python合并RepeatMasker预测结果中染色体的overlap区域
目录
- 前言
- 问题
- 思路
- 1. 预处理
- 2. 将pretreatment.txt作为输入文件,
- 3.去重+归并排序
- 4.开始比对,gap=50
- 5.将new_result.txt作为输出文件,生成结果
- 6. 完整代码
前言
RepeatMasker是一个通过已有数据库预测重复序列的软件,可以筛选DNA序列中的散在重复序列和低复杂序列,是重复序列注释的重要软件。
问题
我们想对RepeatMasker预测的结果文件进行重复序列的合并,也就是去除染色体之间的overlap区域同时将基因间距小于50个bp的也同样视为overlap,我们应该如何用python处理并生成新的预测结果?
思路
- 首先需要对文件进行预处理提取出需要处理的列,'//'可以忽略
- 对相同染色体序列按照升序进行归并排序
- 分别取相应染色体按照滑动窗口的思路进行双指针比对,注意gap=50
1. 预处理
我们这里只需要结果文件的前三列,可以使用awk命令获取
awk '{for(i = 1; i <= 3; i++)
printf("%s ", $i);
printf("\n")}' result.txt > pretreatment.txt
#result.txt为结果文件,pretreatment.txt为预处理结果文件
2. 将pretreatment.txt作为输入文件,
with open ('pretreatment.txt','r')as f:
for i in f.readlines():
if i.strip() == '//':
continue
c = i.strip().split('\t')
b.append(c[0])
a.append((c[0],int(c[1]),int(c[2])))
print ("全部染色体数量: "+str(len(a)))
3.去重+归并排序
c = [i for i in b_set if b.count(i) == 1]
for i in a:
if i[0] not in c:
continue
a.remove(i)
result.append((i[0],int(i[1]),int(i[2])))
print ("去重后染色体数量: "+str(len(a)))
a.sort(key = lambda x : (x[0], x[1], x[2])) #按照第一列,第二列,第三列分别排降升序
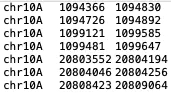
4.开始比对,gap=50
q = ''
start = 0
end = 0
tem1 = []
tem2 = []
gap = 50
for i in a:
if i[0] != q:
if tem1:
if tem1 not in tem2:
tem2.append(tem1)
tem1 = []
q = I[0]
start = int(i[1])
end = int(i[2])
continue
if int(i[1]) < end or int(i[1]) - end < gap:
if int(i[2]) > end:
end = int(i[2])
continue
else:
continue
tem1.append([q,start,end])
start = int(i[1])
end = int(i[2])
5.将new_result.txt作为输出文件,生成结果
with open ('new_result.txt','w')as f:
for i in tem2:
for o in I:
print (o[0],o[1],o[2],file=f)
for i in result:
print (i[0],i[1],i[2],file=f)
6. 完整代码
a = []
b = []
with open ('pretreatment.txt','r')as f:
for i in f.readlines():
if i.strip() == '//':
continue
c = i.strip().split('\t')
b.append(c[0])
a.append((c[0],int(c[1]),int(c[2])))
print ("全部染色体数量: "+str(len(a)))
b_set = set(b)
result = []
c = [i for i in b_set if b.count(i) == 1]
for i in a:
if i[0] not in c:
continue
a.remove(i)
result.append((i[0],int(i[1]),int(i[2])))
print ("去重后染色体数量: "+str(len(a)))
a.sort(key = lambda x : (x[0], x[1], x[2]))
q = ''
start = 0
end = 0
tem1 = []
tem2 = []
gap = 50
for i in a:
if i[0] != q:
if tem1:
if tem1 not in tem2:
tem2.append(tem1)
tem1 = []
q = I[0]
start = int(i[1])
end = int(i[2])
continue
if int(i[1]) < end or int(i[1]) - end < gap:
if int(i[2]) > end:
end = int(i[2])
continue
else:
continue
tem1.append([q,start,end])
start = int(i[1])
end = int(i[2])
with open ('new_result.txt','w')as f:
for i in tem2:
for o in I:
print (o[0],o[1],o[2],file=f)
for i in result:
print (i[0],i[1],i[2],file=f)
以上就是python合并RepeatMasker预测结果中染色体的overlap区域的详细内容,更多关于python RepeatMasker预测overlap的资料请关注我们其它相关文章!
相关推荐
-

关于Numpy之repeat、tile的用法总结
repeat函数的作用:①扩充数组元素 ②降低数组维度 numpy.repeat(a, repeats, axis=None):若axis=None,对于多维数组而言,可以将多维数组变化为一维数组,然后再根据repeats参数扩充数组元素:若axis=M,表示数组在轴M上扩充数组元素. 下面以3维数组为例,了解下repeat函数的使用方法: In [1]: import numpy as np In [2]: arr = np.arange(12).reshape(1,4,3) In [3]:
-
Python Numpy数组扩展repeat和tile使用实例解析
这篇文章主要介绍了Python Numpy数组扩展repeat和tile使用实例解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 numpy.repeat 官方文档 numpy.repeat(a, repeats, axis=None) Repeat elements of an array. 可以看出repeat函数是操作数组中的每一个元素,进行元素的复制. 例如: >>> a = np.arange(3) >>>
-
Numpy中的repeat函数使用
Numpy中repeat函数使用 Numpy是Python强大的数学计算库,和Scipy一起构建起Python科学计算生态.在本节下面我们重点介绍下repeat函数的用法,我们在Python中import numpy,help(numpy.repeat),会出现以下界面: repeat是属于ndarray对象的方法,使用它可以通过两个管道: (1)numpy.repeat(a,repeats,axis=None); (2)object(ndarray).repeat(repeats,axis=N
-
python合并RepeatMasker预测结果中染色体的overlap区域
目录 前言 问题 思路 1. 预处理 2. 将pretreatment.txt作为输入文件, 3.去重+归并排序 4.开始比对,gap=50 5.将new_result.txt作为输出文件,生成结果 6. 完整代码 前言 RepeatMasker是一个通过已有数据库预测重复序列的软件,可以筛选DNA序列中的散在重复序列和低复杂序列,是重复序列注释的重要软件. 问题 我们想对RepeatMasker预测的结果文件进行重复序列的合并,也就是去除染色体之间的overlap区域同时将基因间距小于50个b
-
python 合并多个excel中同名的sheet
大家好~ 老Amy来啦!已经n久没有给大家输出关于办公自动化的文章了-为什么呢?罗列原因: 太忙!(被领导"压榨") 太忙!(没有额外的精力揣测大家办公的需求) 太忙!(持续吃瓜中) 然鹅,一位朋友的困惑成为了我这种"麻木状态"的终结者,他提出需求如下: 想不断尝试的老Amy,开启了思考模式:"我要怎么实现这个需求呢?". 不用着急,首先我们来分析数据本身. 分析数据特征如下: 数据所在路径 C:\Users\logic\Desktop\myte
-
Python合并字典键值并去除重复元素的实例
假设在python中有一字典如下: x={'a':'1,2,3', 'b':'2,3,4'} 需要合并为: x={'c':'1,2,3,4'} 需要做到三件事: 1. 将字符串转化为数值列表 2. 合并两个列表并添加新的键值 3. 去除重复元素 第1步通过常用的函数eval()就可以做到了,第2步需要添加一个键值并添加元素,第3步利用set集合的性质可以达到去重的效果,不过最后需要再将set集合转化为list列表.代码如下: x={'a':'1,2,3','b':'2,3,4'} x['c']=
-
Python编程实现从字典中提取子集的方法分析
本文实例讲述了Python编程实现从字典中提取子集的方法.分享给大家供大家参考,具体如下: 首先我们会想到使用字典推导式(dictionary comprehension)来解决这个问题,例如以下场景: prices={'ACME':45.23,'APPLE':666,'IBM':343,'HPQ':33,'FB':10} #选出价格大于 200 的 gt200={key:value for key,value in prices.items() if value > 200} print(gt
-
Python合并多个Excel数据的方法
安装模块 1.找到对应的模块 http://www.python-excel.org/ 2.用pip install 安装 pip install xlrd pip install XlsxWriter pip list查看 XlsxWriter示例 import xlsxwriter # 创建一个工作簿并添加一个工作表 workbook = xlsxwriter.Workbook("demo.xlsx") worksheet = workbook.add_worksheet()
-
如何用Python合并lmdb文件
由于Caffe使用的存储图像的数据库是lmdb,因此有时候需要对lmdb文件进行操作,本文主要讲解如何用Python合并lmdb文件.没有lmdb支持的,需要用pip命令安装. pip install lmdb 代码及注释如下: # coding=utf-8 # filename: merge_lmdb.py import lmdb # 将两个lmdb文件合并成一个新的lmdb def merge_lmdb(lmdb1, lmdb2, result_lmdb): print 'Merge sta
-
Python机器学习之scikit-learn库中KNN算法的封装与使用方法
本文实例讲述了Python机器学习之scikit-learn库中KNN算法的封装与使用方法.分享给大家供大家参考,具体如下: 1.工具准备,python环境,pycharm 2.在机器学习中,KNN是不需要训练过程的算法,也就是说,输入样例可以直接调用predict预测结果,训练数据集就是模型.当然这里必须将训练数据和训练标签进行拟合才能形成模型. 3.在pycharm中创建新的项目工程,并在项目下新建KNN.py文件. import numpy as np from math import s
-
使用 Python 合并多个格式一致的 Excel 文件(推荐)
一 问题描述 最近朋友在工作中遇到这样一个问题,她每天都要处理如下一批 Excel 表格:每个表格的都只有一个 sheet,表格的前两行为表格标题及表头,表格的最后一行是相关人员签字.最终目标是将每个表格的内容合并到一个 Excel 表格中,使之成为一张表格.在她未咨询我之前,每天复制粘贴这一类操作占用了她绝大部分时间.表格样式如下: 二 需求分析 根据她的描述,最终需求应该是这样的:在这一批表格中选取任意一个表格的前两行作为新表格的标题与表头,将这两行内容以嵌套列表的形式插入一个名为 data
-
Python合并2个字典成1个新字典的方法(9种)
字典是Python语言中唯一的映射类型. 映射类型对象里哈希值(键,key)和指向的对象(值,value)是一对多的的关系,通常被认为是可变的哈希表. 字典对象是可变的,它是一个容器类型,能存储任意个数的Python对象,其中也可包括其他容器类型. 字典类型与序列类型的区别: 1. 存取和访问数据的方式不同. 2. 序列类型只用数字类型的键(从序列的开始按数值顺序索引): 3. 映射类型可以用其他对象类型作键(如:数字.字符串.元祖,一般用字符串作键),和序列类型的键不同,映射类型的键直4.接或
-
详解用Python进行时间序列预测的7种方法
数据准备 数据集(JetRail高铁的乘客数量)下载. 假设要解决一个时序问题:根据过往两年的数据(2012 年 8 月至 2014 年 8月),需要用这些数据预测接下来 7 个月的乘客数量. import pandas as pd import numpy as np import matplotlib.pyplot as plt df = pd.read_csv('train.csv') df.head() df.shape 依照上面的代码,我们获得了 2012-2014 年两年每个小时的乘