C#通过不安全代码看内存加载的示例详解
目录
- 项目文件
- 值类型
- 自定义结构体
- 引用类型string
- 自定class类型
C#中类型分为值类型和引用类型,值类型存储在堆栈中,是栈结构,先进后出,引用类型存储在托管堆中。接下来用不安全代码的地址,来看一下值类型和引用类型的存储。
项目文件
C#中使用不安全代码需要在项目文件中添加AllowUnsafeBlocks配置。
<Project Sdk="Microsoft.NET.Sdk">
<PropertyGroup>
<OutputType>Exe</OutputType>
<TargetFramework>net7.0</TargetFramework>
<ImplicitUsings>enable</ImplicitUsings>
<Nullable>enable</Nullable>
<AllowUnsafeBlocks>true</AllowUnsafeBlocks>
</PropertyGroup>
</Project>
所有的测试案例都是定义两个特定类型的变量,然后查看它的内存地址,然后进行调用一个方法进行相加运算,然后分别在方法内输出变量和结查内存地址,最后返回主方法后变量的内存地址。
值类型
static void TestDouble()
{
var v1 = 1.00001d;
var v2 = 2.00002d;
Console.WriteLine("TestDouble v1 " + (long)&v1);
Console.WriteLine("TestDouble v2 " + (long)&v2);
Console.WriteLine("TestDouble v2-v1 " + ((long)&v2 - (long)&v1));
var v3 = Add(v1, v2);
Console.WriteLine("TestDouble v3 " + (long)&v3);
Console.WriteLine("TestDouble v3-v2 " + ((long)&v3 - (long)&v2));
Console.WriteLine("TestDouble v3-v1 " + ((long)&v3 - (long)&v1));
}
static double Add(double v1, double v2)
{
Console.WriteLine("Add v1 " + (long)&v1);
Console.WriteLine("Add v2 " + (long)&v2);
Console.WriteLine("Add v2-v1 " + ((long)&v2 - (long)&v1));
var v3 = v1 + v2;
Console.WriteLine("Add v3 " + (long)&v3);
Console.WriteLine("Add v3-v2 " + ((long)&v3 - (long)&v2));
Console.WriteLine("Add v3-v1 " + ((long)&v3 - (long)&v1));
return v3;
}

v1的所在内存地址大于v2,最后运算完的v3是最小的,我们可以想象,v1放在栈的最后面,地址最大,然后放v2,最后放v3。回收时的顺序是反回来的。那么Add方法里,v2地址最大,但比TestDouble都要小,说明进栈要晚一些,接下来是v1进栈,最后是v3进栈,不过TestDouble里的每个变量都相差8,但方法里的就不是了,这是因为方法参数,返回值等信息,还要占一些内存空间。还有TestDouble的v3为什么能和v2相差8?不是有Add方法吗?原因是Add调用完后都出栈了,所以TestDouble的v3和v2是相邻的。
自定义结构体
struct TestStruct
{
public TestStruct()
{
i = 100;
}
public long i;
}
static void TestTestStruct()
{
var v1 = new TestStruct();
Console.WriteLine("TestStruct原v1对象地址= " + (long)&v1);
var v2 = new TestStruct();
Console.WriteLine("TestStruct原v2对象地址= " + (long)&v2);
Console.WriteLine("TestStruct v2-v1 " + ((long)&v2 - (long)&v1));
var v3 = Add(v1, v2);
Console.WriteLine("TestStruct原v3对象地址= " + (long)&v3);
Console.WriteLine("TestStruct v3-v2 " + ((long)&v3 - (long)&v2));
}
static TestStruct Add(TestStruct v1, TestStruct v2)
{
Console.WriteLine("Add TestStruct v1对象地址= " + (long)&v1);
Console.WriteLine("Add TestStruct v2对象地址= " + (long)&v2);
Console.WriteLine("Add TestStruct v2-v1 " + ((long)&v2 - (long)&v1));
var v3 = new TestStruct();
v3.i = v1.i + v2.i;
Console.WriteLine("Add TestStruct v3对象地址" + (long)&v3);
Console.WriteLine("Add TestStruct v3-v2 " + ((long)&v3 - (long)&v2));
return v3;
}
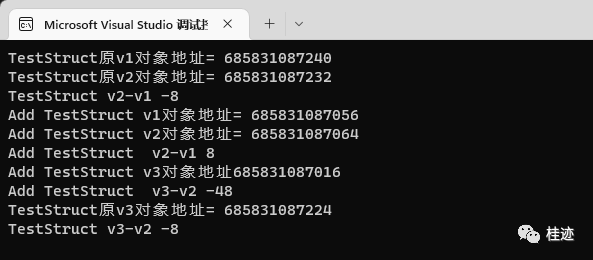
自定义struct与double类似,本质上double也是用struct定义的。
引用类型string
static void TestString()
{
long ad1, ad2, ad3;
var v1 = "aaaa";
var v2 = "bbbb";
fixed (char* p = v1)
{
ad1 = (long)p;
Console.WriteLine("TestString v1字符串地址= " + (long)p);
}
fixed (char* p = v2)
{
ad2 = (long)p;
Console.WriteLine("TestString v2字符串地址= " + (long)p);
}
Console.WriteLine("TestString v2-v1 " + (ad2 - ad1));
var v3 = Add(v1, v2);
fixed (char* p = v3)
{
ad3 = (long)p;
Console.WriteLine("TestString v3字符串地址= " + (long)p);
}
Console.WriteLine("TestString v3-v2 " + (ad3 - ad2));
}
static string Add(string v1, string v2)
{
long ad1, ad2, ad3;
fixed (char* p = v1)
{
ad1 = (long)p;
Console.WriteLine("Add中v1字符串地址= " + (long)p);
}
fixed (char* p = v2)
{
ad2 = (long)p;
Console.WriteLine("Add中v2字符串地址= " + (long)p);
}
Console.WriteLine("Add中 v2-v1 " + (ad2 - ad1));
var v3 = v1 + v2;
fixed (char* p = v3)
{
ad3 = (long)p;
Console.WriteLine("Add中v3字符串地址= " + (long)p);
}
Console.WriteLine("Add中 v3-v2 " + (ad3 - ad2));
Console.WriteLine("Add中 v3-v1 " + (ad3 - ad1));
return v3;
}
static void TestString2()
{
var v1 = "aaaa";
var v2 = "bbbb";
var h1 = GCHandle.Alloc(v1, GCHandleType.Pinned);
Console.WriteLine("TestString2 v1对象地址= " + (long)h1.AddrOfPinnedObject());
var h2 = GCHandle.Alloc(v2, GCHandleType.Pinned);
Console.WriteLine("TestString2 v2对象地址= " + (long)h2.AddrOfPinnedObject());
Console.WriteLine("TestString2 v2-v1 " + ((long)h2.AddrOfPinnedObject() - (long)h1.AddrOfPinnedObject()));
var v3 = Add2(v1, v2);
var h3 = GCHandle.Alloc(v3, GCHandleType.Pinned);
Console.WriteLine("TestString2 v3对象地址= " + (long)h3.AddrOfPinnedObject());
Console.WriteLine("TestString2 v3-v2 " + ((long)h3.AddrOfPinnedObject() - (long)h2.AddrOfPinnedObject()));
}
static string Add2(string v1, string v2)
{
var h1 = GCHandle.Alloc(v1, GCHandleType.Pinned);
Console.WriteLine("Add2中的v1对象地址= " + (long)h1.AddrOfPinnedObject());
var h2 = GCHandle.Alloc(v2, GCHandleType.Pinned);
Console.WriteLine("Add2中的v2对象地址= " + (long)h2.AddrOfPinnedObject());
Console.WriteLine("Add2 v2-v1 " + ((long)h2.AddrOfPinnedObject() - (long)h1.AddrOfPinnedObject()));
var v3 = v1 + v2;
var h3 = GCHandle.Alloc(v3, GCHandleType.Pinned);
Console.WriteLine("Add2中的v3对象地址= " + (long)h3.AddrOfPinnedObject());
Console.WriteLine("Add2 v3-v2 " + ((long)h3.AddrOfPinnedObject() - (long)h2.AddrOfPinnedObject()));
Console.WriteLine("Add2 v3-v1 " + ((long)h3.AddrOfPinnedObject() - (long)h1.AddrOfPinnedObject()));
return v3;
}

字符串是引用类型,v1比v2内存地址小,进入Add后,v1和v2与传入的地址相同,因为是引用类型,Add方法里的v3接着往大走,并且与返回的v3是一个地址,这些没有问题。
string用了两种方法,发现两个方式v1都是aaaa,v2都是bbbb,因为字符串有留用性,所以两个方法的v1和v2是一样的;但两种方式调用了Add后,在Add里的v3都是aaaabbbb,都是拼接,但拼出来的字符串的地址不相同,所以这块没有留用。
自定class类型
class TestClass
{
public int i = 100;
}
static void TestTestClass()
{
var v1 = new TestClass();
var h1 = GCHandle.Alloc(v1, GCHandleType.Pinned);
Console.WriteLine("TestTestClass v1对象地址= " + (long)h1.AddrOfPinnedObject());
var v2 = new TestClass();
var h2 = GCHandle.Alloc(v2, GCHandleType.Pinned);
Console.WriteLine("TestTestClass v2对象地址= " + (long)h2.AddrOfPinnedObject());
Console.WriteLine("TestTestClass v2-v1 " + ((long)h2.AddrOfPinnedObject() - (long)h1.AddrOfPinnedObject()));
var v3 = Add(v1, v2);
var h3 = GCHandle.Alloc(v3, GCHandleType.Pinned);
Console.WriteLine("TestTestClass 3对象地址= " + (long)h3.AddrOfPinnedObject());
Console.WriteLine("TestTestClass v3-v2 " + ((long)h3.AddrOfPinnedObject() - (long)h2.AddrOfPinnedObject()));
}
static TestClass Add(TestClass v1, TestClass v2)
{
var h1 = GCHandle.Alloc(v1, GCHandleType.Pinned);
Console.WriteLine("Add中的v1对象地址= " + (long)h1.AddrOfPinnedObject());
var h2 = GCHandle.Alloc(v2, GCHandleType.Pinned);
Console.WriteLine("Add中的v2对象地址= " + (long)h2.AddrOfPinnedObject());
Console.WriteLine("Add中 v2-v1 " + ((long)h2.AddrOfPinnedObject() - (long)h1.AddrOfPinnedObject()));
var v3 = new TestClass();
v3.i = v1.i + v2.i;
var h3 = GCHandle.Alloc(v3, GCHandleType.Pinned);
Console.WriteLine("Add中的v3对象地址= " + (long)h3.AddrOfPinnedObject());
Console.WriteLine("Add中 v3-v2 " + ((long)h3.AddrOfPinnedObject() - (long)h2.AddrOfPinnedObject()));
Console.WriteLine("Add中 v3-v1 " + ((long)h3.AddrOfPinnedObject() - (long)h1.AddrOfPinnedObject()));
return v3;
}
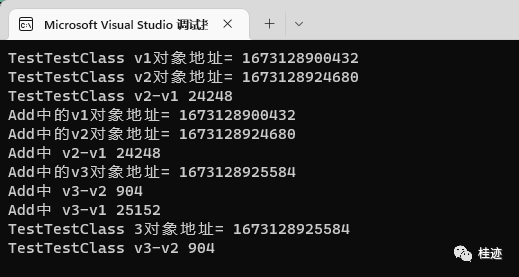
自定义class,每次都是新地址,没有留用性,并且地址都是在增加。
当然引用类型的地址不是一成不变的,因为有垃圾回放,重新整理的过程,本例用用Pinned的方式固定,不过代码量少的情况也不一定能触发回收。
以上就是C#通过不安全代码看内存加载的示例详解的详细内容,更多关于C# 内存加载的资料请关注我们其它相关文章!
相关推荐
-
详细分析c# 客户端内存优化
背景概述 C# 开发客户端系统的时候,.net 框架本身就比较消耗内存资源,特别是xp 这种老爷机内存配置不是很高的电脑上运行,所以就需要进行内存上的优化,才能流畅的在哪些低端电脑上运行. 想要对C# 开发的客户端内存优化需要了解以下几个概念. 虚拟内存 这里引用百度百科的概念:虚拟内存是计算机系统内存管理的一种技术.它使得应用程序认为它拥有连续的可用的内存(一个连续完整的地址空间),而实际上,它通常是被分隔成多个物理内存碎片,还有部分暂时存储在外部磁盘存储器上,在需要时进行数据交换.目前,大多
-
C#中event内存泄漏总结
内存泄漏是指:当一块内存被分配后,被丢弃,没有任何实例指针指向这块内存, 并且这块内存不会被GC视为垃圾进行回收.这块内存会一直存在,直到程序退出.C#是托管型代码,其内存的分配和释放都是由CLR负责,当一块内存没有任何实例引用时,GC会负责将其回收.既然没有任何实例引用的内存会被GC回收,那么内存泄漏是如何发生的? 内存泄漏示例 为了演示内存泄漏是如何发生的,我们来看一段代码 class Program { static event Action TestEvent; static void
-

C#内存管理CLR深入讲解(下篇)
<上篇>中我们主要讨论的是程序集(Assembly)和应用程序域(AppDomain)的话题,着重介绍了两个不同的程序集加载方式——独占方式和共享方式(中立域方式):以及基于进程范围内的字符串驻留.这篇将关注点放在托管对象创建时内存的分配和对大对象(LO:Large Object)的回收上,不对之处,还望各位能够及时指出. 一.从类型(Type)与实例(Instance)谈起 在面向对象的世界中,类型和实例是两个核心的要素.不论是类型和实例,相关的信息比如加载到内存中,对应着某一块或者多块连续
-
C#内存管理CLR深入讲解(上篇)
半年之前,PM让我在部门内部进行一次关于“内存泄露”的专题分享,我为此准备了一份PPT.今天无意中将其翻出来,觉得里面提到的关于CLR下关于内存管理部分的内存还有点意思.为此,今天按照PPT的内容写了一篇文章.本篇文章不会在讨论那些我们熟悉的话题,比如“值类型引用类型具有怎样的区别?”.“垃圾回收分为几个步骤?”.“Finalizer和Dispose有何不同”.等等,而是讨论一些不同的内容.整篇文章分上下两篇,上篇主要谈论的是“程序集(Assembly)和应用程序域(AppDomain)”.也许
-
在C#中捕获内存不足异常
当CLR未能分配所需的足够内存时,将发生System.OutOfMemoryException.System.OutOfMemoryException继承自System.SystemException类.OutOfMemoryException使用COR_E_OUTOFMEMORY值为 0x8007000E的 HRESULT . 一个OutOfMemoryException异常异常主要有两个原因: 我们试图将StringBuilder对象扩展到超出其StringBuilder.MaxCapaci
-
C#通过不安全代码看内存加载的示例详解
目录 项目文件 值类型 自定义结构体 引用类型string 自定class类型 C#中类型分为值类型和引用类型,值类型存储在堆栈中,是栈结构,先进后出,引用类型存储在托管堆中.接下来用不安全代码的地址,来看一下值类型和引用类型的存储. 项目文件 C#中使用不安全代码需要在项目文件中添加AllowUnsafeBlocks配置. <Project Sdk="Microsoft.NET.Sdk"> <PropertyGroup> <OutputType>E
-
mybatis xml文件热加载实现示例详解
目录 引言 一.xml 文件热加载实现原理 1.1 xml 文件怎么样解析 1.2 实现思路 二.mybatis-xmlreload-spring-boot-starter 登场 2.1 核心代码 2.2 安装方式 2.3 使用配置 最后 引言 本文博主给大家带来一篇 mybatis xml 文件热加载的实现教程,自博主从事开发工作使用 Mybatis 以来,如果需要修改 xml 文件的内容,通常都需要重启项目,因为不重启的话,修改是不生效的,Mybatis 仅仅会在项目初始化的时候将 xml
-
Java动态加载类示例详解
在讲解动态加载类之前呢,我们先弄清楚为什么要动态加载类,静态加载不行吗?我们可以看下面的实例: 我在文件夹里写了Office.java 类和 Word.java类,如下: Office.java class Office{ public static void main(String[] args){ if(args[0].equals("Word")){ Word w = new Word(); w.start(); } if(args[0].equals("Excel&q
-
Java代码块与代码加载顺序原理详解
这篇文章主要介绍了Java代码块与代码加载顺序原理详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 本文首先介绍几个基本的名次,然后介绍了三种代码块的特性和使用方法. 在面试大型公司时,如果遇到大型国企或者大的互联网私企,笔试中经常遇到代码块和代码加载顺序的笔试题.这里做一个总结,也方便各位小伙伴飙车不会飘. 名词解释 代码块 由 { } 包起来的代码,称为代码块 静态代码块 由 static { } 包起来的代码,称为静态代码块. 不同类型
-
webpack学习笔记之代码分割和按需加载的实例详解
本文介绍了webpack学习笔记之代码分割和按需加载的实例详解,分享给大家,也给自己留个笔记 为什么需要代码分割和按需加载 代码分割就是我们根据实际业务需求将代码进行分割,然后在合适的时候在将其加载进入文档中. 举个简单的例子: 1.一个HTML中存在一个按钮 2.点击按钮出现一个包着图片的div 3.点击关闭按钮图片消失 Demo目录: 一.当未点击按钮时浏览器只加载了对入口文件打包后的js 二.点击按钮会对组件进行异步加载 这个clichunk就是我们打包好的click组件,包括相应的JS逻
-
JDBC数据库连接过程及驱动加载与设计模式详解
首先要导入JDBC的jar包: 接下来,代码: Class.forName(xxx.xx.xx)返回的是一个类 Class.forName(xxx.xx.xx)的作用是要求JVM查找并加载指定的类,也就是说JVM会执行该类的静态代码段. JDBC连接数据库 • 创建一个以JDBC连接数据库的程序,包含7个步骤: 1.加载JDBC驱动程序: 在连接数据库之前,首先要加载想要连接的数据库的驱动到JVM(Java虚拟机), 这通过java.lang.Class类的静态方法forName(String
-
vue实现网络图片瀑布流 + 下拉刷新 + 上拉加载更多(步骤详解)
一.思路分析和效果图 用vue来实现一个瀑布流效果,加载网络图片,同时有下拉刷新和上拉加载更多功能效果.然后针对这几个效果的实现,捋下思路: 根据加载数据的顺序,依次追加标签展示效果: 选择哪种方式实现瀑布流,这里选择绝对定位方式: 关键问题:由于每张图片的宽高不一样,而瀑布流中要求所有图片的宽度一致,高度随宽度等比缩放.而且由于图片的加载是异步延迟.在不知道图片高度的情况下,每个图片所在的item盒子不好绝对定位.因此在渲染页面前先获取所有图片的高度,是解决问题的关键点!这里选择用JS中的Im
-
Android性能优化之RecyclerView分页加载组件功能详解
目录 引言 1 分页加载组件 1.1 功能定制 1.2 手写分页列表 1.3 生命周期管理 2 github 引言 在Android应用中,列表有着举足轻重的地位,几乎所有的应用都有列表的身影,但是对于列表的交互体验一直是一个大问题.在性能比较好的设备上,列表滑动几乎看不出任何卡顿,但是放在低端机上,卡顿会比较明显,而且列表中经常会伴随图片的加载,卡顿会更加严重,因此本章从手写分页加载组件入手,并对列表卡顿做出对应的优化 1 分页加载组件 为什么要分页加载,通常列表数据存储在服务端会超过100条
-
前端JS图片懒加载原理方案详解
目录 背景 原理 方案 方案一:img的loading属性设为“lazy” 使用方法 优点 兼容性 缺点 方案二:通过offsetTop来计算是否在可视区域内 优化 优点 缺点 方案三:通过getBoundingClientRect来计算是否在可视区域内 方案四:使用IntersectionObserver来判断是否在可视区域内 兼容性 优点 缺点 问题 布局抖动 响应式图片 SEO不友好 插件 背景 懒加载经常出现在前端面试中,是前端性能优化的常用技巧.懒加载也叫延迟加载,把非关键资源先不加载
-
JS图片懒加载库VueLazyLoad详解
目录 背景 说明 实现原理 1. placeholder 的实现很细致和灵活 2. 添加图片缓存 3. 事件监听使用节流 4. 监听事件不止滚动事件 5. 事件列队的方式来处理懒加载 6. 支持 data-srcset 7. 自定义控制可视区的判定范围 待完善 1. 没有解决布局抖动 2. 跳过已经加载图片的判断方式 3. 局部懒加载 4. 性能不是很好 5. observer 模式配置简单 6. SEO 不友好 总结 背景 上篇<图片懒加载原理方案详解>中详细解析了图片懒加载的原理和方案.主