python FastApi实现数据表迁移流程详解
目录
- 啥是数据迁移
- 1.需要新的数据表
- 2.需要对现有表结构进行调整
- 回到ORM
- 迁移手段
- 安装alembic
- 初始化项目
- 修改alembic.ini
- 修改alembic/env.py
- 开始生成迁移工作
- 变更数据库
- FAQ
啥是数据迁移
在我们平时的开发过程中,经常需要对一些数据进行调整。一般会有以下几种场景:
1.需要新的数据表
我们的接口自动化平台虽然已经较为完善了,但难免会继续迭代一些新的功能,假设我们需要做一个订阅用例的功能。
大体想一下就可以知道,订阅用例以后这个数据得持久化(即入库),这样我在查询谁订阅了这条用例的时候,就能获取到订阅人,订阅时间等数据。
这也就意味着我们需要一张订阅表,里面至少得有订阅人和订阅的id,以及订阅时间这3个要素。体现在数据库通俗点说就需要:
// 创建订阅表, 后面的省略 create table...
由于业务的变动,导致新的数据表诞生。
2.需要对现有表结构进行调整
当我们的订阅表完成以后,有的同学就发现了,这个订阅好像不能取消,所以我们此时可能需要一个新的字段: isValid,这个字段用来判断用户是否取消订阅了这个用例,如果我订阅错了,或者嫌消息太多,想取消订阅,那还是得满足需求的。
包括新增字段/修改字段/删除字段,这些都会对数据表产生影响,导致我们需要改动数据库。
回到ORM
我们目前采用sqlalchemy作为我们的orm,如果只需要修改Python的Model类(操作字段就加在Model类里面操作)该多好。这样的话,我们依然不需要去写很基础的sql语句,就能达到修改表结构的目的。而这个,就是我们今天要讲的数据迁移。因为数据需要发生变化,orm与数据库的逻辑对不上号了,所以我们需要迁移。
迁移手段
目前市面上,关于Django(自带orm)和Flask这块都很成熟,django因为有自带的orm显得更牛逼,在manage.py里面自带了migrate(迁移)的命令。
而我们今天要讲的fastapi,由于不像django那么全面,所以我们采用alembic(sqlalchemy作者编写)来帮助我们完成数据迁移操作。
如果你也用的fastapi+sqlalchemy,那我们就一起来耍耍i!
注: sqlalchemy只自带create_all(建立全部表)的功能
安装alembic
大家采用虚拟环境和全局安装都可以,我的建议是全局安装,因为我们可能会在多个项目使用它。
pip install alembic
初始化项目
我们在python项目的根目录输入以下命令:
alembic init alembic
alembic是我们刚才安装的工具,init则是初始化的意思,后面的alembic则是迁移文件夹的名字,一般我们会默认叫alembic,以便于其他人一眼就知道是干嘛的。
修改alembic.ini
执行完成之后你会发现根目录多了个ini配置文件和alembic文件夹,我们需要稍微修改下配置文件:
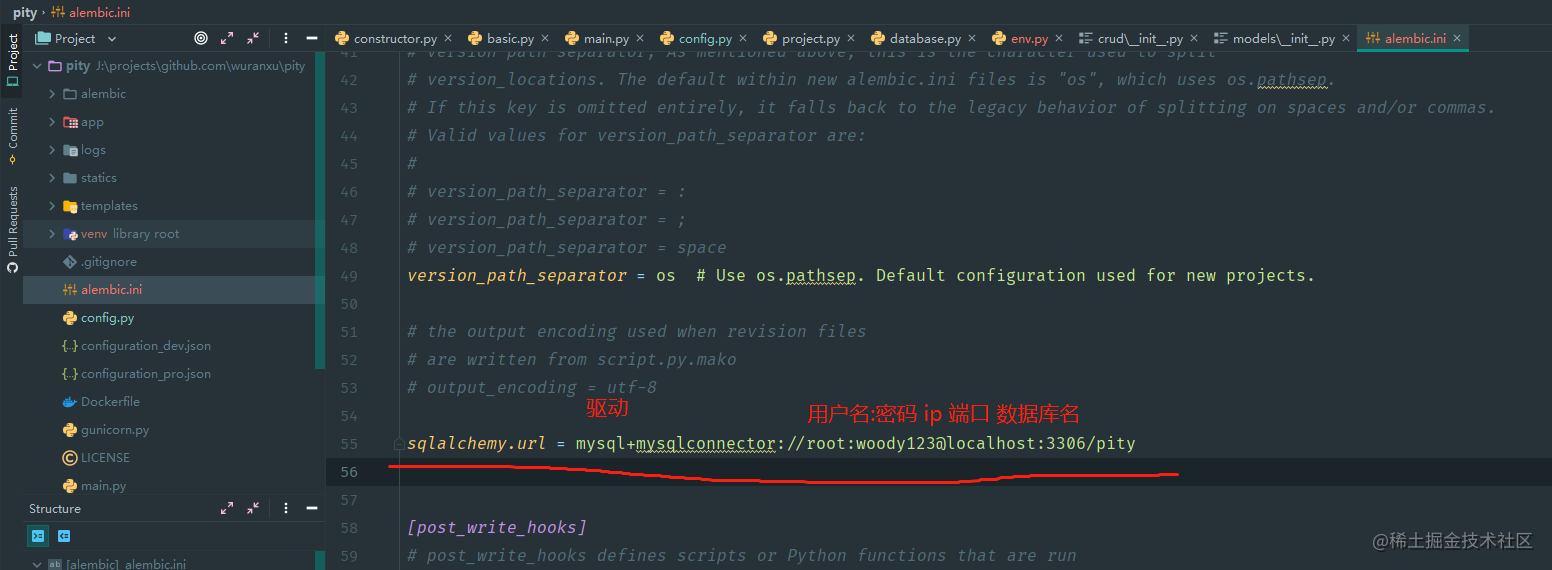
将alembic.ini中的sqlalchemy.url改为你数据库的jdbc连接地址,以我的为例:
修改alembic/env.py
首先我们找到里面的target_metadata变量,默认是None。接着在target_metadata = None上方加入如下代码:
import sys from os.path import abspath, dirname sys.path.append(dirname(dirname(abspath(__file__))))
然后我们需要引入我们的model目录,由于在pity里面,最后的初始化建表工作都是在curd目录进行的:
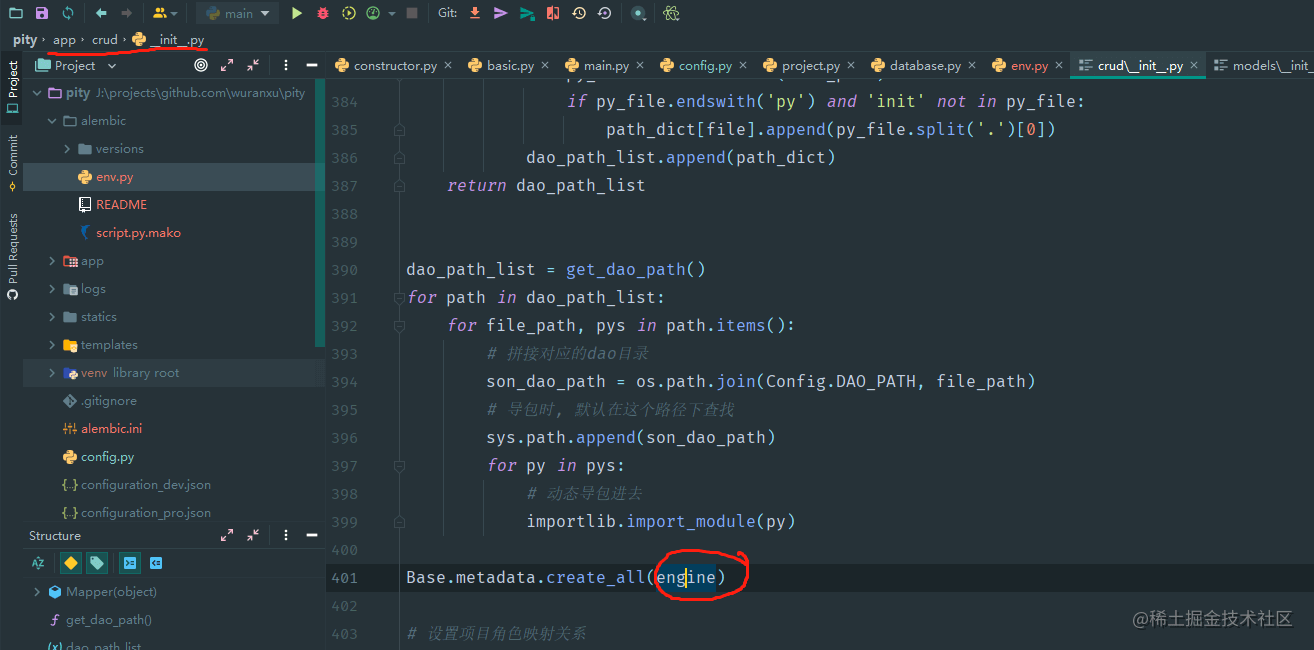
所以我这边是引入crud里面的Base。这个Base是啥玩意呢?
我们使用sqlalchemy,都需要引入各种model,这些model最终都会被加入到Base.metadata,这样sqlalchemy就知道你有哪些表需要处理了。
我们继续修改env.py,也就是告诉alembic你有哪些数据表(上文说的, 数据表都在Base.metadata)。
# 注意这个地方是要引入模型里面的Base,不是connect里面的 from app.crud import Base # 告诉alembic 你的表数据在哪 target_metadata = Base.metadata
开始生成迁移工作
要注意,我们配置这么多东西是为了让alembic知道你的model都在哪,你的数据库怎么连,这样它才能去对比差异并生成结果。
alembic revision --autogenerate -m "test"
稍作等待,我们可以在alembic/versions目录看到对应的py文件:
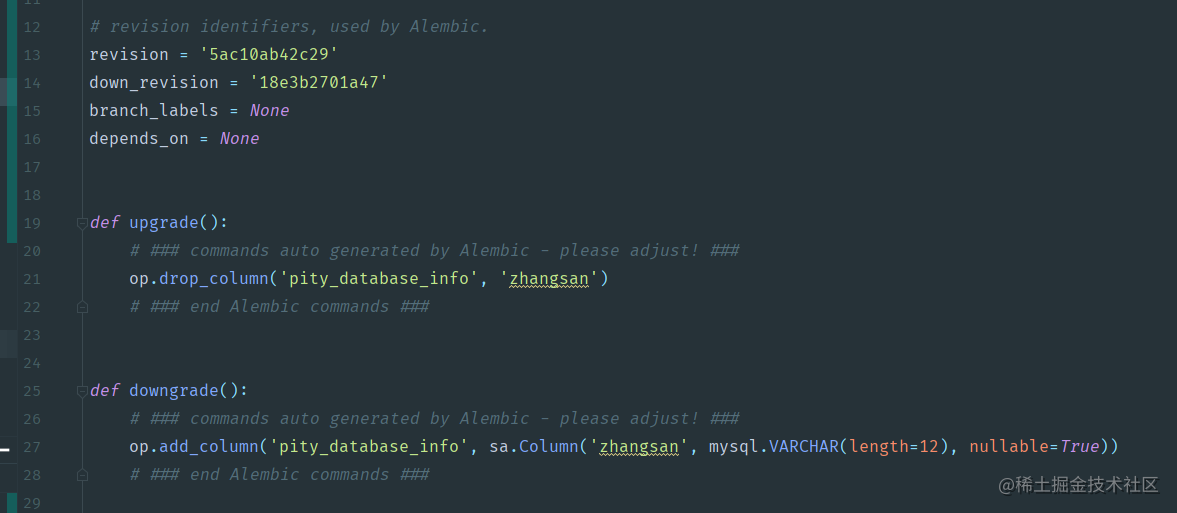
里面会有drop_column(删除字段)这样的操作信息。但要注意,这并没有真正修改数据库。
变更数据库
alembic upgrade head
执行上述命令,alembic就会根据你当前的版本(应该是你刚才生成的version的py脚本)去执行数据库变更操作。
这样,一个简单的迁移工作就完成了。接着我们聊聊注意事项。
FAQ
Q. 版本py脚本无变更信息出现
A. 请检查你的数据库是否真有变更,检查你的数据库url是否正确,检查你的model是否引入正确,如果操作都没问题,可以删除alembic目录和ini,重复上述操作(我昨晚就是这样的)
Q. 为什么字段重命名没有产生变更
A. 这玩意只校验了新增/修改/删除字段,这里的修改指的是字段的nullable这种修改,所以改字段名它不会检测。
Q. 我数据库里面有表没有定义到model,为啥变更给俺把表删除了?
A. 这个问题我也发现了,应该是有什么配置可以配置不删除未找到的表,但我目前还没有去研究,有后续会在底部留言。
最后,这个玩意相对比较鸡肋,建议不要大批量变更。可以频率高一点,比如有一点点改动就用它变更一下,而不要在史诗级改动的时候使用它。我个人的整体感受是,不太好用,但勉强能用。(因为暂时没有发现更合适的)
到此这篇关于python FastApi实现数据表迁移流程详解的文章就介绍到这了,更多相关python数据表迁移内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python实现Web服务器FastAPI的步骤详解
目录 1.简介 2.安装 3.官方示例 3.1 入门示例 Python测试代码如下(main.py): 3.2 跨域CORS 3.3 文件操作 3.4 WebSocket Python测试代码如下: 1.简介 FastAPI 是一个用于构建 API 的现代.快速(高性能)的 web 框架,使用 Python 3.6+ 并基于标准的 Python类型提示. 文档: https://fastapi.tiangolo.com源码: https://github.com/tiangolo/fastapi
-
Python利用fastapi实现上传文件
目录 使用File实现文件上传 使用UploadFile实现文件上传 UploadFile的属性 设置上传文件是可选的 上传多个文件 知识点补充 使用File实现文件上传 使用Form表单上传文件,fastapi使用File获取上传的文件. 指定了参数类型是bytes:file: bytes = File(),此时会将文件内容全部读取到内存,比较适合小文件. 使用File需要提前安装 python-multipart from fastapi import FastAPI, File app
-
python中fastapi设置查询参数可选或必选
目录 可选查询参数 必选查询参数 可选和必选参数共存 为可选参数做类型提示 前言: 在fastapi中,我们定义的查询参数是可以设置成:必选参数 or 可选参数. 可选查询参数 z只要给查询参数的默认值设置为None,表示该查询参数是可选参数. from fastapi import FastAPI app = FastAPI() @app.get("/items/{item_id}") async def read_item(item_id: str, q=None)
-
使用Python FastAPI构建Web服务的实现
FastAPI是一个使用 Python 编写的 Web 框架,还应用了 Python asyncio 库中最新的优化.本文将会介绍如何搭建基于容器的开发环境,还会展示如何使用 FastAPI 实现一个小型 Web 服务. 起步 我们将使用 Fedora 作为基础镜像来搭建开发环境,并使用 Dockerfile 为镜像注入 FastAPI.Uvicorn和 aiofiles这几个包. FROM fedora:32 RUN dnf install -y python-pip \ && dnf
-
python FastApi实现数据表迁移流程详解
目录 啥是数据迁移 1.需要新的数据表 2.需要对现有表结构进行调整 回到ORM 迁移手段 安装alembic 初始化项目 修改alembic.ini 修改alembic/env.py 开始生成迁移工作 变更数据库 FAQ 啥是数据迁移 在我们平时的开发过程中,经常需要对一些数据进行调整.一般会有以下几种场景: 1.需要新的数据表 我们的接口自动化平台虽然已经较为完善了,但难免会继续迭代一些新的功能,假设我们需要做一个订阅用例的功能. 大体想一下就可以知道,订阅用例以后这个数据得持久化(即入库)
-
python之sqlalchemy创建表的实例详解
python之sqlalchemy创建表的实例详解 通过sqlalchemy创建表需要三要素:引擎,基类,元素 from sqlalchemy import create_engine from sqlalchemy.ext.declarative import declarative_base from sqlalchemy import Column,Integer,String 引擎:也就是实体数据库连接 engine = create_engine('mysql+pymysql://go
-
一文搞懂Python中pandas透视表pivot_table功能详解
目录 一.概述 1.1 什么是透视表? 1.2 为什么要使用pivot_table? 二.如何使用pivot_table 2.1 读取数据 2.2Index 2.3Values 2.4Aggfunc 2.5Columns 一文看懂pandas的透视表pivot_table 一.概述 1.1 什么是透视表? 透视表是一种可以对数据动态排布并且分类汇总的表格格式.或许大多数人都在Excel使用过数据透视表,也体会到它的强大功能,而在pandas中它被称作pivot_table. 1.2 为什么要使用
-
Python制作数据分析透视表的方法详解
目录 1.pivot_table函数index属性 2.pivot_table函数values属性 3.pivot_table函数aggfunc属性 4.pivot_table函数columns属性 透视表是一种可以对数据动态排布并且分类汇总的表格格式,在常用的python的数据分析非标准库pandas中体现为pivot_table模块. pivot_table数据透视表可以灵活的定制数据分析需求进行汇总,当然在Excel办公操作中早就存在了数据透视表的工具.如今,数据透视表被应用在python
-
Python统计学一数据的概括性度量详解
一.数据的概括性度量 1.统计学概括: 统计学是应用数学的一个分支,主要通过利用概率论建立数学模型,收集所观察系统的数据,进行量化的分析.总结,并进而进行推断和预测,为相关决策提供依据和参考.统计学主要又分为描述统计学和推断统计学.给定一组数据,统计学可以摘要并且描述这份数据,这个用法称作为描述统计学.另外,观察者以数据的形态建立出一个用以解释其随机性和不确定性的数学模型,以之来推论研究中的步骤及母体,这种用法被称做推论统计学. 2.数据的概括性度量: 1)集中趋势的度量: 众数:众数(Mode
-
MySQL数据表基本操作实例详解
本文实例讲述了MySQL数据表基本操作.分享给大家供大家参考,具体如下: 数据表的基本操作 1.主键约束要求主键列的数据唯一,并且不允许为空.主键能够唯一地识别表中的一条记录,可以结合外键来定义不同数据表之间的关系,并且可以加快数据库查询的速度.主键和记录之间的关系如同身份证和人之间的关系. 2.字表的外键必须关联父表的主键,且关联字段的数据类型必须匹配.如果类型不一样.创建子表时,就会出现错误:ERROR 1005(HY000):can't create table 'databases.ta
-
MYSQL优化之数据表碎片整理详解
目录 在MySQL中,我们经常会使用VARCHAR.TEXT.BLOB等可变长度的文本数据类型.不过,当我们使用这些数据类型之后,我们就不得不做一些额外的工作——MySQL数据表碎片整理. 那么,为什么在使用这些数据类型之后,我们就要对MySQL定期进行碎片整理呢? 现在,我们先来看一个具体的例子.在这里,我们使用如下SQL语句在MySQL自带的TEST数据库中创建名为DEMO的数据表并插入5条测试数据. --创建DEMO表 CREATE TABLE DEMO( id int unsigned,
-
MySql中删除数据表的方法详解
目录 定义: 1 删除一个或多个没有被其他表关联的数据表 1.1 新建一张表 1.2 执行删除命令 1.3 结果检查 2 删除被其他表关联的主表 2.1 创建两张具有关联关系的表 2.2 执行删除DROP TABLE命令 2.3 取消外键关系,再删除. 定义: 删除数据表就是将数据库中已经存在的表从数据库中删除.注意,在删除表的同时,表的定义和表中所有的数据均会被删除.因此,在进行删除操作前,最好对表中的数据做一个备份,以免造成无法挽回的后果.本节将详细讲解数据库表的删除方法. 1 删除一个
-
使用python将excel数据导入数据库过程详解
因为需要对数据处理,将excel数据导入到数据库,记录一下过程. 使用到的库:xlrd 和 pymysql (如果需要写到excel可以使用xlwt) 直接丢代码,使用python3,注释比较清楚. import xlrd import pymysql # import importlib # importlib.reload(sys) #出现呢reload错误使用 def open_excel(): try: book = xlrd.open_workbook("XX.xlsx")
-
Python安装并操作redis实现流程详解
Redis redis是一个key-value存储系统.和Memcached类似,它支持存储的value类型相对更多,包括string(字符串).list(链表).set(集合).zset(sorted set --有序集合)和hash(哈希类型).这些数据类型都支持push/pop.add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的.在此基础上,redis支持各种不同方式的排序.与memcached一样,为了保证效率,数据都是缓存在内存中.区别的是redis会周期性