Python数据可视化探索实例分享
目录
- 一、数据可视化与探索图
- 二、常见的图表实例
- 1.折线图
- 2.散布图
- 3.直方图、长条图
- 4. 圆饼图、箱形图
- 三、社区调查
- 四、波士顿房屋数据集
一、数据可视化与探索图
数据可视化是指用图形或表格的方式来呈现数据。图表能够清楚地呈现数据性质, 以及数据间或属性间的关系,可以轻易地让人看图释义。用户通过探索图(Exploratory Graph)可以了解数据的特性、寻找数据的趋势、降低数据的理解门槛。
二、常见的图表实例
本章主要采用 Pandas 的方式来画图,而不是使用 Matplotlib 模块。其实 Pandas 已经把 Matplotlib 的画图方法整合到 DataFrame 中,因此在实际应用中,用户不需要直接引用 Matplotlib 也可以完成画图的工作。
1.折线图
折线图(line chart)是最基本的图表,可以用来呈现不同栏位连续数据之间的关系。绘制折线图使用的是 plot.line() 的方法,可以设置颜色、形状等参数。在使用上,拆线图绘制方法完全继承了 Matplotlib 的用法,所以程序最后也必须调用 plt.show() 产生图,如图8.4 所示。
df_iris[['sepal length (cm)']].plot.line() plt.show() ax = df[['sepal length (cm)']].plot.line(color='green',title="Demo",style='--') ax.set(xlabel="index", ylabel="length") plt.show()

2.散布图
散布图(Scatter Chart)用于检视不同栏位离散数据之间的关系。绘制散布图使用的是 df.plot.scatter(),如图8.5所示。
df = df_iris
df.plot.scatter(x='sepal length (cm)', y='sepal width (cm)')
from matplotlib import cm
cmap = cm.get_cmap('Spectral')
df.plot.scatter(x='sepal length (cm)',
y='sepal width (cm)',
s=df[['petal length (cm)']]*20,
c=df['target'],
cmap=cmap,
title='different circle size by petal length (cm)')

3.直方图、长条图
直方图(Histogram Chart)通常用于同一栏位,呈现连续数据的分布状况,与直方图类似的另一种图是长条图(Bar Chart),用于检视同一栏位,如图 8.6 所示。
df[['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)','petal width (cm)']].plot.hist() 2 df.target.value_counts().plot.bar()

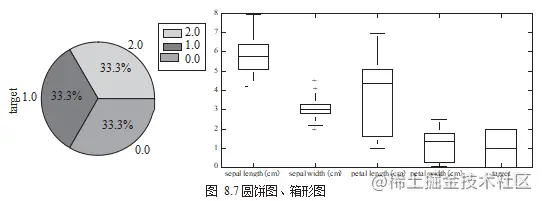
4. 圆饼图、箱形图
圆饼图(Pie Chart)可以用于检视同一栏位各类别所占的比例,而箱形图(Box Chart)则用于检视同一栏位或比较不同栏位数据的分布差异,如图 8.7 所示。
df.target.value_counts().plot.pie(legend=True) df.boxplot(column=['target'],figsize=(10,5))
数据探索实战分享:
本节利用两个真实的数据集实际展示数据探索的几种手法。
三、社区调查
在美国社区调查(American Community Survey)中,每年约有 350 万个家庭被问到关于他们是谁及他们如何生活的详细问题。调查的内容涵盖了许多主题,包括祖先、教育、工作、交通、互联网使用和居住。
数据名称:2013 American Community Survey。
先观察数据的样子与特性,以及每个栏位代表的意义、种类和范围。
# 读取数据
df = pd.read_csv("./ss13husa.csv")
# 栏位种类数量
df.shape
# (756065,231)
# 栏位数值范围
df.describe()
先将两个 ss13pusa.csv 串连起来,这份数据总共包含 30 万笔数据,3 个栏位:SCHL ( 学历,School Level)、 PINCP ( 收入,Income) 和 ESR ( 工作状态,Work Status)。
pusa = pd.read_csv("ss13pusa.csv") pusb = pd.read_csv("ss13pusb.csv")
# 串接两份数据
col = ['SCHL','PINCP','ESR']
df['ac_survey'] = pd.concat([pusa[col],pusb[col],axis=0)
依据学历对数据进行分群,观察不同学历的数量比例,接着计算他们的平均收入。
group = df['ac_survey'].groupby(by=['SCHL']) print('学历分布:' + group.size())
group = ac_survey.groupby(by=['SCHL']) print('平均收入:' +group.mean())
四、波士顿房屋数据集
波士顿房屋数据集(Boston House Price Dataset)包含有关波士顿地区的房屋信息, 包 506 个数据样本和 13 个特征维度。
数据名称:Boston House Price Dataset。
先观察数据的样子与特性,以及每个栏位代表的意义、种类和范围。
可以用直方图的方式画出房价(MEDV)的分布,如图 8.8 所示。
df = pd.read_csv("./housing.data")
# 栏位种类数量
df.shape
# (506, 14)
#栏位数值范围df.describe()
import matplotlib.pyplot as plt
df[['MEDV']].plot.hist()
plt.show()

注:图中英文对应笔者在代码中或数据中指定的名字,实践中读者可将它们替换成自己需要的文字。
接下来需要知道的是哪些维度与“房价”关系明显。先用散布图的方式来观察,如图8.9所示。
# draw scatter chart df.plot.scatter(x='MEDV', y='RM') . plt.show()

最后,计算相关系数并用聚类热图(Heatmap)来进行视觉呈现,如图 8.10 所示。
# compute pearson correlation corr = df.corr() # draw heatmap import seaborn as sns corr = df.corr() sns.heatmap(corr) plt.show()

颜色为红色,表示正向关系;颜色为蓝色,表示负向关系;颜色为白色,表示没有关系。RM 与房价关联度偏向红色,为正向关系;LSTAT、PTRATIO 与房价关联度偏向深蓝, 为负向关系;CRIM、RAD、AGE 与房价关联度偏向白色,为没有关系。
到此这篇关于Python数据可视化探索实例分享的文章就介绍到这了,更多相关Python数据可视化内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python 数据可视化超详细讲解折线图的实现
绘制简单的折线图 在使用matplotlib绘制简单的折线图之前首先需要安装matplotlib,直接在pycharm终端pip install matplotlib即可 使用matplotlib绘制简单的折线图,再对其进行定制,实现数据的可视化操作 import matplotlib.pyplot as plt # 导入pyplot模块并设置别名为plt squares = [1, 4, 9, 16, 25] plt.plot(squares) plt.show() # 打开matplotib
-
Python数据可视化绘图实例详解
目录 利用可视化探索图表 1.数据可视化与探索图 2.常见的图表实例 数据探索实战分享 1.2013年美国社区调查 2.波士顿房屋数据集 利用可视化探索图表 1.数据可视化与探索图 数据可视化是指用图形或表格的方式来呈现数据.图表能够清楚地呈现数据性质, 以及数据间或属性间的关系,可以轻易地让人看图释义.用户通过探索图(Exploratory Graph)可以了解数据的特性.寻找数据的趋势.降低数据的理解门槛. 2.常见的图表实例 本章主要采用 Pandas 的方式来画图,而不是使用 Matpl
-
利用Python对中国500强排行榜数据进行可视化分析
目录 一.前言 二.数据采集 1.开始爬取 获取企业列表 获取企业对应url 获取每一个企业相关数据 2.保存到Excel 三.可视化分析 1.省份分布 导入相关可视化库 统计数据 地图可视化 2.营业收入年增率 3.营业收入年减率 4.利润年增率 5.利润年减率 6.排名上升最快20家企业 7.排名下降最快20家企业 8.资产区间分布 9.市值区间分布 10.营业收入区间分布 11.利润区间分布 12.中国500强企业-排名前10营业收入.利润.资产.市值.股东权益 四.总结 一.前言 今天来
-
python数据可视化之条形图画法
什么是条形图? 条形图(bar chart)是用宽度相同的条形的高度或长短来表示数据多少的图形.条形图可以横置或纵置,纵置时也称为柱形图(column chart).此外,条形图有简单条形图.复式条形图等形式. 简单来说,条形图的宽度一般是相同的,条形的高度或长短表示数据的多少,这也就是条形图和直方图的本质区别. 第一种画法 import numpy as np from pandas import DataFrame # 由于我们的x轴上刻度值是中文 需要使用这个包 进行中文的显示 from
-
Python数据可视化Pyecharts制作Heatmap热力图
目录 HeatMap:热力图 1.基本设置 2.热力图数据项 Demo 举例 1.基础热力图 本文介绍基于 Python3 的 Pyecharts 制作 Heatmap(热力图 时需要使用的设置参数和常用模板案例,可根据实际情况对案例中的内容进行调整即可. 使用 Pyecharts 进行数据可视化时可提供直观.交互丰富.可高度个性化定制的数据可视化图表.案例中的代码内容基于 Pyecharts 1.x 版本 . HeatMap:热力图 1.基本设置 class HeatMap( # 初始化配置项
-
python数据可视化之日期折线图画法
本文实例为大家分享了python日期折线图画法的具体代码,供大家参考,具体内容如下 引入 什么是折线图: 折线图是排列在工作表的列或行中的数据可以绘制到折线图中.折线图可以显示随时间(根据常用比例设置)而变化的连续数据,因此非常适用于显示在相等时间间隔下数据的趋势.在折线图中,类别数据沿水平轴均匀分布,所有值数据沿垂直轴均匀分布. 以上引用自 百度百科 ,简单来说一般折线图 是以时间作为 X 轴 数据 作为 Y轴,这当然不是固定的,是可以自行设置的. 话不多说~ 进入正题 第一种画法: impo
-
Python采集股票数据并制作可视化柱状图
目录 前言 模块使用 开发环境 代码实现步骤 代码 数据可视化 前言 嗨喽!大家好呀,这里是魔王~ 雪球,聪明的投资者都在这里 - 4300万投资者都在用的投资社区, 沪深港美全球市场实时行情,股票基金债券免费资讯,与投资高手实战交流. 模块使用 requests >>> pip install requests (数据请求 第三方模块) re # 正则表达式 去匹配提取数据 json pandas pyecharts 开发环境 Python 3.8 解释器 Pycharm 2021.2
-
Python数据可视化探索实例分享
目录 一.数据可视化与探索图 二.常见的图表实例 1.折线图 2.散布图 3.直方图.长条图 4. 圆饼图.箱形图 三.社区调查 四.波士顿房屋数据集 一.数据可视化与探索图 数据可视化是指用图形或表格的方式来呈现数据.图表能够清楚地呈现数据性质, 以及数据间或属性间的关系,可以轻易地让人看图释义.用户通过探索图(Exploratory Graph)可以了解数据的特性.寻找数据的趋势.降低数据的理解门槛. 二.常见的图表实例 本章主要采用 Pandas 的方式来画图,而不是使用 Matplotl
-
Python数据可视化:饼状图的实例讲解
使用python实现论文里面的饼状图: 原图: python代码实现: # # 饼状图 # plot.figure(figsize=(8,8)) labels = [u'Canteen', u'Supermarket', u'Dorm', u'Others'] sizes = [73, 21, 4, 2] colors = ['red', 'yellow', 'blue', 'green'] explode = (0.05, 0, 0, 0) patches, l_text, p_text =
-
Python数据可视化:幂律分布实例详解
1.公式推导 对幂律分布公式: 对公式两边同时取以10为底的对数: 所以对于幂律公式,对X,Y取对数后,在坐标轴上为线性方程. 2.可视化 从图形上来说,幂律分布及其拟合效果: 对X轴与Y轴取以10为底的对数.效果上就是X轴上1与10,与10与100的距离是一样的. 对XY取双对数后,坐标轴上点可以很好用直线拟合.所以,判定数据是否符合幂律分布,只需要对XY取双对数,判断能否用一个直线很好拟合就行.常见的直线拟合效果评估标准有拟合误差平方和.R平方. 3.代码实现 #!/usr/bin/env
-
Python数据可视化处理库PyEcharts柱状图,饼图,线性图,词云图常用实例详解
python可以在处理各种数据时,如果可以将这些数据,利用图表将其可视化,这样在分析处理起来,将更加直观.清晰,以下是 利用 PyEcharts 常用图表的可视化Demo, 开发环境 python3 柱状图 基本柱状图 from pyecharts import Bar # 基本柱状图 bar = Bar("基本柱状图", "副标题") bar.use_theme('dark') # 暗黑色主题 bar.add('真实成本', # label ["1月&q
-
利用Python进行数据可视化的实例代码
目录 前言 首先搭建环境 实例代码 例子1: 例子2: 例子3: 例子4: 例子5: 例子6: 总结 前言 前面写过一篇用Python制作PPT的博客,感兴趣的可以参考 用Python制作PPT 这篇是关于用Python进行数据可视化的,准备作为一个长贴,随时更新有价值的Python可视化用例,都是网上搜集来的,与君共享,本文所有测试均基于Python3. 首先搭建环境 $pip install pyecharts -U $pip install echarts-themes-pypkg $pi
-
Python利用Bokeh进行数据可视化的教程分享
目录 介绍 代码1.散点标记 代码2.单行 代码3.条形图 代码4.箱线图 代码5.直方图 代码6.散点图 介绍 Bokeh是 Python 中的数据可视化库,提供高性能的交互式图表和绘图.Bokeh 输出可以在笔记本.html 和服务器等各种媒体中获得.可以在 Django 和烧瓶应用程序中嵌入散景图. Bokeh 为用户提供了两个可视化界面: bokeh.models:为应用程序开发人员提供高度灵活性的低级接口. bokeh.plotting:用于创建视觉字形的高级界面. 要安装 bokeh
-
基于Python数据可视化利器Matplotlib,绘图入门篇,Pyplot详解
Pyplot matplotlib.pyplot是一个命令型函数集合,它可以让我们像使用MATLAB一样使用matplotlib.pyplot中的每一个函数都会对画布图像作出相应的改变,如创建画布.在画布中创建一个绘图区.在绘图区上画几条线.给图像添加文字说明等.下面我们就通过实例代码来领略一下他的魅力. import matplotlib.pyplot as plt plt.plot([1,2,3,4]) plt.ylabel('some numbers') plt.show() 上图是我们通
-
Python数据操作方法封装类实例
本文实例讲述了Python数据操作方法封装类.分享给大家供大家参考,具体如下: 工作中经常会用到数据的插叙.单条数据插入和批量数据插入,以下是本人封装的一个类,推荐给各位: #!/usr/bin/env python # -*- coding:utf-8 -*- # Author:Eric.yue import logging import MySQLdb class _MySQL(object): def __init__(self,host, port, user, passwd, db):
-
Python数据可视化:顶级绘图库plotly详解
有史以来最牛逼的绘图工具,没有之一 plotly是现代平台的敏捷商业智能和数据科学库,它作为一款开源的绘图库,可以应用于Python.R.MATLAB.Excel.JavaScript和jupyter等多种语言,主要使用的js进行图形绘制,实现过程中主要就是调用plotly的函数接口,底层实现完全被隐藏,便于初学者的掌握. 下面主要从Python的角度来分析plotly的绘图原理及方法: ###安装plotly: 使用pip来安装plotly库,如果机器上没有pip,需要先进行pip的安装,这里