python opencv3机器学习之EM算法
目录
- 引言
- 一、opencv3.0中自带的例子
- 二、trainEM实现自动聚类进行图片目标检测
引言
不同于其它的机器学习模型,EM算法是一种非监督的学习算法,它的输入数据事先不需要进行标注。相反,该算法从给定的样本集中,能计算出高斯混和参数的最大似然估计。也能得到每个样本对应的标注值,类似于kmeans聚类(输入样本数据,输出样本数据的标注)。实际上,高斯混和模型GMM和kmeans都是EM算法的应用。
在opencv3.0中,EM算法的函数是trainEM,函数原型为:
bool trainEM(InputArray samples, OutputArray logLikelihoods=noArray(),OutputArray labels=noArray(),OutputArray probs=noArray())
四个参数:
samples: 输入的样本,一个单通道的矩阵。从这个样本中,进行高斯混和模型估计。
logLikelihoods: 可选项,输出一个矩阵,里面包含每个样本的似然对数值。
labels: 可选项,输出每个样本对应的标注。
probs: 可选项,输出一个矩阵,里面包含每个隐性变量的后验概率
这个函数没有输入参数的初始化值,是因为它会自动执行kmeans算法,将kmeans算法得到的结果作为参数初始化。
这个trainEM函数实际把E步骤和M步骤都包含进去了,我们也可以对两个步骤分开执行,OPENCV3.0中也提供了分别执行的函数:
bool trainE(InputArray samples, InputArray means0,
InputArray covs0=noArray(),
InputArray weights0=noArray(),
OutputArray logLikelihoods=noArray(),
OutputArray labels=noArray(),
OutputArray probs=noArray())
bool trainM(InputArray samples, InputArray probs0,
OutputArray logLikelihoods=noArray(),
OutputArray labels=noArray(),
OutputArray probs=noArray())
trainEM函数的功能和kmeans差不多,都是实现自动聚类,输出每个样本对应的标注值。但它比kmeans还多出一个功能,就是它还能起到训练分类器的作用,用于后续新样本的预测。
预测函数原型为:
Vec2d predict2(InputArray sample, OutputArray probs) const
sample: 待测样本
probs : 和上面一样,一个可选的输出值,包含每个隐性变量的后验概率
返回一个Vec2d类型的数,包括两个元素的double向量,第一个元素为样本的似然对数值,第二个元素为最大可能混和分量的索引值。
在本文中,我们用两个实例来学习opencv中的EM算法的应用。
一、opencv3.0中自带的例子
既包括聚类trianEM,也包括预测predict2
代码:
#include "stdafx.h"
#include "opencv2/opencv.hpp"
#include <iostream>
using namespace std;
using namespace cv;
using namespace cv::ml;
//使用EM算法实现样本的聚类及预测
int main()
{
const int N = 4; //分成4类
const int N1 = (int)sqrt((double)N);
//定义四种颜色,每一类用一种颜色表示
const Scalar colors[] =
{
Scalar(0, 0, 255), Scalar(0, 255, 0),
Scalar(0, 255, 255), Scalar(255, 255, 0)
};
int i, j;
int nsamples = 100; //100个样本点
Mat samples(nsamples, 2, CV_32FC1); //样本矩阵,100行2列,即100个坐标点
Mat img = Mat::zeros(Size(500, 500), CV_8UC3); //待测数据,每一个坐标点为一个待测数据
samples = samples.reshape(2, 0);
//循环生成四个类别样本数据,共样本100个,每类样本25个
for (i = 0; i < N; i++)
{
Mat samples_part = samples.rowRange(i*nsamples / N, (i + 1)*nsamples / N);
//设置均值
Scalar mean(((i%N1) + 1)*img.rows / (N1 + 1),
((i / N1) + 1)*img.rows / (N1 + 1));
//设置标准差
Scalar sigma(30, 30);
randn(samples_part, mean, sigma); //根据均值和标准差,随机生成25个正态分布坐标点作为样本
}
samples = samples.reshape(1, 0);
// 训练分类器
Mat labels; //标注,不需要事先知道
Ptr<EM> em_model = EM::create();
em_model->setClustersNumber(N);
em_model->setCovarianceMatrixType(EM::COV_MAT_SPHERICAL);
em_model->setTermCriteria(TermCriteria(TermCriteria::COUNT + TermCriteria::EPS, 300, 0.1));
em_model->trainEM(samples, noArray(), labels, noArray());
//对每个坐标点进行分类,并根据类别用不同的颜色画出
Mat sample(1, 2, CV_32FC1);
for (i = 0; i < img.rows; i++)
{
for (j = 0; j < img.cols; j++)
{
sample.at<float>(0) = (float)j;
sample.at<float>(1) = (float)i;
//predict2返回的是double值,用cvRound进行四舍五入得到整型
//此处返回的是两个值Vec2d,取第二个值作为样本标注
int response = cvRound(em_model->predict2(sample, noArray())[1]);
Scalar c = colors[response]; //为不同类别设定颜色
circle(img, Point(j, i), 1, c*0.75, FILLED);
}
}
//画出样本点
for (i = 0; i < nsamples; i++)
{
Point pt(cvRound(samples.at<float>(i, 0)), cvRound(samples.at<float>(i, 1)));
circle(img, pt, 2, colors[labels.at<int>(i)], FILLED);
}
imshow("EM聚类结果", img);
waitKey(0);
return 0;
}
结果:
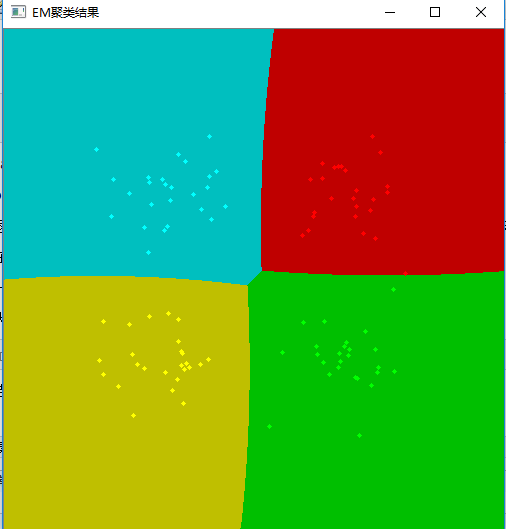
二、trainEM实现自动聚类进行图片目标检测
只用trainEM实现自动聚类功能,进行图片中的目标检测
代码:
#include "stdafx.h"
#include "opencv2/opencv.hpp"
#include <iostream>
using namespace std;
using namespace cv;
using namespace cv::ml;
int main()
{
const int MAX_CLUSTERS = 5;
Vec3b colorTab[] =
{
Vec3b(0, 0, 255),
Vec3b(0, 255, 0),
Vec3b(255, 100, 100),
Vec3b(255, 0, 255),
Vec3b(0, 255, 255)
};
Mat data, labels;
Mat pic = imread("d:/woman.png");
for (int i = 0; i < pic.rows; i++)
for (int j = 0; j < pic.cols; j++)
{
Vec3b point = pic.at<Vec3b>(i, j);
Mat tmp = (Mat_<float>(1, 3) << point[0], point[1], point[2]);
data.push_back(tmp);
}
int N =3; //聚成3类
Ptr<EM> em_model = EM::create();
em_model->setClustersNumber(N);
em_model->setCovarianceMatrixType(EM::COV_MAT_SPHERICAL);
em_model->setTermCriteria(TermCriteria(TermCriteria::COUNT + TermCriteria::EPS, 300, 0.1));
em_model->trainEM(data, noArray(), labels, noArray());
int n = 0;
//显示聚类结果,不同的类别用不同的颜色显示
for (int i = 0; i < pic.rows; i++)
for (int j = 0; j < pic.cols; j++)
{
int clusterIdx = labels.at<int>(n);
pic.at<Vec3b>(i, j) = colorTab[clusterIdx];
n++;
}
imshow("pic", pic);
waitKey(0);
return 0;
}
测试图片

测试结果:
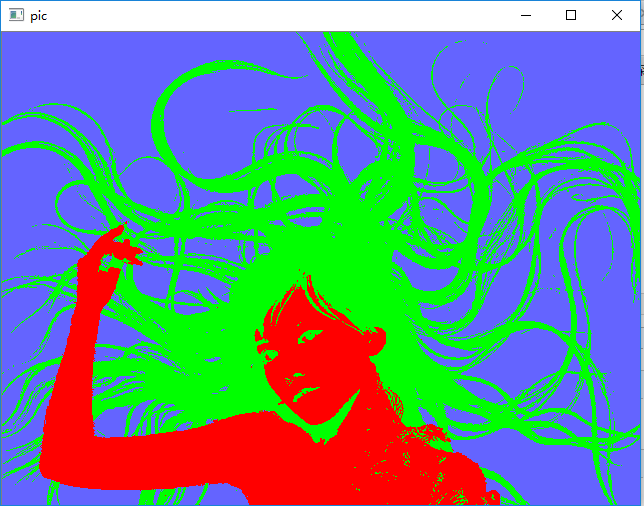
以上就是python opencv3机器学习之EM算法的详细内容,更多关于python opencv3 EM算法的资料请关注我们其它相关文章!
相关推荐
-

python opencv3机器学习之EM算法
目录 引言 一.opencv3.0中自带的例子 二.trainEM实现自动聚类进行图片目标检测 引言 不同于其它的机器学习模型,EM算法是一种非监督的学习算法,它的输入数据事先不需要进行标注.相反,该算法从给定的样本集中,能计算出高斯混和参数的最大似然估计.也能得到每个样本对应的标注值,类似于kmeans聚类(输入样本数据,输出样本数据的标注).实际上,高斯混和模型GMM和kmeans都是EM算法的应用. 在opencv3.0中,EM算法的函数是trainEM,函数原型为: bool train
-
纯python实现机器学习之kNN算法示例
前面文章分别简单介绍了线性回归,逻辑回归,贝叶斯分类,并且用python简单实现.这篇文章介绍更简单的 knn, k-近邻算法(kNN,k-NearestNeighbor). k-近邻算法(kNN,k-NearestNeighbor),是最简单的机器学习分类算法之一,其核心思想在于用距离目标最近的k个样本数据的分类来代表目标的分类(这k个样本数据和目标数据最为相似). 原理 kNN算法的核心思想是用距离最近(多种衡量距离的方式)的k个样本数据来代表目标数据的分类. 具体讲,存在训练样本集, 每个
-
EM算法的python实现的方法步骤
前言:前一篇文章大概说了EM算法的整个理解以及一些相关的公式神马的,那些数学公式啥的看完真的是忘完了,那就来用代码记忆记忆吧!接下来将会对python版本的EM算法进行一些分析. EM的python实现和解析 引入问题(双硬币问题) 假设有两枚硬币A.B,以相同的概率随机选择一个硬币,进行如下的抛硬币实验:共做5次实验,每次实验独立的抛十次,结果如图中a所示,例如某次实验产生了H.T.T.T.H.H.T.H.T.H,H代表正面朝上. 假设试验数据记录员可能是实习生,业务不一定熟悉,造成a和b两种
-
机器学习之KNN算法原理及Python实现方法详解
本文实例讲述了机器学习之KNN算法原理及Python实现方法.分享给大家供大家参考,具体如下: 文中代码出自<机器学习实战>CH02,可参考本站: 机器学习实战 (Peter Harrington著) 中文版 机器学习实战 (Peter Harrington著) 英文原版 [附源代码] KNN算法介绍 KNN是一种监督学习算法,通过计算新数据与训练数据特征值之间的距离,然后选取K(K>=1)个距离最近的邻居进行分类判(投票法)或者回归.若K=1,新数据被简单分配给其近邻的类. KNN算法
-
Python机器学习k-近邻算法(K Nearest Neighbor)实例详解
本文实例讲述了Python机器学习k-近邻算法.分享给大家供大家参考,具体如下: 工作原理 存在一份训练样本集,并且每个样本都有属于自己的标签,即我们知道每个样本集中所属于的类别.输入没有标签的新数据后,将新数据的每个特征与样本集中数据对应的特征进行比较,然后提取样本集中与之最相近的k个样本.观察并统计这k个样本的标签,选择数量最大的标签作为这个新数据的标签. 用以下这幅图可以很好的解释kNN算法: 不同形状的点,为不同标签的点.其中绿色点为未知标签的数据点.现在要对绿色点进行预测.由图不难得出
-
Python实现EM算法实例代码
EM算法实例 通过实例可以快速了解EM算法的基本思想,具体推导请点文末链接.图a是让我们预热的,图b是EM算法的实例. 这是一个抛硬币的例子,H表示正面向上,T表示反面向上,参数θ表示正面朝上的概率.硬币有两个,A和B,硬币是有偏的.本次实验总共做了5组,每组随机选一个硬币,连续抛10次.如果知道每次抛的是哪个硬币,那么计算参数θ就非常简单了,如 下图所示: 如果不知道每次抛的是哪个硬币呢?那么,我们就需要用EM算法,基本步骤为: 1.给θ_AθA和θ_BθB一个初始值: 2.(E-
-
Python机器学习之AdaBoost算法
一.算法概述 AdaBoost 是英文 Adaptive Boosting(自适应增强)的缩写,由 Yoav Freund 和Robert Schapire 在1995年提出. AdaBoost 的自适应在于前一个基本分类器分类错误的样本的权重会得到加强,加强后的全体样本再次被用来训练下一个基本分类器.同时,在每一轮训练中加入一个新的弱分类器,直到达到某个预定的足够小的错误率或达到预先指定的最大迭代次数时停止训练. AdaBoost 算法是一种集成学习的算法,其核心思想就是对多个机器学习模型进行
-
Python实现机器学习算法的分类
Python算法的分类 对葡萄酒数据集进行测试,由于数据集是多分类且数据的样本分布不平衡,所以直接对数据测试,效果不理想.所以使用SMOTE过采样对数据进行处理,对数据去重,去空,处理后数据达到均衡,然后进行测试,与之前测试相比,准确率提升较高. 例如:决策树: Smote处理前: Smote处理后: from typing import Counter from matplotlib import colors, markers import numpy as np import pandas
-
Python机器学习入门(五)算法审查
目录 1.审查分类算法 1.1线性算法审查 1.1.1逻辑回归 1.1.2线性判别分析 1.2非线性算法审查 1.2.1K近邻算法 1.2.2贝叶斯分类器 1.2.4支持向量机 2.审查回归算法 2.1线性算法审查 2.1.1线性回归算法 2.1.2岭回归算法 2.1.3套索回归算法 2.1.4弹性网络回归算法 2.2非线性算法审查 2.2.1K近邻算法 2.2.2分类与回归树 2.2.3支持向量机 3.算法比较 总结 程序测试是展现BUG存在的有效方式,但令人绝望的是它不足以展现其缺位. --
-
python机器学习实现oneR算法(以鸢尾data为例)
目录 一.导包与获取数据 二.划分为训练集和测试集 三.定义函数:获取某特征值出现次数最多的类别及错误率 四.定义函数:获取每个特征值下出现次数最多的类别.错误率 五.调用函数,获取最佳特征值 六.测试算法 oneR即“一条规则”.oneR算法根据已有的数据中,具有相同特征值的个体最可能属于哪个类别来进行分类.以鸢尾data为例,该算法实现过程可解读为以下六步: 一. 导包与获取数据 以均值为阈值,将大于或等于阈值的特征标记为1,低于阈值的特征标记为0. import numpy as np f