图文详解Java中的序列化机制
目录
- 概述
- 对象序列化和反序列化机制
- 修改默认的序列化机制
- 使用transient关键字
- 自定义readObject、writeObject方法
- 实现Externalizable接口
- serialVersionUID的作用
- 使用序列化clone
概述
java中的序列化可能大家像我一样都停留在实现Serializable接口上,对于它里面的一些核心机制没有深入了解过。直到最近在项目中踩了一个坑,就是序列化对象添加一个字段以后,使用方系统报了反序列化失败,原因是我们双方的序列化对象没有加上serialVersionUID,那你们知道下面几个问题吗:
- 序列化对象中的
serialVersionUID是干嘛用的? - 如何修改默认的序列化机制?
- 如何使用序列化的方式克隆对象?
对象序列化和反序列化机制
序列化: 将对象转成二进制写到输出流的过程。
反序列化: 通过输入流读回二进制转成对象的过程。
通过对象的序列化和反序列化机制可以实现对象在网络之间传输。
在Java中,如果一个对象要想实现序列化,必须要实现下面两个接口之一:
- Serializable 接口
- Externalizable 接口
这里我们先讲解常用的Serializable 接口。
writeObject序列化过程栗子:
@Test
public void testSerializable() throws FileNotFoundException {
User user = new User("alvin", 19);
// 文件输出流
FileOutputStream bout = new FileOutputStream("user.dat");
try (ObjectOutputStream out = new ObjectOutputStream(bout)) {
// 序列化
out.writeObject(user);
} catch (IOException e) {
e.printStackTrace();
}
}
@Data
@NoArgsConstructor
@AllArgsConstructor
public class User implements Serializable {
private String username;
private Integer age;
}
结果:
readObject反序列化栗子:
现在模拟另外一个系统需要反序列化user.dat
@Test
public void testDeSerializable() throws FileNotFoundException {
User user = null;
// 写到内存中,当然也可以写到文件中
FileInputStream fis = new FileInputStream("user.dat");
try (ObjectInputStream in = new ObjectInputStream(fis)) {
// 反序列化 readObject
user = (User) in.readObject();
} catch (IOException | ClassNotFoundException e) {
e.printStackTrace();
}
Assert.assertEquals("alvin", user.getUsername());
}
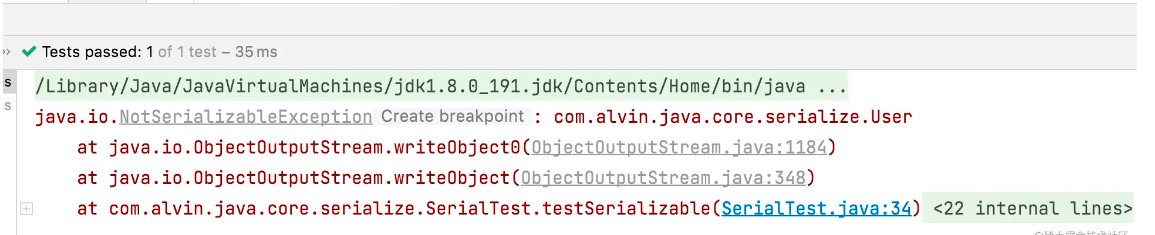
如果User类不实现Serializable接口, 那会怎么样?
当然是报错了,如下图:
小结:
一个对象想要被序列化,那么它的类就要实现此接口或者它的子接口。
修改默认的序列化机制
默认的情况下,如果实现了Serializable接口的对象进行序列化的时候,默认会将全部的数据域,也就是成员变量进行序列化输出,那往往有时候并不需要这样,有什么方法可以修改序列化机制呢?下面提供3中方式。
使用transient关键字
将成员变量标记成transient,那么在序列化的过程中这些数据域会被跳过,如下图所示:

这是一种最简单的方式,但是不够灵活。
自定义readObject、writeObject方法
序列化类中可以通过定义下面签名的方法:
private void readObject(java.io.ObjectInputStream s) throws java.io.IOException, ClassNotFoundExceptionprivate void writeObject(java.io.ObjectOutputStream s) throws java.io.IOException
只要类中有这两个签名的方法,那么就不会调用默认的序列化,取而代之调用这些方法。
本例我们举个jdk中的例子,ArrayList就实现了这两个方法,重写了序列化机制。

主要原因ArrayList底层的数组通常会预留一些容量,等容量不足时再扩充容量,那么有些空间可能就没有实际存储元素,采用自定义方式实现序列化时,就可以保证只序列化实际存储的那些元素,而不是整个数组,从而节省空间和时间。
实现Externalizable接口
Externalizable接口想必大家很少用到,它是Serializable接口的子类,用户要实现的writeExternal()和readExternal() 方法,用来决定如何序列化和反序列化。
因为序列化和反序列化方法需要自己实现,因此可以指定序列化哪些属性,而transient在这里无效。
对Externalizable对象反序列化时,会先调用类的无参构造方法,这是有别于默认反序列方式的。如果把类的不带参数的构造方法删除,或者把该构造方法的访问权限设置为private、默认或protected级别,会抛出java.io.InvalidException: no valid constructor异常,因此Externalizable对象必须有默认构造函数,而且必需是public的。
举例说明:
public class User2 implements Externalizable {
private String username;
private Integer age;
@Override
public void writeExternal(ObjectOutput out) throws IOException {
out.writeUTF(username);
out.writeInt(age);
}
@Override
public void readExternal(ObjectInput in) throws IOException, ClassNotFoundException {
username = in.readUTF();
age = in.readInt();
}
}
serialVersionUID的作用
这就回到概述中提到的项目中遇到的问题,现在简要描述下:
A系统中的序列化对象User用的最新版本如下:

B系统中反序列化的对象,还是老的User版本如下:

这时候A系统生成的序列化文件,交给B系统反序列化时,出错了, 如下图:

原因:
类定义发生了变化,比如添加、删除、修改类中的数据域后,它的唯一标记符或者称为SHA指纹、或者理解为serialVersionUID都会发生变化,这个值会保存在序列化二进制中,如果反序列化过程发现对不上,就会报错,如上图所示。
那么如何处理呢?
这时候,我们如果觉得这个序列化对象是可以兼容的,那么可以自定义一个serialVersionUID的静态成员变量,它就不会自动生成,而是直接用这个值,如下图:

使用序列化clone
clone大家都知道吧,在深拷贝的时候编码还是很麻烦的,借用序列化机制可以实现深拷贝。做法很简单,就是将对象序列化到输出流中,然后读回。
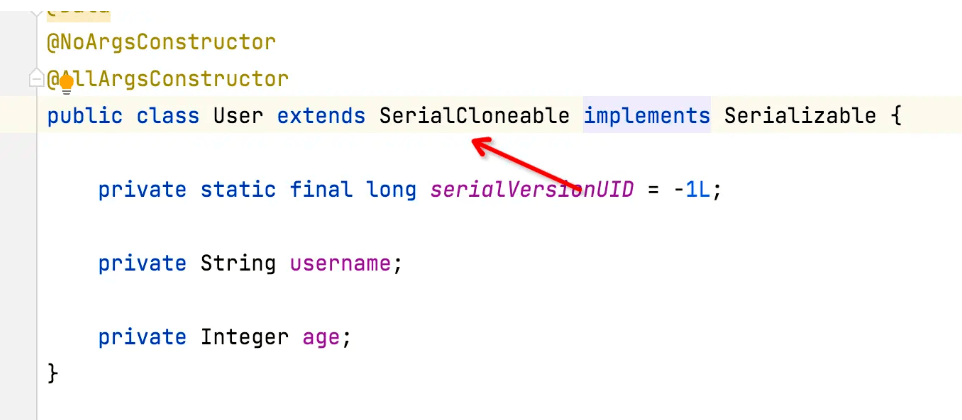
public class SerialCloneable implements Cloneable, Serializable {
@Override
public Object clone() throws CloneNotSupportedException {
try {
// 保存到字节数组流
ByteArrayOutputStream bout = new ByteArrayOutputStream();
try(ObjectOutputStream out = new ObjectOutputStream(bout)) {
out.writeObject(this);
}
// 读取
try(InputStream bin = new ByteArrayInputStream(bout.toByteArray())) {
ObjectInputStream in = new ObjectInputStream(bin);
return in.readObject();
}
} catch (IOException | ClassNotFoundException e) {
CloneNotSupportedException e2 = new CloneNotSupportedException();
e2.initCause(e);
throw e2;
}
}
}
注意一点,这种方式性能不高,通常比显示构建、复制数据要慢不少。
到此这篇关于图文详解Java中的序列化机制的文章就介绍到这了,更多相关Java序列化机制内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
详解Java序列化机制
概况 在程序中为了能直接以 Java 对象的形式进行保存,然后再重新得到该 Java 对象,这就需要序列化能力.序列化其实可以看成是一种机制,按照一定的格式将 Java 对象的某状态转成介质可接受的形式,以方便存储或传输.其实想想就大致清楚基本流程,序列化时将 Java 对象相关的类信息.属性及属性值等等保存起来,反序列化时再根据这些信息构建出 Java 对象.而过程可能涉及到其他对象的引用,所以这里引用的对象的相关信息也要参与序列化. Java 中进行序列化操作需要实现 Serializabl
-
Java序列化(Serialization) 机制
Java中,一切都是对象,在分布式环境中经常需要将Object从这一端网络或设备传递到另一端.这就需要有一种可以在两端传输数据的协议.Java序列化机制就是为了解决这个问题而产生. 将对象状态转换成字节流之后,可以用java.io包中各种字节流的类将其保存到文件中,管道到另一线程中或通过网络连接将对象数据发送到另一主机.对象序列化功能非常简单.强大,在RMI.Socket.JMS.EJB都有应用.对象序列化问题在网络编程中并不是最核心的课题,但却相当重要,具有许多实用意义. java对象序列化不
-
Java序列化机制与原理的深入分析
Java序列化算法透析 Serialization(序列化)是一种将对象以一连串的字节描述的过程:反序列化deserialization是一种将这些字节重建成一个对象的过程.Java序列化API提供一种处理对象序列化的标准机制.在这里你能学到如何序列化一个对象,什么时候需要序列化以及Java序列化的算法,我们用一个实例来示范序列化以后的字节是如何描述一个对象的信息的.序列化的必要性 Java中,一切都是对象,在分布式环境中经常需要将Object从这一端网络或设备传递到另一端.这就需要有一种可以在
-

深入理解Java原生的序列化机制
概念 一个对象如果想在硬盘上存储,一定就需要借助于一定的数据格式.这种把对象转换为硬盘存储的格式的过程就叫做对象的序列化,同样地,将这些文件再反向转换为程序中对象的操作就叫做反序列化 一些复杂的解决方案可能是将对象转换为json字符串的方式,这种方式的优点是易读,但是效率还是太低,所以Java的序列化的解决方案是将对象转换为一个二进制流的形式,来实现数据的持久化,本篇文章将会来详细讲解序列化的实现和原理 实现 准备 我们这里有一个普通的对象,要注意的是这个类和其中用到的所有对象都需要实现序列化接
-
通过实例了解java序列化机制
这篇文章主要介绍了通过实例了解java序列化机制,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 序列化是指对象通过写出描述自己状态的数值来记录自己的过程,即将对象表示成一系列有序字节,Java提供了将对象写入流和从流中恢复对象的方法.对象能包含其它的对象,而其它的对象又可以包含另外的对象.Java序列化能够自动的处理嵌套的对象.对于一个对象的简单域,writeObject()直接将其值写入流中. 当遇到一个对象域时,writeObject()被
-
图文详解Java中的序列化机制
目录 概述 对象序列化和反序列化机制 修改默认的序列化机制 使用transient关键字 自定义readObject.writeObject方法 实现Externalizable接口 serialVersionUID的作用 使用序列化clone 概述 java中的序列化可能大家像我一样都停留在实现Serializable接口上,对于它里面的一些核心机制没有深入了解过.直到最近在项目中踩了一个坑,就是序列化对象添加一个字段以后,使用方系统报了反序列化失败,原因是我们双方的序列化对象没有加上seri
-
详解Java中的反射机制和动态代理
一.反射概述 反射机制指的是Java在运行时候有一种自观的能力,能够了解自身的情况为下一步做准备,其想表达的意思就是:在运行状态中,对于任意一个类,都能够获取到这个类的所有属性和方法:对于任意一个对象,都能够调用它的任意一个方法和属性(包括私有的方法和属性),这种动态获取的信息以及动态调用对象的方法的功能就称为java语言的反射机制.通俗点讲,通过反射,该类对我们来说是完全透明的,想要获取任何东西都可以,这是一种动态获取类的信息以及动态调用对象方法的能力. 想要使用反射机制,就必须要先获取到该类
-
一文详解Java中的类加载机制
目录 一.前言 二.类加载的时机 2.1 类加载过程 2.2 什么时候类初始化 2.3 被动引用不会初始化 三.类加载的过程 3.1 加载 3.2 验证 3.3 准备 3.4 解析 3.5 初始化 四.父类和子类初始化过程中的执行顺序 五.类加载器 5.1 类与类加载器 5.2 双亲委派模型 5.3 破坏双亲委派模型 六.Java模块化系统 一.前言 Java虚拟机把描述类的数据从Class文件加载到内存,并对数据进行校验.转换解析和初始化,最 终形成可以被虚拟机直接使用的Java类型,这个过程
-
详解Java中对象序列化与反序列化
序列化 (Serialization)是将对象的状态信息转换为可以存储或传输的形式的过程.一般将一个对象存储至一个储存媒介,例如档案或是记亿体缓冲等.在网络传输过程中,可以是字节或是XML等格式.而字节的或XML编码格式可以还原完全相等的对象.这个相反的过程又称为反序列化. Java对象的序列化与反序列化 在Java中,我们可以通过多种方式来创建对象,并且只要对象没有被回收我们都可以复用该对象.但是,我们创建出来的这些Java对象都是存在于JVM的堆内存中的.只有JVM处于运行状态的时候,这些对
-
图文详解PHP中GC回收机制的利用
目录 前言 简单铺垫 初识GC 小试牛刀 总结 前言 在前面讲魔术方法时就提到过一个问题,__destruct()无论如何都会被触发,但是前提是必须得完成程序的开始与结束,但是如果程序走了一半,突然报错,那么__destruct()不会触发了,那如果又必须要__destruct()触发又得怎么搞呢? 这里就要提到一个垃圾回收机制---GC回收!! 简单铺垫 先看看这个简单的序列化,一定要先思考再看后面的答案 <?php highlight_file(__FILE__); class errorr
-
图文详解Java中class的初始化顺序
class的装载 在讲class的初始化之前,我们来讲解下class的装载顺序. 以下摘自<Thinking in Java 4> 由于Java 中的一切东西都是对象,所以许多活动 变得更加简单,这个问题便是其中的一例.正如下一章会讲到的那样,每个对象的代码都存在于独立的文件中.除非真的需要代码,否则那个文件是不会载入的.通常,我们可认为除非那个类的一个对象构造完毕,否则代码不会真的载入.由于static 方法存在一些细微的歧义,所以也能认为"类代码在首次使用的时候载入".
-
图文详解Java中的字节输入与输出流
目录 字节输入流 字节输入流结构图 FileInputStream类 构造方法: 常用读取方法: 字节输出流 字节输出流结构图: FileOutputStream类 构造方法: 常用写入方法: 总结 字节输入流 java.io.InputStream抽象类是所有字节输入流的超类,将数据从文件中读取出来. 字节输入流结构图 在Java中针对文件的读写操作有一些流,其中介绍最常见的字节输入流. FileInputStream类 FileInputStream流被称为字节输入流,对文件以字节的形式读取
-
图文详解Java的反射机制
目录 1.什么是反射 2.Hello,java反射 3.java程序运行的三个阶段 4.反射相关类 5.反射的优化 6.Class类分析 7.获取Class对象的六种方式 8.类加载机制 动态加载和静态加载 类加载流程概述 加载阶段 连接阶段 初始化 9.通过反射获取类的结构信息 1.什么是反射 反射就是Reflection,Java的反射是指程序在运行期可以拿到一个对象的所有信息. 加载类后,在堆中就产生了一个class类型的对象,这个对象包含了类的完整结构的信息,通过这个对象得到类的结构.这
-
详解java中反射机制(含数组参数)
详解java中反射机制(含数组参数) java的反射是我一直非常喜欢的地方,因为有了这个,可以让程序的灵活性大大的增加,同时通用性也提高了很多.反射原理什么的,我就不想做过大介绍了,网上一搜,就一大把.(下面我是只附录介绍下) Reflection 是Java被视为动态(或准动态)语言的一个关键性质.这个机制允许程序在运行时透过Reflection APIs取得任何一个已知名称的class的内部信息,包括其modifiers(诸如public, static 等等).superclass(例如O
-
详解java中各类锁的机制
目录 前言 1. 乐观锁与悲观锁 2. 公平锁与非公平锁 3. 可重入锁 4. 读写锁(共享锁与独占锁) 6. 自旋锁 7. 无锁 / 偏向锁 / 轻量级锁 / 重量级锁 前言 总结java常见的锁 区分各个锁机制以及如何使用 使用方法 锁名 考察线程是否要锁住同步资源 乐观锁和悲观锁 锁住同步资源后,要不要阻塞 不阻塞可以使用自旋锁 一个线程多个流程获取同一把锁 可重入锁 多个线程公用一把锁 读写锁(写的共享锁) 多个线程竞争要不要排队 公平锁与非公平锁 1. 乐观锁与悲观锁 悲观锁:不能同时