不需要用到正则的Python文本解析库parse
目录
- 1. 真实案例
- 2. parse 的结果
- 3. 重复利用 pattern
- 4. 类型转化
- 5. 提取时去除空格
- 6. 大小写敏感开关
- 7. 匹配字符数
- 8. 三个重要属性
- 9. 自定义类型的转换
- 10 总结一下
从一段指定的字符串中,取得期望的数据,正常人都会想到正则表达式吧?
写过正则表达式的人都知道,正则表达式入门不难,写起来也容易。
但是正则表达式几乎没有可读性可言,维护起来,真的会让人抓狂,别以为这段正则是你写的就可以驾驭它,过个一个月你可能就不认识它了。
完全可以说,天下苦正则久矣。
1. 真实案例
拿一个最近使用 parse 的真实案例来举例说明。
下面是 ovs 一个条流表,现在我需要收集提取一个虚拟机(网口)里有多少流量、多少包流经了这条流表。也就是每个 in_port 对应的 n_bytes、n_packets 的值 。
cookie=0x9816da8e872d717d, duration=298506.364s, table=0, n_packets=480, n_bytes=20160, priority=10,ip,in_port="tapbbdf080b-c2" actions=NORMAL
如果是你,你会怎么做呢?
先以逗号分隔开来,再以等号分隔取出值来?
你不防可以尝试一下,写出来的代码应该和我想象的一样,没有一丝美感而言。
我来给你展示一下,我是怎么做的?
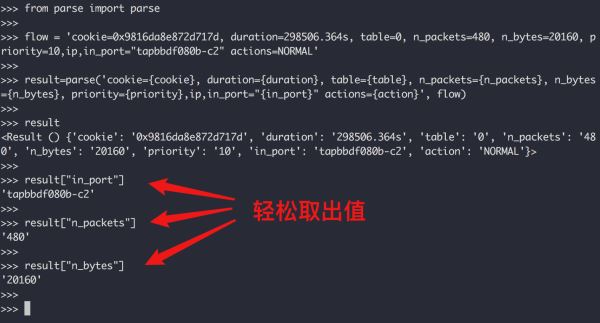
可以看到,我使用了一个叫做 parse 的第三方包,是需要自行安装的
$ python -m pip install parse
从上面这个案例中,你应该能感受到 parse 对于解析规范的字符串,是非常强大的。
2. parse 的结果
parse 的结果只有两种结果:
1.没有匹配上,parse 的值为None
>>> parse("halo", "hello") is None
True
>>>
如果匹配上,parse 的值则 为 Result 实例
>>> parse("hello", "hello world")
>>> parse("hello", "hello")
<Result () {}>
>>>
如果你编写的解析规则,没有为字段定义字段名,也就是匿名字段, Result 将是一个 类似 list 的实例,演示如下:
>>> profile = parse("I am {}, {} years old, {}", "I am Jack, 27 years old, male")
>>> profile
<Result ('Jack', '27', 'male') {}>
>>> profile[0]
'Jack'
>>> profile[1]
'27'
>>> profile[2]
'male'
而如果你编写的解析规则,为字段定义了字段名, Result 将是一个 类似 字典 的实例,演示如下:
>>> profile = parse("I am {name}, {age} years old, {gender}", "I am Jack, 27 years old, male")
>>> profile
<Result () {'gender': 'male', 'age': '27', 'name': 'Jack'}>
>>> profile['name']
'Jack'
>>> profile['age']
'27'
>>> profile['gender']
'male'
3. 重复利用 pattern
和使用 re 一样,parse 同样支持 pattern 复用。
>>> from parse import compile
>>>
>>> pattern = compile("I am {}, {} years old, {}")
>>> pattern.parse("I am Jack, 27 years old, male")
<Result ('Jack', '27', 'male') {}>
>>>
>>> pattern.parse("I am Tom, 26 years old, male")
<Result ('Tom', '26', 'male') {}>
4. 类型转化
从上面的例子中,你应该能注意到,parse 在获取年龄的时候,变成了一个"27" ,这是一个字符串,有没有一种办法,可以在提取的时候就按照我们的类型进行转换呢?
你可以这样写。
>>> from parse import parse
>>> profile = parse("I am {name}, {age:d} years old, {gender}", "I am Jack, 27 years old, male")
>>> profile
<Result () {'gender': 'male', 'age': 27, 'name': 'Jack'}>
>>> type(profile["age"])
<type 'int'>
除了将其转为 整型,还有其他格式吗?
内置的格式还有很多,比如
匹配时间
>>> parse('Meet at {:tg}', 'Meet at 1/2/2011 11:00 PM')
<Result (datetime.datetime(2011, 2, 1, 23, 0),) {}>
更多类型请参考官方文档:
| Type | Characters Matched | Output |
|---|---|---|
| l | Letters (ASCII) | str |
| w | Letters, numbers and underscore | str |
| W | Not letters, numbers and underscore | str |
| s | Whitespace | str |
| S | Non-whitespace | str |
| d | Digits (effectively integer numbers) | int |
| D | Non-digit | str |
| n | Numbers with thousands separators (, or .) | int |
| % | Percentage (converted to value/100.0) | float |
| f | Fixed-point numbers | float |
| F | Decimal numbers | Decimal |
| e | Floating-point numbers with exponent e.g. 1.1e-10, NAN (all case insensitive) | float |
| g | General number format (either d, f or e) | float |
| b | Binary numbers | int |
| o | Octal numbers | int |
| x | Hexadecimal numbers (lower and upper case) | int |
| ti | ISO 8601 format date/time e.g. 1972-01-20T10:21:36Z (“T” and “Z” optional) | datetime |
| te | RFC2822 e-mail format date/time e.g. Mon, 20 Jan 1972 10:21:36 +1000 | datetime |
| tg | Global (day/month) format date/time e.g. 20/1/1972 10:21:36 AM +1:00 | datetime |
| ta | US (month/day) format date/time e.g. 1/20/1972 10:21:36 PM +10:30 | datetime |
| tc | ctime() format date/time e.g. Sun Sep 16 01:03:52 1973 | datetime |
| th | HTTP log format date/time e.g. 21/Nov/2011:00:07:11 +0000 | datetime |
| ts | Linux system log format date/time e.g. Nov 9 03:37:44 | datetime |
| tt | Time e.g. 10:21:36 PM -5:30 | time |
5. 提取时去除空格
去除两边空格
>>> parse('hello {} , hello python', 'hello world , hello python')
<Result (' world ',) {}>
>>>
>>>
>>> parse('hello {:^} , hello python', 'hello world , hello python')
<Result ('world',) {}>
去除左边空格
>>> parse('hello {:>} , hello python', 'hello world , hello python')
<Result ('world ',) {}>
去除右边空格
>>> parse('hello {:<} , hello python', 'hello world , hello python')
<Result (' world',) {}>
6. 大小写敏感开关
Parse 默认是大小写不敏感的,你写 hello 和 HELLO 是一样的。
如果你需要区分大小写,那可以加个参数,演示如下:
>>> parse('SPAM', 'spam')
<Result () {}>
>>> parse('SPAM', 'spam') is None
False
>>> parse('SPAM', 'spam', case_sensitive=True) is None
True
7. 匹配字符数
精确匹配:指定最大字符数
>>> parse('{:.2}{:.2}', 'hello') # 字符数不符
>>>
>>> parse('{:.2}{:.2}', 'hell') # 字符数相符
<Result ('he', 'll') {}>
模糊匹配:指定最小字符数
>>> parse('{:.2}{:2}', 'hello')
<Result ('h', 'ello') {}>
>>>
>>> parse('{:2}{:2}', 'hello')
<Result ('he', 'llo') {}>
若要在精准/模糊匹配的模式下,再进行格式转换,可以这样写
>>> parse('{:2}{:2}', '1024')
<Result ('10', '24') {}>
>>>
>>>
>>> parse('{:2d}{:2d}', '1024')
<Result (10, 24) {}>
8. 三个重要属性
Parse 里有三个非常重要的属性
fixed:利用位置提取的匿名字段的元组named:存放有命名的字段的字典spans:存放匹配到字段的位置
下面这段代码,带你了解他们之间有什么不同
>>> profile = parse("I am {name}, {age:d} years old, {}", "I am Jack, 27 years old, male")
>>> profile.fixed
('male',)
>>> profile.named
{'age': 27, 'name': 'Jack'}
>>> profile.spans
{0: (25, 29), 'age': (11, 13), 'name': (5, 9)}
>>>
9. 自定义类型的转换
匹配到的字符串,会做为参数传入对应的函数
比如我们之前讲过的,将字符串转整型
>>> parse("I am {:d}", "I am 27")
<Result (27,) {}>
>>> type(_[0])
<type 'int'>
>>>
其等价于
>>> def myint(string):
... return int(string)
...
>>>
>>>
>>> parse("I am {:myint}", "I am 27", dict(myint=myint))
<Result (27,) {}>
>>> type(_[0])
<type 'int'>
>>>
利用它,我们可以定制很多的功能,比如我想把匹配的字符串弄成全大写
>>> def shouty(string):
... return string.upper()
...
>>> parse('{:shouty} world', 'hello world', dict(shouty=shouty))
<Result ('HELLO',) {}>
>>>
10 总结一下
parse 库在字符串解析处理场景中提供的便利,肉眼可见,上手简单。
在一些简单的场景中,使用 parse 可比使用 re 去写正则开发效率不知道高几个 level,用它写出来的代码富有美感,可读性高,后期维护起代码来一点压力也没有,推荐你使用。
以上就是不需要用到正则的Python文本解析库parse的详细内容,更多关于Python文本解析库parse的资料请关注我们其它相关文章!
相关推荐
-
python爬虫入门教程--HTML文本的解析库BeautifulSoup(四)
前言 python爬虫系列文章的第3篇介绍了网络请求库神器 Requests ,请求把数据返回来之后就要提取目标数据,不同的网站返回的内容通常有多种不同的格式,一种是 json 格式,这类数据对开发者来说最友好.另一种 XML 格式的,还有一种最常见格式的是 HTML 文档,今天就来讲讲如何从 HTML 中提取出感兴趣的数据 自己写个 HTML 解析器来解析吗?还是用正则表达式?这些都不是最好的办法,好在,Python 社区在这方便早就有了很成熟的方案,BeautifulSoup 就是这一类问题
-
Python文本处理简单易懂方法解析
这篇文章主要介绍了Python文本处理简单易懂方法解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 自从认识了python这门语言,所有的事情好像变得容易了,作为小白,逗汁儿今天就为大家总结一下python的文本处理的一些小方法. 话不多说,代码撸起来. python大小写字符互换 在进行大小写互换时,常用到的方法有4种,upper().lower().capitalize() 和title(). str = "www.dataCASTLE.
-
Python 转换文本编码实现解析
最近在做周报的时候,需要把csv文本中的数据提取出来制作表格后生产图表. 在获取csv文本内容的时候,基本上都是用with open(filename, encoding ='UTF-8') as f:来打开csv文本,但是实际使用过程中发现有些csv文本并不是utf-8格式,从而导致程序在run的过程中报错,每次都需要手动去把该文本文件的编码格式修改成utf-8,再次来run该程序,所以想说:直接在程序中判断并修改文本编码. 基本思路:先查找该文本是否是utf-8的编码,如果不是则修改为utf
-
python3解析库lxml的安装与基本使用
前言 在爬虫的学习中,我们爬取网页信息之后就是对信息项匹配,这个时候一般是使用正则.但是在使用中发现正则写的不好的时候不能精确匹配(这其实是自己的问题!)所以就找啊找.想到了可以通过标签来进行精确匹配岂不是比正则要快.所以找到了lxml. lxml是python的一个解析库,支持HTML和XML的解析,支持XPath解析方式,而且解析效率非常高 XPath,全称XML Path Language,即XML路径语言,它是一门在XML文档中查找信息的语言,它最初是用来搜寻XML文档的,但是它同样适用
-

不需要用到正则的Python文本解析库parse
目录 1. 真实案例 2. parse 的结果 3. 重复利用 pattern 4. 类型转化 5. 提取时去除空格 6. 大小写敏感开关 7. 匹配字符数 8. 三个重要属性 9. 自定义类型的转换 10 总结一下 从一段指定的字符串中,取得期望的数据,正常人都会想到正则表达式吧? 写过正则表达式的人都知道,正则表达式入门不难,写起来也容易. 但是正则表达式几乎没有可读性可言,维护起来,真的会让人抓狂,别以为这段正则是你写的就可以驾驭它,过个一个月你可能就不认识它了. 完全可以说,天下苦正则久
-
Python json解析库jsonpath原理及使用示例
jsonpath jsonpath 用于多层嵌套 json格式的 解析. pip install jsonpath JsonPath 描述 $ 根节点 @ 现行节点 .or[] 取子节点 n/a 取父节点,jsonpath为支持 .. 就是不管位置,选择所有复合条件的条件 * 匹配所有元素节点 n/a 根据属性访问,json不支持,因为json是个key-value递归结构,不需要数属性访问 [] 迭代器标示(可以在里边做简单的迭代操作,如数组下标,根据内容选值等) [,] 支持迭代器中做多选
-
python常用request库与lxml库操作方法整理总结
目录 requests 库最常见的操作 请求参数以及请求方法 响应对象的属性与方法 属性 property 方法 会话对象 SSL 证书验证,客户端证书,CA 证书 代理 Cookie lxml 库 lxml.etree XPath lxml 其他说明 requests 库最常见的操作 请求参数以及请求方法 导入 requests 库之后,基本都在围绕 requests.get 做文章,这里重点要回顾的是 get 方法的参数,其中包含如下内容,下述内容在官方手册没有呈现清单,通过最新版源码分析.
-
python正则表达中的re库常用方法总结
元字符 : 预定义字符集: 我进行组合一些复杂的正则表达式的时候是为了快捷去晚上找一些现成的模式,然后再自己进行修改,变成符合自己需要的一些正则表达式. import re # 正则表达式中的一些使用的符号 # 匹配出现符合条件的 0 次的或者是 多次 str1 = 'qwertyuio1ui3oo467j398k' # 关键词: * 下面的句子就是进行匹配 零次 或者是 多次(多个字符) 符合是数字的意思 pattern = re.compile(r'\d*') res = re.findal
-
详解Python文本操作相关模块
详解Python文本操作相关模块 linecache--通过使用缓存在内部尝试优化以达到高效从任何文件中读出任何行. 主要方法: linecache.getline(filename, lineno[, module_globals]):获取指定行的内容 linecache.clearcache():清除缓存 linecache.checkcache([filename]):检查缓存的有效性 dircache--定义了一个函数,使用缓存读取目录列表.使用目录的mtime来实现缓存失效.此外还定义
-
分享Python文本生成二维码实例
本文实例分享了Python文本生成二维码的详细代码,供大家参考,具体内容如下 测试一:将文本生成白底黑字的二维码图片 测试二:将文本生成带logo的二维码图片 #coding:utf-8 ''' Python生成二维码 v1.0 主要将文本生成二维码图片 测试一:将文本生成白底黑字的二维码图片 测试二:将文本生成带logo的二维码图片 ''' __author__ = 'Xue' import qrcode from PIL import Image import os #生成二维码图片 def
-
python基于Tkinter库实现简单文本编辑器实例
本文实例讲述了python基于Tkinter库实现简单文本编辑器的方法.分享给大家供大家参考.具体实现方法如下: ## {{{ http://code.activestate.com/recipes/578568/ (r1) from Tkinter import * from tkSimpleDialog import askstring from tkFileDialog import asksaveasfilename from tkMessageBox import askokcance
-
Python使用Scrapy保存控制台信息到文本解析
在Windows平台下,如果想运行爬虫的话,就需要在cmd中输入: scrapy crawl spider_name 这时,爬虫就能启动,并在控制台(cmd)中打印一些信息,如下图所示: 但是,cmd中默认只能显示几屏的信息,其他的信息就无法看到. 如果我们想查看爬虫在运行过程中的调试信息或错误信息的话,会很不方便. 此时,我们就可以将控制台的信息写入的一个文本文件中去,方便我们查看. 命令如下: D:\>scrapy crawl spder_name -s LOG_FILE=scrapy.lo
-
Python文本处理之按行处理大文件的方法
以行的形式读出一个文件最简单的方式是使用文件对象的readline().readlines()和xreadlines()方法. Python2.2+为这种频繁的操作提供了一个简化的语法--让文件对象自身在行上高效迭代(这种迭代是严格的向前的). 为了读取整个文件,可能要使用read()方法,且使用字符串的split()来将它拆分WEIGHT行或其他块. 下面是一些例子: >>> for line in open('chap1.txt'): # Python 2.2+ ... # proc
-
JS正则(RegExp)判断文本框中是否包含特殊符号
前言 有时,我们希望判断文本框中用户输入的字符是否含有特殊符号(*/#$@),就像用户注册时密码框的填写. demo 利用 RegExp 对象,能很优雅的实现以上需求: // even(文本框内容) function (even) { // 规则对象(flag) var flag = new RegExp("[`~!@#$^&*()=|{}':;',\\[\\].<><>/?~!@#¥--&*()--|{}[]'::""'.,.? ]&