R语言ARMA模型的参数选择说明
AR(p)模型与MA(q)实际上是ARMA(p,q)模型的特例。它们都统称为ARMA模型,而ARMA(p,q)模型的统计性质也是AR(p)与MA(q)模型的统计性质的有机组合。
平稳系列建模
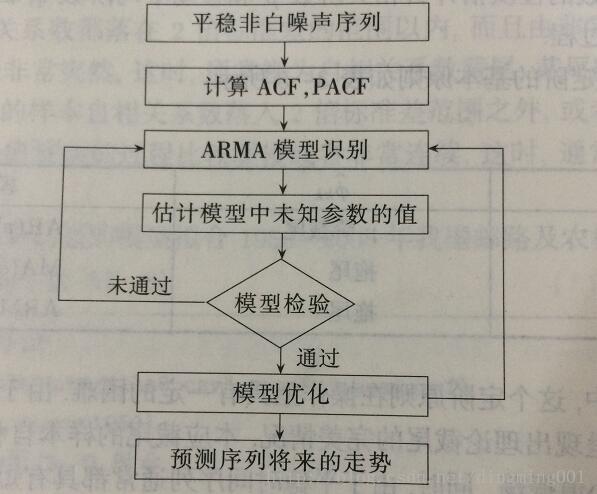
假如某个观察值序列通过序列预处理可以判定为平稳非白噪声序列,就可以利用ARMA模型对序列建模。
1.求出该观察值序列的样本自相关系数(ACF)与偏相关系数(PACF的值。
2.根据根样本自相关系数和偏自相关系数的性质,选择阶数适当的ARMA(p,q)模型进行拟合。
3.估计模型中未知参数的值
4.检验模型的有效性。如果拟合模型未通过检验,回到步骤(2),重新选择模型拟合。
5.模型优化。如果拟合模型通过检验,仍然回到步骤(2),充分考虑各种可能,建立多个拟合模型,从所有通过检验的拟合的模型中选择最优模型。
6.利用拟合模型,预测序列将来的走势。
选择合适的模型拟合1950-2008年我国邮路及农村投递线路每年新增里程数序列:
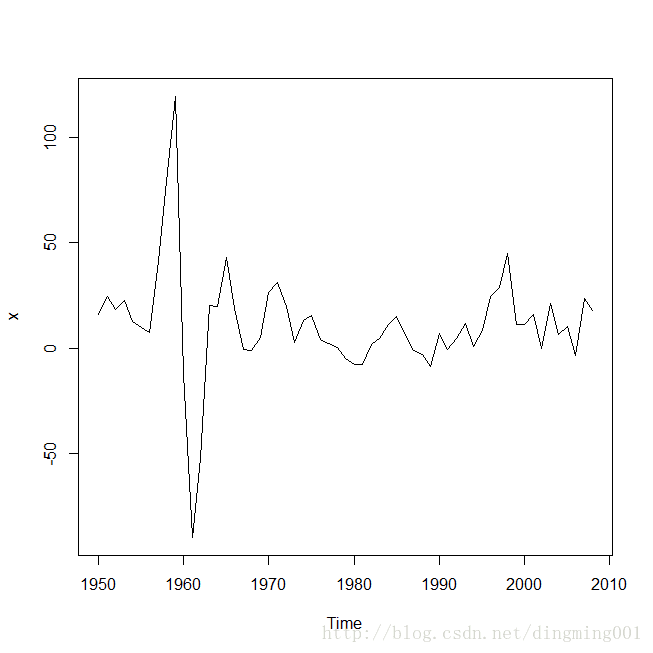
白噪声检验:
for(i in 1:2) print(Box.test(x,type = "Ljung-Box",lag=6*i))
Box-Ljung test
data: x
X-squared = 37.754, df = 6, p-value = 1.255e-06
Box-Ljung test
data: x
X-squared = 44.62, df = 12, p-value = 1.197e-05
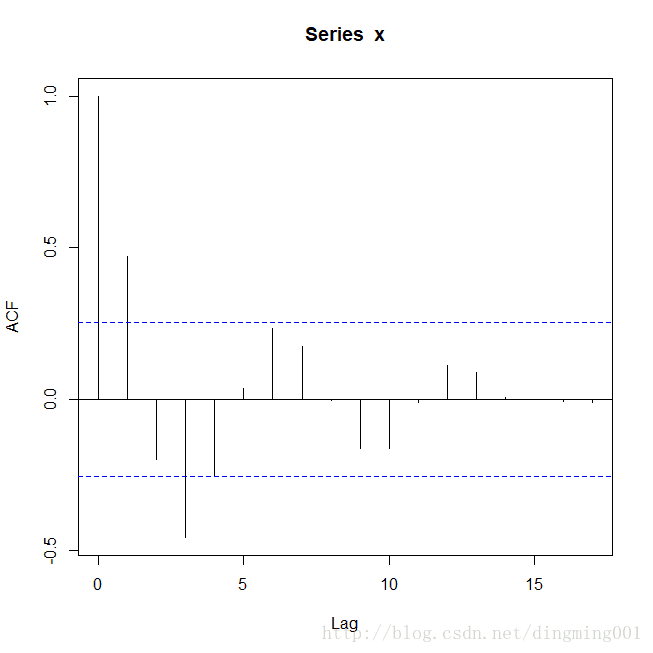
绘制自相关图和偏自相关图
acf(x) pacf(x)
补充:关于ARMA模型的R语言实现
新手一枚,和大家一起学习R,以后基本每周都会更新1到2篇关于数据预测处理的模型和方法,希望和大家一起学习,一起成长。
本周首先更新的是用R来实现ARMA模型。
时间序列的模型,基本上都要建立在平稳的序列上,这里我们将来了解下ARMA模型,以及其实现的R代码。
ARMA(p,q)模型,全称移动平均自回归模型,它是由自回归(AR)部分和移动平均(MA)部分组成的,所以称之为ARMA模型。进行ARMA模型的话,要求时间序列一定要是平稳的才行,否则建模无效。
1.ARMA模型具有如下形式:
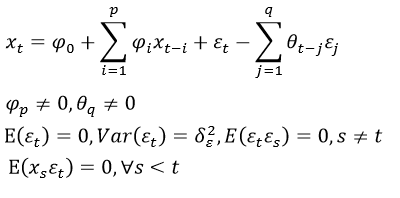
2.ARMA模型建模步骤
(1)画出时序图,求出样本的相关系数,偏自相关系数值
(2)根据样本的相关系数和偏自相关系数,选择适当的阶数,由于这具有一定的主观性,所以这里我们选用的是最小AIC准则来定阶
(3)估计模型中的参数值
(4)检验模型的有效性,一般分为残差的白噪声检验和参数的显著性检验。
(5)利用模型进行预测。
3.建模
我们利用美国科罗拉多州某一加油站连续57天的OVERSHOOT序列,来进行本次建模。
(1)首先
读入数据,画出其时序图,检验其平稳性。
library(zoo)
library(tseries)
library(forecast)
overshort=read.table("C:/Users/MrDavid/data_TS/A1.9.csv",sep=",",header=T)
overshort=ts(overshort)
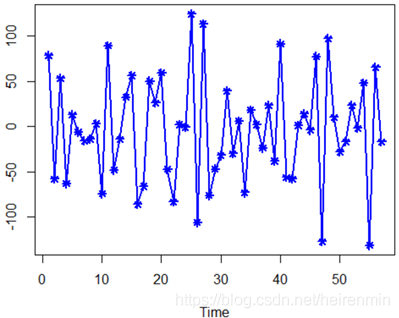
plot(overshort,col=4,lwd=2,pch=8,type="o")
结果如下:
进行一次单位根检验,测试该序列的平稳性:
代码:adf.test(overshort)
结果如下图所示:

由以上单位根检验,我们看到P值为0.01小于0.05,所以该序列平稳
(2)对于平稳的时间序列
我们需要进行白噪声检验,因为白噪声是纯随机序列,对白噪声序列进行建模毫无意义。
for(i in 1:3) print(Box.test(overshort,type="Ljung-Box",lag=6*i))
结果如下图:

可以看出,该序列非白噪声序列,可以进行建模。
(3)模型的拟合
模型的拟合,我们可以画出自相关图,和偏自相关图,对时间序列进行定阶
acf(overshort,col=4,lwd=2) pacf(overshort,col=4,lwd=2)
结果如下:
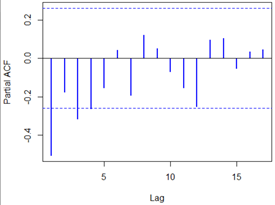
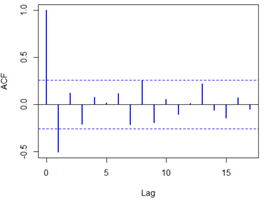
自相关图除了显示1阶延迟在两倍标准差之外,其他自相关系数都在两倍标准差之内,可以认为该序列自相关系数1阶截尾,骗子相关系数显示出非截尾性质,可以拟合模型为ARMA(0,1),即MA(1)模型。
该模型除了自相关,偏自相关系数定阶以外,还可以根据自动定阶函数auto.arima来对该序列进行定阶结果如下:
auto.arima(overshort)

也显示出该序列的模型为MA(1)模型
接下来进行建模,找出模型的系数:
a=arima(overshort,order=c(0,0,1),include.mean=T) a
得出结果:

该模型为:

对模型进行显著性检验:
for(i in 1:3) print(Box.test(a$residual,type="Ljung-Box",lag=6*i))

残差的白噪声检验,反映出,该残差是白噪声序列,所以残差白噪声检验通过。
对参数进行显著性检验:
t1=-0.8477/0.1206 pt(t1,df=12,lower.tail=T) t2=-4.7945/1.0252 pt(t2,df=12,lower.tail=T)

参数的显著性检验也通过,说明该序列建模成功。
(4)利用该模型预测未来5期值。
a.fore=forecast(a,h=5) a.fore

(5)画出预测图:
L1=a.fore$fitted-1.96*sqrt(a$sigma2) U1=a.fore$fitted+1.96*sqrt(a$sigma2) L2=ts(a.fore$lower[,2]) U2=ts(a.fore$upper[,2]) c1=min(overshort,L1,L2) c2=max(overshort,L2,U2) plot(overshort,type="p",pch=8,ylim=c(c1,c2)) lines(a.fore$fitted,col=2,lwd=2) lines(a.fore$mean,col=2,lwd=2) lines(L1,col=4,lty=2) lines(U1,col=4,lty=2) lines(L2,col=4,lty=2) lines(U2,col=4,lty=2)
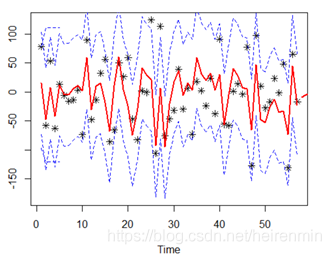
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-
R语言-生成频数表和列联表crosstable函数介绍
列联表crosstable 列联表不仅可以用来做简单的描述性统计,还可以在机器学习中用来比较识别正确率,FPR,TPR等等数据,以便我们比较不同的ML模型 or 调参. 2x2列联表一般长下面这样: Total Observations in Table: 143 | test_cancer$diagnosis lda.class | 0 | 1 | Row Total | -------------|-----------|-----------|-----------| 0 | 82 | 1
-
R语言中na.fail和na.omit的用法
实际工作中,数据集很少是完整的,许多情况下样本中都会包括若干缺失值NA,这在进行数据分析和挖掘时比较麻烦. R语言通过na.fail和na.omit可以很好地处理样本中的缺失值 1.na.fail(<向量a>): 如果向量a内包括至少1个NA,则返回错误:如果不包括任何NA,则返回原有向量a 2.na.omit(<向量a>): 返回删除NA后的向量a 3.attr( na.omit(<向量a>) ,"na.action"): 返回向量a中元素为NA的
-

R语言实现用cbind合并两列数据
我有两个数据文件,分别只有一列,这两列数据行数一行,我想把这两列合并到一个数据文件中,方便使用. 我的两个数据文件分别是1.txt,2.txt,保存后的文件名是3.txt. // 代码如下 gow1<-read.table("1.txt",header = FALSE) gow2<-read.table("2.txt",header = FALSE) View(gow1) View(gow2) gow<-cbind(gow1,gow2) View(
-
R语言中ifelse、which、%in%的用法详解
ifelse.which.%in%是R语言里极其重要的函数,以后会经常在别的程序中看到. ifelse ifelse是if条件判断语句的简写,它的用法如下: ifelse(test,yes,no) 参数 描述 test 一个可以判断逻辑表达式 yes 判断为 true 后返回的对象 no 判断为 flase 后返回的对象 举例: x = 5 ifelse(x,1,0) 如果x不等于0,就返回1,等于0就返回0. which which 返回条件为真的句柄,给正确的逻辑对象返回一个它的索引. wh
-
R语言-使用ifelse进行数据分组
数据分组,根据数据分析对象的特征,按照一定的数值指标,把数据分析对象划分为不同的区间部分来研究,以揭示内在的联系和规律性: 在R中,我们常用ifelse函数来进行数据的分组,跟excel中的if函数是同一种用法. ifelse(condition,TRUE,FALSE) > data <- read.table('1.csv', sep='|', header=TRUE); > > level <- ifelse( + data$cost<=20, "(0,2
-
解决R语言中install_github中无法安装遇到的问题
首先,让我们来进入常规步骤 我安装的是recharts包,正常的写法呢,就是以下这个样子: install.packages("devtools") #devtools::install_github("madlogos/recharts") 第一个问题: 然而对于今天的我来说,那就太天真了,首先踏入的第一个坑: 无法打开URL'http://yihui.name/xran/src/contrib/PACKAGES' Warning in install.packa
-
R语言中if(){}else{}语句和ifelse()函数的区别详解
首先看看定义: # if statement if(cond) expr if(cond) cons.expr else alt.expr # ifelse function ifelse(test, yes, no) 这两个函数(R语言中都是函数)相同的地方都是根据条件返回对应的值. 区别在于: if语句的条件是个TRUE/FALSE值,如果是个长度>1的逻辑向量,只判断第一个TRUE/FALSE值:而ifelse是长度任意的逻辑向量,返回根据逻辑向量对应对的yes/no值组合的新向量 ife
-
R语言 实现选取某一行的最大值
可以先自定义函数 也可以用的时候再定义. > mat <- matrix(c(1:3,7:9,4:6), byrow = T, nc = 3) > mat [,1] [,2] [,3] [1,] 1 2 3 [2,] 7 8 9 [3,] 4 5 6 > apply(mat, 2, function(x){order(x, decreasing=T)[1]}) # 查找每一列 [1] 2 2 2 > apply(mat, 1, function(x){order(x, dec
-
R语言ARMA模型的参数选择说明
AR(p)模型与MA(q)实际上是ARMA(p,q)模型的特例.它们都统称为ARMA模型,而ARMA(p,q)模型的统计性质也是AR(p)与MA(q)模型的统计性质的有机组合. 平稳系列建模 假如某个观察值序列通过序列预处理可以判定为平稳非白噪声序列,就可以利用ARMA模型对序列建模. 1.求出该观察值序列的样本自相关系数(ACF)与偏相关系数(PACF的值. 2.根据根样本自相关系数和偏自相关系数的性质,选择阶数适当的ARMA(p,q)模型进行拟合. 3.估计模型中未知参数的值 4.检验模型的
-
R语言 title()函数的参数用法说明
如下所示: title(main = NULL, sub = NULL, xlab = NULL, ylab = NULL, line = NA, outer = FALSE, ...) 参数 描述 main 主标题 sub 副标题 xlab x轴标签 ylab y轴标签 line 到轴线的行数距离 outer 一个逻辑值. 如果为TRUE,则标题位于图的外部边缘. 补充:R语言低级绘图函数-title title 函数用来在一张图表上添加标题 基本用法: main 表示主标题,通常位于图像的上
-
R语言关于生存分析知识点总结
生存分析处理预测特定事件将要发生的时间. 它也被称为故障时间分析或分析死亡时间. 例如,预测患有癌症的人将存活的天数或预测机械系统将失败的时间. 命名为survival的R语言包用于进行生存分析. 此包包含函数Surv(),它将输入数据作为R语言公式,并在选择的变量中创建一个生存对象用于分析. 然后我们使用函数survfit()创建一个分析图. 安装软件包 install.packages("survival") 语法 在R语言中创建生存分析的基本语法是 Surv(time,event
-
详解R语言实现前向逐步回归(前向选择模型)
目录 前向逐步回归原理 数据导入并分组 导入数据 特征与标签分开存放 前向逐步回归构建输出特征集合 从空开始一次创建属性列表 模型效果评估 前向逐步回归原理 前向逐步回归的过程是:遍历属性的一列子集,选择使模型效果最好的那一列属性.接着寻找与其组合效果最好的第二列属性,而不是遍历所有的两列子集.以此类推,每次遍历时,子集都包含上一次遍历得到的最优子集.这样,每次遍历都会选择一个新的属性添加到特征集合中,直至特征集合中特征个数不能再增加. 数据导入并分组 导入数据,将数据集抽取70%作为训练集,剩
-
详解R语言中的多项式回归、局部回归、核平滑和平滑样条回归模型
在标准线性模型中,我们假设 .当线性假设无法满足时,可以考虑使用其他方法. 多项式回归 扩展可能是假设某些多项式函数, 同样,在标准线性模型方法(使用GLM的条件正态分布)中,参数 可以使用最小二乘法获得,其中 在 . 即使此多项式模型不是真正的多项式模型,也可能仍然是一个很好的近似值 .实际上,根据 Stone-Weierstrass定理,如果 在某个区间上是连续的,则有一个统一的近似值 ,通过多项式函数. 仅作说明,请考虑以下数据集 db = data.frame(x=xr,y=y
-
R语言实现广义线性回归模型
目录 1 与广义线性模型有关的R函数 2 正态分布族 3 二项分布族 例 R. Norell实验 广义线性模型(GLM)是常见正态线性模型的直接推广,它可以适用于连续数据和离散数据,特别是后者,如属性数据.计数数据.这在应用上,尤其是生物.医学.经济和社会数据的统计分析上,有着重要意义. 对于广义线性模型应有一下三个概念: 第一是线性自变量,它表明第i个响应变量的期望值E(yi)只能通过线性自变量βTxi而依赖于xi,其中如通常一样,β是未知参数的(p+1)x1向量,可能包含截距. 第二是连续
-
R语言数据可视化学习之图形参数修改详解
1.图形参数的修改par()函数 我们可以通过使用par()函数来修改图形的参数,其调用格式为par(optionname=name, optionname=name,-).当par()不加参数时,返回当前图形参数设置的列表:par(no.readonly=T)将生成一个可以修改当前参数设置的列表.注意以这种方式修改参数设置,除非参数再次被修改,否则一直执行此参数设置. 例如现在想画出mtcars数据集中mpg的折线图,并用虚线代替实线,并将两幅图排列在同一幅图里,代码及图形如下: > opar
-
详解R语言plot函数参数合集
最近用R语言画图,plot 函数是用的最多的函数,而他的参数非常繁多,由此总结一下,以供后续方便查阅. plot(x, y = NULL, type = "p", xlim = NULL, ylim = NULL, log = "", main = NULL, sub = NULL, xlab = NULL, ylab = NULL, ann = par("ann"), axes = TRUE, frame.plot = axes, panel.
-
R语言利用loess如何去除某个变量对数据的影响详解
R语言介绍 R语言是用于统计分析,图形表示和报告的编程语言和软件环境. R语言由Ross Ihaka和Robert Gentleman在新西兰奥克兰大学创建,目前由R语言开发核心团队开发. R语言的核心是解释计算机语言,其允许分支和循环以及使用函数的模块化编程. R语言允许与以C,C ++,.Net,Python或FORTRAN语言编写的过程集成以提高效率. R语言在GNU通用公共许可证下免费提供,并为各种操作系统(如Linux,Windows和Mac)提供预编译的二进制版本. R是一个在GNU
-
R语言是什么 R语言简介
R是由Ross Ihaka和Robert Gentleman在1993年开发的一种编程语言,R拥有广泛的统计和图形方法目录.它包括机器学习算法.线性回归.时间序列.统计推理等.大多数R库都是用R编写的,但是对于繁重的计算任务,最好使用C.c++和Fortran代码. R不仅在学术界很受欢迎,很多大公司也使用R编程语言,包括Uber.谷歌.Airbnb.Facebook等.用R进行数据分析需要一系列步骤:编程.转换.发现.建模和交流结果 R 语言是为数学研究工作者设计的一种数学编程语言,主要用于统