如何实现python爬虫爬取视频时实现实时进度条显示
目录
- 一、全部代码展示
- 二、解释
- 1.with closing
- with用法(实现上下文管理)
- closing用法(完美解决上述问题)
- 2.文件流stream
- 3.response.headers['content-length']
- 4.response.iter_content()
- 5.\r和%
- 三、结果展示
- 四、总结
前言:
在爬取并下载网页上的视频的时候,我们需要实时进度条,这可以帮助我们更直观的看到视频的下载进度。
一、全部代码展示
from contextlib import closing
from requests import get
url = 'https://v26-web.douyinvod.com/57cdd29ee3a718825bf7b1b14d63955b/615d475f/video/tos/cn/tos-cn-ve-15/72c47fb481464cfda3d415b9759aade7/?a=6383&br=2192&bt=2192&cd=0%7C0%7C0&ch=26&cr=0&cs=0&cv=1&dr=0&ds=4&er=&ft=jal9wj--bz7ThWG4S1ct&l=021633499366600fdbddc0200fff0030a92169a000000490f5507&lr=all&mime_type=video_mp4&net=0&pl=0&qs=0&rc=ank7OzU6ZnRkNjMzNGkzM0ApNmY4aGU8MzwzNzo3ZjNpZWdiYXBtcjQwLXNgLS1kLTBzczYtNS0tMmE1Xi82Yy9gLTE6Yw%3D%3D&vl=&vr='
with closing(get(url, stream=True)) as response:
chunk_size = 1024 # 单次请求最大值
# response.headers['content-length']得到的数据类型是str而不是int
content_size = int(response.headers['content-length']) # 文件总大小
data_count = 0 # 当前已传输的大小
with open('文件名.mp4', "wb") as file:
for data in response.iter_content(chunk_size=chunk_size):
file.write(data)
done_block = int((data_count / content_size) * 50)
# 已经下载的文件大小
data_count = data_count + len(data)
# 实时进度条进度
now_jd = (data_count / content_size) * 100
# %% 表示%
print("\r [%s%s] %d%% " % (done_block * '█', ' ' * (50 - 1 - done_block), now_jd), end=" ")
注:上面的url已过期,需要各位自己去找网页上的视频url
二、解释
1.with closing
我们在日常读取文件资源时,经常会用到with open() as f:的句子。
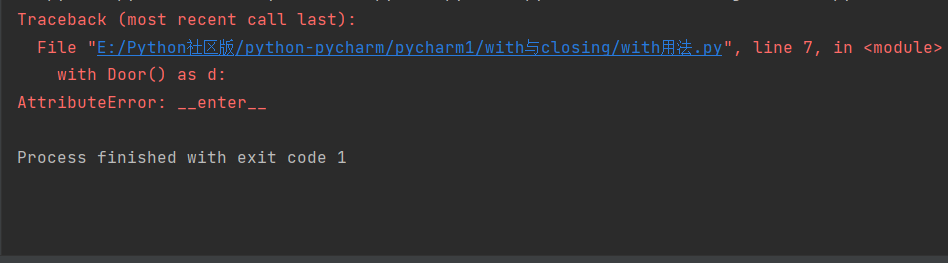
但是使用with语句的时候是需要条件的,任何对象,只要正确实现了上下文管理,就可以使用with语句,实现上下文管理是通过__enter__和__exit__这两个方法实现的。
with用法(没有实现上下文管理)
class Door():
def open(self):
print('Door is opened')
def close(self):
print('Door is closed')
with Door() as d:
d.open()
d.close()
结果报错了:
with用法(实现上下文管理)
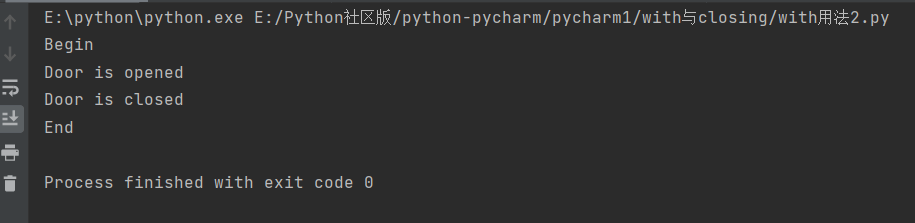
用__enter__和__exit__实现了上下文管理
class Door():
def open(self):
print('Door is opened')
def close(self):
print('Door is closed')
with Door() as d:
d.open()
d.close()
结果没报错:
closing用法(完美解决上述问题)
一个对象没有实现上下文,我们就不能把它用于with语句。这个时候,可以用contextlib中的
closing()来把该对象变为上下文对象。
class Door():
def __enter__(self):
print('Begin')
return self
def __exit__(self, exc_type, exc_value, traceback):
if exc_type:
print('Error')
else:
print('End')
def open(self):
print('Door is opened')
def close(self):
print('Door is closed')
with Door() as d:
d.open()
d.close()
例如:用with语句使用requests中的get(url)
也就是本文中的案例,使用with closing()下载视频(在网页中)
2.文件流stream
想象一下,如果把文件读取比作向池子里抽水,同步会阻塞程序,异步会等待结果,如果池子非常大呢?
因此有了文件流,它就好比你一边抽一边取,不用等池子满了再用,
所以对于一些大型文件(几个G的视频)一般会用到这个参数。(对小型文件也可以使用)
3.response.headers['content-length']
这表示获取文件的总大小,但是它得到的结果的数据类型是str而不是int,因此需要进行数据类型转换。
4.response.iter_content()
该方法一般用于从网上下载文件和网页(需要用到requests.get(url))
其中chunk_size表示单次请求最大值。
5.\r和%
\r表示回车(回到行首)
%是一种占位符
而对于%%,第一个%起到了转义的作用,使结果输出为百分号%
三、结果展示

四、总结
我之前看了许多的进度条,这些进度条都能动,但是满足不了根据文件内容进行加载(里面的参数要么都定死了,要么就与文件大小无关),不能做到真正的交互功能,这次的进度条就很好的展示了,大家可以去试试!!
这次下载视频展示进度条是争对一个url,大家可以将它加到你的爬虫的循环中,这样就能在爬每个视频的时候展示实时进度条了!!
到此这篇关于如何实现python爬虫爬取视频时实现实时进度条显示的文章就介绍到这了,更多相关python爬取显示进度条内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

3种Python 实现酷炫进度条的实用方法
目录 1.自定义ProgressBar 2.tqdm 3.Rich 前言: 在下载某些文件的时候你一定会不时盯着进度条,在写代码的时候使用进度条可以便捷的观察任务处理情况. 除了使用 print 来打印之外,今天本文我来给大家介绍几种酷炫的进度条的方式. 1.自定义ProgressBar 最原始的办法就是不借助任何第三方工具,自己写一个进度条函数,使用time模块配合sys模块即可 import sys import time def progressbar(it, prefix=""
-
Python进度条可视化之监测程序运行速度
目录 前言 安装 使用方式 示例 前言 今天和大家分享一个进度条可视化库,它的名字叫做 tqdm ,可以帮助我们监测程序运行的进度,用户只需要封装可迭代对象即可. 安装 通过命令行直接安装. pip install tqdm 也可以使用豆瓣镜像安装. pip install -i https://pypi.douban.com/simple tqdm 执行上述命令后,可以检查一下是否安装成功. pip show tqdm 使用方式 以下演示运行环境:jupyter notebook 不同运行环境
-
Python异步处理返回进度——使用Flask实现进度条
目录 使用Flask实现进度条 问题描述 解决方案 Flask Flask使用简单异步任务 使用Flask实现进度条 问题描述 Python异步处理,新起一个进程返回处理进度 解决方案 使用 tqdm 和 multiprocessing.Pool 安装 pip install tqdm 代码 import time import threading from multiprocessing import Pool from tqdm import tqdm def do_work(x): tim
-
Python实现实时显示进度条的六种方法
目录 第1种:普通进度条 第2种:带时间的普通进度条 第3种:tqdm库 第4种: alive_progress库 第5种:PySimpleGUI库 第6种:progressbar库 总结 相信大家对进度条一定不陌生了,比如在我们安装python库的时候可以看到下载的进度,此外在下载文件时也可以看到类似的进度条,比如下图这种: 应用场景:下载文件.任务计时等 今天辰哥就给大家分享Python的6种不同的实现实时显示处理进度的方式,文中每一种方式都附带一个案例,并提供官方文档,供大家学习,自定义去
-
python文本进度条实例
目录 1,刚开始(可能会很low) 2.单行消失 3.优化后的单行消失 总结 1,刚开始(可能会很low) import time scale=10 print("----执行开始----") for i in range(scale+1): a='*'*i b='.'*(scale-i) c=(i/scale)*100 print("{:^3.0f}%[{}->{}]".format(c,a,b)) time.sleep(0.1) print("-
-
Python实现实时显示进度条的6种方法
目录 第1种:普通进度条 第2种:带时间的普通进度条 第3种:tqdm库 第4种: alive_progress库 第5种:PySimpleGUI库 第6种:progressbar库 相信大家对进度条一定不陌生了,比如在我们安装python库的时候可以看到下载的进度,此外在下载文件时也可以看到类似的进度条,比如下图这种: 应用场景:下载文件.任务计时等 今天辰哥就给大家分享Python的6种不同的实现实时显示处理进度的方式,文中每一种方式都附带一个案例,并提供官方文档,供大家学习,自定义去修改.
-
如何实现python爬虫爬取视频时实现实时进度条显示
目录 一.全部代码展示 二.解释 1.with closing with用法(实现上下文管理) closing用法(完美解决上述问题) 2.文件流stream 3.response.headers['content-length'] 4.response.iter_content() 5.\r和% 三.结果展示 四.总结 前言: 在爬取并下载网页上的视频的时候,我们需要实时进度条,这可以帮助我们更直观的看到视频的下载进度. 一.全部代码展示 from contextlib import clos
-
Python爬虫爬取ts碎片视频+验证码登录功能
目标:爬取自己账号中购买的课程视频. 一.实现登录账号 这里采用的是手动输入验证码的方式,有能力的盆友也可以通过图像识别的方式自动填写验证码.登录后,采用session保持登录. 1.获取验证码地址 第一步:首先查看验证码对应的代码,可以从图中看到验证码图片的地址是:https://per.enetedu.com/Common/CreateImage?tmep_seq=1613623257608 颜色标红的部分tmep_seq=1613623257608,是为了解决浏览器缓存问题加的时间戳,因此
-
python爬虫爬取快手视频多线程下载功能
环境: python 2.7 + win10 工具:fiddler postman 安卓模拟器 首先,打开fiddler,fiddler作为http/https 抓包神器,这里就不多介绍. 配置允许https 配置允许远程连接 也就是打开http代理 电脑ip: 192.168.1.110 然后 确保手机和电脑是在一个局域网下,可以通信.由于我这边没有安卓手机,就用了安卓模拟器代替,效果一样的. 打开手机浏览器,输入192.168.1.110:8888 也就是设置的代理地址,安装证书之后才能
-
Python爬虫爬取杭州24时温度并展示操作示例
本文实例讲述了Python爬虫爬取杭州24时温度并展示操作.分享给大家供大家参考,具体如下: 散点图 爬虫杭州今日24时温度 https://www.baidutianqi.com/today/58457.htm 利用正则表达式爬取杭州温度 面向对象编程 图表展示(散点图 / 折线图) 导入相关库 import requests import re from matplotlib import pyplot as plt from matplotlib import font_manager i
-
python爬虫爬取某网站视频的示例代码
把获取到的下载视频的url存放在数组中(也可写入文件中),通过调用迅雷接口,进行自动下载.(请先下载迅雷,并在其设置中心的下载管理中设置为一键下载) 实现代码如下: from bs4 import BeautifulSoup import requests import os,re,time import urllib3 from win32com.client import Dispatch class DownloadVideo: def __init__(self): self.r = r
-
python爬虫爬取淘宝商品比价(附淘宝反爬虫机制解决小办法)
因为评论有很多人说爬取不到,我强调几点 kv的格式应该是这样的: kv = {'cookie':'你复制的一长串cookie','user-agent':'Mozilla/5.0'} 注意都应该用 '' ,然后还有个英文的 逗号, kv写完要在后面的代码中添加 r = requests.get(url, headers=kv,timeout=30) 自己得先登录自己的淘宝账号才有自己登陆的cookie呀,没登录cookie当然没用 以下原博 本人是python新手,目前在看中国大学MOOC的嵩天
-
python爬虫爬取某站上海租房图片
对于一个net开发这爬虫真真的以前没有写过.这段时间开始学习python爬虫,今天周末无聊写了一段代码爬取上海租房图片,其实很简短就是利用爬虫的第三方库Requests与BeautifulSoup.python 版本:python3.6 ,IDE :pycharm.其实就几行代码,但希望没有开发基础的人也能一下子看明白,所以大神请绕行. 第三方库首先安装 我是用的pycharm所以另为的脚本安装我这就不介绍了. 如上图打开默认设置选择Project Interprecter,双击pip或者点击加
-
python爬虫爬取淘宝商品信息
本文实例为大家分享了python爬取淘宝商品的具体代码,供大家参考,具体内容如下 import requests as req import re def getHTMLText(url): try: r = req.get(url, timeout=30) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return "" def parasePage(ilt, html): tr
-
python爬虫爬取网页表格数据
用python爬取网页表格数据,供大家参考,具体内容如下 from bs4 import BeautifulSoup import requests import csv import bs4 #检查url地址 def check_link(url): try: r = requests.get(url) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: print('无法链接服务器!!!')
-
Python爬虫爬取新浪微博内容示例【基于代理IP】
本文实例讲述了Python爬虫爬取新浪微博内容.分享给大家供大家参考,具体如下: 用Python编写爬虫,爬取微博大V的微博内容,本文以女神的微博为例(爬新浪m站:https://m.weibo.cn/u/1259110474) 一般做爬虫爬取网站,首选的都是m站,其次是wap站,最后考虑PC站.当然,这不是绝对的,有的时候PC站的信息最全,而你又恰好需要全部的信息,那么PC站是你的首选.一般m站都以m开头后接域名, 所以本文开搞的网址就是 m.weibo.cn. 前期准备 1.代理IP 网上有