在pytorch中计算准确率,召回率和F1值的操作
看代码吧~
predict = output.argmax(dim = 1)
confusion_matrix =torch.zeros(2,2)
for t, p in zip(predict.view(-1), target.view(-1)):
confusion_matrix[t.long(), p.long()] += 1
a_p =(confusion_matrix.diag() / confusion_matrix.sum(1))[0]
b_p = (confusion_matrix.diag() / confusion_matrix.sum(1))[1]
a_r =(confusion_matrix.diag() / confusion_matrix.sum(0))[0]
b_r = (confusion_matrix.diag() / confusion_matrix.sum(0))[1]
补充:pytorch 查全率 recall 查准率 precision F1调和平均 准确率 accuracy
看代码吧~
def eval():
net.eval()
test_loss = 0
correct = 0
total = 0
classnum = 9
target_num = torch.zeros((1,classnum))
predict_num = torch.zeros((1,classnum))
acc_num = torch.zeros((1,classnum))
for batch_idx, (inputs, targets) in enumerate(testloader):
if use_cuda:
inputs, targets = inputs.cuda(), targets.cuda()
inputs, targets = Variable(inputs, volatile=True), Variable(targets)
outputs = net(inputs)
loss = criterion(outputs, targets)
# loss is variable , if add it(+=loss) directly, there will be a bigger ang bigger graph.
test_loss += loss.data[0]
_, predicted = torch.max(outputs.data, 1)
total += targets.size(0)
correct += predicted.eq(targets.data).cpu().sum()
pre_mask = torch.zeros(outputs.size()).scatter_(1, predicted.cpu().view(-1, 1), 1.)
predict_num += pre_mask.sum(0)
tar_mask = torch.zeros(outputs.size()).scatter_(1, targets.data.cpu().view(-1, 1), 1.)
target_num += tar_mask.sum(0)
acc_mask = pre_mask*tar_mask
acc_num += acc_mask.sum(0)
recall = acc_num/target_num
precision = acc_num/predict_num
F1 = 2*recall*precision/(recall+precision)
accuracy = acc_num.sum(1)/target_num.sum(1)
#精度调整
recall = (recall.numpy()[0]*100).round(3)
precision = (precision.numpy()[0]*100).round(3)
F1 = (F1.numpy()[0]*100).round(3)
accuracy = (accuracy.numpy()[0]*100).round(3)
# 打印格式方便复制
print('recall'," ".join('%s' % id for id in recall))
print('precision'," ".join('%s' % id for id in precision))
print('F1'," ".join('%s' % id for id in F1))
print('accuracy',accuracy)
补充:Python scikit-learn,分类模型的评估,精确率和召回率,classification_report
分类模型的评估标准一般最常见使用的是准确率(estimator.score()),即预测结果正确的百分比。
混淆矩阵:

准确率是相对所有分类结果;精确率、召回率、F1-score是相对于某一个分类的预测评估标准。
精确率(Precision):预测结果为正例样本中真实为正例的比例(查的准)()

召回率(Recall):真实为正例的样本中预测结果为正例的比例(查的全)()

分类的其他评估标准:F1-score,反映了模型的稳健型
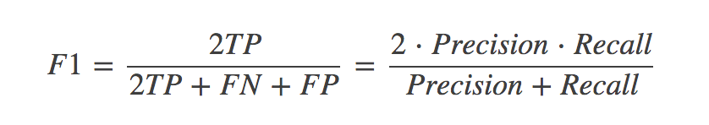

demo.py(分类评估,精确率、召回率、F1-score,classification_report):
from sklearn.datasets import fetch_20newsgroups
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import classification_report
# 加载数据集 从scikit-learn官网下载新闻数据集(共20个类别)
news = fetch_20newsgroups(subset='all') # all表示下载训练集和测试集
# 进行数据分割 (划分训练集和测试集)
x_train, x_test, y_train, y_test = train_test_split(news.data, news.target, test_size=0.25)
# 对数据集进行特征抽取 (进行特征提取,将新闻文档转化成特征词重要性的数字矩阵)
tf = TfidfVectorizer() # tf-idf表示特征词的重要性
# 以训练集数据统计特征词的重要性 (从训练集数据中提取特征词)
x_train = tf.fit_transform(x_train)
print(tf.get_feature_names()) # ["condensed", "condescend", ...]
x_test = tf.transform(x_test) # 不需要重新fit()数据,直接按照训练集提取的特征词进行重要性统计。
# 进行朴素贝叶斯算法的预测
mlt = MultinomialNB(alpha=1.0) # alpha表示拉普拉斯平滑系数,默认1
print(x_train.toarray()) # toarray() 将稀疏矩阵以稠密矩阵的形式显示。
'''
[[ 0. 0. 0. ..., 0.04234873 0. 0. ]
[ 0. 0. 0. ..., 0. 0. 0. ]
...,
[ 0. 0.03934786 0. ..., 0. 0. 0. ]
'''
mlt.fit(x_train, y_train) # 填充训练集数据
# 预测类别
y_predict = mlt.predict(x_test)
print("预测的文章类别为:", y_predict) # [4 18 8 ..., 15 15 4]
# 准确率
print("准确率为:", mlt.score(x_test, y_test)) # 0.853565365025
print("每个类别的精确率和召回率:", classification_report(y_test, y_predict, target_names=news.target_names))
'''
precision recall f1-score support
alt.atheism 0.86 0.66 0.75 207
comp.graphics 0.85 0.75 0.80 238
sport.baseball 0.96 0.94 0.95 253
...,
'''
召回率的意义(应用场景):产品的不合格率(不想漏掉任何一个不合格的产品,查全);癌症预测(不想漏掉任何一个癌症患者)
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
Pytorch 计算误判率,计算准确率,计算召回率的例子
无论是官方文档还是各位大神的论文或搭建的网络很多都是计算准确率,很少有计算误判率, 下面就说说怎么计算准确率以及误判率.召回率等指标 1.计算正确率 获取每批次的预判正确个数 train_correct = (pred == batch_y.squeeze(1)).sum() 该语句的意思是 预测的标签与实际标签相等的总数 获取训练集总的预判正确个数 train_acc += train_correct.data[0] #用来计算正确率 准确率 : train_acc / (len(train_
-
Pytorch 实现计算分类器准确率(总分类及子分类)
分类器平均准确率计算: correct = torch.zeros(1).squeeze().cuda() total = torch.zeros(1).squeeze().cuda() for i, (images, labels) in enumerate(train_loader): images = Variable(images.cuda()) labels = Variable(labels.cuda()) output = model(images) prediction = to
-
pytorch绘制并显示loss曲线和acc曲线,LeNet5识别图像准确率
我用的是Anaconda3 ,用spyder编写pytorch的代码,在Anaconda3中新建了一个pytorch的虚拟环境(虚拟环境的名字就叫pytorch). 以下内容仅供参考哦~~ 1.首先打开Anaconda Prompt,然后输入activate pytorch,进入pytorch. 2.输入pip install tensorboardX,安装完成后,输入python,用from tensorboardX import SummaryWriter检验是否安装成功.如下图所示: 3.
-

在pytorch中计算准确率,召回率和F1值的操作
看代码吧~ predict = output.argmax(dim = 1) confusion_matrix =torch.zeros(2,2) for t, p in zip(predict.view(-1), target.view(-1)): confusion_matrix[t.long(), p.long()] += 1 a_p =(confusion_matrix.diag() / confusion_matrix.sum(1))[0] b_p = (confusion_matri
-
在pytorch 中计算精度、回归率、F1 score等指标的实例
pytorch中训练完网络后,需要对学习的结果进行测试.官网上例程用的方法统统都是正确率,使用的是torch.eq()这个函数. 但是为了更精细的评价结果,我们还需要计算其他各个指标.在把官网API翻了一遍之后发现并没有用于计算TP,TN,FP,FN的函数... 在动了无数歪脑筋之后,心想pytorch完全支持numpy,那能不能直接进行判断,试了一下果然可以,上代码: # TP predict 和 label 同时为1 TP += ((pred_choice == 1) & (target.d
-
在Pytorch中计算自己模型的FLOPs方式
https://github.com/Lyken17/pytorch-OpCounter 安装方法很简单: pip install thop 基本用法: from torchvision.models import resnet50from thop import profile model = resnet50() flops, params = profile(model, input_size=(1, 3, 224,224)) 对自己的module进行特别的计算: class YourMo
-
在Pytorch中计算卷积方法的区别详解(conv2d的区别)
在二维矩阵间的运算: class torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True) 对由多个特征平面组成的输入信号进行2D的卷积操作.详解 torch.nn.functional.conv2d(input, weight, bias=None, stride=1, padding=0, dilation=1, groups=1)
-
Pytorch中accuracy和loss的计算知识点总结
这几天关于accuracy和loss的计算有一些疑惑,原来是自己还没有弄清楚. 给出实例 def train(train_loader, model, criteon, optimizer, epoch): train_loss = 0 train_acc = 0 num_correct= 0 for step, (x,y) in enumerate(train_loader): # x: [b, 3, 224, 224], y: [b] x, y = x.to(device), y.to(de
-
pytorch中的卷积和池化计算方式详解
TensorFlow里面的padding只有两个选项也就是valid和same pytorch里面的padding么有这两个选项,它是数字0,1,2,3等等,默认是0 所以输出的h和w的计算方式也是稍微有一点点不同的:tf中的输出大小是和原来的大小成倍数关系,不能任意的输出大小:而nn输出大小可以通过padding进行改变 nn里面的卷积操作或者是池化操作的H和W部分都是一样的计算公式:H和W的计算 class torch.nn.MaxPool2d(kernel_size, stride=Non
-
解决pytorch中的kl divergence计算问题
偶然从pytorch讨论论坛中看到的一个问题,KL divergence different results from tf,kl divergence 在TensorFlow中和pytorch中计算结果不同,平时没有注意到,记录下 一篇关于KL散度.JS散度以及交叉熵对比的文章 kl divergence 介绍 KL散度( Kullback–Leibler divergence),又称相对熵,是描述两个概率分布 P 和 Q 差异的一种方法.计算公式: 可以发现,P 和 Q 中元素的个数不用相等
-
浅谈PyTorch中in-place operation的含义
in-place operation在pytorch中是指改变一个tensor的值的时候,不经过复制操作,而是直接在原来的内存上改变它的值.可以把它成为原地操作符. 在pytorch中经常加后缀"_"来代表原地in-place operation,比如说.add_() 或者.scatter().python里面的+=,*=也是in-place operation. 下面是正常的加操作,执行结束加操作之后x的值没有发生变化: import torch x=torch.rand(2) #t
-
Pytorch中求模型准确率的两种方法小结
方法一:直接在epoch过程中求取准确率 简介:此段代码是LeNet5中截取的. def train_model(model,train_loader): optimizer = torch.optim.Adam(model.parameters()) loss_func = nn.CrossEntropyLoss() EPOCHS = 5 for epoch in range(EPOCHS): correct = 0 for batch_idx,(X_batch,y_batch) in enu