Python通过m3u8文件下载合并ts视频的操作
前段时间,接到一个需求,要求下载某一个网站的视频,然后自己从网上查阅了相关的资料,在这里做一个总结。
1. m3u8文件
m3u8是苹果公司推出一种视频播放标准,是一种文件检索格式,将视频切割成一小段一小段的ts格式的视频文件,然后存在服务器中(现在为了减少I/o访问次数,一般存在服务器的内存中),通过m3u8解析出来路径,然后去请求,是现在比较流行的一种加载方式。目前,很多新闻视频网站都是采用这种模式去加载视频。
M3U8文件是指UTF-8编码格式的M3U文件。M3U文件是记录了一个索引纯文本文件,打开它时播放软件并不是播放它,而是根据它的索引找到对应的音视频文件的网络地址进行在线播放。原视频数据分割为很多个TS流,每个TS流的地址记录在m3u8文件列表中。
下面就是m3u8文件的格式。
#EXTM3U #EXT-X-VERSION:3 #EXT-X-MEDIA-SEQUENCE:0 #EXT-X-ALLOW-CACHE:YES #EXT-X-TARGETDURATION:15 #EXTINF:6.916667, out000.ts #EXTINF:10.416667, out001.ts #EXTINF:10.416667, out002.ts #EXTINF:1.375000, out003.ts #EXTINF:1.541667, out004.ts #EXTINF:7.666667, out005.ts #EXTINF:10.416667,
2. ts文件处理
只有m3u8文件,需要下载ts文件
ts文件能正常播放,但太多而小,需要合并 有ts文件
但因为被加密无法播放,需要解码
在这里我只记录下前两个步骤,因为,我目前研究的比较少,还没有遇到ts被加密的情况。
3. 分析举例
那么下面,我就正式举一个网站,第一财经网(直接点击)跟大家正式的讲解下。
这是该网站的视频。如下图:

点击第一个视频,这就是我们这次要爬取的视频。

然后鼠标右键点击,选择"检查" 或者按F12键,进入开发者模式,查看网页代码。
然后,点击Network ,再点击other,寻找请求地址中带有m3u8和ts标记的请求地址。
不懂,请看下图。有一点,很重要。网站通过切割后ts加载视频,并不是没有规律的,而是通过m3u8文件附带的。也就说,网站一定是先加载m3u8文件,然后根据m3u8文件,去请求ts文件。所以,如果你找不到m3u8文件的话,你可以先找第一个ts文件,然后往上面翻,一定能找到m3u8文件。
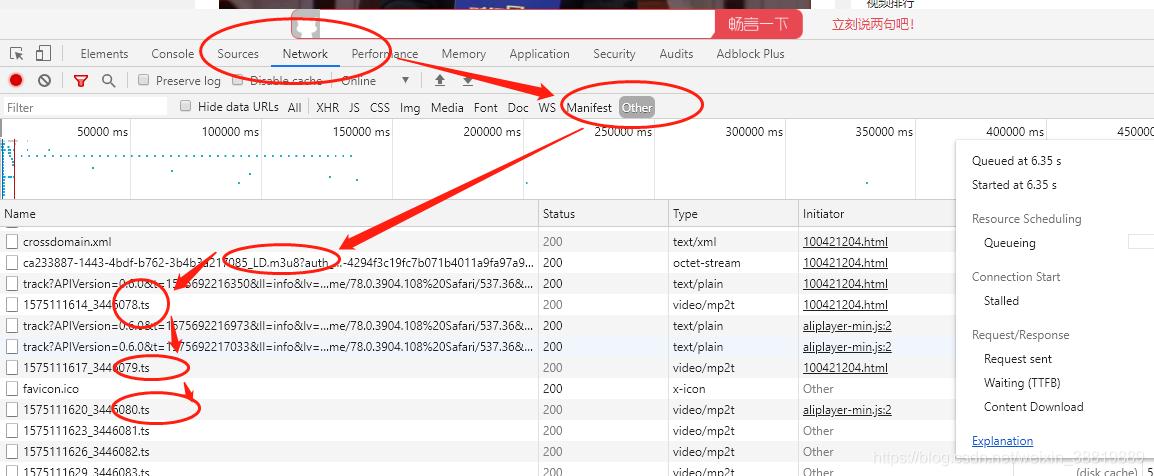
再点击这个m3u8文件,右侧对应的就是它的请求地址。

请求地址如下:
https://ycalvod.yicai.com/record/live/cbn/ca233887-1443-4bdf-b762-3b4b3a217085_LD.m3u8?auth_key=1575703722-0-0-6f09e9a156491f027a035e31c238c48c&ycfrom=yicaiwww
你可以把上面那个地址,输入浏览器地址框内,下载下来。也可以通过查看源码,找到该功能的对应的html代码。
这是下载下来的m3u8文件。

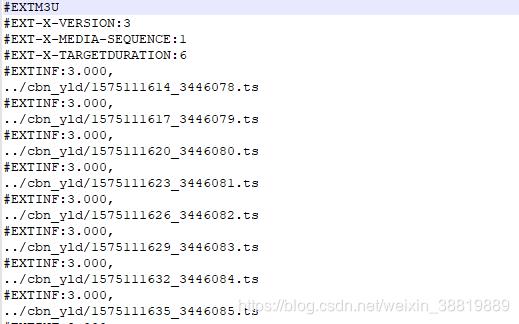
从图片可以看出来,每一个ts文件都是相对的地址,所以下面我们就需要找到绝对地址。

ts文件地址如下:
https://ycalvod.yicai.com/record/live/cbn_yld/1575111614_3446078.ts
上面,我们已经把这个网站的视频加载模式分析的很透彻,下面就开始撸代码了。
4. 获取ts文件
def getTsUrl():
ts_url_list = []
baseUrl = "https://ycalvod.yicai.com/record/live"
with open("ca233887-1443-4bdf-b762-3b4b3a217085_LD.m3u8", "r", encoding="utf-8") as f:
m3u8Contents = f.readlines()
for content in m3u8Contents:
if content.endswith("ts\n"):
ts_Url = baseUrl + content.replace("\n", "").replace("..", "")
ts_url_list.append(ts_Url)
print(ts_Url)
return ts_url_list
5. 下载ts文件
def download_ts_video(download_path, ts_url_list):
download_path = r"C:\Users\Administrator\Desktop\AiShu\下载视频\TS视频"
for i in range(len(ts_url_list)):
ts_url = ts_url_list[i]
try:
response = requests.get(ts_url, stream=True, verify=False)
except Exception as e:
print("异常请求:%s" % e.args)
return
ts_path = download_path + "\{}.ts".format(i)
with open(ts_path, "wb+") as file:
for chunk in response.iter_content(chunk_size=1024):
if chunk:
file.write(chunk)
print("TS文件下载完毕!!")
这就是我本地下载好的ts切割视频

6. 合并TS视频
def heBingTsVideo(download_path,hebing_path):
all_ts = os.listdir(download_path)
with open(hebing_path, 'wb+') as f:
for i in range(len(all_ts)):
ts_video_path = os.path.join(download_path, all_ts[i])
f.write(open(ts_video_path, 'rb').read())
print("合并完成!!")
最后的结果如下:

7. 完整的代码
有兴趣的小伙伴,可以研究下。
import requests,os
def getTsUrl():
ts_url_list = []
baseUrl = "https://ycalvod.yicai.com/record/live"
with open("ca233887-1443-4bdf-b762-3b4b3a217085_LD.m3u8", "r", encoding="utf-8") as f:
m3u8Contents = f.readlines()
for content in m3u8Contents:
if content.endswith("ts\n"):
ts_Url = baseUrl + content.replace("\n", "").replace("..", "")
ts_url_list.append(ts_Url)
print(ts_Url)
return ts_url_list
def download_ts_video(download_path, ts_url_list):
download_path = r"C:\Users\Administrator\Desktop\AiShu\下载视频\TS视频"
for i in range(len(ts_url_list)):
ts_url = ts_url_list[i]
try:
response = requests.get(ts_url, stream=True, verify=False)
except Exception as e:
print("异常请求:%s" % e.args)
return
ts_path = download_path + "\{}.ts".format(i)
with open(ts_path, "wb+") as file:
for chunk in response.iter_content(chunk_size=1024):
if chunk:
file.write(chunk)
print("TS文件下载完毕!!")
def heBingTsVideo(download_path,hebing_path):
all_ts = os.listdir(download_path)
with open(hebing_path, 'wb+') as f:
for i in range(len(all_ts)):
ts_video_path = os.path.join(download_path, all_ts[i])
f.write(open(ts_video_path, 'rb').read())
print("合并完成!!")
if __name__ == '__main__':
download_path = r"C:\Users\Administrator\Desktop\AiShu\下载视频\TS视频"
hebing_path = r"C:\Users\Administrator\Desktop\AiShu\下载视频\合并TS视频\第一财经.mp4"
ts_url_list = getTsUrl()
download_ts_video(download_path, ts_url_list)
heBingTsVideo(download_path,hebing_path)
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-
python将下载到本地m3u8视频合成MP4的代码详解
代码如下所示: import os import requests import datetime from Crypto.Cipher import AES def decode_key_file(key_file_name): with open(key_file_name,"r") as f: data=f.read() return data def decode_m_file(m_file_name): with open(m_file_name,"r")
-

python基于tkinter制作m3u8视频下载工具
这是我为了学习tkinter用python 写的一个下载m3u8视频的小程序,程序使用了多线程下载,下载后自动合并成一个视频文件,方便播放. 目前的众多视频都是m3u8的播放类型,只要知道视频的m3u8地址,就可以完美下载整个视频. m3u8地址获取 打开浏览器,点开你要获取地址的视频 重要的来了,右键>>审查元素或者按F12也可以 根据开发或测试的实际环境选择相应的设备,选择iphone6 plus 选择好了以后,刷新页面,点击漏斗,选择media,一定刷新之后再点击,没出来的话切换几下选项
-
Python解析m3u8拼接下载mp4视频文件的示例代码
一.关于m3u8: m3u8是苹果公司推出一种视频播放标准,是m3u的一种,不过编码方式是utf-8,是一种文件检索格式,将视频切割成一小段一小段的ts格式的视频文件,然后存在服务器中(现在为了减少I/o访问次数,一般存在服务器的内存中),通过m3u8解析出来路径,然后去请求. 示例: #EXTM3U #EXT-X-TARGETDURATION:10 #EXTINF:9, http://data.video.iqiyi.com/videos/vts/20210301/69/b8/73ad4ef0
-
python 实现多线程下载m3u8格式视频并使用fmmpeg合并
电影之类的长视频好像都用m3u8格式了,这就导致了多线程下载视频的意义不是很大,都是短视频,线不线程就没什么意义了嘛. 我们知道,m3u8的链接会下载一个文档,相当长,半小时的视频,应该有接近千行ts链接. 这些ts链接下载成ts文件,就是碎片化的视频,加以合并,就成了需要的视频. 那,即便网速很快,下几千行视频,效率也就低了,更何况还要合并.我就琢磨了一下午,怎么样才能多线程下载m3u8格式的视频呢? 先上代码,再说重难点: import datetime import os import r
-
python爬取m3u8连接的视频
本文为大家分享了python爬取m3u8连接的视频方法,供大家参考,具体内容如下 要求:输入m3u8所在url,且ts视频与其在同一路径下 #!/usr/bin/env/python #_*_coding:utf-8_*_ #Data:17-10-08 #Auther:苏莫 #Link:http://blog.csdn.net/lingluofengzang #PythonVersion:python2.7 #filename:download_movie.py import os import
-
python3.6根据m3u8下载mp4视频
需要下载某网站的视频,chrome浏览器按F12打开开发者模式,发现视频链接是以"blob:http"开头的链接,打开这个链接后找不到网页,网上查了下,找到了下载方法,在这里做个记录,如果有错误,欢迎指出. 程序在Windows 10下运行,不过Linux应该也没问题. 使用到的有re模块,requests模块和Crypto模块,其中requests模块和Crypto模块如果没安装可以使用pip命令安装.(Crypto模块安装感觉比较坑,我是从anaconda里拷贝了一份) 下面开始正
-
python实现m3u8格式转换为mp4视频格式
开发动机:最近用手机QQ浏览器下载了一些视频,视频越来越多,占用了手机内存,于是想把下载的视频传到电脑上保存,可后来发现这些视频都是m3u8格式的,且这个格式的视频都切成了碎片,存在电脑里不方便查看,于是想把它转换为其他可以直接打开播放的完整视频,到网上找了一些工具,都不怎么好用,后来发现一个手机端的"缓冲合并工具",倒是可以用,但是合并的视频顺序是乱的,碎片的视频顺序还需要用户手动调整,感觉太耽误时间了,于是自己打算写一个转换工具. 直接上代码:(程序的文件名为:convert_m3
-
python爬取基于m3u8协议的ts文件并合并
前言 简单学习过网络爬虫,只是之前都是照着书上做并发,大概能理解,却还是无法自己用到自己项目中,这里自己研究实现一个网页嗅探HTML5播放控件中基于m3u8协议ts格式视频资源的项目,并未考虑过复杂情况,毕竟只是练练手. 源码 # coding=utf-8 import asyncio import multiprocessing import os import re import time from math import floor from multiprocessing import
-
python 下载m3u8视频的示例代码
import requests import os import datetime import threading class xiazai(): def __init__(self,url): self.url = url work_dir = os.getcwd() # print(work_dir) # 用来保存ts文件 file_dir = os.path.join(work_dir, 'file_tmp') if not os.path.exists(file_dir): os.mk
-
Python通过m3u8文件下载合并ts视频的操作
前段时间,接到一个需求,要求下载某一个网站的视频,然后自己从网上查阅了相关的资料,在这里做一个总结. 1. m3u8文件 m3u8是苹果公司推出一种视频播放标准,是一种文件检索格式,将视频切割成一小段一小段的ts格式的视频文件,然后存在服务器中(现在为了减少I/o访问次数,一般存在服务器的内存中),通过m3u8解析出来路径,然后去请求,是现在比较流行的一种加载方式.目前,很多新闻视频网站都是采用这种模式去加载视频. M3U8文件是指UTF-8编码格式的M3U文件.M3U文件是记录了一个索引纯文本
-
Python合并ts文件至mp4格式及解密教程详解
m3u8是什么格式?m3u8是苹果公司推出的视频播放标准,是m3u的一种,只是编码格式采用的是UTF-8. 使用m3u8格式文件主要因为可以实现多码率视频的适配,视频网站可以根据用户的网络带宽情况,自动为客户端匹配一个合适的码率文件进行播放,从而保证视频的流畅度. m3u8准确来说是一种索引文件,使用m3u8文件实际上是通过它来解析对应的放在服务器上的视频网络地址,从而实现在线播放. 它将视频切割成一小段一小段的ts格式的视频文件,然后存在服务器中(现在为了减少I/o访问次数,一般存在服务器的内
-
Python实现抓取腾讯视频所有电影的示例代码
目录 运行环境 实现目的与思路 目的 思路 完整代码 视频缓存ts文件 实现效果 运行环境 IDE丨pycharm 版本丨Python3.6 系统丨Windows 实现目的与思路 目的 实现对腾讯视频目标url的解析与下载,由于第三方vip解析,只提供在线观看,隐藏想实现对目标视频的下载 思路 首先拿到想要看的腾讯电影url,通过第三方vip视频解析网站进行解析,通过抓包,模拟浏览器发送正常请求,通过拿到缓存ts文件,下载视频ts文件,最后通过转换为mp4文件,即可实现正常播放 完整代码 imp
-
java将m3u8格式转成视频文件的方法
这是一次尝试,android手机将在线的m3u8小电影保存到手机端,手机端把文件复制到电脑端. 然后使用小工具合并成可播放的视频. /** * 合并视频文件 * */ public class MergeVideos { /** * source为源地址,destination为合并之后的文件地址,videoName为合并后视频的名字,num为视频数量 * @param source * @param destination * @throws IOException */ public sta
-
python 爬取B站原视频的实例代码
B站原视频爬取,我就不多说直接上代码.直接运行就好. B站是把视频和音频分开.要把2个合并起来使用.这个需要分析才能看出来.然后就是登陆这块是比较难的. import os import re import argparse import subprocess import prettytable from DecryptLogin import login '''B站类''' class Bilibili(): def __init__(self, username, password, **
-
python字典DICT类型合并详解
本文为大家分享了python字典DICT类型合并的方法,供大家参考,具体内容如下 我要的字典的键值有些是数据库中表的字段名, 但是有些却不是, 我需要把它们整合到一起, 因此有些这篇文章.(非得凑够150个字,我也是没有办法,扯一点昨天的问题吧,话说python中的session就只能在requests库中发挥作用?就不能想asp.net中那样存值,然后设置过期时间以便验证?我原本是想在python中找个与asp.net中的cache差不多功能的库,结果,缓存那块python好像就是redis和
-
Python numpy实现数组合并实例(vstack,hstack)
若干个数组可以沿不同的轴合合并到一起,vstack,hstack的简单用法, >>> a = np.floor(10*np.random.random((2,2))) >>> a array([[ 8., 8.], [ 0., 0.]]) >>> b = np.floor(10*np.random.random((2,2))) >>> b array([[ 1., 8.], [ 0., 4.]]) >>> np.vs