Python Selenium实现无可视化界面过程解析
无可视化界面的意义
有时候我们爬取网页数据,并不希望看其中的过程,只想看到最后的数据结果就可以了,这时候,***面就很有必要了!
代码如下
from selenium import webdriver
from time import sleep
#实现无可视化界面
from selenium.webdriver.chrome.options import Options
#实现规避检测
from selenium.webdriver import ChromeOptions
#实现无可视化界面的操作
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
#实现规避检测
option = ChromeOptions()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
#如何实现让selenium规避被检测到的风险
bro = webdriver.Chrome(executable_path='./chromedriver',chrome_options=chrome_options,options=option)
#无可视化界面(无头浏览器) phantomJs
bro.get('https://www.baidu.com')
print(bro.page_source)
sleep(2)
bro.quit()
运行效果:
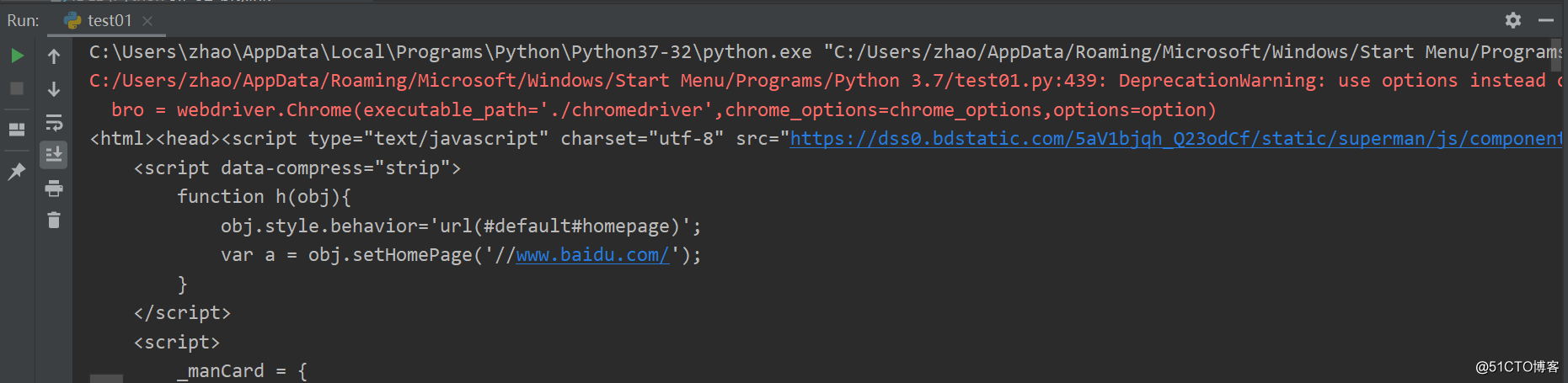
打印出网页代码,证明爬取网站信息成功
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

Python selenium如何打包静态网页并下载
需求:单纯的将page.source写入文件的方式,会导致一些图片无法显示,对于google浏览器,直接将页面打包下载成一个mhtml格式的文件,则可以进行离线下载.对应python selenium 微信公众号历史文章随手一点就返回首页?郁闷之下只好将他们都下载下来.:https://www.jb51.net/article/193111.htm 遇到的问题: 1.单纯使用webdriver.ActionChains无法完成下载动作,未能操作windows窗口. 2.没有找到相关能直接下载.m
-
Python selenium爬取微信公众号文章代码详解
参照资料:selenium webdriver添加cookie: https://www.jb51.net/article/193102.html 需求: 想阅读微信公众号历史文章,但是每次找回看得地方不方便. 思路: 1.使用selenium打开微信公众号历史文章,并滚动刷新到最底部,获取到所有历史文章urls. 2.对urls进行遍历访问,并进行下载到本地. 实现 1.打开微信客户端,点击某个微信公众号->进入公众号->打开历史文章链接(使用浏览器打开),并通过开发者工具获取到cookie
-
Python selenium爬虫实现定时任务过程解析
现在需要启动一个selenium的爬虫,使用火狐驱动+多线程,大家都明白的,现在电脑管家显示CPU占用率20%,启动selenium后不停的开启浏览器+多线程, 好,没过5分钟,CPU占用率直接拉到90%+,电脑卡到飞起,定时程序虽然还在运行,但是已经类似于待机状态, 是不是突然感觉到面对电脑卡死,第一反应:卧槽,这个lj电脑,这么程序都跑不起来,我还写这么多代码,*****!! 是吧,接下来上代码,具体功能,请自信查阅相关资料深造: from datetime import datetime
-
python + selenium 刷B站播放量的实例代码
B站UP主的主要收益来源(播放量获取的奖励.用户充电.广告等等) 首先做up主最直接的就是做视频,当你的粉丝过1000或者视频总播放超过10万时可以申请创造激励,申请创造激励之后,你的原创视频播放会给你带来收益,平均1000播放3元左右,根据你视频的质量上下浮动,如果你的视频被顶上首页那很自然的你的视频你会获得大量的流量,当然视频的点赞投币都会影响视频被顶上首页的概率. python selenium 模块 selenium模块是一个用于Web应用程序测试的工具.Selenium测试直接运行在浏
-
python+django+selenium搭建简易自动化测试
该平台会集成UI自动化及api自动化,里面也会涉及到一些简单的HTML等前端,当然都是很基础的东西.在以后的博客里,我会一点点的尽量写详细,帮助一些测试小白一起成长,当然我也是个小菜鸡. 第一章 django 搭建平台. 1.1搭建环境 Django 官方网站:https://www.djangoproject.com/ Python 官方仓库下载地址:https://pypi.python.org/pypi/Django 这里我们通过pip来安装django ,这里版本用1.10.3. Pyt
-
Python3爬虫中Selenium的用法详解
Selenium是一个自动化测试工具,利用它可以驱动浏览器执行特定的动作,如点击.下拉等操作,同时还可以获取浏览器当前呈现的页面的源代码,做到可见即可爬.对于一些JavaScript动态渲染的页面来说,此种抓取方式非常有效.本节中,就让我们来感受一下它的强大之处吧. 1. 准备工作 本节以Chrome为例来讲解Selenium的用法.在开始之前,请确保已经正确安装好了Chrome浏览器并配置好了ChromeDriver.另外,还需要正确安装好Python的Selenium库,详细的安装和配置过程
-
Python selenium键盘鼠标事件实现过程详解
引言 ----在实际的web测试工作中,需要配合键盘按键来操作,webdriver的 keys()类提供键盘上所有按键的操作,还可以模拟组合键Ctrl+a,Ctrl+v等. 举例: #cording=gbk import os import time from selenium import webdriver from selenium.webdriver.common.by import By #导入by方法 from selenium.webdriver.common.action_cha
-
Python中Selenium库使用教程详解
selenium介绍 selenium最初是一个自动化测试工具,而爬虫中使用它主要是为了解决requests无法直接执行JavaScript代码的问题 selenium本质是通过驱动浏览器,完全模拟浏览器的操作,比如跳转.输入.点击.下拉等,来拿到网页渲染之后的结果,可支持多种浏览器 中文参考文档 官网 环境安装 下载安装selenium pip install selenium -i https://mirrors.aliyun.com/pypi/simple/ 谷歌浏览器驱动程序下载地址:
-
Python Selenium实现无可视化界面过程解析
无可视化界面的意义 有时候我们爬取网页数据,并不希望看其中的过程,只想看到最后的数据结果就可以了,这时候,***面就很有必要了! 代码如下 from selenium import webdriver from time import sleep #实现无可视化界面 from selenium.webdriver.chrome.options import Options #实现规避检测 from selenium.webdriver import ChromeOptions #实现无可视化界面
-
Python散点图与折线图绘制过程解析
这篇文章主要介绍了Python散点图与折线图绘制过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 在数据分析的过程中,经常需要将数据可视化,目前常使用的:散点图 折线图 需要import的外部包 一个是绘图 一个是字体导入 import matplotlib.pyplot as plt from matplotlib.font_manager import FontProperties 在数据处理前需要获取数据,从TXT XML csv
-
Python socket模块ftp传输文件过程解析
这篇文章主要介绍了Python socket模块ftp传输文件过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 使用环境:python3,window环境,需要在头部声明# -*- coding:utf-8 -*- 实现功能: 将sever端所处文件夹的文件,传输到client端所处的文件夹中. 并且通过md5检测是否出错. 客户端命令的形式是: get 文件名 client处的新文件是 文件名.new ftp_sever.py impo
-
Python使用微信接入图灵机器人过程解析
这篇文章主要介绍了Python使用微信接入图灵机器人过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 1.wxpy库介绍 wxpy 在 itchat 的基础上,通过大量接口优化提升了模块的易用性,并进行丰富的功能扩展. 文档地址: https://wxpy.readthedocs.io 从 PYPI 官方源下载安装 pip install -U wxpy 2.图灵机器人 首先注册一个账号:http://www.turingapi.com/
-
python redis 批量设置过期key过程解析
这篇文章主要介绍了python redis 批量设置过期key过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 在使用 Redis.Codis 时,我们经常需要做一些批量操作,通过连接数据库批量对 key 进行操作: 关于未过期: 1.常有大批量的key未设置过期,导致内存一直暴增 2.rd需求 扫描出这些key,rd自己处理过期(一般dba不介入数据的修改) 3.dba 批量设置过期时间,(一般测试可以直接批量设置,线上谨慎操作) 通过
-
python Opencv计算图像相似度过程解析
这篇文章主要介绍了python Opencv计算图像相似度过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 一.相关概念 一般我们人区分谁是谁,给物品分类,都是通过各种特征去辨别的,比如黑长直.大白腿.樱桃唇.瓜子脸.王麻子脸上有麻子,隔壁老王和儿子很像,但是儿子下巴涨了一颗痣和他妈一模一样,让你确定这是你儿子. 还有其他物品.什么桌子带腿.镜子反光能在里面倒影出东西,各种各样的特征,我们通过学习.归纳,自然而然能够很快识别分类出新物品.
-
python爬虫模拟浏览器访问-User-Agent过程解析
这篇文章主要介绍了python爬虫模拟浏览器访问-User-Agent过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 模拟浏览器访问-User-Agent: import urllib2 #User-Agent 模拟浏览器访问 headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, li
-
python实现百度OCR图片识别过程解析
这篇文章主要介绍了python实现百度OCR图片识别过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 代码如下 import base64 import requests class CodeDemo: def __init__(self,AK,SK,code_url,img_path): self.AK=AK self.SK=SK self.code_url=code_url self.img_path=img_path self.ac
-
Python自定义计算时间过滤器实现过程解析
这篇文章主要介绍了Python自定义计算时间过滤器实现过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 在写自定义的过滤器时,因为django.template.Library.filter()本身可以作为一个装饰器,所以可以使用: register = django.template.Library() @register.filter 代替 register.filter("过滤器名","函数名") 如果
-
Python unittest工作原理和使用过程解析
这篇文章主要介绍了Python unittest工作原理和使用过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 1.unittest的工作原理: TestCase:一个testcase就是一条测试用例. setUp:测试环境的准备 tearDown:测试环境的还原 run:测试执行 TestSuite:测试套件或集合,多个测试用例的集合就是1个suite,一个suite可以包含多条测试用例,测试套件suite里面也可以嵌套测试套件suit