SQL血缘解析,JAVA去解析Hive的源码实践的话我还是打算放到后期来做,先把Python能够实现的先实现完.主要是HiveSQL的底层就是JAVA代码,怎么改写还是绕不开JAVA的.不过上篇系列我有提到过sqlparse,其实这个库
-
解析SQL 表结构信息查询 含主外键、自增长
最近项目需要做什么数据字典,需要表结构信息.在网上看了许多关于表结构信息的查询,感觉都不怎么样.相对好一点就是<基于SQL2005 SQL2008 表结构信息查询升级版的详解(含外键信息)> ,但是这里有一点小问题,缺少一个过滤以致运行有一点小bug.在AdventureWorks2012数据库中的Address表查询结果如图:在查询过滤中我们添加以下信息就ok了:AND g.class_desc = 'OBJECT_OR_COLUMN'修改后的SQL如下: 复制代码 代码如下: SELECT
-
python如何解析复杂sql,实现数据库和表的提取的实例剖析
需求: 公司的数据分析师,提交一个sql, 一般都三四百行.由于数据安全的需要,不能开放所有的数据库和数据表给数据分析师查询,所以需要解析sql中的数据库和表,与权限管理系统中记录的数据库和表权限信息比对,实现非法查询的拦截. 解决办法: 在解决这个问题前,现在github找了一下轮子,发现python下面除了sql parse没什么好的解析数据库和表的轮轮.到是在java里面找到presto-parser解析的比较准.于是自己结合sql parse源码写了个类,供大家参考,测试了一下,检测还是
-
解析Mybatis对sql表的一对多查询问题
Mybatisd对sql表的一对多查询 select * from projectrecord pr left join projects po on po.pid=pr.pid left join emp e on e.empno = pr.empno where pr.pid=1 <?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE mapper PUBLIC "-//mybatis.or
-
Python 实现数据库(SQL)更新脚本的生成方法
我在工作的时候,在测试环境下使用的数据库跟生产环境的数据库不一致,当我们的测试环境下的数据库完成测试准备更新到生产环境上的数据库时候,需要准备更新脚本,真是一不小心没记下来就会忘了改了哪里,哪里添加了什么,这个真是非常让人头疼.因此我就试着用Python来实现自动的生成更新脚本,以免我这烂记性,记不住事. 主要操作如下: 1.在原先 basedao.py 中添加如下方法,这样旧能很方便的获取数据库的数据,为测试数据库和生产数据库做对比打下了基础. def select_database_stru
-
Python数据结构之顺序表的实现代码示例
顺序表即线性表的顺序存储结构.它是通过一组地址连续的存储单元对线性表中的数据进行存储的,相邻的两个元素在物理位置上也是相邻的.比如,第1个元素是存储在线性表的起始位置LOC(1),那么第i个元素即是存储在LOC(1)+(i-1)*sizeof(ElemType)位置上,其中sizeof(ElemType)表示每一个元素所占的空间. 追加直接往列表后面添加元素,插入是将插入位置后的元素全部往后面移动一个位置,然后再将这个元素放到指定的位置,将长度加1删除是将该位置后面的元素往前移动,覆盖该元素,然
-
python导出hive数据表的schema实例代码
本文研究的主要问题是python语言导出hive数据表的schema,分享了实现代码,具体如下. 为了避免运营提出无穷无尽的查询需求,我们决定将有查询价值的数据从mysql导入hive中,让他们使用HUE这个开源工具进行查询.想必他们对表结构不甚了解,还需要为之提供一个表结构说明,于是编写了一个脚本,从hive数据库中将每张表的字段即类型查询出来,代码如下: #coding=utf-8 import pyhs2 from xlwt import * hiveconn = pyhs2.connec
-
分析Python中解析构建数据知识
Python 可以通过各种库去解析我们常见的数据.其中 csv 文件以纯文本形式存储表格数据,以某字符作为分隔值,通常为逗号:xml 可拓展标记语言,很像超文本标记语言 Html ,但主要对文档和数据进行结构化处理,被用来传输数据:json 作为一种轻量级数据交换格式,比 xml 更小巧但描述能力却不差,其本质是特定格式的字符串:Microsoft Excel 是电子表格,可进行各种数据的处理.统计分析和辅助决策操作,其数据格式为 xls.xlsx.接下来主要介绍通过 Python 简单解析构建
-
Python HTML解析器BeautifulSoup用法实例详解【爬虫解析器】
本文实例讲述了Python HTML解析器BeautifulSoup用法.分享给大家供大家参考,具体如下: BeautifulSoup简介 我们知道,Python拥有出色的内置HTML解析器模块--HTMLParser,然而还有一个功能更为强大的HTML或XML解析工具--BeautifulSoup(美味的汤),它是一个第三方库.简单来说,BeautifulSoup最主要的功能是从网页抓取数据.本文我们来感受一下BeautifulSoup的优雅而强大的功能吧! BeautifulSoup安装 B
-
Python实现从SQL型数据库读写dataframe型数据的方法【基于pandas】
本文实例讲述了Python实现从SQL型数据库读写dataframe型数据的方法.分享给大家供大家参考,具体如下: Python的pandas包对表格化的数据处理能力很强,而SQL数据库的数据就是以表格的形式储存,因此经常将sql数据库里的数据直接读取为dataframe,分析操作以后再将dataframe存到sql数据库中.而pandas中的read_sql和to_sql函数就可以很方便得从sql数据库中读写数据. read_sql 参见pandas.read_sql的文档,read_sql主