浅谈tensorflow与pytorch的相互转换
目录
- 1.变量预定义
- 2.创建变量并初始化
- 3.语句执行
- 4.tensor
- 5.其他函数
本文以一段代码为例,简单介绍一下tensorflow与pytorch的相互转换(主要是tensorflow转pytorch),可能介绍的没有那么详细,仅供参考。
由于本人只熟悉pytorch,而对tensorflow一知半解,而代码经常遇到tensorflow,而我希望使用pytorch,因此简单介绍一下tensorflow转pytorch,可能存在诸多错误,希望轻喷~
1.变量预定义
在TensorFlow的世界里,变量的定义和初始化是分开的。
tensorflow中一般都是在开头预定义变量,声明其数据类型、形状等,在执行的时候再赋具体的值,如下图所示,而pytorch用到时才会定义,定义和变量初始化是合在一起的。
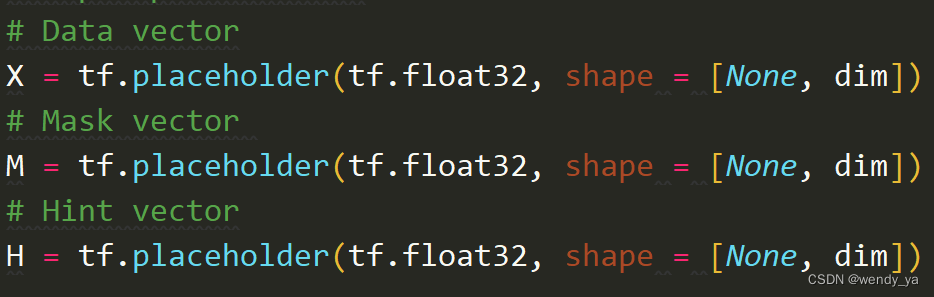
2.创建变量并初始化
tensorflow中利用tf.Variable创建变量并进行初始化,而pytorch中使用torch.tensor创建变量并进行初始化,如下图所示。
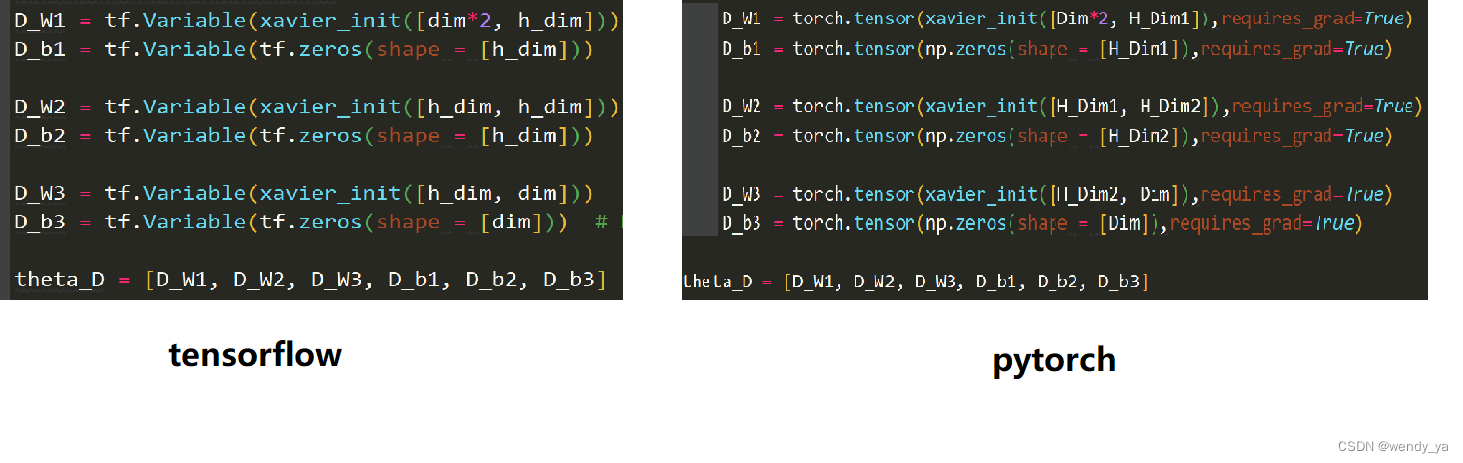
3.语句执行
在TensorFlow的世界里,变量的定义和初始化是分开的,所有关于图变量的赋值和计算都要通过tf.Session的run来进行。
sess.run([G_solver, G_loss_temp, MSE_loss],
feed_dict = {X: X_mb, M: M_mb, H: H_mb})
而在pytorch中,并不需要通过run进行,赋值完了直接计算即可。
4.tensor
pytorch运算时要创建完的numpy数组转为tensor,如下:
if use_gpu is True: X_mb = torch.tensor(X_mb, device="cuda") M_mb = torch.tensor(M_mb, device="cuda") H_mb = torch.tensor(H_mb, device="cuda") else: X_mb = torch.tensor(X_mb) M_mb = torch.tensor(M_mb) H_mb = torch.tensor(H_mb)
最后运行完还要将tensor数据类型转换回numpy数组:
if use_gpu is True: imputed_data=imputed_data.cpu().detach().numpy() else: imputed_data=imputed_data.detach().numpy()
而tensorflow中不需要这种操作。
5.其他函数
在tensorflow中包含诸多函数是pytorch中没有的,但是都可以在其他库中找到类似,具体如下表所示。
| tensorflow中函数 | pytorch中代替(所在库) | 参数区别 |
|---|---|---|
| tf.sqrt | np.sqrt(numpy) | 完全相同 |
| tf.random_normal | np.random.normal(numpy) | tf.random_normal(shape = size, stddev = xavier_stddev) np.random.normal(size = size, scale = xavier_stddev) |
| tf.concat | torch.cat(torch) | inputs = tf.concat(values = [x, m], axis = 1) inputs = torch.cat(dim=1, tensors=[x, m]) |
| tf.nn.relu | F.relu(torch.nn.functional) | 完全相同 |
| tf.nn.sigmoid | torch.sigmoid(torch) | 完全相同 |
| tf.matmul | torch.matmul(torch) | 完全相同 |
| tf.reduce_mean | torch.mean(torch) | 完全相同 |
| tf.log | torch.log(torch) | 完全相同 |
| tf.zeros | np.zeros | 完全相同 |
| tf.train.AdamOptimizer | torch.optim.Adam(torch) | optimizer_D = tf.train.AdamOptimizer().minimize(D_loss, var_list=theta_D) optimizer_D = torch.optim.Adam(params=theta_D) |
到此这篇关于浅谈tensorflow与pytorch的相互转换的文章就介绍到这了,更多相关tensorflow与pytorch的相互转换内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
关于windows下Tensorflow和pytorch安装教程
一.Tensorflow安装 1.Tensorflow介绍 Tensorflow是广泛使用的实现机器学习以及其它涉及大量数学运算的算法库之一.Tensorflow由Google开发,是GitHub上最受欢迎的机器学习库之一.Google几乎在所有应用程序中都使用Tensorflow来实现机器学习. 例如,如果您使用到了Google照片或Google语音搜索,那么您就间接使用了Tensorflow模型.它们在大型Google硬件集群上工作,在感知任务方面功能强大. 2.Tensorflow安装(c
-
Pytorch框架实现mnist手写库识别(与tensorflow对比)
前言最近在学习过程中需要用到pytorch框架,简单学习了一下,写了一个简单的案例,记录一下pytorch中搭建一个识别网络基础的东西.对应一位博主写的tensorflow的识别mnist数据集,将其改为pytorch框架,也可以详细看到两个框架大体的区别. Tensorflow版本转载来源(CSDN博主「兔八哥1024」):https://www.jb51.net/article/191157.htm Pytorch实战mnist手写数字识别 #需要导入的包 import torch impo
-

Pytorch自动求导函数详解流程以及与TensorFlow搭建网络的对比
一.定义新的自动求导函数 在底层,每个原始的自动求导运算实际上是两个在Tensor上运行的函数.其中,forward函数计算从输入Tensor获得的输出Tensors.而backward函数接收输出,Tensors对于某个标量值得梯度,并且计算输入Tensors相对于该相同标量值得梯度. 在Pytorch中,可以容易地通过定义torch.autograd.Function的子类实现forward和backward函数,来定义自动求导函数.之后就可以使用这个新的自动梯度运算符了.我们可以通过构造一
-
Win10下安装CUDA11.0+CUDNN8.0+tensorflow-gpu2.4.1+pytorch1.7.0+paddlepaddle-gpu2.0.0
下载地址 官方下载:CUDA和CUDNN. 安装CUDA 安装之前,建议关掉360安全卫士 双击cuda_11.0.3_451.82_win10.exe文件 根据自己需要更改安装路径 将Visual Studio Integration的勾去掉 配置环境变量 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.0\bin; C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.0\l
-
pytorch_pretrained_bert如何将tensorflow模型转化为pytorch模型
pytorch_pretrained_bert将tensorflow模型转化为pytorch模型 BERT仓库里的模型是TensorFlow版本的,需要进行相应的转换才能在pytorch中使用 在Google BERT仓库里下载需要的模型,这里使用的是中文预训练模型(chinese_L-12_H-768_A_12) 下载chinese_L-12_H-768_A-12.zip后解压,里面有5个文件 chinese_L-12_H-768_A-12.zip后解压,里面有5个文件 bert_config
-
浅谈tensorflow与pytorch的相互转换
目录 1.变量预定义 2.创建变量并初始化 3.语句执行 4.tensor 5.其他函数 本文以一段代码为例,简单介绍一下tensorflow与pytorch的相互转换(主要是tensorflow转pytorch),可能介绍的没有那么详细,仅供参考. 由于本人只熟悉pytorch,而对tensorflow一知半解,而代码经常遇到tensorflow,而我希望使用pytorch,因此简单介绍一下tensorflow转pytorch,可能存在诸多错误,希望轻喷~ 1.变量预定义 在TensorFlo
-
浅谈tensorflow中几个随机函数的用法
如下所示: tf.constant(value, dtype=None, shape=None) 创建一个常量tensor,按照给出value来赋值,可以用shape来指定其形状.value可以是一个数,也可以是一个list. 如果是一个数,那么这个常亮中所有值的按该数来赋值. tf.random_normal(shape,mean=0.0,stddev=1.0,dtype=tf.float32) tf.truncated_normal(shape, mean=0.0, stddev=1.0,
-
浅谈Tensorflow由于版本问题出现的几种错误及解决方法
1.AttributeError: 'module' object has no attribute 'rnn_cell' S:将tf.nn.rnn_cell替换为tf.contrib.rnn 2.TypeError: Expected int32, got list containing Tensors of type '_Message' instead. S:由于tf.concat的问题,将tf.concat(1, [conv1, conv2]) 的格式替换为tf.concat( [con
-
浅谈tensorflow中张量的提取值和赋值
tf.gather和gather_nd从params中收集数值,tf.scatter_nd 和 tf.scatter_nd_update用updates更新某一张量.严格上说,tf.gather_nd和tf.scatter_nd_update互为逆操作. 已知数值的位置,从张量中提取数值:tf.gather, tf.gather_nd tf.gather indices每个元素(标量)是params某个axis的索引,tf.gather_nd 中indices最后一个阶对应于索引值. tf.ga
-
浅谈tensorflow中Dataset图片的批量读取及维度的操作详解
三维的读取图片(w, h, c): import tensorflow as tf import glob import os def _parse_function(filename): # print(filename) image_string = tf.read_file(filename) image_decoded = tf.image.decode_image(image_string) # (375, 500, 3) image_resized = tf.image.resize
-
浅谈Tensorflow 动态双向RNN的输出问题
tf.nn.bidirectional_dynamic_rnn() 函数: def bidirectional_dynamic_rnn( cell_fw, # 前向RNN cell_bw, # 后向RNN inputs, # 输入 sequence_length=None,# 输入序列的实际长度(可选,默认为输入序列的最大长度) initial_state_fw=None, # 前向的初始化状态(可选) initial_state_bw=None, # 后向的初始化状态(可选) dtype=No
-
浅谈tensorflow之内存暴涨问题
在用tensorflow实现一些模型的时候,有时候我们在运行程序的时候,会发现程序占用的内存在不断增长.最后内存溢出,程序被kill掉了. 这个问题,其实有两个可能性.一个是比较常见,同时也是很难发现的.这个问题的解决,需要我们知道tensorflow在构图的时候,是没有所谓的临时变量的,只要有operator.那么tensorflow就会在构建的图中增加这个operator所代表的节点.所以,在运行程序的过程中,内存不断增长的原因就是在模型训练迭代的过程中,tensorflow一直在帮你增加图
-
浅谈tensorflow 中tf.concat()的使用
concat()是将tensor沿着指定维度连接起来.其中tensorflow1.3版中是这样定义的: concat(values,axis,name='concat') 一.对于2维来说,0表示行,1表示列 t1 = [[1, 2, 3], [4, 5, 6]] t2 = [[7, 8, 9], [10, 11, 12]] with tf.Session() as sess: print(sess.run(tf.concat([t1, t2], 0) )) 结果为:[[1, 2, 3], [4
-
浅谈Tensorflow加载Vgg预训练模型的几个注意事项
写这个博客的关键Bug: Value passed to parameter 'input' has DataType uint8 not in list of allowed values: float16, bfloat16, float32, float64.本博客将围绕 加载图片 和 保存图片到本地 来详细解释和解决上述的Bug及其引出来的一系列Bug. 加载图片 首先,造成上述Bug的代码如下所示 image_path = "data/test.jpg" # 本地的测试图片
-
浅谈tensorflow模型保存为pb的各种姿势
一,直接保存pb 1, 首先我们当然可以直接在tensorflow训练中直接保存为pb为格式,保存pb的好处就是使用场景是实现创建模型与使用模型的解耦,使得创建模型与使用模型的解耦,使得前向推导inference代码统一.另外的好处就是保存为pb的时候,模型的变量会变成固定的,导致模型的大小会大大减小. 这里稍稍解释下pb:是MetaGraph的protocol buffer格式的文件,MetaGraph包括计算图,数据流,以及相关的变量和输入输出 主要使用tf.SavedModelBuilde