Go语言开发kube-scheduler整体架构深度剖析
目录
- k8s 的调度器 kube-scheduler
- 官方描述scheduler
- 各个类型扩展点
- kube-scheduler 代码的主要框架
k8s 的调度器 kube-scheduler
kube-scheduler 作为 k8s 的调度器,就好比人的大脑,将行动指定传递到手脚等器官,进而执行对应的动作,对于 kube-scheduler 则是将 Pod 分配(调度)到集群内的各个节点,进而创建容器运行进程,对于k8s来说至关重要。
为了深入学习 kube-scheduler,本系从源码和实战角度深度学 习kube-scheduler,该系列一共分6篇文章,如下:
- kube-scheduler 整体架构
- 初始化一个 scheduler
- 一个 Pod 是如何被调度的
- 如何开发一个属于自己的scheduler插件
- 开发一个 prefilter 扩展点的插件
- 开发一个 socre 扩展点的插件
本篇先熟悉 kube-scheduler 的整体架构设计,看清全局,做到心里有数,在后面的篇章再庖丁解牛,一步步挖掘细节。
官方描述scheduler
我们先看看官方是怎么描述 scheduler 的
The Kubernetes scheduler is a control plane process which assigns Pods to Nodes. The scheduler determines which Nodes are valid placements for each Pod in the scheduling queue according to constraints and available resources. The scheduler then ranks each valid Node and binds the Pod to a suitable Node. Multiple different schedulers may be used within a cluster; kube-scheduler is the reference implementation.
k8s scheduler 是一个控制面进程,它分配 Pod 到 Nodes。根据限制和可用资源,scheduler 确定哪些节点符合调度队列里的 Pod。然后对这些符合的节点进行打分,然后把Pod绑定到合适的节点上。一个集群内可以存在多个scheduler,而 kube-scheduler 是一个参考实现。
这段话简单概括下就是:当有 pod 需要 scheduler 调度的时候, scheduler 会根据一些列规则挑选出最符合的节点,然后将Pod绑定到这个Node。
所以 scheduler 主要要做的事就是根据 Nodes 当前状态和 pod 对资源的需求,按照顺序运行一系列指定的算法来挑选出一个Node。
我们可以通过下图,对上述说的列算法有一个初步的认识,后面我们在展开详细说

如图中所示,图中每一个绿色箭头在k8s中叫扩展点(extension point),从图中可以看到一共有10个扩展点,我们可以分个类,如下图
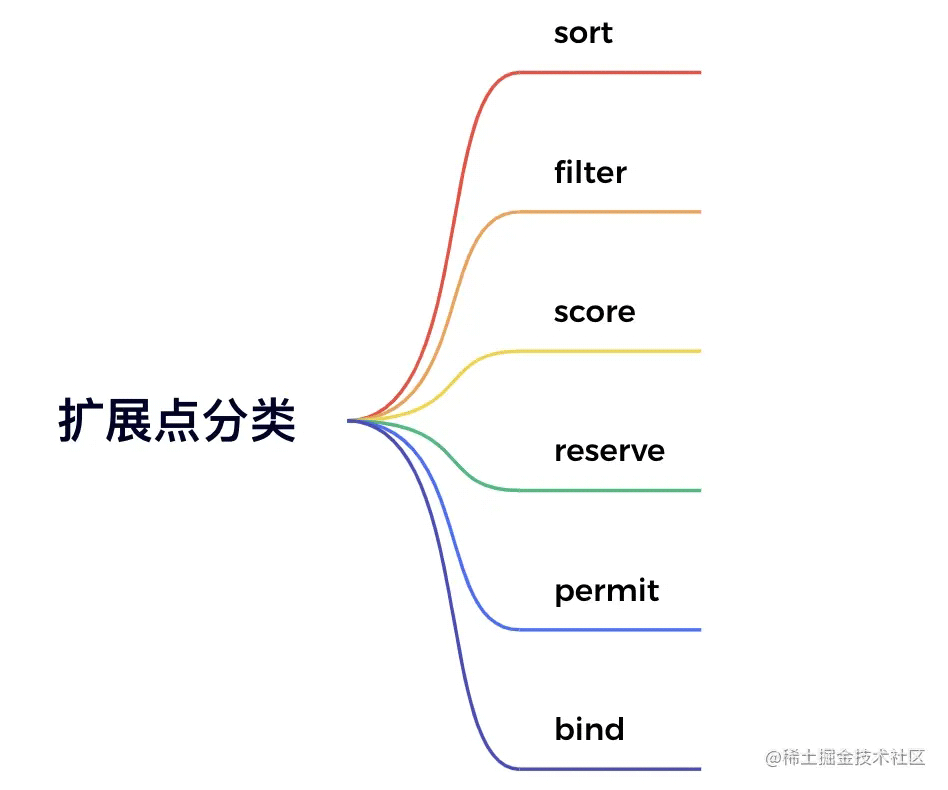
每一个扩展点可以运行一个或多个算法,在k8s中把这种算法叫做插件(Plugin)。顾名思义,扩展点就是可以扩展的,所以用户可以开发自己的插件嵌入扩展点中,我们既可以将自己开发的插件和系统默认插件同时运行,也可以关闭系统自带的插件只运行自己的插件,这部分在后面开发实践阶段会详细介绍。
各个类型扩展点
- sort
sort 类型的扩展点只有一个:sort,而且这个扩展点下面只能有一个插件可以运行,如果同时 enable 多个 sort 插件,scheduler 会退出。
在 k8s 中,待调度的 Pod 会放在一个叫 activeQ 队列中,这个队列是一个基于堆实现的优先队列(priority queue),为什么是优先队列呢?
因为你可以对 Pod 设置优先级,将你认为需要优先调度的 Pod 优先级调大,如果队列里有多个 Pod 需要调度,就会出现抢占现象,优先级高的 Pod 会移动到队列头部,scheduler 会优先取出这个 Pod 进行调度。那么这个优先级怎么设置呢?有两种方法:
- 如使用 k8s 默认 sort 插件,则可以给 Pod (deployment等方式) 设置 PriorityClass(创建 PriorityClass 资源并配置deployment);如果你的所有 Pod 都没有设置 PriorityClass,那么会根据 Pod 创建的时间先后顺序进行调度。PriorityClass 和 Pod 创建时间是系统默认的排序依据。
- 实现自己的 sort 插件定制排序算法,根据该排序算法实现抢占,例如你可以将包含特定标签的 Pod 移到队头。后面会详细讲述如何实现自己的插件来改变系统默认行为。
- filter
filter 类型扩展点有3个:prefilter,filter,postfilter。各个扩展点有多个插件组成的插件集合根据 Pod 的配置共同过滤 Node,如下图:

preFilter 扩展点主要有两个作用,一是为后面的扩展点计算 Pod 的一些信息,例如 preFilter 阶段的 NodeResourcesFit 算法不会去判断节点合适与否,而是计算这个Pod需要多少资源,然后存储这个信息,在 filter 扩展点的 NodeResourcesFit 插件中会把之前算出来的资源拿出来做判断;另外一个作用就是过滤一些明显不符合要求的节点,这样可以减少后续扩展点插件一些无意义的计算。
filter 扩展点主要的作用就是根据各个插件定义的顺序依次执行,筛选出符合 Pod 的节点,这些插件会在 preFilter 后留下的每个 Node 上运行,如果能够通过所有插件的”考验“,那么这个节点就留下来了。如果某个插件判断这个节点不符合,那么剩余的所有插件都不会对该节点做计算。
postFilter 扩展点只会在filter结束后没有任何 Node 符合 Pod 的情况下才会运行,否则这个扩展点会被跳过。我们可以看到,这个扩展点在系统只有一个默认的插件, 这个默认插件的作用遍历这个 Pod 所在的命名空间下面的所有 Pod,查找是否有可以被抢占的 Pod,如果有的话选出一个最合适的 Pod 然后 delete 掉这个Pod,并在待调度的 Pod 的 status 字段下面配置 nominateNode 为这个被抢占的 Pod。
- score
这个类型的扩展点的作用就是为上面 filter 扩展点筛选出来的所有 Node 进行打分,挑选出一个得分最高(最合适的),这个 Node 就是 Pod 要被调度上去的节点。这个这个类型的扩展有 preScore 和 score 两个,前者是为后者打分做前置准备的,preScore 的各个插件会计算一些信息供 score使用,这个和 prefilter 比较类似。
- reserve
reserve 类型扩展点系统默认只实现了一个插件:VolumeBinding,更新 Pod 声明的 PVC 和对应的 PV缓存信息,表示该 PV 已经被 Pod占用。
- permit
该类型扩展点,系统没有实现默认的插件,我们就不说了
- bind
该类型扩展点有三个扩展点:preBind、bind和postBind。
preBind 扩展点有一个内置插件 VolumeBinding,这个插件会调用 pv controller 完成绑定操作,在前面的 reserve 也有同名插件,这个插件只是更新了本地缓存中的信息,没有实际做绑定。
bind 扩展点也只有一个默认的内置插件:DefaultBinder,这个插件只做了一件很简单的事,将 Pod.Spec.nodeName 更新为选出来的那个 node。后面的“故事”就是 kubelet 监听到了 nodeName=Kubelet所在nodename,然后开始创建Pod(容器)。 到了这里,整个调度流程就结束了。
从文章开头的那张图中我们能够看到 scheduler 分两个 cycle: scheduling cycle 和 binding cycle。区分这两个 cycle 的原因是为了提升调度效率。从上面的描述中我们能够看到,在 bind cycle 中,会有两次外部 api 调用:调用 pv controller 绑定 pv 和调用 kube-apiserver 绑定 Node,api调用是耗时的,所以将 bind 扩展点拆分出来,另起一个 go 协程进行 bind。而在 scheduling cycle 中为了提升效率的一个重要原则就是 Pod、 Node 等信息从本地缓存中获取,而具体的实现原理就是先使用 list 获取所有 Node、Pod 的信息,然后再 watch 他们的变化更新本地缓存。
上面我们主要从扩展点和插件方面说明了 scheduler 的架构。下面我们从源码架构说说 scheduler 是怎么工作。
kube-scheduler 代码的主要框架
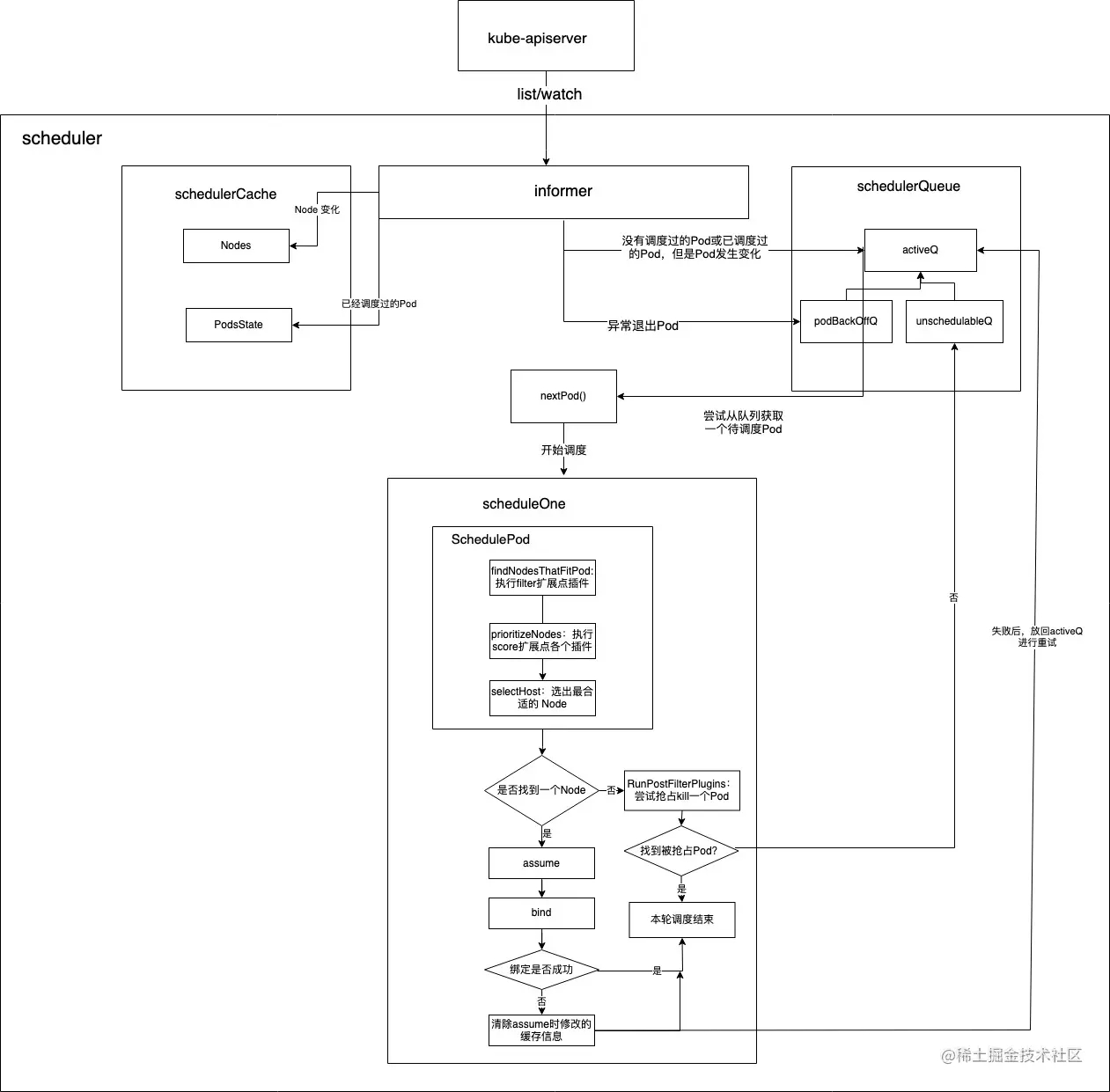
我们先来看看 kube-scheduler 中的几个关键组件
- schedulerCache
schedulerCache 缓存 Pod,Node 等信息,各个扩展点的插件在计算时所需要的 Node 和 Pod 信息都是从 schedulerCache 获取。schedulerCache 具体在内部是一个实现了 Cache 接口的 结构体 cacheImpl,我们看下这个结构体:
type cacheImpl struct {
stop <-chan struct{}
ttl time.Duration
period time.Duration
// This mutex guards all fields within this cache struct.
mu sync.RWMutex
// a set of assumed pod keys.
// The key could further be used to get an entry in podStates.
assumedPods sets.String
// a map from pod key to podState.
podStates map[string]*podState
nodes map[string]*nodeInfoListItem
// headNode points to the most recently updated NodeInfo in "nodes". It is the
// head of the linked list.
headNode *nodeInfoListItem
nodeTree *nodeTree
// A map from image name to its imageState.
imageStates map[string]*imageState
}
说他是缓存,从这个结构体可以看到,实际上就是map,用来存储 Pod 和 Node 的信息。那么这些数据是怎么来的呢?我们来看下一个组件informer
- informer
informer 是 client-go 提供的能力,他的作用是监听目标资源的变化,同步到本地缓存。几乎,在 k8s 的所有组件包括 controller-manager,kube-proxy,kubelet 等都使用了 informer 来监听 kube-apiserver 来获取资源的变化。举个例子,比如你执行了 kubectl edit 命令改变了一个 deployment 的镜像版本,k8s 是怎么感知到这个变化,进一步做 Pod 的重建的工作的呢?就是 kube-scheduler 使用了 informer 来监听 Pod 的变化实现的。
具体来说,kube-scheduler 使用 informer 监听了:Node, Pod, CSINode, CSIDriver, CSIStorageCapacity, PersistentVolume, PersistentVolumeClaim, StorageClass。监听 Node,Pod 我们可以理解,那么为什么要监听后面那些资源呢?后面的那些资源都是跟存储有关,在 preFilter 和 filter 扩展点的插件里面有 Volumebinding 这么一个插件,是检查系统当前是否能够满足 Pod 声明的 PVC,如果不能满足,那么只能把 Pod 放入 unscheduleableQ 里。但是,后续如果系统如果可以满足 Pod 对存储的需要了,这个 Pod 需要第一时间能够被创建出来,所以系统必须要能够实时感知到系统 PVC 等资源的变化及时将 unscheduleableQ 里面调度失败的 Pod 进行重新调度。这就是 informer 存在的意义了。具体的 informer 的实现原理可以参考这篇文章。
- schedulerQueue
schedulerQueue包含三个队列:activeQ, podBackoffQ,unschedulablePods。
activeQ 是一个优先队列,基于堆实现,用于存放待调度的 Pod,优先级高的会放在队列头部,优先被调度。该队列存放的 Pod 可能的情况有:刚创建未被调度的Pod;backOffPod 队列中转移过来的Pod;unschedule 队列里转移过来的 Pod。
podBackoffQ 也是一个优先队列,用于存放那些异常的Pod,这种 Pod 需要等待一定的时间才能够被再次调度,会有协程定期去读取这个队列,然后加入到 activeQ 队列然后重新调度。
unschedulablePods 严格上来说不属于队列,用于存放调度失败的 Pod。这个队列也会有协程定期(默认30s)去读取,然后判断当前时间距离上次调度时间的差是否超过5Min,如果超过这个时间则把 Pod 移动到 activeQ 重新调度。
func (p *PriorityQueue) Run() {
go wait.Until(p.flushBackoffQCompleted, 1.0*time.Second, p.stop)
go wait.Until(p.flushUnschedulablePodsLeftover, 30*time.Second, p.stop)
}
说完这几个组件,我们再来看看,当一个新的 Pod 创建出来后,这个流程是怎么走的
- informer 监听到了有新建 Pod,根据 Pod 的优先级把 Pod 加入到 activeQ 中适当位置(即执行sort插件);
- scheduler 从 activeQ 队头取一个Pod(如果队列没有Pod可取,则会一直阻塞;此时假设就是上述说的新建的 Pod),开始调度;
- 执行 filter 类型扩展点(包括preFilter,filter,postFilter)插件,选出所有符合 Pod 的 Node,如果无法找到符合的 Node, 则把 Pod 加入 unscheduleableQ 中,此次调度结束;
- 执行 score 扩展点插件,找出最符合 Pod 的 那个Node;
- assume Pod。这一步就是乐观假设 Pod 已经调度成功,更新缓存中 Node 和 PodStats 信息,到了这里scheduling cycle就已经结束了,然后会开启新的一轮调度。至于真正的绑定,则会新起一个协程。
- 执行 reserve 插件;
- 启动协程绑定 Pod 到 Node上。实际上就是修改 Pod.spec.nodeName: 选定的node名字,然后调用 kube-apiserver 接口写入 etcd。如果绑定失败了,那么移除缓存中此前加入的信息,然后把 Pod 放入activeQ 中,后续重新调度。
- 执行 postBinding,该步没有实现的插件没所以没有做任何事。
以上就是 kube-scheduler 的基本原理。
在后面的文章中,我们会继续聊聊 kube-scheduler 是怎么初始化出来的,要想开发一个自己的插件要做哪些事,更多关于Go kube-scheduler架构的资料请关注我们其它相关文章!
相关推荐
-
Kubernetes scheduler启动监控资源变化解析
目录 确立目标 run Scheduler NodeName Informer Shared Informer PodInformer Reflect Summary 确立目标 理解kube-scheduler启动的流程 了解Informer是如何从kube-apiserver监听资源变化的情况 理解kube-scheduler启动的流程 代码在cmd/kube-scheduler run // kube-scheduler 类似于kube-apiserver,是个常驻进程,查看其对应的Run函
-
vue3调度器effect的scheduler功能实现详解
目录 一.调度执行 二.单元测试 三.代码实现 四.回归实现 五.结语 一.调度执行 说到scheduler,也就是vue3的调度器,可能大家还不是特别明白调度器的是什么,先大概介绍一下. 可调度性是响应式系统非常重要的特性.首先我们要明确什么是可调度性.所谓可调度性,指的是当trigger 动作触发副作用函数重新执行时,有能力决定副作用函数执行的时机.次数以及方式. 有了调度函数,我们在trigger函数中触发副作用函数重新执行时,就可以直接调用用户传递的调度器函数,从而把控制权交给用户. 举
-
Go语言kube-scheduler深度剖析开发之scheduler初始化
目录 引言 Scheduler之Profiles Scheduler 之 SchedulingQueue Scheduler 之 cache Scheduler 之 NextPod 和 SchedulePod 引言 为了深入学习 kube-scheduler,本系从源码和实战角度深度学 习kube-scheduler,该系列一共分6篇文章,如下: kube-scheduler 整体架构 本文 :初始化一个 scheduler 一个 Pod 是如何调度的 如何开发一个属于自己的scheduler插
-
Go语言kube-scheduler深度剖析与开发之pod调度
目录 正文 感知 Pod 取出 Pod 调度 Pod 正文 为了深入学习 kube-scheduler,本系从源码和实战角度深度学 习kube-scheduler,该系列一共分6篇文章,如下: kube-scheduler 整体架构 初始化一个 scheduler 本文: 一个 Pod 是如何调度的 如何开发一个属于自己的scheduler插件 开发一个 prefilter 扩展点的插件 开发一个 socre 扩展点的插件 上一篇文章我们讲了一个 kube-scheduler 是怎么初始化出来的
-
Go语言开发kube-scheduler整体架构深度剖析
目录 k8s 的调度器 kube-scheduler 官方描述scheduler 各个类型扩展点 kube-scheduler 代码的主要框架 k8s 的调度器 kube-scheduler kube-scheduler 作为 k8s 的调度器,就好比人的大脑,将行动指定传递到手脚等器官,进而执行对应的动作,对于 kube-scheduler 则是将 Pod 分配(调度)到集群内的各个节点,进而创建容器运行进程,对于k8s来说至关重要. 为了深入学习 kube-scheduler,本系从源码和实
-
你真的理解C语言qsort函数吗 带你深度剖析qsort函数
目录 一.前言 二.简单冒泡排序法 三.qsort函数的使用 1.qsort函数的介绍 2.qsort函数的运用 2.1.qsort函数排序整型数组 2.2.qsort函数排序结构体 四.利用冒泡排序模拟实现qsort函数 五.总结 一.前言 我们初识C语言时,会做过让一个整型数组按照从小到大来排序的问题,我们使用的是冒泡排序法,但是如果我们想要比较其他类型怎么办呢,显然我们当时的代码只适用于简单的整形排序,对于结构体等没办法排序,本篇将引入一个库函数来实现我们希望的顺序. 二.简单冒泡排序法
-
jQuery 2.0.3 源码分析之core(一)整体架构
拜读一个开源框架,最想学到的就是设计的思想和实现的技巧. 废话不多说,jquery这么多年了分析都写烂了,老早以前就拜读过, 不过这几年都是做移动端,一直御用zepto, 最近抽出点时间把jquery又给扫一遍 我也不会照本宣科的翻译源码,结合自己的实际经验一起拜读吧! github上最新是jquery-master,加入了AMD规范了,我就以官方最新2.0.3为准 整体架构 jQuery框架的核心就是从HTML文档中匹配元素并对其执行操作. 例如: 复制代码 代码如下: $().find().
-

Go语言开发浏览器视频流rtsp转webrtc播放
目录 1. 前言 2. rtsp转webRTC 3. 初步测试结果 4. 结合我们之前的onvif+gSoap+cgo的方案做修改 4.1 go后端修改 4.2 前端修改 4.3 项目结构和编译运行 4.4 结果展示 5. 最后 1. 前言 前面我们测试了rtsp转hls方式,发现延迟比较大,不太适合我们的使用需求.接下来我们试一下webrtc的方式看下使用情况. 综合考虑下来,我们最好能找到一个go作为后端,前端兼容性较好的前后端方案来处理webrtc,这样我们就可以结合我们之前的cgo+on
-
Go语言开发编程规范命令风格代码格式
前言 今天这篇文章是站在巨人的肩膀上,汇总了目前主流的开发规范,同时结合Go语言的特点,以及自己的项目经验总结出来的:爆肝分享两千字Go编程规范. 后续还会更新更多优雅的规范. 命名风格 1. [强制]代码中的命名均不能以下划线或美元符号开始,也不能以下划线或美元符号结束. 反 例 : _name / __name / $name / name_ / name$ / name__ 2. [强制]代码中的命名严禁使用拼音与英文混合的方式,更不允许直接使用中文的方式. 说明:正确的英文拼写和语法可以
-
ahooks整体架构及React工具库源码解读
目录 引言 React hooks utils 库 ahooks 简介 特点 hooks 种类 ahooks 整体架构 项目启动 整体结构 hooks 总结 引言 本文是深入浅出 ahooks 源码系列文章的第一篇,这个系列的目标主要有以下几点: 加深对 React hooks 的理解. 学习如何抽象自定义 hooks.构建属于自己的 React hooks 工具库. 培养阅读学习源码的习惯,工具库是一个对源码阅读不错的选择. 注:本系列对 ahooks 的源码解析是基于 v3.3.13.自己
-
thinkPHP5.0框架整体架构总览【应用,模块,MVC,驱动,行为,命名空间等】
本文讲述了thinkPHP5.0框架整体架构.分享给大家供大家参考,具体如下: ThinkPHP5.0应用基于MVC(模型-视图-控制器)的方式来组织. MVC是一个设计模式,它强制性的使应用程序的输入.处理和输出分开.使用MVC应用程序被分成三个核心部件:模型(M).视图(V).控制器(C),它们各自处理自己的任务. 5.0的URL访问受路由决定,如果关闭路由或者没有匹配路由的情况下,则是基于: http://serverName/index.php(或者其它应用入口文件)/模块/控制器/操作
-
Go语言开发环境搭建与初探(Windows平台下)
Go语言开发环境的搭建(Windows) Windows下的Go语言开发安装包 官方下载地址: https://code.google.com/p/go/downloads/list 我们下载地址:http://www.jb51.net/softs/237132.html Go语言中文官网(有相关参考和文档) http://zh.golanger.com/ 方法/步骤 1.在Go语言的Google代码项目上下载Windows下的Go语言开发包(下载地址见工具).有zip压缩版和msi安装版两个按
-
CentOS 7下配置Ruby语言开发环境的方法教程
本文跟大家分享的是在CentOS 7下配置Ruby语言开发环境的方法教程,分享出来供大家参考学习,下面来看看详细的介绍: 安装Ruby 2.2 CentOS7存储库中的Ruby版本为2.0,但如果需要,可以使用RPM软件包安装2.2 1.添加CentOS SCLo软件集合存储库 [root@linuxprobe ~]# yum -y install centos-release-scl-rh centos-release-scl # set [priority=10] [root@linuxpr