python爬虫调度器用法及实例代码
我们一般使用爬虫看到的都是最后的数据结果,对于整个的获取过程没有过多了解过。对于初学python的小伙伴们来说,不光是代码的练习,还是原理的分析都是必不可少的。
小编把整个爬取的过程分为了几个部分,从一开始的下载,到数据的去重解析,再到整个爬虫循环的结束,以图片和代码的双重形式展现给大家,希望能够对爬虫调度器有一个深刻的理解。
我们可以编写几个元件,每个元件完成一项功能,下图中的蓝底白字就是对这一流程的抽象:
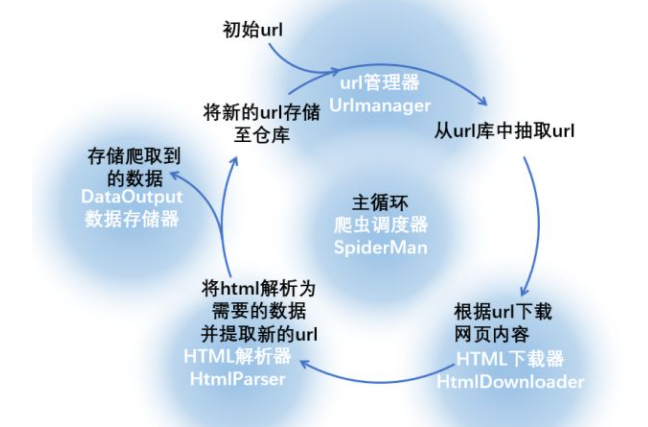
- UrlManager:将存储和获取url以及url去重的几个步骤在url管理器中完成(当然也可以针对每一步分别编写相应的函数,但是这样更直观)。url管理器要有两个url仓库,一个存储未爬取的url,一个存储已爬取的url,除了仓库之外,还应该具有一些完成特定功能的函数,如存储url、url去重、从仓库中挑选并返回一个url等
- HtmlDownloader:将下载网页内容的功能在HTML下载器中完成,下载器的功能较为单一,不多解释。但从整个爬虫的角度上来说,下载器是爬虫的核心,在实际操作的过程中,下载器要和目标网站的各种反爬虫手段斗智斗勇(各种表单、隐藏字段和假链接、验证码、IP限制等等),这也是最耗费大脑的步骤
- HtmlParser:解析提取数据的功能在HTML解析器中完成,解析器内的函数应该分别具有返回数据和新url的功能
- DAtaOutput:存储数据的功能由数据存储器完成
- SpiderMan:主循环由爬虫调度器来完成,调度器为整个程序的入口,将其余四个元件有序执行
爬虫调度器将要完成整个循环,下面写出python下爬虫调度器的程序:
# coding: utf-8
new_urls = set()
data = {}
class SpiderMan(object):
def __init__(self):
#调度器内包含其它四个元件,在初始化调度器的时候也要建立四个元件对象的实例
self.manager = UrlManager()
self.downloader = HtmlDownloader()
self.parser = HtmlParser()
self.output = DataOutput()
def spider(self, origin_url):
#添加初始url
self.manager.add_new_url(origin_url)
#下面进入主循环,暂定爬取页面总数小于100
num = 0
while(self.manager.has_new_url() and self.manager.old_url_size()<100):
try:
num = num + 1
print "正在处理第{}个链接".format(num)
#从新url仓库中获取url
new_url = self.manager.get_new_url()
#调用html下载器下载页面
html = self.downloader.download(new_url)
#调用解析器解析页面,返回新的url和data
try:
new_urls, data = self.parser.parser(new_url, html)
except Exception, e:
print e
for url in new_urls:
self.manager.add_new_url(url)
#将已经爬取过的这个url添加至老url仓库中
self.manager.add_old_url(new_url)
#将返回的数据存储至文件
self.output.store_data(data)
print "store data succefully"
print "第{}个链接已经抓取完成".format(self.manager.old_url_size())
except Exception, e:
print e
#爬取循环结束的时候将存储的数据输出至文件
self.output.output_html()
从整个循环的流程我们可以看出,由爬虫调度器指挥四个元件完成数据的抓取、筛选、保存流程,并以此为基础还可以进行新的循环。看懂原理之后,我们就可以使用以上的代码进行实战啦。
到此这篇关于python爬虫调度器用法及实例代码的文章就介绍到这了,更多相关python爬虫调度器是什么内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
简单的Python调度器Schedule详解
最近在做项目的时候经常会用到定时任务,由于我的项目是使用Java来开发,用的是SpringBoot框架,因此要实现这个定时任务其实并不难. 后来我在想如果我要在Python中实现,我要怎么做呢? 一开始我首先想到的是Timer Timer 这个是一个扩展自threading模块来实现的定时任务.它其实是一个线程. # 首先定义一个需要定时执行的方法 >>> def hello(): print("hello!") # 导入threading,并创建Timer,设置1秒
-

python爬虫调度器用法及实例代码
我们一般使用爬虫看到的都是最后的数据结果,对于整个的获取过程没有过多了解过.对于初学python的小伙伴们来说,不光是代码的练习,还是原理的分析都是必不可少的. 小编把整个爬取的过程分为了几个部分,从一开始的下载,到数据的去重解析,再到整个爬虫循环的结束,以图片和代码的双重形式展现给大家,希望能够对爬虫调度器有一个深刻的理解. 我们可以编写几个元件,每个元件完成一项功能,下图中的蓝底白字就是对这一流程的抽象: UrlManager:将存储和获取url以及url去重的几个步骤在url管理器中完成(
-
Python上下文管理器用法及实例解析
这篇文章主要介绍了Python上下文管理器用法及实例解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 with上下文管理器 语法:with ... as ... 如:with open('test.txt', 'r') as fp,打开一个文件作为文件句柄对象赋值给fp with是一个语句块,上下文管理器中里面实现了两个方法:enter, exit,enter是进入代码块前自动调用的方法,exit是 退出with语句块时调用的,例如,文件对象
-
Python 爬虫多线程详解及实例代码
python是支持多线程的,主要是通过thread和threading这两个模块来实现的.thread模块是比较底层的模块,threading模块是对thread做了一些包装的,可以更加方便的使用. 虽然python的多线程受GIL限制,并不是真正的多线程,但是对于I/O密集型计算还是能明显提高效率,比如说爬虫. 下面用一个实例来验证多线程的效率.代码只涉及页面获取,并没有解析出来. # -*-coding:utf-8 -*- import urllib2, time import thread
-
python函数装饰器用法实例详解
本文实例讲述了python函数装饰器用法.分享给大家供大家参考.具体如下: 装饰器经常被用于有切面需求的场景,较为经典的有插入日志.性能测试.事务处理等.装饰器是解决这类问题的绝佳设计, 有了装饰器,我们就可以抽离出大量函数中与函数功能本身无关的雷同代码并继续重用.概括的讲,装饰器的作用就是为已经存在的对象添加额外的功能. #! coding=utf-8 import time def timeit(func): def wrapper(a): start = time.clock() func
-
Python多层装饰器用法实例分析
本文实例讲述了Python多层装饰器用法.分享给大家供大家参考,具体如下: 前言 Python 的装饰器能够在不破坏函数原本结构的基础上,对函数的功能进行补充.当我们需要对一个函数补充不同的功能,可能需要用到多层的装饰器.在我的使用过程中,遇到了两种装饰器层叠的情况,这里把这两种情况写下来,作为踩坑记录. 情况1 def A(funC): def decorated_C(funE): def decorated_E_by_CA(*args, **kwargs): out = funC(funE)
-
python类装饰器用法实例
本文实例讲述了python类装饰器用法.分享给大家供大家参考.具体如下: #!coding=utf-8 registry = {} def register(cls): registry[cls.__clsid__] = cls return cls @register class Foo(object): __clsid__ = '123-456' def bar(self): pass print registry 运行结果如下: {'123-456': <class '__main__.F
-
python爬虫 批量下载zabbix文档代码实例
这篇文章主要介绍了python爬虫 批量下载zabbix文档代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 # -*- coding: UTF-8 -*- import requests,re,time url = 'https://www.zabbix.com/documentation/3.4/zh/manual' base_url = 'https://www.zabbix.com/documentation/3.4/' seco
-
Python爬虫爬取百度搜索内容代码实例
这篇文章主要介绍了Python爬虫爬取百度搜索内容代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 搜索引擎用的很频繁,现在利用Python爬虫提取百度搜索内容,同时再进一步提取内容分析就可以简便搜索过程.详细案例如下: 代码如下 # coding=utf8 import urllib2 import string import urllib import re import random #设置多个user_agents,防止百度限制I
-
python muggle_ocr库用法及实例代码
说明 1.muggle_ocr是一款轻量级的ocr识别库,对于python来说是识别率较高的图片验证码模块. 2.主要用于识别各种类型的验证码,一般文字提取效果稍差. 安装命令 pip install muggle_ocr 实例 import muggle_ocr # 初始化sdk:model_type 包含了 ModelType.OCR/ModelType.Captcha 两种模式,分别对应常规图片与验证码 sdk = muggle_ocr.SDK(model_type=muggle_ocr.
-
用python做一个搜索引擎(Pylucene)的实例代码
1.什么是搜索引擎? 搜索引擎是"对网络信息资源进行搜集整理并提供信息查询服务的系统,包括信息搜集.信息整理和用户查询三部分".如图1是搜索引擎的一般结构,信息搜集模块从网络采集信息到网络信息库之中(一般使用爬虫):然后信息整理模块对采集的信息进行分词.去停用词.赋权重等操作后建立索引表(一般是倒排索引)构成索引库:最后用户查询模块就可以识别用户的检索需求并提供检索服务啦. 图1 搜索引擎的一般结构 2. 使用python实现一个简单搜索引擎 2.1 问题分析 从图1看,一个完整的搜索