关于spring循环依赖问题及解决方案
目录
- 一、三种循环依赖的情况
- 比如几个Bean之间的互相引用
- 甚至自己“循环”依赖自己
- 二、解决方案
- 如何获取依赖
- 三、解决循环依赖必须要三级缓存吗
- 结论
- 四、无法解决的循环依赖问题
- 1.在主bean中通过构造函数注入所依赖的bean
- 2.总结
一、三种循环依赖的情况
①构造器的循环依赖:
- 这种依赖spring是处理不了的,直接抛出BeanCurrentlylnCreationException异常。
②单例模式下的setter循环依赖:
- 通过“三级缓存”处理循环依赖,能处理。
③非单例循环依赖:
- 无法处理。原型(Prototype)的场景是不支持循环依赖的,通常会走到AbstractBeanFactory类中下面的判断,抛出异常。
if (isPrototypeCurrentlyInCreation(beanName))
{ throw new BeanCurrentlyInCreationException(beanName);}
原因很好理解,创建新的A时,发现要注入原型字段B,又创建新的B发现要注入原型字段A…这就套娃了, 你猜是先StackOverflow还是OutOfMemory?
Spring怕你不好猜,就先抛出了BeanCurrentlyInCreationException
出现的背景:
比如几个Bean之间的互相引用
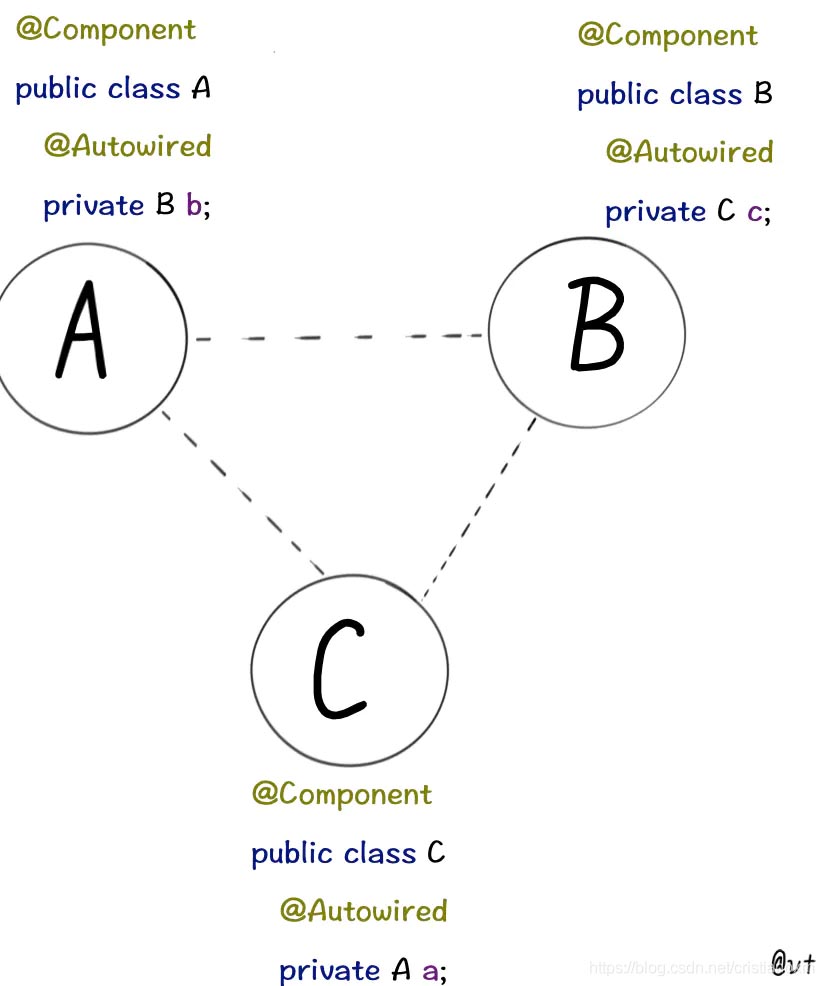
甚至自己“循环”依赖自己

二、解决方案
首先,Spring内部维护了三个Map,也就是我们通常说的三级缓存。
笔者翻阅Spring文档倒是没有找到三级缓存的概念,可能也是本土为了方便理解的词汇。
在Spring的DefaultSingletonBeanRegistry类中,你会赫然发现类上方挂着这三个Map:
singletonObjects(一级缓存)它是我们最熟悉的朋友,俗称“单例池”“容器”,缓存创建完成单例Bean的地方。earlySingletonObjects(二级缓存)映射Bean的早期引用,也就是说在这个Map里的Bean不是完整的,甚至还不能称之为“Bean”,只是一个Instance.singletonFactories(三级缓存) 映射创建Bean的原始工厂
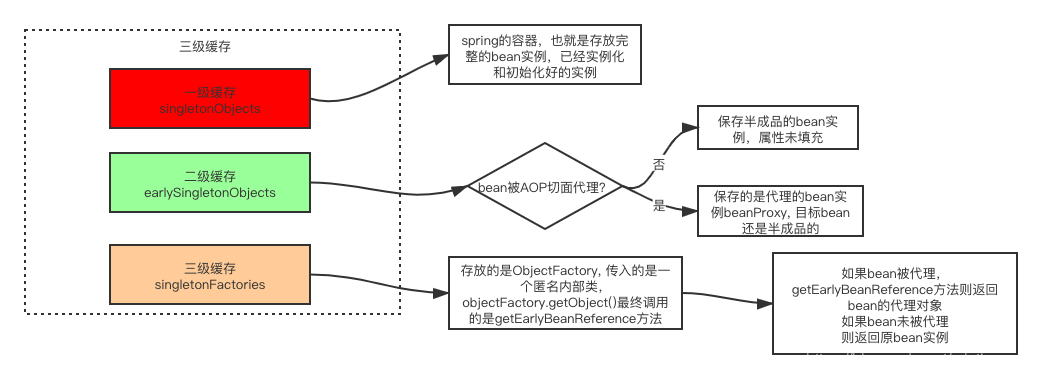
后两个Map其实是“垫脚石”级别的,只是创建Bean的时候,用来借助了一下,创建完成就清掉了。
那么Spring 是如何通过上面介绍的三级缓存来解决循环依赖的呢?
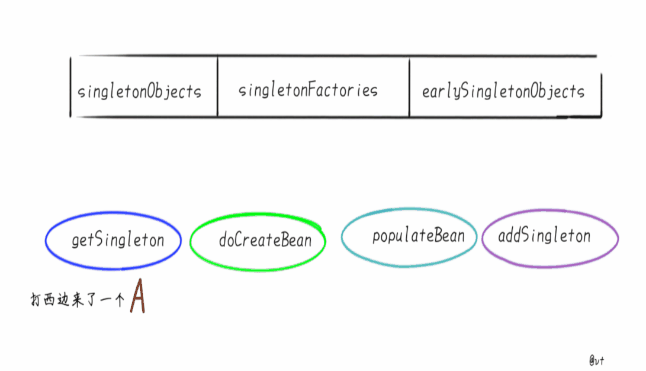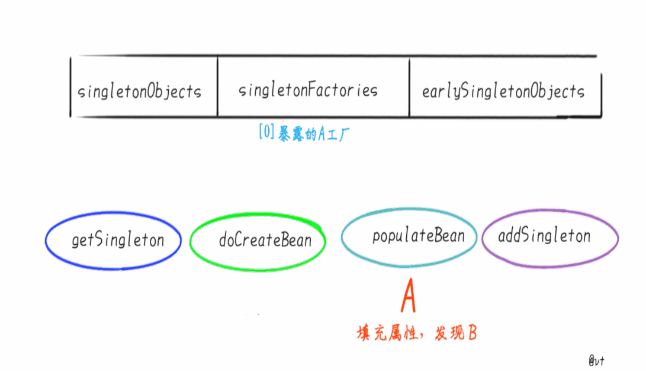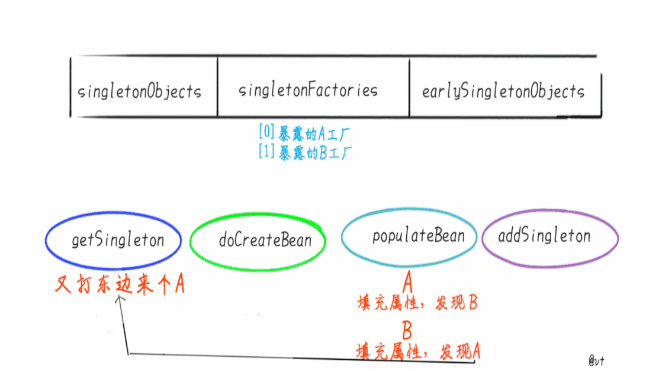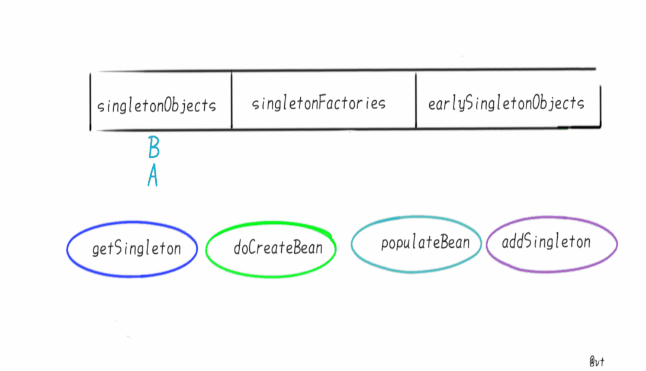
这里只用 A,B 形成的循环依赖来举例:
- 实例化 A,此时 A 还未完成属性填充和初始化方法(@PostConstruct)的执行,A 只是一个半成品。
- 为 A 创建一个 Bean工厂,并放入到 singletonFactories 中。
- 发现 A 需要注入 B 对象,但是一级、二级、三级缓存均为发现对象 B。
- 实例化 B,此时 B 还未完成属性填充和初始化方法(@PostConstruct)的执行,B 只是一个半成品。
- 为 B 创建一个 Bean工厂,并放入到 singletonFactories 中。
- 发现 B 需要注入 A 对象,此时在一级、二级未发现对象A,但是在三级缓存中发现了对象 A,从三级缓存中得到对象 A,并将对象 A 放入二级缓存中,同时删除三级缓存中的对象 A。(注意,此时的 A还是一个半成品,并没有完成属性填充和执行初始化方法)
- 将对象 A 注入到对象 B 中。
- 对象 B 完成属性填充,执行初始化方法,并放入到一级缓存中,同时删除二级缓存中的对象 B。(此时对象 B 已经是一个成品)
- 对象 A 得到对象B,将对象 B 注入到对象 A 中。(对象 A 得到的是一个完整的对象 B)
- 对象 A完成属性填充,执行初始化方法,并放入到一级缓存中,同时删除二级缓存中的对象 A。
我们从源码的角度来看一下这个过程:
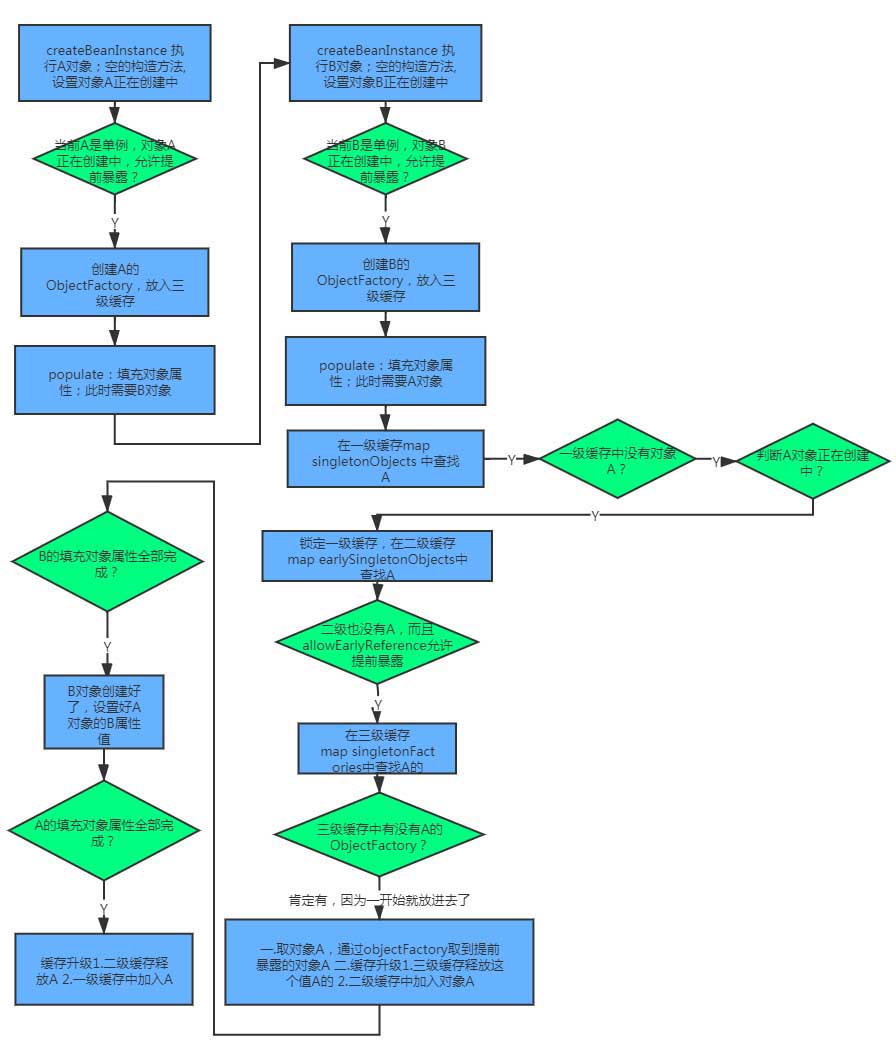
创建 Bean 的方法在 AbstractAutowireCapableBeanFactory::doCreateBean()
protected Object doCreateBean(final String beanName, final RootBeanDefinition mbd, Object[] args) throws BeanCreationException {
BeanWrapper instanceWrapper = null;
if (instanceWrapper == null) {
// ① 实例化对象
instanceWrapper = this.createBeanInstance(beanName, mbd, args);
}
final Object bean = instanceWrapper != null ? instanceWrapper.getWrappedInstance() : null;
Class<?> beanType = instanceWrapper != null ? instanceWrapper.getWrappedClass() : null;
// ② 判断是否允许提前暴露对象,如果允许,则直接添加一个 ObjectFactory 到三级缓存
boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences &&
isSingletonCurrentlyInCreation(beanName));
if (earlySingletonExposure) {
// 添加三级缓存的方法详情在下方
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
}
// ③ 填充属性
this.populateBean(beanName, mbd, instanceWrapper);
// ④ 执行初始化方法,并创建代理
exposedObject = initializeBean(beanName, exposedObject, mbd);
return exposedObject;
}
添加三级缓存的方法如下:
protected void addSingletonFactory(String beanName, ObjectFactory<?> singletonFactory) {
Assert.notNull(singletonFactory, "Singleton factory must not be null");
synchronized (this.singletonObjects) {
if (!this.singletonObjects.containsKey(beanName)) { // 判断一级缓存中不存在此对象
this.singletonFactories.put(beanName, singletonFactory); // 添加至三级缓存
this.earlySingletonObjects.remove(beanName); // 确保二级缓存没有此对象
this.registeredSingletons.add(beanName);
}
}
}
@FunctionalInterface
public interface ObjectFactory<T> {
T getObject() throws BeansException;
}
通过这段代码,我们可以知道 Spring 在实例化对象的之后,就会为其创建一个 Bean 工厂,并将此工厂加入到三级缓存中。
因此,Spring 一开始提前暴露的并不是实例化的 Bean,而是将 Bean 包装起来的 ObjectFactory。为什么要这么做呢?
这实际上涉及到 AOP,如果创建的 Bean 是有代理的,那么注入的就应该是代理 Bean,而不是原始的 Bean。但是 Spring 一开始并不知道 Bean 是否会有循环依赖,通常情况下(没有循环依赖的情况下),Spring 都会在完成填充属性,并且执行完初始化方法之后再为其创建代理。但是,如果出现了循环依赖的话,Spring 就不得不为其提前创建代理对象,否则注入的就是一个原始对象,而不是代理对象。因此,这里就涉及到应该在哪里提前创建代理对象?
Spring 的做法就是在 ObjectFactory 中去提前创建代理对象。它会执行 getObject() 方法来获取到 Bean。实际上,它真正执行的方法如下:
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
Object exposedObject = bean;
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof SmartInstantiationAwareBeanPostProcessor) {
SmartInstantiationAwareBeanPostProcessor ibp = (SmartInstantiationAwareBeanPostProcessor) bp;
// 如果需要代理,这里会返回代理对象;否则返回原始对象
exposedObject = ibp.getEarlyBeanReference(exposedObject, beanName);
}
}
}
return exposedObject;
}
因为提前进行了代理,避免对后面重复创建代理对象,会在 earlyProxyReferences 中记录已被代理的对象。
public abstract class AbstractAutoProxyCreator extends ProxyProcessorSupport
implements SmartInstantiationAwareBeanPostProcessor, BeanFactoryAware {
@Override
public Object getEarlyBeanReference(Object bean, String beanName) {
Object cacheKey = getCacheKey(bean.getClass(), beanName);
// 记录已被代理的对象
this.earlyProxyReferences.put(cacheKey, bean);
return wrapIfNecessary(bean, beanName, cacheKey);
}
}
通过上面的解析,我们可以知道 Spring 需要三级缓存的目的是为了在没有循环依赖的情况下,延迟代理对象的创建,使 Bean 的创建符合 Spring 的设计原则。
如何获取依赖
我们目前已经知道了 Spring 的三级依赖的作用,但是 Spring 在注入属性的时候是如何去获取依赖的呢?
他是通过一个getSingleton()方法去获取所需要的 Bean 的。
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
// 一级缓存
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
synchronized (this.singletonObjects) {
// 二级缓存
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null && allowEarlyReference) {
// 三级缓存
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
// Bean 工厂中获取 Bean
singletonObject = singletonFactory.getObject();
// 放入到二级缓存中
this.earlySingletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
}
}
}
}
return singletonObject;
}
当 Spring 为某个 Bean 填充属性的时候,它首先会寻找需要注入对象的名称,然后依次执行 getSingleton() 方法得到所需注入的对象,而获取对象的过程就是先从一级缓存中获取,一级缓存中没有就从二级缓存中获取,二级缓存中没有就从三级缓存中获取,如果三级缓存中也没有,那么就会去执行 doCreateBean() 方法创建这个 Bean。
流程图总结:
三、解决循环依赖必须要三级缓存吗
我们现在已经知道,第三级缓存的目的是为了延迟代理对象的创建,因为如果没有依赖循环的话,那么就不需要为其提前创建代理,可以将它延迟到初始化完成之后再创建。
既然目的只是延迟的话,那么我们是不是可以不延迟创建,而是在实例化完成之后,就为其创建代理对象,这样我们就不需要第三级缓存了。因此,我们可以将addSingletonFactory() 方法进行改造。
protected void addSingletonFactory(String beanName, ObjectFactory<?> singletonFactory) {
Assert.notNull(singletonFactory, "Singleton factory must not be null");
synchronized (this.singletonObjects) {
if (!this.singletonObjects.containsKey(beanName)) { // 判断一级缓存中不存在此对象
object o = singletonFactory.getObject(); // 直接从工厂中获取 Bean
this.earlySingletonObjects.put(beanName, o); // 添加至二级缓存中
this.registeredSingletons.add(beanName);
}
}
}
这样的话,每次实例化完 Bean 之后就直接去创建代理对象,并添加到二级缓存中。测试结果是完全正常的,Spring 的初始化时间应该也是不会有太大的影响,因为如果 Bean 本身不需要代理的话,是直接返回原始 Bean 的,并不需要走复杂的创建代理 Bean 的流程。
结论
测试证明,二级缓存也是可以解决循环依赖的。为什么 Spring 不选择二级缓存,而要额外多添加一层缓存呢?
如果 Spring 选择二级缓存来解决循环依赖的话,那么就意味着所有 Bean 都需要在实例化完成之后就立马为其创建代理,而Spring 的设计原则是在 Bean 初始化完成之后才为其创建代理。所以,Spring 选择了三级缓存。但是因为循环依赖的出现,导致了 Spring 不得不提前去创建代理,因为如果不提前创建代理对象,那么注入的就是原始对象,这样就会产生错误。
四、无法解决的循环依赖问题
1.在主bean中通过构造函数注入所依赖的bean
如下controller为主bean,service为所依赖的bean:
@RestController
public class AccountController {
private static final Logger LOG = LoggerFactory.getLogger(AccountController.class);
private AccountService accountService;
// 构造函数依赖注入
// 不管是否设置为required为true,都会出现循环依赖问题
@Autowire
// @Autowired(required = false)
public AccountController(AccountService accountService) {
this.accountService = accountService;
}
}
@Service
public class AccountService {
private static final Logger LOG = LoggerFactory.getLogger(AccountService.class);
// 属性值依赖注入
@Autowired
private AccountController accountController;
}
启动打印如下:
***************************
APPLICATION FAILED TO START
***************************Description:
The dependencies of some of the beans in the application context form a cycle:
┌─────┐
| accountController defined in file [/Users/xieyizun/study/personal-projects/easy-web/target/classes/com/yzxie/easy/log/web/controller/AccountController.class]
↑ ↓
| accountService (field private com.yzxie.easy.log.web.controller.AccountController com.yzxie.easy.log.web.service.AccountService.accountController)
└─────┘
如果是在主bean中通过属性值或者setter方法注入所依赖的bean,而在所依赖的bean使用了构造函数注入主bean对象,这种情况则不会出现循环依赖问题。
@RestController
public class AccountController {
private static final Logger LOG = LoggerFactory.getLogger(AccountController.class);
// 属性值注入
@Autowired
private AccountService accountService;
}
@Service
public class AccountService {
private AccountController accountController;
// 构造函数注入
@Autowired
public AccountService(AccountController accountController) {
this.accountController = accountController;
}
}
2.总结
- 当存在循环依赖时,主bean对象不能通过构造函数的方式注入所依赖的bean对象,而所依赖的bean对象则不受限制,即可以通过三种注入方式的任意一种注入主bean对象。
- 如果主bean对象通过构造函数方式注入所依赖的bean对象,则无论所依赖的bean对象通过何种方式注入主bean,都无法解决循环依赖问题,程序无法启动。(其实在主bean加上@Lazy也能解决)
原因主要是主bean对象通过构造函数注入所依赖bean对象时,无法创建该所依赖的bean对象,获取该所依赖bean对象的引用。因为如下代码所示。
创建主bean对象,调用顺序为:
- 1.调用构造函数
- 2. 放到三级缓存
- 3. 属性赋值。其中调用构造函数时会触发所依赖的bean对象的创建。
// bean对象实例创建的核心实现方法
protected Object doCreateBean(final String beanName, final RootBeanDefinition mbd, final @Nullable Object[] args)
throws BeanCreationException {
// 省略其他代码
// 1. 调用构造函数创建该bean对象,若不存在构造函数注入,顺利通过
instanceWrapper = createBeanInstance(beanName, mbd, args);
// 2. 在singletonFactories缓存中,放入该bean对象,以便解决循环依赖问题
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
// 3. populateBean方法:bean对象的属性赋值
populateBean(beanName, mbd, instanceWrapper);
// 省略其他代码
return exposedObject;
}
createBeanInstance是调用构造函数创建主bean对象,在里面会注入构造函数中所依赖的bean,而此时并没有执行到addSingletonFactory方法来添加主bean对象的创建工厂到三级缓存singletonFactories中。故在createBeanInstance内部,注入和创建该主bean对象时,如果在构造函数中存在对其他bean对象的依赖,并且该bean对象也存在对主bean对象的依赖,则会出现循环依赖问题,原理如下:
主bean对象为A,A对象依赖于B对象,B对象也存在对A对象的依赖,创建A对象时,会触发B对象的创建,则B无法通过三级缓存机制获取主bean对象A的引用(即B如果通过构造函数注入A,则无法创建B对象;如果通过属性注入或者setter方法注入A,则创建B对象后,对B对象进行属性赋值,会卡在populateBean方法也无法返回)。 故无法创建主bean对象所依赖的B,创建主bean对象A时,createBeanInstance方法无法返回,出现代码死锁,程序报循环依赖错误。
注意:spring的循环依赖其实是可以关闭的,设置allowCircularReference=false
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

关于SpringBoot禁止循环依赖解说
前言: Spring的Bean管理,一直是整个体系中津津乐道的东西.尤其是Bean的循环依赖,更是很多面试官最喜欢考察的2B知识点之一. 但事实上,项目中存在Bean的循环依赖,是代码质量低下的表现.多数人寄希望于框架层来给擦屁股,造成了整个代码的设计越来越糟,最后用一些奇技淫巧来填补犯下的错误. 还好,SpringBoot终于受不了这种滥用,默认把循环依赖给禁用了! 从2.6版本开始,如果你的项目里还存在循环依赖,SpringBoot将拒绝启动! 验证代码小片段: 为了验证这个功能,我们只需要
-
SpringBoot2.6.x升级后循环依赖及Swagger无法使用问题
最近想体验下最新版本的SpringBoot,逛了下官网,发现SpringBoot目前最新版本已经是2.6.4了,版本更新确实够快的.之前的项目升级了2.6.4版本后发现有好多坑,不仅有循环依赖的问题,连Swagger都没法用了!今天给大家分享下升级过程,填一填这些坑! SpringBoot实战电商项目mall(50k+star)地址:https://github.com/macrozheng/mall 聊聊SpringBoot版本 首先我们来聊聊SpringBoot的版本,目前最新版本是2.6.
-
Java中的Spring 如何处理循环依赖
目录 前言 什么是循环依赖 构造器循环依赖 Setter循环依赖 构造器循环依赖处理 那么Spring到底是如何做的呢? DefaultSingletonBeanRegistry#getSingleton AbstractAutowireCapableBeanFactory#autowireConstructor setter循环依赖处理 AbstractAutowireCapableBeanFactory#doCreateBean prototype模式的循环依赖 总结 前言 Spring如何
-
Springboot详细讲解循环依赖
目录 一.循环依赖 二.循环依赖形成条件(使用构造器注入) 三.循环依赖形成条件(@Aysnc注解的bean生成了对象的代理) 四.针对以上问题对Spring如何解决循环依赖进行详细阐述 一.循环依赖 顾名思义多个类中的依赖形成了环路,形成了类似于死锁的情况,导致springboot在启动时无法为我们创建Bean.通俗来说 就是beanA中依赖了beanB,beanB中也依赖了beanA. spring是支持循环依赖的,但是默认只支持单例的循环依赖,如果bean中依赖了原型bean,则需要加上l
-
Spring Bean创建和循环依赖
目录 1 前言 2 Bean 的创建 createBeanInstance populateBean initializeBean 循环依赖问题 总结 1 前言 前文已经讲述了Spring BeanFactory 与 FactoryBean 的区别详情,在本文中将继续讲解 Bean 的创建和初始化,在这个环节中将会涉及到 Bean 的创建.初始化和循环依赖内容. 2 Bean 的创建 在前文中已经讲述了 Spring 容器启动的核心方法 refresh,关于 Bean 的创建和初始化方法都是在
-
关于spring循环依赖问题及解决方案
目录 一.三种循环依赖的情况 比如几个Bean之间的互相引用 甚至自己“循环”依赖自己 二.解决方案 如何获取依赖 三.解决循环依赖必须要三级缓存吗 结论 四.无法解决的循环依赖问题 1.在主bean中通过构造函数注入所依赖的bean 2.总结 一.三种循环依赖的情况 ①构造器的循环依赖: 这种依赖spring是处理不了的,直接抛出BeanCurrentlylnCreationException异常. ②单例模式下的setter循环依赖: 通过“三级缓存”处理循环依赖,能处理. ③非单例循环依赖
-
Spring循环依赖的解决方案详解
目录 简介 方案1. Feild注入单例(@AutoWired) 方案2. 构造器注入+@Lazy 方案3. Setter/Field注入单例 方案4. @PostConstruct 方案5. 实现ApplicationContextAware与InitializingBean 简介 说明 本文用实例介绍如何解决Spring的循环依赖问题. 相关网址 Spring循环依赖之问题复现详解 公共代码 package com.example.controller; import com.example
-
Spring循环依赖的三种方式(推荐)
引言:循环依赖就是N个类中循环嵌套引用,如果在日常开发中我们用new 对象的方式发生这种循环依赖的话程序会在运行时一直循环调用,直至内存溢出报错.下面说一下spring是如果解决循环依赖的. 第一种:构造器参数循环依赖 Spring容器会将每一个正在创建的Bean 标识符放在一个"当前创建Bean池"中,Bean标识符在创建过程中将一直保持 在这个池中,因此如果在创建Bean过程中发现自己已经在"当前创建Bean池"里时将抛出 BeanCurrentlyInCrea
-
浅入浅出的讲解Spring循环依赖问题
目录 前言 概念 什么是循环依赖? 报错信息 通俗版理解 两人对峙 必须有一人妥协 Spring版理解 实例化和初始化什么区别? 三级缓存 创建过程(简易版) 创建过程(源码版) 最后 前言 最近有粉丝问到了循环依赖问题,以后再有人问你,拿这篇"吊打"他. 概念 什么是循环依赖? 多个bean之间相互依赖,形成了一个闭环.比如:A依赖于B.B依赖于C.C依赖于A. 通常来说,如果问Spring容器内部如何解决循环依赖,一定是指默认的单例Bean中,基于set方法构造注入的属性互相引用的
-
一文搞懂Spring循环依赖的原理
目录 简介 循环依赖实例 测试 简介 说明 本文用实例来介绍@Autowired解决循环依赖的原理.@Autowired是通过三级缓存来解决循环依赖的. 除了@Autoired,还有其他方案来解决循环依赖的,见:Spring循环依赖的解决方案详解 概述 @Autowired进行属性注入可以解决循环依赖.原理是:Spring控制了bean的生命周期,先实例化bean,后注入bean的属性.Spring中记录了正在创建中的bean(已经实例化但还没初始化完毕的bean),所以可以在注入属性时,从记录
-
Spring 循环依赖之AOP实现详情
前言: 我们接着上一篇文章继续往下看,首先看一下下面的例子,前面的两个serviceA和serviceB不变,我们添加一个BeanPostProcessor: @Component public class MyPostProcessor implements BeanPostProcessor { @Override public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansEx
-
简单了解Spring循环依赖解决过程
这篇文章主要介绍了简单了解Spring循环依赖解决过程,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 前言 说起Spring中循环依赖的解决办法,相信很多园友们都或多或少的知道一些,但当真的要详细说明的时候,可能又没法一下将它讲清楚.本文就试着尽自己所能,对此做出一个较详细的解读.另,需注意一点,下文中会出现类的实例化跟类的初始化两个短语,为怕园友迷惑,事先声明一下,本文的实例化是指刚执行完构造器将一个对象new出来,但还未填充属性值的状态,而
-
Spring循环依赖的解决办法,你真的懂了吗
介绍 先说一下什么是循环依赖,循坏依赖即循环引用,两个或多个bean相互引用,最终形成一个环.Spring在初始化A的时候需要注入B,而初始化B的时候需要注入A,在Spring启动后这2个Bean都要被初始化完成 Spring的循环依赖有两种场景 构造器的循环依赖 属性的循环依赖 构造器的循环依赖,可以在构造函数中使用@Lazy注解延迟加载.在注入依赖时,先注入代理对象,当首次使用时再创建对象完成注入 属性的循环依赖主要是通过3个map来解决的 构造器的循环依赖 @Component publi
-
Java Spring循环依赖原理与bean的生命周期图文案例详解
前言 Spring是如何处理循环依赖的,又是怎么做到,互相注入对方的proxy bean而不是raw bean的?现在就分析一下 一.循环依赖是什么 Spring中放入两个Service,分别是C1和C2,然后C1和C2又互为对方的成员变量.这种情况C1和C2就可以说是相互循环依赖了 二.源码图解 1. bean的主要生命周期图解 上图是一个没有循坏依赖的bean的主要生命周期节点,下图的循坏依赖可以结合该图解一起看 2.循环依赖图解 可以看到里面有一个很重要的逻辑: 当一个bean经过所有的步
-
Java Spring 循环依赖解析
目录 1.常见问题 2.什么是循环依赖? 3.循环依赖说明 4.BeanCurrentlyInCreationException 5.依赖注入的两种方式 方式一:构造器方式注入依赖 方式二:以 set 方式注入依赖 6.Spring 三级缓存介绍和循环依赖解决过程 三级缓存介绍 实例化/初始化定义 三级缓存使用过程 A/B 两对象在三级缓冲的迁移说明 ObjectFactory 接口 DEBUG 断点调试 循环依赖解决 7.Spring 循环依赖总结 1.常见问题 你解释一下 spring 中的