Python百度指数获取脚本下载并保存
目录
- 前言
- 具体步骤
- 1. 获得cookie值
- 2. 使用我的代码
- 可视化
- 总结
前言
有时候大家需要知道一个关键词在互联网上的热度,想知道某个关键词的热度变化趋势。大家可能就是使用百度指数、微信指数之类的。非常好用,但是就是不能把数据下载保存下来,不方便我们后面进行操作。
我无意间看到别人提供的python脚本,可以对百度指数进行爬虫,于是我稍微修改了部分代码,做了一个可以直接返回pd.DataFrame的数据框的类;然后后面又加了一个小的可视化代码。这里和大家分享,只要使用这个脚本,就可以将百度指数数据下载下来,并且保存。
具体步骤
1. 获得cookie值
百度指数是需要登陆,进行用户验证,因此,我们要登陆百度指数,然后随便搜索一个关键词,比如python。然后在网页空白地方,右键打开【检查】,然后进入【网络】

这个时候会发现【网络】里面都是空的,需要重新刷新网页即可看到所有内容。内容太多了,注意选择【Fetch/XHR】.
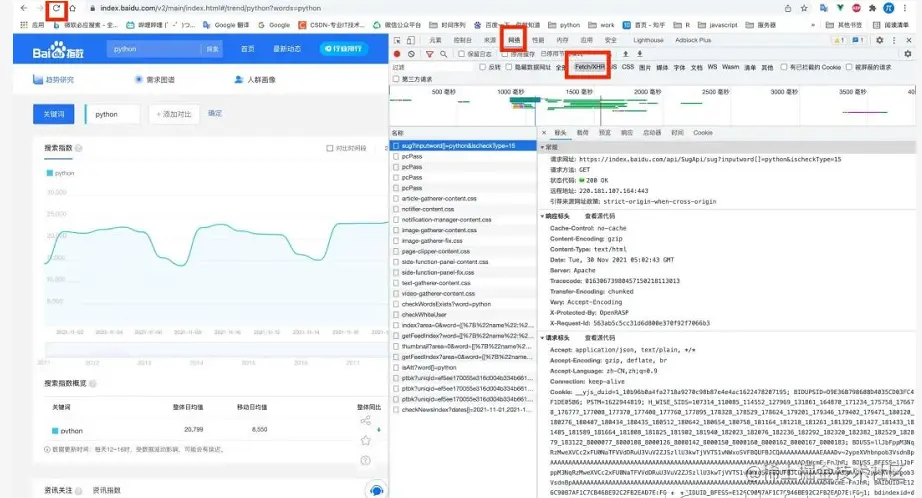
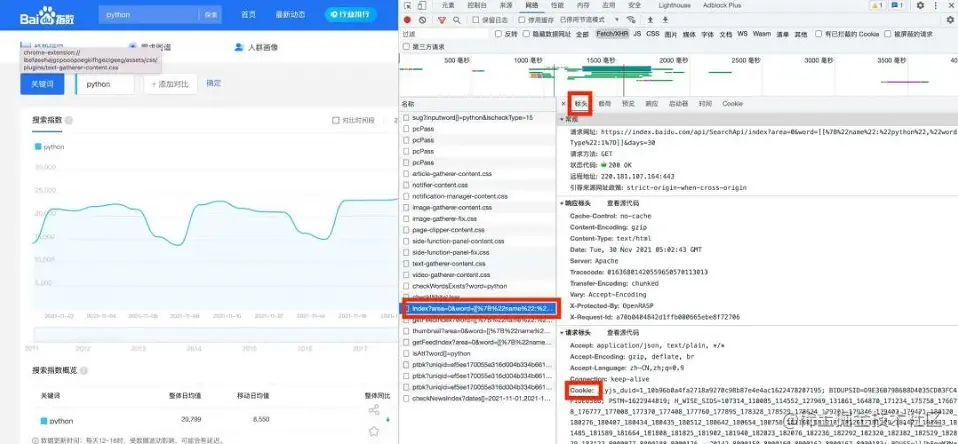
然后找到index?开头的文件,查看他的【标头】、查看他的【Cookie】.将这个cookie的值复制
2. 使用我的代码
基础代码,只要复制好就行:
import requests
import json
from datetime import date, timedelta
import pandas as pd
class DownloadBaiDuIndex(object):
def __init__(self, cookie):
self.cookie = cookie
self.headers = {
"Connection": "keep-alive",
"Accept": "application/json, text/plain, */*",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36",
"Sec-Fetch-Site": "same-origin",
"Sec-Fetch-Mode": "cors",
"Sec-Fetch-Dest": "empty",
"Referer": "https://index.baidu.com/v2/main/index.html",
"Accept-Language": "zh-CN,zh;q=0.9",
'Cookie': self.cookie,
}
def decrypt(self, ptbk, index_data):
n = len(ptbk) // 2
a = dict(zip(ptbk[:n], ptbk[n:]))
return "".join([a[s] for s in index_data])
def get_index_data_json(self, keys, start=None, end=None):
words = [[{"name": key, "wordType": 1}] for key in keys]
words = str(words).replace(" ", "").replace("'", """)
url = f'http://index.baidu.com/api/SearchApi/index?area=0&word={words}&area=0&startDate={start}&endDate={end}'
print(words, start, end)
res = requests.get(url, headers=self.headers)
data = res.json()['data']
uniqid = data['uniqid']
url = f'http://index.baidu.com/Interface/ptbk?uniqid={uniqid}'
res = requests.get(url, headers=self.headers)
ptbk = res.json()['data']
result = {}
result["startDate"] = start
result["endDate"] = end
for userIndexe in data['userIndexes']:
name = userIndexe['word'][0]['name']
tmp = {}
index_all = userIndexe['all']['data']
index_all_data = [int(e) for e in self.decrypt(ptbk, index_all).split(",")]
tmp["all"] = index_all_data
index_pc = userIndexe['pc']['data']
index_pc_data = [int(e) for e in self.decrypt(ptbk, index_pc).split(",")]
tmp["pc"] = index_pc_data
index_wise = userIndexe['wise']['data']
index_wise_data = [int(e)
for e in self.decrypt(ptbk, index_wise).split(",")]
tmp["wise"] = index_wise_data
result[name] = tmp
return result
def GetIndex(self, keys, start=None, end=None):
today = date.today()
if start is None:
start = str(today - timedelta(days=8))
if end is None:
end = str(today - timedelta(days=2))
try:
raw_data = self.get_index_data_json(keys=keys, start=start, end=end)
raw_data = pd.DataFrame(raw_data[keys[0]])
raw_data.index = pd.date_range(start=start, end=end)
except Exception as e:
print(e)
raw_data = pd.DataFrame({'all': [], 'pc': [], 'wise': []})
finally:
return raw_data
使用上面的类:
使用上面的类,然后使用下面的代码。先初始化类,然后在使用这个对象的GetIndex函数,里面的参数keys就是传递一个关键词就行,要用列表形式传递。
说更加简单一点的,只要把python替换成别的关键词就行了,然后时间也都是文本形式,样式就是'yyyy-mm-dd'形式就行。
cookie = '你的cookie值,注意使用英文单引号;就是直接复制就行了' # 初始化一个类 downloadbaiduindex = DownloadBaiDuIndex(cookie=cookie) data = downloadbaiduindex.GetIndex(keys=['python'], start='2021-01-01', end='2021-11-12') data
保存数据
如果想保存数据,直接可以这么写:
data.to_csv('data.csv')
可视化
获得数据已经很简单了,接下来可视化,就是非常简单的事情了,你用别的语言处理数据也都可以了。我这里简单的画一个时间序列图:
import plotly.graph_objects as go
import pandas as pd
df = data
fig = go.Figure([go.Scatter(x=df.index, y=df['all'], fill='tozeroy')])
fig.update_layout(template='plotly_white', title='python 百度指数')
fig.show()
fig.write_html('python.html')
结果如下:

总结
上面基本上没有任何难点了,只要没把cookie复制错,只要没有把上面的参数写错就行。
到此这篇关于Python百度指数获取脚本下载并保存的文章就介绍到这了,更多相关Python获取脚本内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python实现一键下载视频脚本
目录 需求 解决方案 代码 总结 需求 小编通常会上一些专业的视频网站比如腾讯视频.优酷,在上面看电影.电视剧.这些网站有个优点,可以缓存视频,在通勤路上比如地铁就可以愉快的刷剧了,因为地铁上的网速通常不怎么好. 但是有一些经典电影或者电视剧,这些视频并没有提供,那么我们只能上一些小电影网站看了,资源是有了,但是问题来了,这些小电影网站大多数都没有视频下载功能,那在地铁上就没法看了. 如果可以把这些视频下载下来,再传输到手机里不就可以离线看了吗? 接下来小编就演示下如何用 python 脚本来实
-
Python实现的飞速中文网小说下载脚本
1.JavaScript 加密什么的最讨厌了 :-( 1).eval 一个不依赖外部变量的函数立即调用很天真,看我 nodejs 来干掉你! 2).HTTP 请求的验证首先尝试 Referer,「小甜饼」没有想像中的那么重要. 3).curl 和各命令行工具处理起文本很顺手呢 4).但是 Python 也没多几行呢 2.Requests效率比 lxml 自己那个好太多 3.progressbar太先进了,我还是自个儿写吧-- 4.argparse写 Python 命令行程序必备啊- 5.stri
-
使用python采集脚本之家电子书资源并自动下载到本地的实例脚本
jb51上面的资源还比较全,就准备用python来实现自动采集信息,与下载啦. Python具有丰富和强大的库,使用urllib,re等就可以轻松开发出一个网络信息采集器! 下面,是我写的一个实例脚本,用来采集某技术网站的特定栏目的所有电子书资源,并下载到本地保存! 软件运行截图如下: 在脚本运行时期,不但会打印出信息到shell窗口,还会保存日志到txt文件,记录采集到的页面地址,书籍的名称,大小,服务器本地下载地址以及百度网盘的下载地址! 实例采集并下载我们的python栏目电子书资源: #
-
编写Python脚本批量下载DesktopNexus壁纸的教程
DesktopNexus 是我最喜爱的一个壁纸下载网站,上面有许多高质量的壁纸,几乎每天必上, 每月也必会坚持分享我这个月来收集的壁纸 但是 DesktopNexus 壁纸的下载很麻烦,而且因为壁纸会通过浏览器检测你当前分辨率来展示 合适你当前分辨率的壁纸,再加上是国外的网站,速度上很不乐观. 于是我写了个脚本,检测输入的页面中壁纸页面的链接,然后批量下载到指定文件夹中. 脚本使用 python 写的,所以需要机器上安装有 python . 用法: $ python desktop_nexus.
-
利用python写个下载teahour音频的小脚本
前言 最近空闲的时候看到了之前就关注的一个小站http://teahour.fm/,一直想把这里的音频都听一遍,可转眼间怎么着也有两年了,却什么也没做.有些伤感,于是就写了个脚本,抓了下音频的下载链接,等下载下来后一定要认真听听. 时间仓促,加调试也就那么十几分钟,脚本写的可能有些烂,大家可以留言指出. teahour.py #!/usr/bin/env python #coding: utf-8 import sys import requests from BeautifulSoup imp
-
写一个Python脚本下载哔哩哔哩舞蹈区的所有视频
一.抓取列表 首先点开舞蹈区先选择宅舞列表. 然后打开 F12 的控制面板,可以找到一条 https://api.bilibili.com/x/web-interface/newlist?rid=20&type=0&pn=1&ps=20&jsonp=jsonp&callback=jsonCallback_bili_57905715749828263 的 url,其中 rid 是 B 站的小分类,pn 是页数. 小编试着在浏览器将地址打开居然报了 404,可是在控制面
-
编写Python脚本来实现最简单的FTP下载的教程
访问FTP,无非两件事情:upload和download,最近在项目中需要从ftp下载大量文件,然后我就试着去实验自己的ftp操作类,如下(PS:此段有问题,别复制使用,可以参考去试验自己的ftp类!) import os from ftplib import FTP class FTPSync(): def __init__(self, host, usr, psw, log_file): self.host = host self.usr = usr self.psw = psw self.
-
Python实现多线程下载脚本的示例代码
0x01 分析 一个简单的多线程下载资源的Python脚本,主要实现部分包含两个类: Download类:包含download()和get_complete_rate()两种方法. download()方法种首先用 urlopen() 方法打开远程资源并通过 Content-Length获取资源的大小,然后计算每个线程应该下载网络资源的大小及对应部分吗,最后依次创建并启动多个线程来下载网络资源的指定部分. get_complete_rate()则是用来返回已下载的部分占全部资源大小的比例,用来回
-
Python脚本实现下载合并SAE日志
由于一些原因,需要SAE上站点的日志文件,从SAE上只能按天下载,下载下来手动处理比较蛋疼,尤其是数量很大的时候.还好SAE提供了API可以批量获得日志文件下载地址,刚刚写了python脚本自动下载和合并这些文件 调用API获得下载地址 文档位置在这里 设置自己的应用和下载参数 请求中需要设置的变量如下 复制代码 代码如下: api_url = 'http://dloadcenter.sae.sina.com.cn/interapi.php?' appname = 'xxxxx' from_da
-
Python百度指数获取脚本下载并保存
目录 前言 具体步骤 1. 获得cookie值 2. 使用我的代码 可视化 总结 前言 有时候大家需要知道一个关键词在互联网上的热度,想知道某个关键词的热度变化趋势.大家可能就是使用百度指数.微信指数之类的.非常好用,但是就是不能把数据下载保存下来,不方便我们后面进行操作. 我无意间看到别人提供的python脚本,可以对百度指数进行爬虫,于是我稍微修改了部分代码,做了一个可以直接返回pd.DataFrame的数据框的类:然后后面又加了一个小的可视化代码.这里和大家分享,只要使用这个脚本,就可以将
-
Python利用百度地图获取两地距离(附demo)
目录 百度地图开放平台 介绍需要用到的API 编写Python程序 1.获取对应地点的经纬度 2.获取两地之间的距离 3.合并函数调用 4.进行简单的功能测试 5.对Excel中的批量地点计算距离 百度地图开放平台 进入百度地图开放平台后,登陆用户,点击上方的控制台,按照提示进行激活后创建服务端类型的应用,应用名任意设置,其中白名单校验不做任何限制可以填写0.0.0.0/0.创建成功后画面应如下图所示,其中访问应用(AK)即途中红色方框圈起来的部分一定要注意不要随意泄漏,后面需要使用到,这是后面
-
Python 获取 datax 执行结果保存到数据库的方法
执行 datax 作业,创建执行文件,在 crontab 中每天1点(下面有关系)执行: 其中 job_start 及 job_finish 这两行记录是自己添加的,为了方便识别出哪张表. #!/bin/bash source /etc/profile user1="root" pass1="pwd" user2="root" pass2="pwd" job_path="/opt/datax/job/" j
-
python从ftp获取文件并下载到本地
最近有需求是,需要把对方提供的ftp地址上的图片获取到本地服务器,原先计划想着是用shell 操作,因为shell 本身也支持ftp的命令 在通过for 循环也能达到需求.但是后来想着 还是拿python 操作:于是在网上进行百度:无一例外 还是那么失望 无法直接抄来就用.于是在一个代码上进行修改.还是有点心东西学习到了:具体操作代码如下 只要修改ftp 账号密码 已经对应目录即可使用 在这需要注意一点的是os.path.join 的用法需要注意 #!/usr/bin/python # -*-
-
Python实现从百度API获取天气的方法
本文实例讲述了Python实现从百度API获取天气的方法.分享给大家供大家参考.具体实现方法如下: 复制代码 代码如下: __author__ = 'saint' import os import urllib.request import urllib.parse import json class weather(object): # 获取城市代码的uri code_uri = "http://apistore.baidu.com/microservice/cityinfo?
-
java获取百度网盘真实下载链接的方法
本文实例讲述了java获取百度网盘真实下载链接的方法.分享给大家供大家参考.具体如下: 目前还存在一个问题,同一ip在获取3次以后会出现验证码,会获取失败,感兴趣的朋友对此可以加以完善. 返回的List<Map<String, Object>> 中的map包含:fileName( 文件名),url(实链地址) HttpRequest.java如下: import java.io.BufferedReader; import java.io.IOException; import
-
利用Python+Excel制作一个视频下载器
说起Excel,那绝对是数据处理领域王者般的存在. 而作为网红语言Python,在数据领域也是被广泛使用. 其中Python的第三方库-xlwings,一个Python和Excel的交互工具,可以轻松地通过VBA来调用Python脚本,实现复杂的数据分析. 今天,小F就给大家介绍一个Python+Excel的项目[视频下载器]. 主要使用到下面这些Python库. import os import sys import ssl import ffmpeg import xlwings as xw
-
Python爬虫自动化获取华图和粉笔网站的错题(推荐)
这篇博客对于考公人或者其他用华图或者粉笔做题的人比较友好,通过输入网址可以自动化获取华图以及粉笔练习的错题. 粉笔网站 我们从做过的题目组中获取错题 打开某一次做题组,我们首先进行抓包看看数据在哪里 我们发现现在数据已经被隐藏,事实上数据在这两个包中: https://tiku.fenbi.com/api/xingce/questions https://tiku.fenbi.com/api/xingce/solutions 一个为题目的一个为解析的.此url要通过传入一个题目组参数才能获取到当
-
linux命令行操作百度云上传下载文件
目录 0. 背景 1. 安装 2. 登录百度云账号 3.上传文件 4.下载文件 5. 其它命令 6. python代码调用 0. 背景 很多时候我们只能通过ssh工具远程连接服务器,很多时候是没有图形界面的,可以使用ssh或者ftp上传下载大的文件,这时下载速率受限于服务器带宽.由于本人目前在家连接学校服务器是自己搭建frp做的内网穿透,这时上传下载的速率取决于frp服务器,由于带宽只有4M,上传下载20G以上的大文件,上传下载速度500KB左右,耗时又费力,从github上发现一个不错项目ht