基于Tensorflow搭建一个神经网络的实现
一、Tensorlow结构
import tensorflow as tf
import numpy as np
#创建数据
x_data = np.random.rand(100).astype(np.float32)
y_data = x_data*0.1+0.3
#创建一个 tensorlow 结构
weights = tf.Variable(tf.random_uniform([1], -1.0, 1.0))#一维,范围[-1,1]
biases = tf.Variable(tf.zeros([1]))
y = weights*x_data + biases
loss = tf.reduce_mean(tf.square(y - y_data))#均方差函数
#建立优化器,减少误差,提高参数准确度,每次迭代都会优化
optimizer = tf.train.GradientDescentOptimizer(0.5)#学习率为0.5(<1)
train = optimizer.minimize(loss)#最小化损失函数
#初始化不变量
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
#train
for step in range(201):
sess.run(train)
if step % 20 == 0:
print(step, sess.run(weights), sess.run(biases))
二、session的使用
import tensorflow as tf matrix1 = tf.constant([[3, 3]]) matrix2 = tf.constant([[2], [2]]) product = tf.matmul(matrix1, matrix2) #method1 sess = tf.Session() result2 = sess.run(product) print(result2) #method2 # with tf.Session() as sess: # result2 = sess.run(product) # print(result2)
三、Variable的使用
import tensorflow as tf
state = tf.Variable(0, name = 'counter')#变量初始化
# print(state.name)
one = tf.constant(1)
new_value = tf.add(state, one)
#将state用new_value代替
updata = tf.assign(state, new_value)
#变量激活
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
for _ in range(3):
sess.run(updata)
print(sess.run(state))
四、placeholder的使用
#给定type,tf大部分只能处理float32数据
input1 = tf.placeholder(tf.float32)
input2 = tf.placeholder(tf.float32)
output = tf.multiply(input1, input2)
with tf.Session() as sess:
print(sess.run(output, feed_dict={input1:[7.], input2:[2.]}))
五、激活函数 六、添加层
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
def add_layer(inputs, in_size, out_size, activation_function = None):
Weights = tf.Variable(tf.random_normal([in_size, out_size]))#正态分布
biases = tf.Variable(tf.zeros([1, out_size])+0.1) #1行,out_size列,初始值不推荐为0,所以加上0.1
Wx_plus_b = tf.matmul(inputs, Weights) + biases #Weights*x+b的初始化值,也是未激活的值
#激活
if activation_function is None:
#如果没有设置激活函数,,则直接把当前信号原封不动的传递出去
outputs = Wx_plus_b
else:
#如果设置了激活函数,则由此激活函数对信号进行传递或抑制
outputs = activation_function(Wx_plus_b)
return outputs
七、创建一个神经网络
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
def add_layer(inputs, in_size, out_size, activation_function = None):
Weights = tf.Variable(tf.random_normal([in_size, out_size]))#正态分布
biases = tf.Variable(tf.zeros([1, out_size])+0.1) #1行,out_size列,初始值不推荐为0,所以加上0.1
Wx_plus_b = tf.matmul(inputs, Weights) + biases #Weights*x+b的初始化值,也是未激活的值
#激活
if activation_function is None:
#如果没有设置激活函数,,则直接把当前信号原封不动的传递出去
outputs = Wx_plus_b
else:
#如果设置了激活函数,则由此激活函数对信号进行传递或抑制
outputs = activation_function(Wx_plus_b)
return outputs
"""定义数据形式"""
#创建一列(相当于只有一个属性值),(-1,1)之间,有300个单位,后面是维度,x_data是有300行
x_data = np.linspace(-1, 1, 300)[:, np.newaxis]#np.linspace在指定间隔内返回均匀间隔数字
#加入噪声,均值为0,方差为0.05,形状和x_data一样
noise = np.random.normal(0, 0.05, x_data.shape)
#定义y的函数为二次曲线函数,同时增加一些噪声数据
y_data = np.square(x_data) - 0.5 + noise
#定义输入值,输入结构的输入行数不固定,但列就是1列的值
xs = tf.placeholder(tf.float32, [None, 1])
ys = tf.placeholder(tf.float32, [None, 1])
"""建立网络"""
#定义隐藏层,输入为xs,输入size为1列,因为x_data只有一个属性值,输出size假定有10个神经元的隐藏层,激活函数relu
l1 = add_layer(xs, 1, 10, activation_function=tf.nn.relu)
#定义输出层,输出为l1输入size为10列,也就是l1的列数,输出size为1,这里的输出类似y_data,因此为1列
prediction = add_layer(l1, 10, 1,activation_function=None)
"""预测"""
#定义损失函数为差值平方和的平均值
loss = tf.reduce_mean(tf.reduce_sum(tf.square(ys-prediction),reduction_indices=[1]))
"""训练"""
#进行逐步优化的梯度下降优化器,学习率为0.1,以最小化损失函数进行优化
train_step = tf.train.GradientDescentOptimizer(0.1).minimize(loss)
#初始化模型所有参数
init = tf.global_variables_initializer()
#可视化
with tf.Session() as sess:
sess.run(init)
for i in range(1000):#学习1000次
sess.run(train_step, feed_dict={xs:x_data, ys:y_data})
if i%50==0:
print(sess.run(loss, feed_dict={xs:x_data, ys:y_data}))
八、可视化
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
def add_layer(inputs, in_size, out_size, activation_function = None):
Weights = tf.Variable(tf.random_normal([in_size, out_size]))#正态分布
biases = tf.Variable(tf.zeros([1, out_size])+0.1) #1行,out_size列,初始值不推荐为0,所以加上0.1
Wx_plus_b = tf.matmul(inputs, Weights) + biases #Weights*x+b的初始化值,也是未激活的值
#激活
if activation_function is None:
#如果没有设置激活函数,,则直接把当前信号原封不动的传递出去
outputs = Wx_plus_b
else:
#如果设置了激活函数,则由此激活函数对信号进行传递或抑制
outputs = activation_function(Wx_plus_b)
return outputs
"""定义数据形式"""
#创建一列(相当于只有一个属性值),(-1,1)之间,有300个单位,后面是维度,x_data是有300行
x_data = np.linspace(-1, 1, 300)[:, np.newaxis]#np.linspace在指定间隔内返回均匀间隔数字
#加入噪声,均值为0,方差为0.05,形状和x_data一样
noise = np.random.normal(0, 0.05, x_data.shape)
#定义y的函数为二次曲线函数,同时增加一些噪声数据
y_data = np.square(x_data) - 0.5 + noise
#定义输入值,输入结构的输入行数不固定,但列就是1列的值
xs = tf.placeholder(tf.float32, [None, 1])
ys = tf.placeholder(tf.float32, [None, 1])
"""建立网络"""
#定义隐藏层,输入为xs,输入size为1列,因为x_data只有一个属性值,输出size假定有10个神经元的隐藏层,激活函数relu
l1 = add_layer(xs, 1, 10, activation_function=tf.nn.relu)
#定义输出层,输出为l1输入size为10列,也就是l1的列数,输出size为1,这里的输出类似y_data,因此为1列
prediction = add_layer(l1, 10, 1,activation_function=None)
"""预测"""
#定义损失函数为差值平方和的平均值
loss = tf.reduce_mean(tf.reduce_sum(tf.square(ys-prediction),reduction_indices=[1]))
"""训练"""
#进行逐步优化的梯度下降优化器,学习率为0.1,以最小化损失函数进行优化
train_step = tf.train.GradientDescentOptimizer(0.1).minimize(loss)
#初始化模型所有参数
init = tf.global_variables_initializer()
#可视化
with tf.Session() as sess:
sess.run(init)
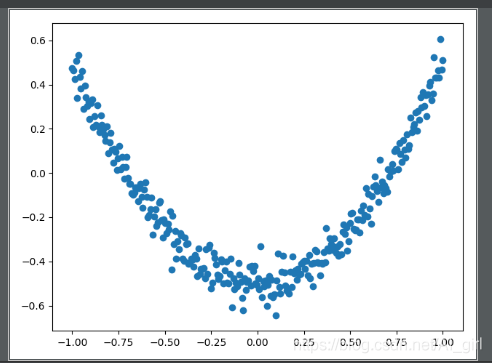
fig = plt.figure()#先生成一个图片框
#连续性画图
ax = fig.add_subplot(1, 1, 1)#编号为1,1,1
ax.scatter(x_data, y_data)#画散点图
#不暂停
plt.ion()#打开互交模式
# plt.show()
#plt.show绘制一次就暂停了
for i in range(1000):#学习1000次
sess.run(train_step, feed_dict={xs:x_data, ys:y_data})
if i%50==0:
try:
#画出一条后,抹除掉,去除第一个线段,但是只有一个相当于抹除当前线段
ax.lines.remove(lines[0])
except Exception:
pass
prediction_value = sess.run(prediction, feed_dict={xs:x_data})
lines = ax.plot(x_data,prediction_value,'r-',lw=5)#lw线宽
#暂停
plt.pause(0.5)
可视化结果:
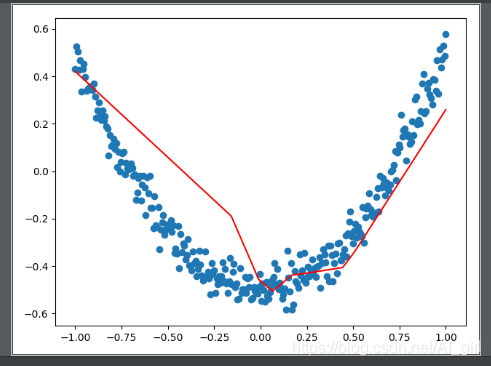
动图效果如下所示:

到此这篇关于基于Tensorflow搭建一个神经网络的实现的文章就介绍到这了,更多相关Tensorflow搭建神经网络内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

tensorflow建立一个简单的神经网络的方法
本笔记目的是通过tensorflow实现一个两层的神经网络.目的是实现一个二次函数的拟合. 如何添加一层网络 代码如下: def add_layer(inputs, in_size, out_size, activation_function=None): # add one more layer and return the output of this layer Weights = tf.Variable(tf.random_normal([in_size, out_size])) bia
-
TensorFlow实现卷积神经网络CNN
一.卷积神经网络CNN简介 卷积神经网络(ConvolutionalNeuralNetwork,CNN)最初是为解决图像识别等问题设计的,CNN现在的应用已经不限于图像和视频,也可用于时间序列信号,比如音频信号和文本数据等.CNN作为一个深度学习架构被提出的最初诉求是降低对图像数据预处理的要求,避免复杂的特征工程.在卷积神经网络中,第一个卷积层会直接接受图像像素级的输入,每一层卷积(滤波器)都会提取数据中最有效的特征,这种方法可以提取到图像中最基础的特征,而后再进行组合和抽象形成更高阶的特征,因
-
TensorFlow神经网络优化策略学习
在神经网络模型优化的过程中,会遇到许多问题,比如如何设置学习率的问题,我们可通过指数衰减的方式让模型在训练初期快速接近较优解,在训练后期稳定进入最优解区域:针对过拟合问题,通过正则化的方法加以应对:滑动平均模型可以让最终得到的模型在未知数据上表现的更加健壮. 一.学习率的设置 学习率设置既不能过大,也不能过小.TensorFlow提供了一种更加灵活的学习率设置方法--指数衰减法.该方法实现了指数衰减学习率,先使用较大的学习率来快速得到一个比较优的解,然后随着迭代的继续逐步减小学习率,使得模型在训
-
tensorflow入门之训练简单的神经网络方法
这几天开始学tensorflow,先来做一下学习记录 一.神经网络解决问题步骤: 1.提取问题中实体的特征向量作为神经网络的输入.也就是说要对数据集进行特征工程,然后知道每个样本的特征维度,以此来定义输入神经元的个数. 2.定义神经网络的结构,并定义如何从神经网络的输入得到输出.也就是说定义输入层,隐藏层以及输出层. 3.通过训练数据来调整神经网络中的参数取值,这是训练神经网络的过程.一般来说要定义模型的损失函数,以及参数优化的方法,如交叉熵损失函数和梯度下降法调优等. 4.利用训练好的模型预测
-
Tensorflow实现AlexNet卷积神经网络及运算时间评测
本文实例为大家分享了Tensorflow实现AlexNet卷积神经网络的具体实现代码,供大家参考,具体内容如下 之前已经介绍过了AlexNet的网络构建了,这次主要不是为了训练数据,而是为了对每个batch的前馈(Forward)和反馈(backward)的平均耗时进行计算.在设计网络的过程中,分类的结果很重要,但是运算速率也相当重要.尤其是在跟踪(Tracking)的任务中,如果使用的网络太深,那么也会导致实时性不好. from datetime import datetime import
-
TensorFlow深度学习之卷积神经网络CNN
一.卷积神经网络的概述 卷积神经网络(ConvolutionalNeural Network,CNN)最初是为解决图像识别等问题设计的,CNN现在的应用已经不限于图像和视频,也可用于时间序列信号,比如音频信号和文本数据等.CNN作为一个深度学习架构被提出的最初诉求是降低对图像数据预处理的要求,避免复杂的特征工程.在卷积神经网络中,第一个卷积层会直接接受图像像素级的输入,每一层卷积(滤波器)都会提取数据中最有效的特征,这种方法可以提取到图像中最基础的特征,而后再进行组合和抽象形成更高阶的特征,因此
-
TensorFlow实现RNN循环神经网络
RNN(recurrent neural Network)循环神经网络 主要用于自然语言处理(nature language processing,NLP) RNN主要用途是处理和预测序列数据 RNN广泛的用于 语音识别.语言模型.机器翻译 RNN的来源就是为了刻画一个序列当前的输出与之前的信息影响后面节点的输出 RNN 是包含循环的网络,允许信息的持久化. RNN会记忆之前的信息,并利用之前的信息影响后面节点的输出. RNN的隐藏层之间的节点是有相连的,隐藏层的输入不仅仅包括输入层的输出,还包
-
基于Tensorflow搭建一个神经网络的实现
一.Tensorlow结构 import tensorflow as tf import numpy as np #创建数据 x_data = np.random.rand(100).astype(np.float32) y_data = x_data*0.1+0.3 #创建一个 tensorlow 结构 weights = tf.Variable(tf.random_uniform([1], -1.0, 1.0))#一维,范围[-1,1] biases = tf.Variable(tf.zer
-
使用TensorFlow搭建一个全连接神经网络教程
说明 本例子利用TensorFlow搭建一个全连接神经网络,实现对MNIST手写数字的识别. 先上代码 from tensorflow.examples.tutorials.mnist import input_data import tensorflow as tf # prepare data mnist = input_data.read_data_sets('MNIST_data', one_hot=True) xs = tf.placeholder(tf.float32, [None,
-
基于maven搭建一个ssm的web项目的详细图文教程
1:使用idea建立一个web项目 2:引入pom依赖 <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.
-
Tensorflow实现卷积神经网络用于人脸关键点识别
今年来人工智能的概念越来越火,AlphaGo以4:1击败李世石更是起到推波助澜的作用.作为一个开挖掘机的菜鸟,深深感到不学习一下deep learning早晚要被淘汰. 既然要开始学,当然是搭一个深度神经网络跑几个数据集感受一下作为入门最直观了.自己写代码实现的话debug的过程和运行效率都会很忧伤,我也不知道怎么调用GPU- 所以还是站在巨人的肩膀上,用现成的框架吧.粗略了解一下,现在比较知名的有caffe.mxnet.tensorflow等等.选哪个呢?对我来说选择的标准就两个,第一要容易安
-
Docker下搭建一个JAVA Tomcat运行环境的方法
前言 Docker旨在提供一种应用程序的自动化部署解决方案,在 Linux 系统上迅速创建一个容器(轻量级虚拟机)并部署和运行应用程序,并通过配置文件可以轻松实现应用程序的自动化安装.部署和升级,非常方便.因为使用了容器,所以可以很方便的把生产环境和开发环境分开,互不影响,这是 docker 最普遍的一个玩法.更多的玩法还有大规模 web 应用.数据库部署.持续部署.集群.测试环境.面向服务的云计算.虚拟桌面 VDI 等等. 主观的印象:Docker 使用 Go 语言编写,用 cgroup 实现
-
详解Docker学习笔记之搭建一个JAVA Tomcat运行环境
前言 Docker旨在提供一种应用程序的自动化部署解决方案,在 Linux 系统上迅速创建一个容器(轻量级虚拟机)并部署和运行应用程序,并通过配置文件可以轻松实现应用程序的自动化安装.部署和升级,非常方便.因为使用了容器,所以可以很方便的把生产环境和开发环境分开,互不影响,这是 docker 最普遍的一个玩法.更多的玩法还有大规模 web 应用.数据库部署.持续部署.集群.测试环境.面向服务的云计算.虚拟桌面 VDI 等等. 主观的印象:Docker 使用 Go 语言编写,用 cgroup 实现
-
运用PyTorch动手搭建一个共享单车预测器
本文摘自 <深度学习原理与PyTorch实战> 我们将从预测某地的共享单车数量这个实际问题出发,带领读者走进神经网络的殿堂,运用PyTorch动手搭建一个共享单车预测器,在实战过程中掌握神经元.神经网络.激活函数.机器学习等基本概念,以及数据预处理的方法.此外,还会揭秘神经网络这个"黑箱",看看它如何工作,哪个神经元起到了关键作用,从而让读者对神经网络的运作原理有更深入的了解. 3.1 共享单车的烦恼 大约从2016年起,我们的身边出现了很多共享单车.五颜六色.各式各样的共
-
R语言基于Keras的MLP神经网络及环境搭建
目录 Intro 环境搭建 本机电脑配置 安装TensorFlow以及Keras 安装R以及Rstudio 基于R语言的深度学习MLP 在Rstudio中安装Tensorflow和Keras MNIST数据集的预处理 深度学习MLP模型 总结和学习笔记 Intro R语言是我使用的第一种计算机语言,也是目前的主流数据分析语言之一,常常被人与python相比较.在EDA,制图和机器学习方面R语言拥有很多的的package可供选择.但深度学习方面由于缺少学习库以及合适的框架而被python赶超.但K
-
TensorFlow搭建神经网络最佳实践
一.TensorFLow完整样例 在MNIST数据集上,搭建一个简单神经网络结构,一个包含ReLU单元的非线性化处理的两层神经网络.在训练神经网络的时候,使用带指数衰减的学习率设置.使用正则化来避免过拟合.使用滑动平均模型来使得最终的模型更加健壮. 程序将计算神经网络前向传播的部分单独定义一个函数inference,训练部分定义一个train函数,再定义一个主函数main. 完整程序: #!/usr/bin/env python3 # -*- coding: utf-8 -*- ""&